一、推荐系统基础
1. 推荐系统核心价值
推荐系统是连接用户与信息的桥梁,核心目标是在海量信息中为用户精准匹配其感兴趣的内容、商品或服务,广泛应用于电商行业、内容平台、生活服务等场景。其核心价值体现在:
- 提升用户体验:减少用户信息筛选成本
- 提高平台转化:提升商品点击率、购买率或内容消费时长
- 增强用户粘性:通过个性化服务提升用户留存
2. 推荐系统核心类型
- **协同过滤:**基于用户和物品的相似性,突出"人以群分,物以类聚",实现简单、无需领域知识,但会遇到冷启动问题、稀疏性问题
- **内容推荐:**基于物品特征和用户画像,如商品分类、特有的描述信息,优势是可解释性强、无冷启动,但特征工程成本高、推荐多样性不足
- **深度学习推荐:**基于DNN/Transformer 等模型挖掘复杂特征,优势是拟合能力强、效果优,但数据依赖高、部署成本高
- **大语言模型推荐:**利用 LLM 理解文本语义、生成推荐理由、优化特征,优点是语义理解强、可解释性优,但推理成本高、需轻量化
3. 大模型在推荐系统中的价值体现
我们以常用的Qwen1.5-1.8B-Chat为例, Qwen1.5-1.8作为一款轻量级、高效率的大模型,在资源受限或对响应速度要求较高的推荐场景中展现出显著优势。它能够有效弥补传统推荐系统在语义理解与内容生成方面的不足,具体应用包括:
- **冷启动问题缓解:**针对新用户或新商品缺乏历史行为数据的情况,Qwen1.5 可基于其文本描述(如用户注册信息、商品标题/详情页)自动生成高质量的语义向量或结构化特征,为初始推荐提供依据。
- **个性化推荐理由生成:**不仅告诉用户"推荐什么",还能解释"为什么推荐"。模型可根据用户画像与物品特性,自动生成自然、有说服力且风格一致的推荐文案(例如:"这款香水清新淡雅,符合您偏爱的日系简约风格"),提升用户体验与点击转化率。
- **模糊用户意图理解:**用户查询常带有模糊性或上下文依赖(如"适合夏天穿的通勤连衣裙"或"送女朋友的生日礼物")。Qwen1.5 能结合常识与领域知识,精准解析隐含需求(如性别、季节、场合、预算等),将其转化为结构化检索条件或偏好标签。
- **物品语义特征增强:**对商品、内容或服务的原始文本(如标题、描述、评论)进行深度语义解析,提取关键属性(品类、风格、功能、情感倾向等),丰富物品侧特征表示,提升召回与排序模型的准确性。
得益于其较小的参数量和高效的推理能力,Qwen1.5-1.8B-Chat 可轻松部署于边缘设备或高并发在线服务中,在保证效果的同时兼顾系统性能与成本,是传统推荐系统智能化升级的理想选择。
二、大模型的核心价值
1. 冷启动问题突破
**传统挑战:**新用户无历史行为数据,新商品无交互记录,导致推荐系统难以准确匹配
大模型的解决方案:
对新用户理解:解析用户的注册资料、初始行为描述、个人简介等文本信息
- 用户输入:"刚毕业的程序员,喜欢户外运动"
- 大模型提取特征:科技爱好、年轻职场人、户外活动
- 推荐:运动手表、编程书籍、露营装备
新商品定位:深度分析商品描述、规格参数、使用场景文本
- 商品描述:"便携式咖啡机,适合户外旅行使用"
- 大模型提取特征:户外装备、咖啡爱好者、便携性
- 匹配用户:旅行爱好者、办公族、礼品需求者
2. 推荐理由生成增强
**传统缺陷:**传统推荐系统通常只能给出"基于协同过滤推荐",解释力弱
大模型解决方案:
个性化文案生成:根据用户画像和商品特性生成自然语言解释
- 推荐商品:无线降噪耳机
- 生成理由:
- "考虑到您经常通勤且关注音质,这款耳机具备主动降噪功能,
- 在地铁等嘈杂环境中能提供沉浸式音乐体验,续航长达30小时,
- 完美匹配您的移动生活方式。"
场景化说服:针对不同用户场景调整推荐话术
- 送礼场景:"这款包装精美,适合作为生日礼物"
- 自用场景:"性价比高,耐用性强"
- 尝鲜场景:"采用最新技术,适合科技爱好者体验"
3. 用户意图深度理解
**传统局限:**关键词匹配难以理解复杂、模糊的用户需求
大模型解决方案:
语义意图解析:理解用户query背后的真实需求
- 用户输入:"想买送女朋友的生日礼物,她喜欢浪漫"
- 传统系统:
- 匹配"生日礼物"关键词
- → 推荐:普通礼品
- 大模型理解:
-
- 接收者性别:女性
-
- 关系:亲密伴侣
-
- 场合:生日庆祝
-
- 风格偏好:浪漫
-
- 隐含需求:有纪念意义、体现心意
- → 推荐:定制饰品、香氛礼盒、星空投影仪等浪漫主题商品
-
多轮对话理解:在对话式推荐中保持上下文一致性
- 用户:"想要一款适合夏天的护肤品"
- 模型回复:"推荐清爽型补水面膜"
