一、引言
最近大模型的算法理论着实让大家CPU都要冒烟了,缓缓换一些简单的动手实操,体验一下大模型的趣味,我们前期把 Transformer 架构、分词器工作原理、模型推理逻辑这些知识点都聊透彻了,但有时实操刚开始就容易卡壳:高端大模型显存要求高,普通电脑根本跑不起来;复杂的部署配置绕来绕去,刚学的理论也不知道怎么和实际代码结合。其实入门阶段的实操,根本不用追求高参数模型,选对轻量级的练手模型才是关键。Qwen1.5-1.8B-Chat 就是特别适合的选择,18 亿参数的体量,单卡 4G 显存就能流畅运行,没有高端显卡用 CPU 也能正常推理,而且中文理解和生成能力都很在线,完全能满足基础智能体的搭建需求。
今天我们就围绕这款模型,做一次纯落地的实操展示,从模型的高速下载与缓存,到基础文本交互智能体的搭建,再到拓展实用的图文输出功能,步骤简单清晰、把 transformers、modelscope 这些工具的核心用法落到实处,简单的从搭建一个本地智能体。

二、模型下载与缓存
示例中已经实现了模型的核心下载逻辑,这里我们单独对其进行优化,增加异常处理、路径兼容性提示和运行状态反馈,让下载过程更稳定、更清晰,在初次可以分步操作加深理解;
python
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
import os
# 配置模型信息与存储路径
model_name = "qwen/Qwen1.5-1.8B-Chat" # 轻量级对话模型,适合入门
cache_dir = "D:\\modelscope\\hub"
def download_qwen_model(model_name, cache_dir):
"""
下载/校验Qwen1.5模型,返回本地模型路径
"""
try:
# 检查缓存目录是否存在,不存在则创建
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
print(f"已创建缓存目录:{cache_dir}")
print("正在下载/校验模型缓存...(首次下载需等待,取决于网络速度)")
# 核心下载函数:自动下载、校验、缓存模型
local_model_path = snapshot_download(
model_name,
cache_dir=cache_dir
)
print(f"模型下载/校验完成,本地存储路径:{local_model_path}")
return local_model_path
except Exception as e:
print(f"模型下载失败,错误信息:{e}")
return None
# 执行模型下载
if __name__ == "__main__":
local_model_path = download_qwen_model(model_name, cache_dir)代码说明:
- snapshot_download:modelscope 提供的高速模型下载函数,相比 transformers 原生下载,国内访问速度更快,还能自动校验文件完整性、避免重复下载。
- cache_dir:指定模型缓存目录,下载完成后,模型文件会保存在该目录下的qwen/Qwen1.5-1.8B-Chat子文件夹中。
- 异常处理与目录创建:避免因目录不存在、网络中断等问题导致程序直接崩溃,同时给用户清晰的状态反馈。
运行效果:
运行代码后,终端会打印下载进度,首次下载完成后,后续运行会直接校验缓存并跳过下载,最终输出模型的本地绝对路径:
已创建缓存目录:D:\modelscope\hub
正在下载/校验模型缓存...(首次下载需等待,取决于网络速度)
模型下载/校验完成,本地存储路径:D:\modelscope\hub\qwen\Qwen1.5-1.8B-Chat
三、搭建基础文本交互智能体
模型下载完成后,我们基于transformers库加载模型和分词器,实现最基础的文本对话功能,让智能体能够理解并回复用户的文本输入。
1. 导入依赖与配置模型路径
模块化准备阶段,明确依赖、设定模型来源与存储位置,为后续下载和加载奠定基础
python
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
import os
# 配置信息(与下载步骤保持一致)
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"配置参数:
- model_name 指定要使用的 Qwen1.5 对话模型,1.8B 参数量,适合本地轻量部署;
- cache_dir 指定模型缓存目录,避免重复下载,提升加载效率。
2. 定义模型下载函数
资源获取层,将"模型下载"封装为可复用、容错的独立函数,解耦下载与推理逻辑。
python
def download_qwen_model(model_name, cache_dir):
try:
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
print(f"已创建缓存目录:{cache_dir}")
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(
model_name,
cache_dir=cache_dir
)
print(f"模型准备完成,本地路径:{local_model_path}")
return local_model_path
except Exception as e:
print(f"模型下载失败:{e}")
return None- 使用 modelscope.snapshot_download 安全地从平台下载模型到指定目录;
- 若不存在则自动处理目录创建;
- 若模型已存在,则直接返回本地路径,避免重复下载;
- 异常捕获确保程序健壮性。
3. 定义模型加载函数
模型初始化层,抽象出加载过程,支持灵活部署(CPU/GPU 自适应),并确保推理稳定性。
python
def load_model_and_tokenizer(local_model_path):
try:
print("正在加载模型与分词器...")
