
在当前视觉语言模型(VLM)领域,GPT-4o、Gemini 1.5 等专有模型占据性能巅峰,但封闭的权重、数据与代码严重阻碍了科研社区的探索。多数开源 VLM 要么性能落后,要么依赖专有模型生成的合成数据,本质上是对封闭模型的蒸馏,缺乏 "从零构建高性能 VLM" 的基础认知。
Allen Institute for AI 与华盛顿大学联合发布的 Molmo 系列模型与 PixMo 数据集,彻底改变了这一现状。它们以 "全开源" 为核心,在不依赖任何外部 VLM 的前提下,实现了对 Claude 3.5 Sonnet、Gemini 1.5 等专有模型的超越,仅落后于 GPT-4o。
原文链接:https://arxiv.org/pdf/2409.17146
项目主页:https://allenai.org/blog/molmo
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与核心痛点
1.1 行业现状:专有模型垄断,开源模型陷入 "蒸馏依赖"
当前 VLM 领域呈现两极分化:
- 专有模型(GPT-4o、Gemini 1.5 Pro、Claude 3.5 Sonnet)性能强大,能生成详尽图像描述、精准回答复杂视觉问题,但完全封闭,不公开权重、数据或代码。
- 开源模型面临两难:早期全开源模型(如 LLaVA 1.5)性能已显著落后;近期强开源权重模型(如 PaliGemma、Qwen2-VL)要么数据专有,要么严重依赖专有 VLM 生成的合成数据(如 ShareGPT4V 使用 GPT-4V 生成描述),本质是对封闭模型的蒸馏。
1.2 核心痛点:缺乏 "从零构建" 的基础能力与高质量数据
科研社区的关键缺失在于:
- 基础认知缺口:如何不依赖任何专有 VLM,从零构建高性能 VLM 的完整方法论。
- 数据瓶颈:高质量多模态数据(预训练与微调)的收集成本高、标注难度大,学术社区难以获取。
- 技术闭环缺失:现有开源方案无法同时满足 "开源权重 + 开源数据 + 开源训练代码 + 开源评估" 的全链路透明化。
1.3 研究目标:构建全开源的 SOTA VLM 生态
本文的核心目标是打破上述困境,实现三大突破:
- 提出全开源的 VLM 家族(Molmo),公开权重、训练数据、代码与评估方法。
- 构建不依赖任何外部 VLM 的高质量多模态数据集(PixMo),涵盖预训练、微调所需的各类任务。
- 验证 "高质量数据 + 合理建模选择 + 优化训练流程" 足以构建媲美专有模型的开源 VLM。
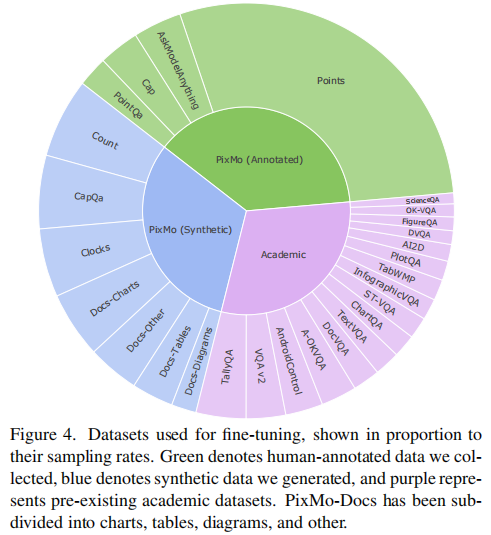
二、核心创新:PixMo 数据集 ------ 开源 VLM 的燃料
Molmo 的成功,最关键的基石是 PixMo 数据集。它包含 7 个数据集(3 个人工标注数据集 + 4 个合成数据集),所有数据均不依赖任何 VLM 生成,通过创新的数据收集方法解决了高质量标注的难题。
2.1 PixMo 数据集整体设计
PixMo 的核心设计理念是 "覆盖 VLM 全能力链路",数据集构成与对应能力如下:
| 数据集类型 | 具体数据集 | 核心用途 | 数据规模 | 关键创新 |
|---|---|---|---|---|
| 人工标注(预训练) | PixMo-Cap | 密集图像描述预训练 | 71.2 万张图像,130 万条转录本 / 描述,平均 196 词 / 描述 | 语音转文字标注,避免抄袭与低质描述 |
| 人工标注(微调) | PixMo-AskModelAnything | 自由形式图像问答 | 7.3 万张图像,16.2 万条问答对 | 人类与纯语言 LLM 交互编辑,保证回答质量 |
| 人工标注(微调) | PixMo-Points | 2D 指向与计数 | 22.3 万张图像,230 万条指向标注 + 7.9 万条指向解释 | 点标注替代边界框,大幅提升标注效率 |
| 合成数据集(微调) | PixMo-CapQA | 基于描述的问答生成 | 16.5 万张图像,21.4 万条问答对 | 纯语言 LLM 基于图像描述生成问答 |