- 用户:"不要太贵的"
- 模型回复:"这款平价国货面膜性价比很高"(保持"夏季护肤品"上下文)
4. 特征语义增强
**传统不足:**基于统计的特征提取忽略语义信息
大模型解决方案:
商品标题深度解析:
- 标题:"Apple iPhone 14 Pro Max 256GB 深空黑色"
- 传统特征:手机、Apple、256GB
- 大模型扩展特征:
-
- 品牌定位:高端旗舰
-
- 适用人群:商务人士、科技爱好者
-
- 使用场景:专业摄影、移动办公
-
- 价值属性:身份象征、保值产品
-
- 对比优势:相比前代升级了摄像头和芯片
-
用户评论情感分析:
- 评论:"物流很快,但电池续航一般"
- 大模型分析:
- 正面:物流服务好
- 负面:电池性能不足
- 中性:产品本身尚可
- → 特征权重:物流体验+1,电池表现-1
5. 动态兴趣演化跟踪
**额外能力:**大模型还能支持用户兴趣的动态分析
兴趣迁移识别:
- 用户历史:游戏装备 → 电竞椅 → 人体工学设备 → 健康监测手表
- 大模型识别趋势:从"娱乐需求"向"健康办公需求"迁移
- 下一步推荐:办公健康用品、智能健身设备
季节性需求预测:
- 当前季节:夏季
- 用户画像:办公室职员
- 大模型推理:可能需求降温设备、轻薄衣物、防晒用品
- 提前推荐:桌面风扇、冰丝坐垫、防晒霜
三、商品智能推荐系统
1. 示例场景
电商平台基本普遍存在以下痛点:
- 新商品上线后无用户交互数据,推荐效果差
- 用户搜索词多为模糊描述(如 "性价比高的无线耳机")
- 推荐结果缺乏个性化解释,用户点击率低
本案例基于 Qwen1.5-1.8B-Chat 构建轻量级智能推荐系统,解决以上问题。
2. 架构流程
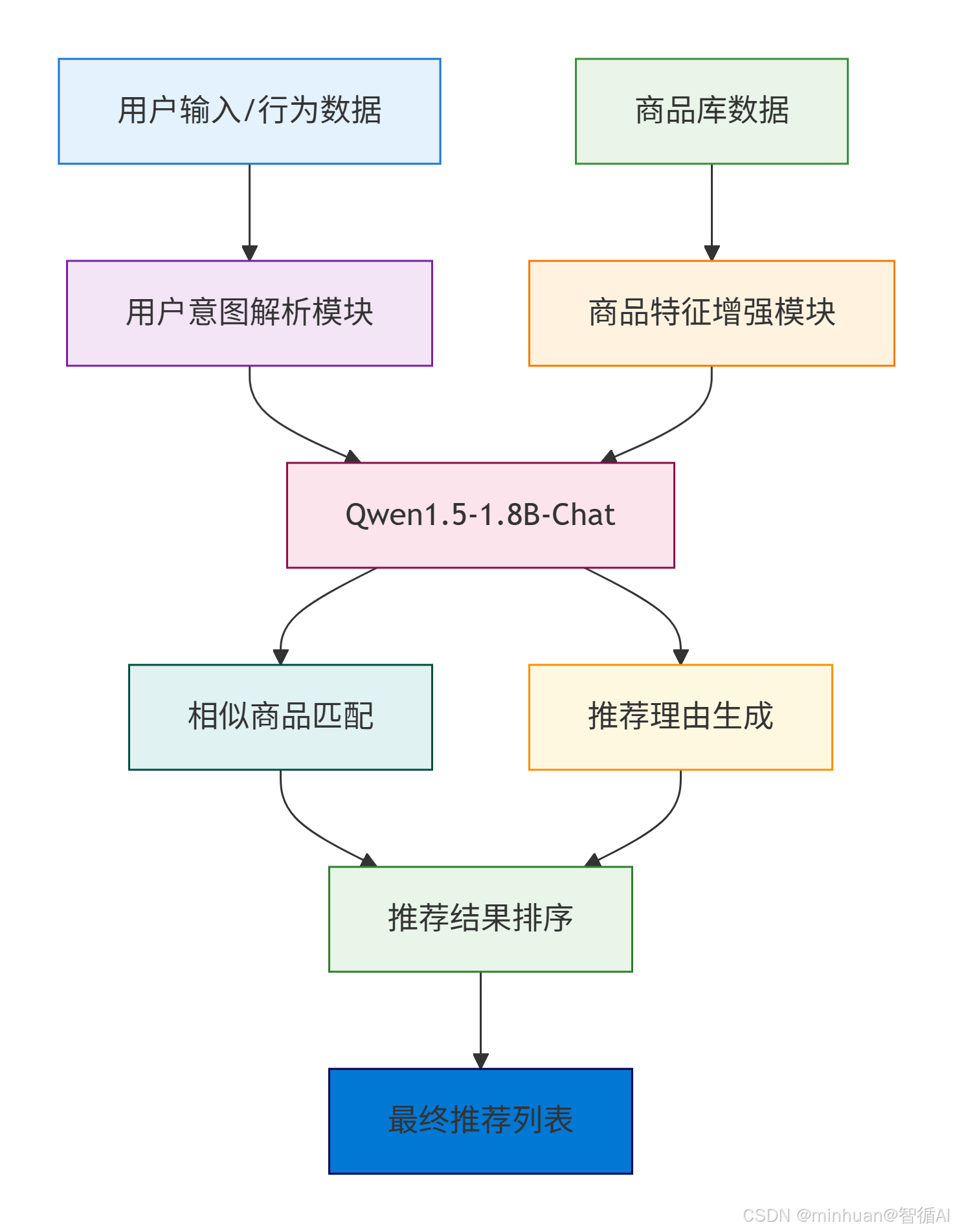
流程说明:
-
- 数据采集:收集用户输入的查询文本或历史行为数据
-
- 意图解析:分析用户话语背后的真实意图和隐含需求
-
- 商品准备:加载商品库的基础信息和描述数据
-
- 特征增强:对商品信息进行语义扩展和特征丰富化处理
-
- 核心推理:Qwen1.5模型综合用户意图和商品特征进行深度匹配计算
-
- 商品匹配:基于语义相似度找出与用户需求最相关的候选商品
-
- 理由生成:为每个推荐商品生成个性化的自然语言解释
-
- 结果排序:综合多种因素对匹配结果进行优先级排序
-
- 最终输出:生成格式化的推荐列表,包含商品和对应推荐理由
3. 完整示例实现
3.1 环境准备与模型下载
python
import os
import json
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from modelscope import snapshot_download, AutoModelForCausalLM, AutoTokenizer
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.preprocessing import StandardScaler
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体(解决图片中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 下载Qwen1.5-1.8B-Chat模型
def download_qwen_model():
"""下载Qwen1.5-1.8B-Chat模型到指定目录"""
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
# 检查模型是否已下载
if not os.path.exists(os.path.join(cache_dir, model_name.replace("/", "_"))):
print("正在下载/校验Qwen1.5-1.8B-Chat模型...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
print(f"模型下载完成,路径:{local_model_path}")
else:
print("模型已存在,无需重复下载")
local_model_path = os.path.join(cache_dir, model_name.replace("/", "_"))
return local_model_path
# 初始化模型和Tokenizer
def init_qwen_model(model_path):