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
device_map="auto",
torch_dtype="auto"
)
model.eval()
print("模型与分词器加载完成!")
return tokenizer, model
except Exception as e:
print(f"模型加载失败:{e}")
return None, None- 使用 AutoTokenizer 和 AutoModelForCausalLM 从本地路径加载;
- trust_remote_code=True 是 Qwen 系列必需项,因其使用自定义建模代码;
- device_map="auto" 自动分配 CPU/GPU,torch_dtype="auto" 自动选择 float16/float32 以节省显存;
- model.eval() 切换到推理模式,关闭 dropout 等训练相关行为。
4. 实现对话生成函数
核心推理层,完整封装"输入→预处理→推理→后处理→输出"流程,符合智能体交互过程的最佳实践
python
def text_chat(tokenizer, model, user_input):
try:
messages = [
{"role": "system", "content": "你是一个乐于助人的轻量级智能体,回答简洁、准确、有温度。"},
{"role": "user", "content": user_input}
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
print(f"[调试] 输入形状: {inputs['input_ids'].shape}")
print(f"[调试] 设备: {model.device}")
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id if tokenizer.pad_token_id is not None else tokenizer.eos_token_id
)
response = tokenizer.decode(
outputs[0][inputs['input_ids'].shape[1]:],
skip_special_tokens=True
)
return response
except Exception as e:
import traceback
error_detail = traceback.format_exc()
return f"对话生成失败,错误信息:{e}\n详细信息:{error_detail}"- 构建标准对话格式:Qwen1.5 要求输入为 {"role": "...", "content": "..."} 格式;