| 合成数据集(微调) | PixMo-Docs | 文档 / 图表理解 | 25.5 万张图像,230 万条问答对 | LLM 生成代码渲染图像,覆盖图表 / 表格 / 文档 |
| 合成数据集(微调) | PixMo-Clocks | 时钟读取 | 80 万张合成时钟图像,82.6 万条示例 | 50 种表身 + 16 万种表盘,覆盖多样时间显示 |
| 合成数据集(微调) | PixMo-Count | 计数任务 | 3.6 万张训练图像,1080 张验证 / 测试图像 | 基于目标检测器生成,手动验证确保质量 |
PixMo 数据集的设计与 Molmo 模型能力的对应关系如图 1 所示:

2.2 关键数据集详细解析
2.2.1 PixMo-Cap:高质量密集描述数据集(预训练核心)
解决传统图像描述标注的三大问题:标注者仅关注少数显著元素、长文本输入耗时、可能抄袭专有 VLM 结果。
核心创新:语音转文字标注法
- 标注流程:让标注者对图像进行 60-90 秒语音描述,而非直接打字;收集音频记录作为 "未使用 VLM" 的证明;使用纯语言 LLM 整理转录文本,生成最终描述(去除口语化表达、统一风格)。
- 数据优势:描述平均长度 196 词,远超 COCO Captions(11 词)和 Localized Narratives(37 词),细节丰富度大幅提升。
- 覆盖场景:涵盖 70 + 多样主题(路标、梗图、食物、绘画、网站截图、模糊照片等),确保数据多样性。
2.2.2 PixMo-Points:2D 指向数据集(突破接地与计数能力)
这是 PixMo 最具创新性的数据集,核心解决 "语言 - 图像像素接地" 问题:
- 三大目标:
- 支持模型根据文本描述指向图像像素。
- 支持通过指向实现精确计数(逐点标记目标)。
- 支持以指向作为视觉解释(回答问题时标注关键像素)。
- 标注效率:使用点标注替代边界框或分割掩码,标注速度更快,可收集大规模数据(230 万条指向标注)。
- 数据特性:涵盖 "目标存在" 与 "目标不存在" 两种情况,支持多样化物体、表达式和场景的接地任务。
2.2.3 PixMo-AskModelAnything:自由形式问答数据集(微调核心)
为解决 "真实场景问答多样性" 问题,采用人类与纯语言 LLM 交互的标注流程:
- 标注者选择图像并提出问题。
- 运行非 VLM 的 OCR 模型和 PixMo-Cap 训练的模型,获取图像文本信息与描述。
- 纯语言 LLM 基于上述信息回答问题。
- 标注者审核答案,可拒绝并要求修改,直至满意。
- 数据价值:确保回答的高质量与准确性,覆盖真实场景中各类复杂问题(而非模板化问答)。
2.2.4 合成数据集:补充特定技能
四个合成数据集针对特定高频技能,弥补人工标注的局限性:
- PixMo-Clocks:解决时钟读取这一常见视觉任务,生成大量多样化时钟图像与时间问答。
- PixMo-Count:专注计数任务,基于目标检测器生成候选,手动验证确保计数准确性,难度高于现有 CountBenchQA。
- PixMo-Docs:通过 LLM 生成代码渲染图表、表格、文档等图像,再生成问答对,解决文档理解数据稀缺问题。
- PixMo-CapQA:基于 PixMo-Cap 的密集描述,由 LLM 生成问答对,扩充问答数据规模。
2.3 数据收集的关键创新
PixMo 之所以能在低成本下获取高质量数据,核心在于三大收集创新:
- 模态转换技巧:用语音描述替代文字输入(PixMo-Cap),提升描述细节与标注效率。
- 人机协作标注:人类主导 + 纯语言 LLM 辅助(PixMo-AskModelAnything),平衡质量与效率。
- 简化标注任务:用点标注替代复杂的边界框 / 分割掩码(PixMo-Points),降低标注门槛。
三、技术细节:Molmo 模型架构与训练流程
Molmo 采用 "视觉编码器 + 语言模型" 的标准架构,但通过一系列关键优化提升性能,同时保证训练效率。
3.1 整体架构设计
Molmo 的架构遵循 "简洁高效" 原则,由四大组件构成(如图 2 所示):
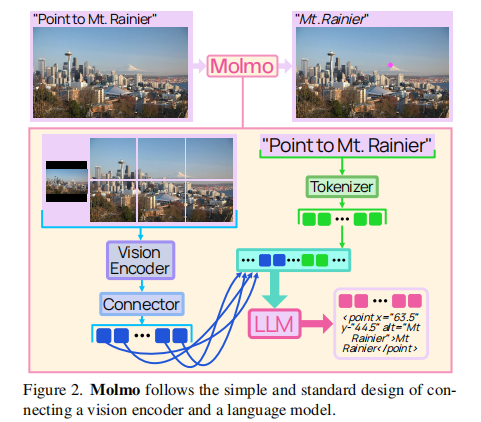