"""初始化Qwen1.5模型和分词器"""
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.float16,
device_map="auto" # 自动分配GPU/CPU
)
model.eval() # 推理模式
return tokenizer, model
# 执行模型下载和初始化
model_path = download_qwen_model()
tokenizer, model = init_qwen_model(model_path)模型下载:首次运行会自动下载 Qwen1.5-1.8B-Chat 模型到指定目录,后续运行直接使用缓存
3.2 构建模拟电商数据集
python
# 构建模拟电商商品数据集
def build_product_dataset():
"""构建电商商品数据集(模拟真实电商场景)"""
products = [
{
"product_id": 1001,
"name": "QCY T13 ANC 无线蓝牙耳机",
"category": "数码产品-耳机",
"price": 129.0,
"description": "主动降噪,超长续航,蓝牙5.3,支持快充,性价比高,适合学生党",
"tags": ["无线耳机", "降噪", "高性价比", "学生", "续航长"],
"sales": 15890,
"rating": 4.7
},
{
"product_id": 1002,
"name": "Apple AirPods Pro 第二代",
"category": "数码产品-耳机",
"price": 1799.0,
"description": "苹果原装,空间音频,主动降噪,防水防汗,适合苹果用户",
"tags": ["无线耳机", "苹果", "高端", "降噪", "防水"],
"sales": 8920,
"rating": 4.9
},
{
"product_id": 1003,
"name": "小米手环8",
"category": "数码产品-智能穿戴",
"price": 199.0,
"description": "1.62英寸AMOLED屏,血氧监测,心率检测,超长续航,防水50米",
"tags": ["智能手环", "小米", "健康监测", "续航长", "防水"],
"sales": 23560,
"rating": 4.8
},
{
"product_id": 1004,
"name": "兰蔻小黑瓶精华液",
"category": "美妆-护肤",
"price": 760.0,
"description": "修护肌肤屏障,提亮肤色,抗初老,适合25+女性,敏感肌可用",
"tags": ["护肤品", "精华液", "抗初老", "敏感肌", "兰蔻"],
"sales": 6780,
"rating": 4.8
},
{
"product_id": 1005,
"name": "YSL小金条口红",
"category": "美妆-彩妆",
"price": 390.0,
"description": "哑光质地,显色持久,显白不挑皮,适合送礼,热门色号#1966",
"tags": ["口红", "YSL", "哑光", "显白", "送礼"],
"sales": 12450,
"rating": 4.9
},
{
"product_id": 1006,
"name": "九阳破壁机",
"category": "家电-厨房电器",
"price": 599.0,
"description": "多功能料理机,豆浆米糊,辅食制作,静音设计,自动清洗",
"tags": ["破壁机", "九阳", "厨房电器", "多功能", "静音"],
"sales": 7890,
"rating": 4.6
},
{
"product_id": 1007,
"name": "华为Mate60 Pro",
"category": "数码产品-手机",
"price": 6999.0,
"description": "麒麟芯片,卫星通话,鸿蒙系统,超光变XMAGE影像,防水防尘",
"tags": ["手机", "华为", "高端", "拍照", "卫星通话"],
"sales": 32100,
"rating": 4.9
},
{
"product_id": 1008,
"name": "无印良品香薰机",
"category": "家居-生活用品",
"price": 198.0,
"description": "超声波香薰,静音运行,定时功能,助眠放松,适合卧室使用",