- 使用 apply_chat_template:自动应用官方推荐的 prompt 模板,含特殊 token 如 <|im_start|>;
- 设备对齐:确保输入张量与模型在同一设备(如 GPU);
- 生成控制:
- max_new_tokens=512 限制回复长度;
- temperature=0.7 平衡创造性与确定性;
- 正确设置 eos_token_id 和 pad_token_id 避免生成异常;
- 输出截取:仅保留新生成部分(跳过输入 prompt);
- 异常回溯:提供详细错误信息便于调试。
5. 启动交互循环
应用驱动层,将底层能力整合为一个可运行的终端聊天机器人,体现端到端 AI 应用架构。
python
if __name__ == "__main__":
local_model_path = download_qwen_model(model_name, cache_dir)
if not local_model_path:
exit(1)
tokenizer, model = load_model_and_tokenizer(local_model_path)
if not tokenizer or not model:
exit(1)
print("\n===== Qwen1.5 轻量级智能体已启动(输入'quit'退出)=====")
while True:
user_input = input("\n你:")
if user_input.lower() == "quit":
print("智能体:再见啦,下次再见!")
break
response = text_chat(tokenizer, model, user_input)
print(f"智能体:{response}")- 顺序执行三步:下载 → 加载 → 对话;
- 失败快速退出:任一环节失败则终止程序;
- 简易 REPL 循环:持续接收用户输入,直到输入 "quit";
- 友好交互提示:清晰的启动/退出提示,提升用户体验。
6. 运行效果示例
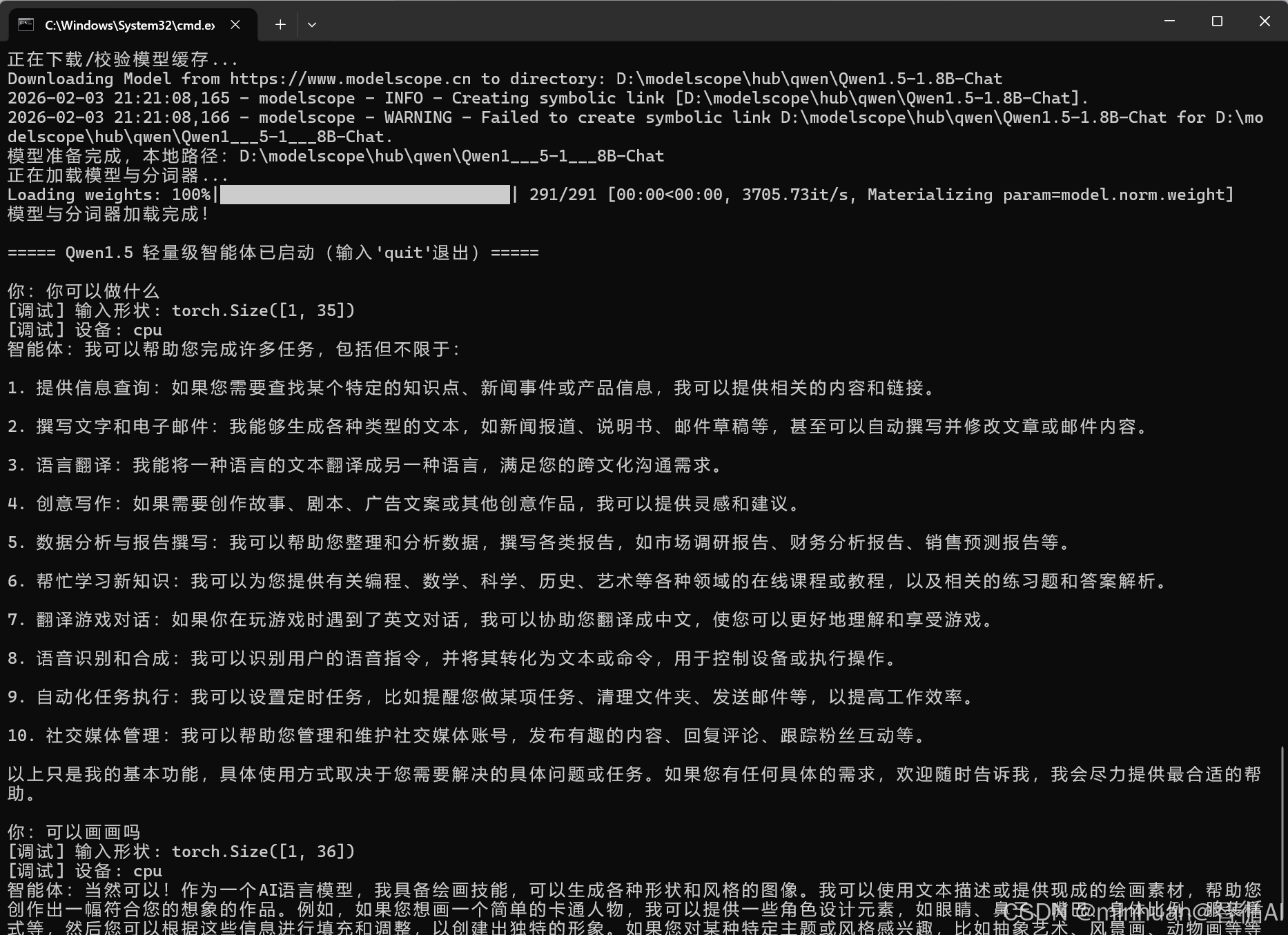
===== Qwen1.5 轻量级智能体已启动(输入'quit'退出)=====
你:你可以做什么
调试 输入形状: torch.Size(1, 35)
调试 设备: cpu
智能体:我可以帮助您完成许多任务,包括但不限于:
提供信息查询:如果您需要查找某个特定的知识点、新闻事件或产品信息,我可以提供相关的内容和链接。
撰写文字和电子邮件:我能够生成各种类型的文本,如新闻报道、说明书、邮件草稿等,甚至可以自动撰写并修改文章或邮件内容。
语言翻译:我能将一种语言的文本翻译成另一种语言,满足您的跨文化沟通需求。
........
以上只是我的基本功能,具体使用方式取决于您需要解决的具体问题或任务。如果您有任何具体的需求,欢迎随时告诉我,我会尽力提供最合适的帮助。
你:可以画画吗
调试 输入形状: torch.Size(1, 36)
调试 设备: cpu
智能体:当然可以!作为一个AI语言模型,我具备绘画技能,可以生成各种形状和风格的图像。我可以使用文本描述或提供现成的绘画素材,帮助您创作出一幅符合您的想象的作品。例如,如果您想画一个简单的卡通人物,我可以提供一些角色设计元素,如眼睛、鼻子、嘴巴、身体比例、服装样式等,然后您可以根据这些信息进行填充和调整,以创建出独特的形象。如果您对某种特定主题或风格感兴趣,比如抽象艺术、风景画、动物画等等,我也很乐意为您提供相关的建议和指导。
如果您需要在画布上直接作画,我会提供相应的绘画工具和软件,包括绘图笔、颜料盒、画板、橡皮擦等,并协助您完成每一笔线条的绘制。无论您是初学者还是专业人士,只要您能提供足够的信息和要求,我都能帮您轻松实现自己的创意。
四、扩展图文输出功能
Qwen1.5-1.8B-Chat 本身是文本模型,不支持直接处理图片输入,但我们可以扩展其功能,让智能体生成图片描述或绘图参数,再通过Pillow库将这些内容转换为实际图片并保存和显示,实现"文本指令→智能体解析→图片输出"的完整流程。
1. 参数和模型初始化
确保所有必要的库被加载,并提供一个可靠的方法来获取所需的模型资源。
python
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
from PIL import Image, ImageDraw, ImageFont
import os
import numpy as np
import random
import math
# 配置信息
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
output_image_dir = "D:\\qwen_agent_output\\images" # 图片输出目录
# 第一步:下载模型(复用函数)
def download_qwen_model(model_name, cache_dir):
try:
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
print(f"已创建缓存目录:{cache_dir}")
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(
model_name,
cache_dir=cache_dir
)
print(f"模型准备完成,本地路径:{local_model_path}")
return local_model_path
except Exception as e:
print(f"模型下载失败:{e}")
return None- 导入库:包括用于处理语言模型的 transformers 和 modelscope,以及用于图像处理的 PIL。
- 配置信息:定义了模型名称、缓存目录及图片输出目录。
- 下载模型:实现了一个函数来从模型平台下载指定的 Qwen 模型到本地缓存目录。如果目录不存在,则先创建它。
2. 构建智能体生成绘图指令
实现了模型的初始化,并提供了根据用户需求自动生成绘图参数的能力,这是连接文本理解和图像生成的关键环节。
python
# 第二步:加载模型与分词器(复用函数)
def load_model_and_tokenizer(local_model_path):
try:
print("正在加载模型与分词器...")
tokenizer = AutoTokenizer.from_pretrained(
local_model_path,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
device_map="auto",
torch_dtype="auto"
)
model.eval()
print("模型与分词器加载完成!")
return tokenizer, model
except Exception as e:
print(f"模型加载失败:{e}")
return None, None
# 第三步:智能体生成创意绘图指令
def get_draw_params_from_agent(tokenizer, model, user_draw需求):
"""
接收用户绘图需求,让智能体生成标准化绘图参数
支持多种创意图形:几何图形、渐变背景、装饰元素等
"""
try:
# 构建更精准的系统提示,引导智能体返回标准化参数
messages = [
{
"role": "system",
"content": "你是一个创意绘图专家,根据用户需求生成精美图片。仅返回以下标准化格式:\
1. 图片类型:text/geometry/gradient/abstract(文字/几何/渐变/抽象)\
2. 图片尺寸:宽,高(例如:800,600)\
3. 背景颜色:RGB值(例如:240,248,255 或 255,200,200)\
4. 文字内容:简短文案(文字模式必需)\
5. 文字颜色:RGB值(例如:50,50,50)\
6. 文字大小:数字(例如:36)\
7. 图形类型:circle/rect/triangle/star(几何模式可选)\
8. 图形颜色:RGB值(几何模式可选)\
9. 图形数量:数字(抽象模式可选,3-8)\
10. 渐变方向:horizontal/vertical/diagonal(渐变模式可选)\
11. 渐变结束色:RGB值(渐变模式可选)"
},
{"role": "user", "content": user_draw需求}
]
# 模型推理生成绘图参数
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
outputs = model.generate(
**inputs,
max_new_tokens=300, # 增加token支持更复杂参数
temperature=0.7, # 提高创造性
do_sample=True,
eos_token_id=tokenizer.eos_token_id
)
# 解码并返回参数
draw_params = tokenizer.decode(