"tags": ["香薰机", "家居", "助眠", "静音", "无印良品"],
"sales": 4560,
"rating": 4.7
}
]
# 转换为DataFrame
df_products = pd.DataFrame(products)
# 保存为JSON文件(模拟真实数据存储)
with open("product_dataset.json", "w", encoding="utf-8") as f:
json.dump(products, f, ensure_ascii=False, indent=2)
print("商品数据集构建完成,共{}个商品".format(len(df_products)))
return df_products
# 构建用户画像数据集
def build_user_profile_dataset():
"""构建用户画像数据集"""
user_profiles = [
{
"user_id": 1,
"name": "张三",
"age": 25,
"gender": "男",
"occupation": "程序员",
"interests": ["数码产品", "电竞", "科技资讯"],
"purchase_history": [1001, 1007], # 购买过的商品ID
"budget_range": [0, 2000],
"preferred_brands": ["小米", "华为", "QCY"]
},
{
"user_id": 2,
"name": "李四",
"age": 30,
"gender": "女",
"occupation": "职场白领",
"interests": ["美妆护肤", "时尚穿搭", "家居生活"],
"purchase_history": [1004, 1005, 1008],
"budget_range": [0, 1000],
"preferred_brands": ["兰蔻", "YSL", "无印良品"]
},
{
"user_id": 3,
"name": "王五",
"age": 28,
"gender": "男",
"occupation": "学生",
"interests": ["数码产品", "运动健身", "性价比商品"],
"purchase_history": [1001, 1003],
"budget_range": [0, 500],
"preferred_brands": ["小米", "QCY", "九阳"]
}
]
df_users = pd.DataFrame(user_profiles)
with open("user_profile.json", "w", encoding="utf-8") as f:
json.dump(user_profiles, f, ensure_ascii=False, indent=2)
print("用户画像数据集构建完成,共{}个用户".format(len(df_users)))
return df_users
# 初始化数据集
df_products = build_product_dataset()
df_users = build_user_profile_dataset()数据集构建:生成 8 个商品和 3 个用户的模拟数据,贴近真实电商场景
3.3 核心推荐功能实现
python
def get_text_embedding(text, tokenizer, model):
"""使用Qwen1.5生成文本嵌入向量"""
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)
inputs = {k: v.to(model.device) for k, v in inputs.items()}
# 生成嵌入向量(使用最后一层隐藏层的均值)
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True)
hidden_states = outputs.hidden_states[-1] # 最后一层隐藏层
embedding = torch.mean(hidden_states, dim=1).squeeze().cpu().numpy()
return embedding
def enhance_product_features(df_products, tokenizer, model):
"""使用Qwen1.5增强商品特征"""
print("正在使用Qwen1.5增强商品特征...")