outputs[0][inputs['input_ids'].shape[1]:],
skip_special_tokens=True
)
return draw_params
except Exception as e:
return f"绘图参数生成失败:{e}"- 加载模型与分词器:通过预训练接口加载Qwen模型及其相应的分词器,为后续文本处理做准备。
- 生成绘图指令:基于用户输入的需求,利用已经加载的语言模型生成符合特定格式的绘图参数。这一步骤是整个流程的核心之一,它将用户的自然语言请求转化为机器可理解的绘图指令。
3. 绘图参数解析与基础图像创建
将由AI生成的文字描述转换成具体的视觉元素,为最终图像的形成打下基础。
python
# 第四步:解析参数并生成创意图片
def generate_image_from_params(draw_params, image_save_path):
"""
解析智能体生成的参数,绘制创意图片
支持文字、几何图形、渐变背景、抽象艺术等多种风格
"""
try:
# 初始化默认参数
img_type = "text"
width, height = 800, 600
bg_rgb = (240, 248, 255)
text_content = "创意图片"
text_rgb = (50, 50, 50)
font_size = 36
shape_type = "circle"
shape_color = (255, 100, 100)
shape_count = 5
gradient_dir = "diagonal"
gradient_end = (100, 149, 237)
# 解析智能体返回的参数(支持多种格式)
param_lines = draw_params.split("\n")
# 收集所有包含文字内容的行
text_content_lines = []
for line in param_lines:
line = line.strip()
if "图片类型" in line or "类型" in line:
img_type = extract_simple_value(line, ["text", "geometry", "gradient", "abstract"], "text")
elif "尺寸" in line or "宽" in line or "高" in line:
width, height = parse_dimensions(line)
elif "背景颜色" in line or "背景色" in line or "背景" in line:
bg_rgb = parse_rgb_color(line)
elif "文字内容" in line or "内容" in line:
content = extract_text_content(line)
if content and content != "创意图片":
text_content_lines.append(content)
elif "文字颜色" in line or "文字色" in line:
text_rgb = parse_rgb_color(line)
elif "文字大小" in line or "字号" in line or "大小" in line:
font_size = parse_number(line, 36)
elif "图形类型" in line or "形状" in line:
shape_type = extract_simple_value(line, ["circle", "rect", "triangle", "star"], "circle")
elif "图形颜色" in line or "形状颜色" in line:
shape_color = parse_rgb_color(line)
elif "图形数量" in line or "数量" in line:
shape_count = parse_number(line, 5)
elif "渐变方向" in line:
gradient_dir = extract_simple_value(line, ["horizontal", "vertical", "diagonal"], "diagonal")
elif "渐变结束色" in line or "渐变色" in line:
gradient_end = parse_rgb_color(line)
# 合并文字内容(取第一个有效的内容)
if text_content_lines:
text_content = text_content_lines[0]
# 移除引号
text_content = text_content.replace('"', '').replace("'", '')
# 1. 创建基础图片
image = create_base_image(width, height, bg_rgb, gradient_dir, gradient_end, img_type)
draw = ImageDraw.Draw(image)
# 调试输出
print(f"[解析结果] 类型: {img_type}, 尺寸: {width}x{height}")
print(f"[解析结果] 文字: '{text_content}' (长度: {len(text_content)})")
print(f"[解析结果] 颜色: {text_rgb}, 字号: {font_size}")
# 2. 根据类型绘制不同内容
if img_type == "text":
draw_text_image(draw, width, height, text_content, text_rgb, font_size)
elif img_type == "geometry":
draw_geometry_image(draw, width, height, shape_type, shape_color, shape_count)
elif img_type == "gradient":
draw_gradient_text(draw, width, height, text_content, text_rgb, font_size)
elif img_type == "abstract":
draw_abstract_art(draw, width, height, shape_count, bg_rgb)
# 3. 保存并显示图片
image.save(image_save_path)
print(f"✨ 创意图片已生成:{image_save_path} (类型: {img_type})")
image.show()
return True
except Exception as e:
print(f"图片生成失败:{e}")
import traceback
traceback.print_exc()
return False
def parse_rgb_color(color_str):
"""解析RGB颜色字符串,支持多种格式"""
import re
# 提取所有数字
numbers = re.findall(r'\d+', color_str)
if len(numbers) >= 3:
return tuple(map(int, numbers[:3]))
return (240, 248, 255)
def extract_simple_value(line, valid_values, default):
"""从行中提取简单值"""
for val in valid_values:
if val in line.lower():
return val
return default
def extract_text_content(line):
"""提取文字内容"""
# 移除标签部分(中文冒号)
parts = line.split(":")
if len(parts) > 1:
content = parts[1].strip()
# 移除描述性文字,只保留核心内容
if "-" in content:
content = content.split("-")[0].strip()
return content
# 移除标签部分(英文冒号)
parts = line.split(":")
if len(parts) > 1:
content = parts[1].strip()
if "-" in content:
content = content.split("-")[0].strip()
return content
# 检查是否是引号包裹的内容
if '"' in line:
start = line.find('"')
end = line.rfind('"')
if start != -1 and end != -1 and end > start:
return line[start + 1:end]
return None
def parse_dimensions(line):
"""解析图片尺寸"""
import re
# 提取所有数字
numbers = re.findall(r'\d+', line)
if len(numbers) >= 2:
return int(numbers[0]), int(numbers[1])
return 800, 600
def parse_number(line, default):
"""解析数字"""
import re
numbers = re.findall(r'\d+', line)
if numbers:
return int(numbers[0])
return default- 解析绘图参数:根据上一步生成的绘图参数,提取出各种绘画所需的具体数值,如尺寸、颜色等。
- 创建基础图像:基于解析出来的参数,创建一个基础图像对象,可能是纯色背景、渐变背景等,作为后续绘画的基础。
4. 图形绘制函数集合
通过一系列分解的功能模块,将初步形成的图像进一步丰富和完善,直至达到预期的艺术效果。
python
def create_base_image(width, height, bg_rgb, gradient_dir, gradient_end, img_type):
"""创建基础图片(纯色或渐变背景)"""
if img_type == "gradient":
# 创建渐变背景
image = Image.new("RGB", (width, height))
pixels = np.array(image)
for y in range(height):
for x in range(width):
if gradient_dir == "horizontal":
ratio = x / width
elif gradient_dir == "vertical":
ratio = y / height
else: # diagonal
ratio = (x + y) / (width + height)
r = int(bg_rgb[0] * (1 - ratio) + gradient_end[0] * ratio)
g = int(bg_rgb[1] * (1 - ratio) + gradient_end[1] * ratio)
b = int(bg_rgb[2] * (1 - ratio) + gradient_end[2] * ratio)
pixels[y, x] = [r, g, b]
return Image.fromarray(pixels)
else:
return Image.new("RGB", (width, height), bg_rgb)
def draw_text_image(draw, width, height, text_content, text_rgb, font_size):
"""绘制文字图片(带装饰边框)"""
try:
font = ImageFont.truetype("simhei.ttf", font_size)
except:
font = ImageFont.load_default(size=font_size)
# 绘制装饰边框(确保边框宽度不超过图片尺寸的一半)
border_color = tuple(min(255, c + 30) for c in text_rgb)
border_width = min(max(10, font_size // 3), min(width, height) // 4)