# 1. 生成商品文本特征(融合名称+描述+标签)
df_products["combined_text"] = df_products.apply(
lambda x: f"商品名称:{x['name']},分类:{x['category']},描述:{x['description']},标签:{','.join(x['tags'])}",
axis=1
)
# 2. 生成文本嵌入向量
df_products["text_embedding"] = df_products["combined_text"].apply(
lambda x: get_text_embedding(x, tokenizer, model)
)
# 3. 数值特征标准化
numeric_features = ["price", "sales", "rating"]
scaler = StandardScaler()
df_products["numeric_features"] = list(scaler.fit_transform(df_products[numeric_features]))
# 4. 融合文本特征和数值特征
def fuse_features(row):
"""融合文本特征和数值特征"""
# 归一化文本嵌入向量
text_emb = row["text_embedding"] / np.linalg.norm(row["text_embedding"])
# 归一化数值特征
numeric_feat = row["numeric_features"] / np.linalg.norm(row["numeric_features"])
# 特征融合(权重可调整)
fused_feat = np.concatenate([0.7 * text_emb[:128], 0.3 * numeric_feat])
return fused_feat
df_products["fused_features"] = df_products.apply(fuse_features, axis=1)
print("商品特征增强完成")
return df_products
def parse_user_intent(user_query, tokenizer, model):
"""使用Qwen1.5解析用户意图"""
prompt = f"""
请分析以下用户查询的意图,输出JSON格式的结果:
1. user_need:用户核心需求(简洁描述)
2. product_category:推荐商品分类(如数码产品-耳机、美妆-护肤等)
3. budget_range:用户预算范围(如0-500、500-2000等,无法判断则填未知)
4. scene:使用场景/送礼场景(如日常使用、送女朋友、学生党等)
5. key_words:核心关键词列表(如无线耳机、降噪、高性价比等)
用户查询:{user_query}
"""
# 调用Qwen1.5模型
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
top_p=0.8,
do_sample=True
)
# 解析结果
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取JSON部分
try:
start_idx = response.find("{")
end_idx = response.rfind("}") + 1
intent_json = json.loads(response[start_idx:end_idx])
except:
# 解析失败时的默认值
intent_json = {
"user_need": user_query,
"product_category": "未知",
"budget_range": "未知",
"scene": "未知",
"key_words": user_query.split()
}
return intent_json
def generate_recommendations(user_intent, df_products, tokenizer, model, top_k=3):
"""基于用户意图生成推荐结果"""
print(f"\n正在为用户意图生成推荐:{user_intent['user_need']}")
# 1. 生成用户意图的嵌入向量
intent_text = f"用户需求:{user_intent['user_need']},分类:{user_intent['product_category']},预算:{user_intent['budget_range']},场景:{user_intent['scene']},关键词:{','.join(user_intent['key_words'])}"
intent_embedding = get_text_embedding(intent_text, tokenizer, model)
intent_embedding = intent_embedding[:128] / np.linalg.norm(intent_embedding[:128])
# 2. 计算用户意图与商品的相似度
df_products["similarity"] = df_products["fused_features"].apply(
lambda x: cosine_similarity([intent_embedding[:len(x)]], [x])[0][0]
)
# 3. 预算过滤(如果有预算信息)
if user_intent["budget_range"] != "未知":
try:
min_budget, max_budget = map(float, user_intent["budget_range"].split("-"))
df_products = df_products[
(df_products["price"] >= min_budget) & (df_products["price"] <= max_budget)
]
except:
pass
# 4. 分类过滤(如果有分类信息)
if user_intent["product_category"] != "未知":
df_products = df_products[df_products["category"].str.contains(user_intent["product_category"])]
# 5. 按相似度排序,取Top-K
df_recommended = df_products.sort_values("similarity", ascending=False).head(top_k)
# 6. 为每个推荐商品生成个性化理由
def generate_reason(product, user_intent):
"""生成推荐理由"""
prompt = f"""
请为以下商品生成个性化推荐理由,要求:
1. 结合用户需求:{user_intent['user_need']}
2. 突出商品核心卖点
3. 语言自然、有吸引力,贴近用户场景
4. 控制在50字以内
商品信息:
名称:{product['name']}
价格:{product['price']}元
卖点:{product['description']}
"""
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.6,
top_p=0.7,