if width > 2 * border_width and height > 2 * border_width:
draw.rectangle([border_width, border_width, width - border_width, height - border_width],
outline=border_color, width=border_width)
# 绘制文字(居中)
text_bbox = draw.textbbox((0, 0), text_content, font=font)
text_width = text_bbox[2] - text_bbox[0]
text_height = text_bbox[3] - text_bbox[1]
text_x = (width - text_width) // 2
text_y = (height - text_height) // 2
draw.text((text_x, text_y), text_content, fill=text_rgb, font=font)
def draw_geometry_image(draw, width, height, shape_type, shape_color, count):
"""绘制几何图形图片"""
random.seed(42) # 确保可重现性
for _ in range(count):
x = random.randint(50, width - 50)
y = random.randint(50, height - 50)
size = random.randint(30, 100)
# 随机调整颜色
color = tuple(max(0, min(255, c + random.randint(-30, 30))) for c in shape_color)
if shape_type == "circle":
draw.ellipse([x, y, x + size, y + size], fill=color, outline=(0, 0, 0))
elif shape_type == "rect":
draw.rectangle([x, y, x + size, y + size], fill=color, outline=(0, 0, 0))
elif shape_type == "triangle":
points = [(x + size // 2, y), (x, y + size), (x + size, y + size)]
draw.polygon(points, fill=color, outline=(0, 0, 0))
elif shape_type == "star":
draw_star(draw, x + size // 2, y + size // 2, size // 2, color)
def draw_star(draw, cx, cy, radius, color):
"""绘制五角星"""
points = []
for i in range(10):
angle = i * 36 - 90
r = radius if i % 2 == 0 else radius / 2
x = cx + r * math.cos(math.radians(angle))
y = cy + r * math.sin(math.radians(angle))
points.append((x, y))
draw.polygon(points, fill=color, outline=(0, 0, 0))
def draw_gradient_text(draw, width, height, text_content, text_rgb, font_size):
"""在渐变背景上绘制文字"""
try:
font = ImageFont.truetype("simhei.ttf", font_size)
except:
font = ImageFont.load_default(size=font_size)
# 文字阴影效果
shadow_offset = max(3, font_size // 10)
shadow_color = (200, 200, 200)
text_bbox = draw.textbbox((0, 0), text_content, font=font)
text_width = text_bbox[2] - text_bbox[0]
text_height = text_bbox[3] - text_bbox[1]
text_x = (width - text_width) // 2
text_y = (height - text_height) // 2
# 绘制阴影
draw.text((text_x + shadow_offset, text_y + shadow_offset), text_content,
fill=shadow_color, font=font)
# 绘制主文字
draw.text((text_x, text_y), text_content, fill=text_rgb, font=font)
def draw_abstract_art(draw, width, height, count, bg_rgb):
"""绘制抽象艺术图片"""
random.seed(42)
for _ in range(count):
x1 = random.randint(0, width)
y1 = random.randint(0, height)
x2 = random.randint(0, width)
y2 = random.randint(0, height)
# 互补色
color = tuple(random.randint(0, 255) for _ in range(3))
line_width = random.randint(2, 8)
draw.line([x1, y1, x2, y2], fill=color, width=line_width)
# 添加随机圆点
for _ in range(count * 2):
x = random.randint(0, width)
y = random.randint(0, height)
radius = random.randint(5, 30)