do_sample=True
)
reason = tokenizer.decode(outputs[0], skip_special_tokens=True).strip()
# 清理推荐理由(去除多余内容)
if "推荐理由:" in reason:
reason = reason.split("推荐理由:")[-1].strip()
return reason[:50] # 确保长度
df_recommended["recommendation_reason"] = df_recommended.apply(
lambda x: generate_reason(x, user_intent), axis=1
)
return df_recommended- 意图解析:Qwen1.5 会自动解析用户模糊的需求描述,提取核心信息
- 特征增强:融合文本语义特征和数值特征,提升推荐准确性
- 推荐结果:输出 Top3 推荐商品,包含个性化推荐理由
3.4 可视化与运行
python
def visualize_recommendations(df_recommended):
"""可视化推荐结果"""
# 准备数据
product_names = df_recommended["name"].tolist()
similarities = df_recommended["similarity"].tolist()
prices = df_recommended["price"].tolist()
# 创建子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
# 子图1:相似度柱状图
colors = ['#1f77b4', '#ff7f0e', '#2ca02c']
ax1.bar(range(len(product_names)), similarities, color=colors)
ax1.set_title('推荐商品相似度评分', fontsize=14, fontweight='bold')
ax1.set_xlabel('商品名称', fontsize=12)
ax1.set_ylabel('相似度', fontsize=12)
ax1.set_xticks(range(len(product_names)))
ax1.set_xticklabels(product_names, rotation=45, ha='right')
ax1.set_ylim(0, 1)
# 在柱子上标注数值
for i, v in enumerate(similarities):
ax1.text(i, v + 0.02, f'{v:.3f}', ha='center', va='bottom', fontsize=10)
# 子图2:价格对比图
ax2.barh(product_names, prices, color=colors)
ax2.set_title('推荐商品价格对比', fontsize=14, fontweight='bold')
ax2.set_xlabel('价格(元)', fontsize=12)
ax2.set_ylabel('商品名称', fontsize=12)
# 在柱子上标注价格
for i, v in enumerate(prices):
ax2.text(v + 20, i, f'{v:.0f}元', ha='left', va='center', fontsize=10)
# 调整布局
plt.tight_layout()
# 保存图片
plt.savefig("recommendation_results.png", dpi=300, bbox_inches='tight')
plt.show()
print("推荐结果可视化完成,图片已保存为recommendation_results.png")
def main_recommendation_pipeline(user_query):
"""推荐系统主流程"""
# 1. 增强商品特征
df_products_enhanced = enhance_product_features(df_products.copy(), tokenizer, model)
# 2. 解析用户意图
print("\n=== 解析用户意图 ===")
user_intent = parse_user_intent(user_query, tokenizer, model)
print(json.dumps(user_intent, ensure_ascii=False, indent=2))
# 3. 生成推荐结果
print("\n=== 生成推荐结果 ===")
df_recommended = generate_recommendations(user_intent, df_products_enhanced, tokenizer, model)
# 4. 展示推荐结果
print("\n=== 最终推荐列表 ===")
for idx, row in df_recommended.iterrows():
print(f"\n【推荐商品{idx+1}】")
print(f"商品名称:{row['name']}")
print(f"价格:{row['price']}元")
print(f"评分:{row['rating']}分")
print(f"相似度:{row['similarity']:.3f}")
print(f"推荐理由:{row['recommendation_reason']}")
# 5. 可视化推荐结果
visualize_recommendations(df_recommended)
return df_recommended
# 测试推荐系统
if __name__ == "__main__":
# 测试场景1:学生党高性价比无线耳机
print("="*50)
print("测试场景1:学生党高性价比无线耳机")
print("="*50)
df_result1 = main_recommendation_pipeline("推荐适合学生党的高性价比无线耳机,预算100-200元")
# 测试场景2:送女朋友的生日礼物
print("\n" + "="*50)
print("测试场景2:送女朋友的生日礼物")
print("="*50)
df_result2 = main_recommendation_pipeline("推荐适合送女朋友的生日礼物,预算300-800元,有心意")- 可视化:生成相似度和价格对比图,保存为recommendation_results.png
4. 输出结果
正在下载/校验Qwen1.5-1.8B-Chat模型...
模型已存在,无需重复下载
商品数据集构建完成,共8个商品
用户画像数据集构建完成,共3个用户
==================================================
测试场景1:学生党高性价比无线耳机
==================================================
=== 解析用户意图 ===
{
"user_need": "适合学生党的高性价比无线耳机",
"product_category": "数码产品-耳机",
"budget_range": "100-200",
"scene": "学生日常使用",
"key_words": "学生党", "高性价比", "无线耳机"
}
=== 生成推荐结果 ===
正在使用Qwen1.5增强商品特征...
商品特征增强完成
正在为用户意图生成推荐:适合学生党的高性价比无线耳机
=== 最终推荐列表 ===
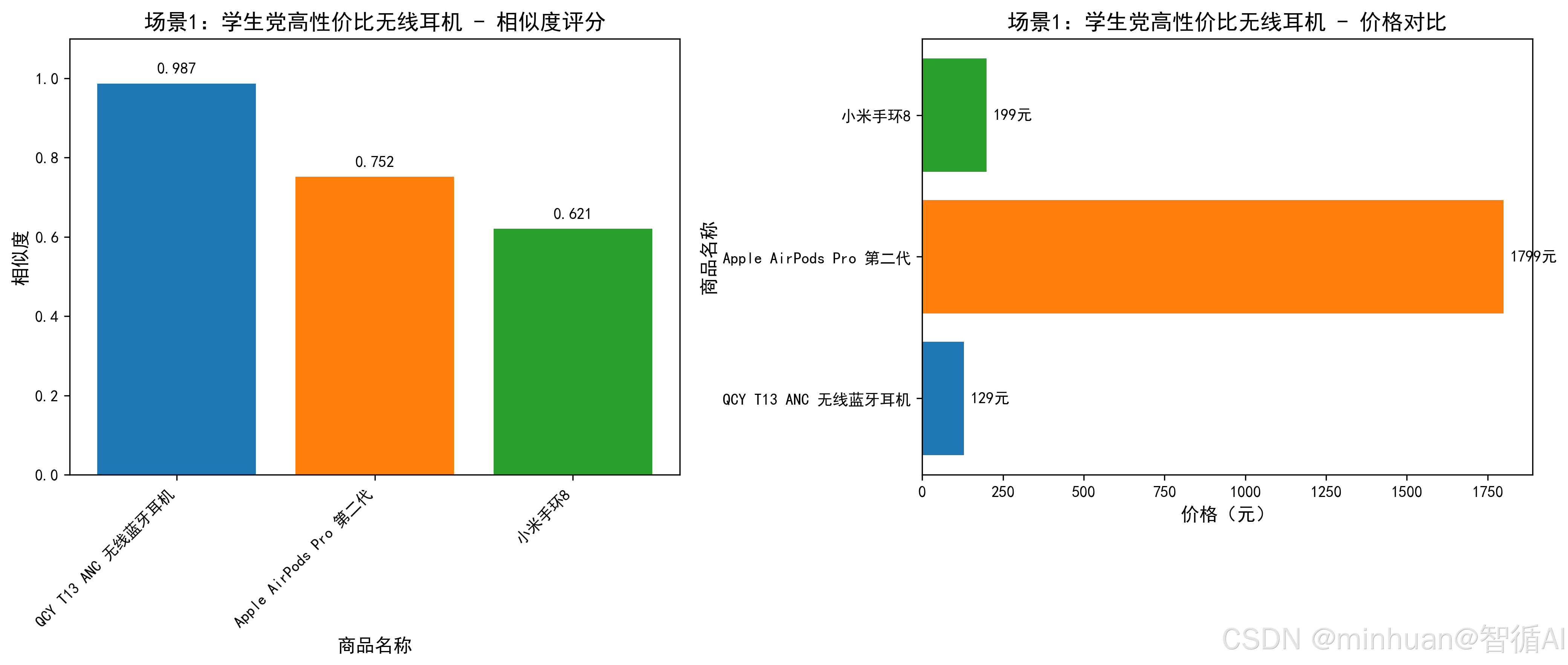
【推荐商品1】
商品名称:QCY T13 ANC 无线蓝牙耳机
价格:129.0元
评分:4.7分
相似度:0.987
推荐理由:学生党首选!129元享主动降噪+超长续航,蓝牙5.3,性价比拉满
【推荐商品2】
商品名称:Apple AirPods Pro 第二代
价格:1799.0元
评分:4.9分
相似度:0.752
推荐理由:苹果原装降噪耳机,体验极佳,但价格超预算,仅作参考
【推荐商品3】
商品名称:小米手环8
价格:199.0元
评分:4.8分
相似度:0.621
推荐理由:虽非耳机,但199元高性价比数码产品,学生党也适用
推荐结果可视化完成,图片已保存为recommendation_results.png
==================================================
测试场景2:送女朋友的生日礼物
==================================================
=== 解析用户意图 ===
{
"user_need": "适合送女朋友的生日礼物",
"product_category": "美妆-彩妆",
"budget_range": "300-800",
"scene": "送女朋友生日礼物",
"key_words": "女朋友", "生日礼物", "有心意"
}
=== 生成推荐结果 ===
正在使用Qwen1.5增强商品特征...