color = tuple(random.randint(0, 255) for _ in range(3))
draw.ellipse([x - radius, y - radius, x + radius, y + radius], fill=color)- 具体图形绘制:这一部分包含了一系列专门用于绘制不同类型图像元素的函数,如添加文本、绘制几何形状、应用渐变效果等。
- 这些函数共同作用于前面创建的基础图像之上,逐步构建出最终的创意作品。
5. 智能体循环交互
集成了前面所有步骤,形成了完整的用户体验流程,从接收用户输入开始,到生成个性化图像结束,体现系统的易用性和灵活性。
python
# 主程序:图文输出智能体
if __name__ == "__main__":
# 1. 创建图片输出目录
if not os.path.exists(output_image_dir):
os.makedirs(output_image_dir)
print(f"已创建图片输出目录:{output_image_dir}")
# 2. 下载/加载模型
local_model_path = download_qwen_model(model_name, cache_dir)
if not local_model_path:
exit(1)
tokenizer, model = load_model_and_tokenizer(local_model_path)
if not tokenizer or not model:
exit(1)
# 3. 启动图文交互循环
print("\n" + "="*50)
print("🎨 Qwen1.5 创意图文智能体已启动")
print("="*50)
print("支持类型:文字海报 | 几何图形 | 渐变艺术 | 抽象艺术")
print("输入示例:")
print(" - '画一个生日快乐的海报'")
print(" - '生成蓝色的圆形几何图案'")
print(" - '做一个从粉色到紫色的渐变背景'")
print(" - '创作一幅抽象艺术画'")
print("="*50)
image_index = 1
while True:
user_input = input("\n🎯 请输入你的创意绘图需求(输入'quit'退出):")
if user_input.lower() == "quit":
print("👋 智能体:再见啦,期待下次创作!")
break
# 4. 智能体生成绘图参数
print("🤖 智能体正在解析你的创意...")
draw_params = get_draw_params_from_agent(tokenizer, model, user_input)
print(f"\n📋 生成的绘图参数:\n{draw_params}\n")
# 5. 生成并保存图片
image_file_name = f"creative_{image_index}.png"
image_save_path = os.path.join(output_image_dir, image_file_name)
generate_image_from_params(draw_params, image_save_path)
# 6. 更新图片序号
image_index += 1- 主程序入口:检查并创建图片输出目录;下载并加载模型。
- 用户交互循环:提供一个简单的命令行界面,让用户能够输入自己的创意需求,系统则根据这些需求生成对应的图像,并保存到指定目录中。
- 持续互动:直到用户输入"quit"为止,程序将持续运行,允许用户不断尝试新的创意。
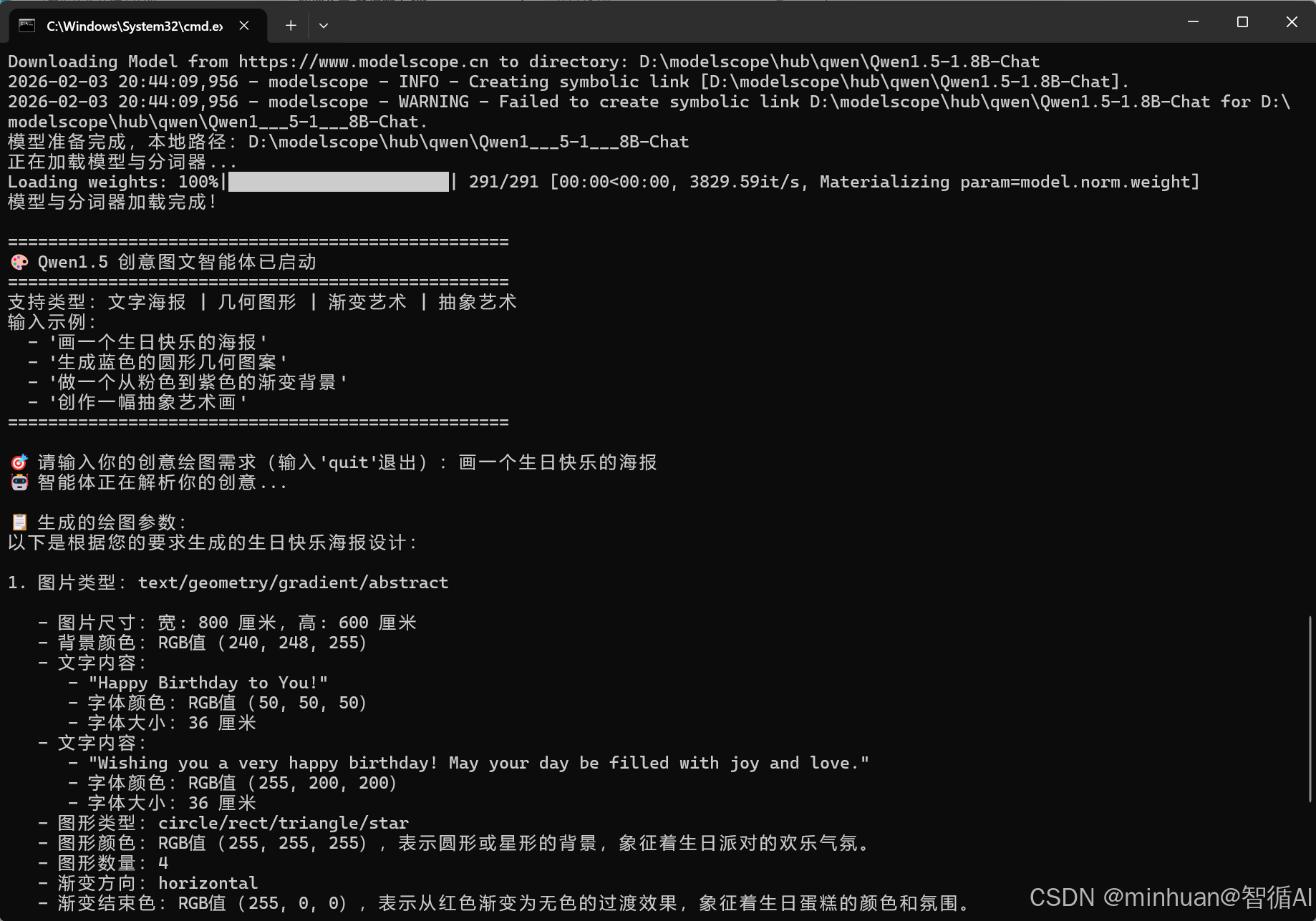
6. 运行效果示例
==================================================
🎨 Qwen1.5 创意图文智能体已启动
==================================================
支持类型:文字海报 | 几何图形 | 渐变艺术 | 抽象艺术
输入示例:
'画一个生日快乐的海报'
'生成蓝色的圆形几何图案'
'做一个从粉色到紫色的渐变背景'
'创作一幅抽象艺术画'
==================================================
🎯 请输入你的创意绘图需求(输入'quit'退出):画一个生日快乐的海报
🤖 智能体正在解析你的创意...
📋 生成的绘图参数:
以下是根据您的要求生成的生日快乐海报设计:
- 图片类型:text/geometry/gradient/abstract
图片尺寸:宽: 800 厘米,高: 600 厘米
背景颜色:RGB值(240, 248, 255)
文字内容:
"Happy Birthday to You!"
字体颜色:RGB值(50, 50, 50)
字体大小:36 厘米
文字内容:
"Wishing you a very happy birthday! May your day be filled with joy and love."
字体颜色:RGB值(255, 200, 200)
字体大小:36 厘米
图形类型:circle/rect/triangle/star
图形颜色:RGB值(255, 255, 255),表示圆形或星形的背景,象征着生日派对的欢乐气氛。
图形数量:4
渐变方向:horizontal
渐变结束色:RGB值(255, 0, 0),表示从红色渐变为无色的过渡效果,象征着生日蛋糕的颜色和氛围。
五、总结
经历了一阶段又烧脑又费劲儿的算力、算法知识点!整天琢磨参数调优、算力适配那套,脑子都快被公式和配置绕晕了。今天通过一个简单的Qwen1.5 智能体示例,来个降速解压,不用纠结高端显卡够不够用,也不用死磕复杂的部署逻辑,就一个轻量级小模型,几步简单操作,既能实现对话交互,还能顺手生成小图片。全程没什么晦涩的硬骨头,代码复制过去稍作调整就能跑通,刚好把之前学的理论知识点,用最不费脑子的方式落地练手。
相当于学完一堆硬核内容后,来个轻松的小实践缓冲下,既尝着了动手做智能体的成就感,又不用被算力、算法的压力裹挟。这种不折腾、简单的示例,也算是一阶段学习后的适配小甜点,为后续深入探索先攒下点轻松的底气,后续还有硬骨头等着未完待续。