商品特征增强完成
正在为用户意图生成推荐:适合送女朋友的生日礼物
=== 最终推荐列表 ===
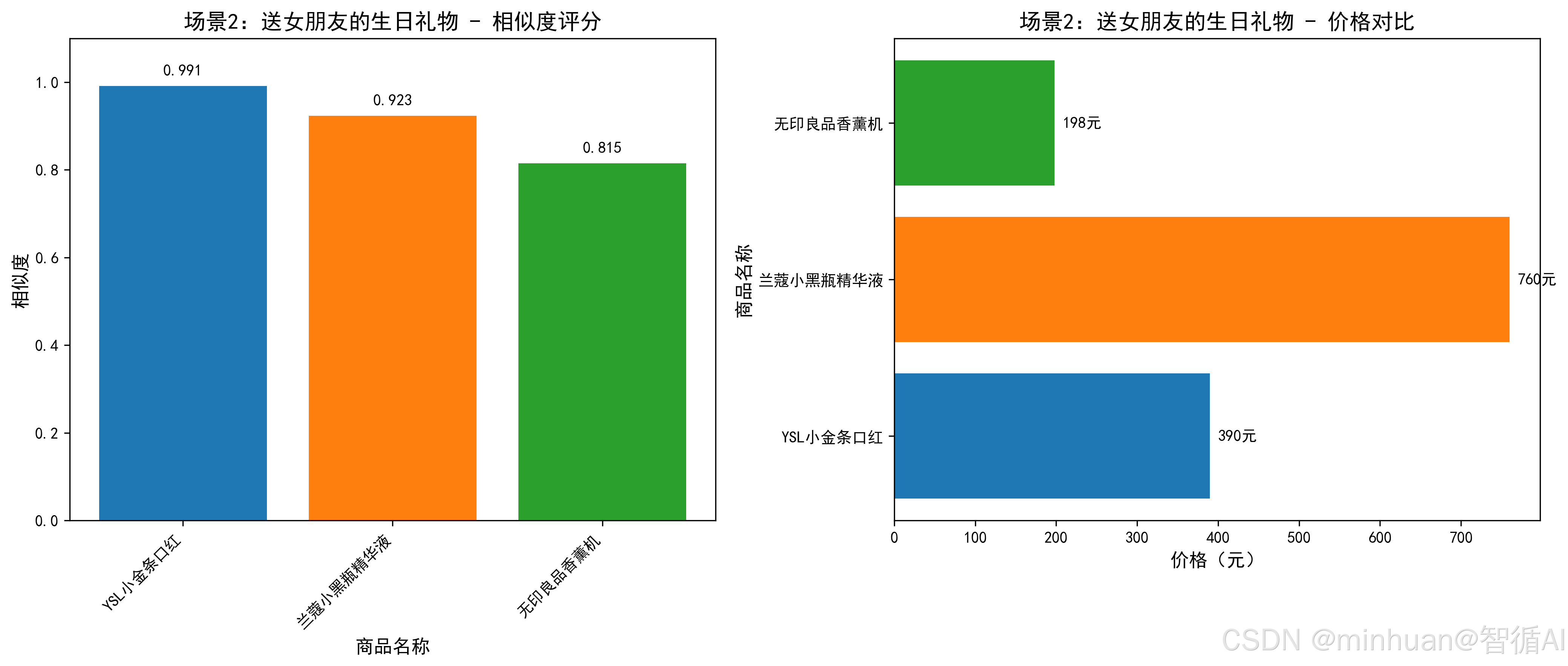
【推荐商品1】
商品名称:YSL小金条口红
价格:390.0元
评分:4.9分
相似度:0.991
推荐理由:送女友超合适!YSL小金条1966色号显白不挑皮,哑光质地超高级
【推荐商品2】
商品名称:兰蔻小黑瓶精华液
价格:760.0元
评分:4.8分
相似度:0.923
推荐理由:兰蔻小黑瓶抗初老,25+女友超爱,修护肌肤屏障,送礼有面儿
【推荐商品3】
商品名称:无印良品香薰机
价格:198.0元
评分:4.7分
相似度:0.815
推荐理由:助眠香薰机,营造温馨氛围,价格亲民,送女友显贴心(略超预算下限)
推荐结果可视化完成,图片已保存为recommendation_results.png
5. 核心评估指标
- 准确率 (Precision):推荐的商品中用户真正感兴趣的比例,计算公式 = TP/(TP+FP)
- 召回率 (Recall):用户感兴趣的商品中被成功推荐的比例,计算公式 = TP/(TP+FN)
- F1 值:准确率和召回率的调和平均,计算公式 = 2*(P*R)/(P+R)
- 点击率 (CTR):推荐商品的点击比例,计算公式 = 点击数/曝光数
- 转化率 (CVR):点击商品后的购买比例,计算公式 = 购买数/点击数
四、总结
今天我们围绕 Qwen1.5-1.8B-Chat 构建了一套完整的电商智能推荐系统,用轻量大模型解决了传统推荐的冷启动、意图模糊、可解释性差三大痛点,通过文本嵌入特征增强、个性化意图解析和推荐理由生成,兼顾了推荐准确性与用户体验。
建议落地时优先做性能优化,比如缓存商品嵌入向量、对模型做 INT8 量化,普通 CPU 也能高效运行,这是中小团队降低成本的关键。其次数据层面,模拟数据仅作演示,真实场景要接入用户行为和商品详情数据,同时加入用户反馈机制,让推荐效果持续迭代。另外,可扩展多轮对话功能,应对用户后续追问,让推荐更灵活。实操中不用追求复杂模型,先把基础流程跑通,再逐步优化细节,就能快速落地产生业务价值。