- 预处理器:将输入图像转换为多尺度、多裁剪图像(低分辨率全景图 + 高分辨率裁剪图)。
- ViT 图像编码器:独立处理每个裁剪图像,提取 patch 级特征。默认使用 OpenAI 的 ViT-L/14 336px CLIP 模型,也支持 SigLIP、MetaCLIP(全开源)。
- 视觉 - 语言连接器(Connector):将 patch 特征池化并投影到 LLM 的嵌入空间。
- 解码器 - only LLM:负责生成文本响应,支持多种基座(OLMo-7B、OLMoE-1B-7B、Qwen2 7B、Qwen2 72B)。
3.2 核心架构优化
3.2.1 多裁剪与重叠裁剪策略(解决高分辨率需求)
传统 ViT 仅支持固定分辨率的方形图像,难以满足 OCR、详细描述等细粒度任务需求。Molmo 的解决方案:
- 多裁剪:将图像分割为多个方形裁剪块(平铺图像),同时保留低分辨率全景图(提供全局上下文)。
- 重叠裁剪:解决裁剪块边界 patch 缺乏上下文的问题(如图 3 所示),让每个 patch 至少包含部分相邻 patch 的上下文;重叠区域的特征不传递给连接器,确保输出特征准确平铺高分辨率图像。

实验证明,重叠裁剪能显著提升性能,尤其对文本识别、细粒度描述等任务至关重要。
3.2.2 视觉 - 语言连接器优化
连接器的核心作用是对齐视觉与语言特征,Molmo 采用三重优化:
- 多层特征融合: concatenate ViT 的倒数第三层和倒数第十层特征,比单一层特征更有效。
- 多头注意力池化:将 2×2 patch 窗口通过多头注意力池化(以 patch 均值为查询)合并为单个向量,优于简单特征拼接。
- MLP 投影:将池化后的特征通过 MLP 映射到 LLM 的嵌入空间,确保维度匹配。
3.2.3 视觉 token 排序与特殊标记设计
视觉 token 的排序直接影响语言模型的理解效率:
- 排序规则:先低分辨率全景图的 patch,再高分辨率裁剪块的 patch(行优先顺序)。
- 特殊标记:插入起始 / 结束标记(区分低 / 高分辨率序列)、行结束标记(指示行转换),帮助 LLM 理解图像结构。
3.2.4 dropout 策略优化
针对多模态训练的特点,设计差异化 dropout:
- 仅对 LLM 应用残差 dropout,视觉编码器和连接器不使用 dropout。
- 预训练阶段(密集描述任务):仅对文本 token 应用 dropout,鼓励模型依赖图像编码而非语言先验。
- 微调阶段:不使用文本 - only dropout(避免短响应的 dropout 过度)。
3.2.5 多标注图像的高效训练
多模态数据常存在单图像多标注(如 VQA v2.0 的多问答对),Molmo 的优化方案:
- 序列合并:将单图像的所有文本标注合并为一个长序列。
- 注意力掩码:让每个标注的 token 仅关注图像 token 和自身标注的其他 token,不关注其他标注的 token。
- 性能收益:减少 2/3 的图像编码次数,训练时间缩短超过 50%,序列长度仅增加 25%。
3.3 Appendix 补充:模型架构与实现细节(§A Model Details)
3.3.1 图像编码的完整流程
论文附录详细拆解了图像从输入到 token 的转换过程(Figure 5):
- 网格选择:根据图像长宽比选择矩形网格(如 2×2、3×1),确保图像缩放后尽可能填充网格,同时不超过最大裁剪块数量(默认 13:1 个低分辨率 + 12 个高分辨率)。
- 缩放与填充:图像按比例缩放至网格尺寸,不足部分用黑色边框填充(避免拉伸变形);低分辨率裁剪块单独将图像缩放到 ViT 支持分辨率(336×336)。
- 裁剪块处理:每个裁剪块独立通过 ViT 编码,为区分填充区域与真实黑色边框,给 patch 特征添加 "无填充 / 部分填充 / 全填充" 的学习嵌入。
- Token 序列构建:按 "低分辨率 patch→高分辨率裁剪块 patch(行优先)" 排序,插入图像起始 / 结束标记、行结束标记(Figure 5 右侧),最终形成视觉 token 序列。

3.3.2 模型超参数详解(§A.2 Hyper-Parameters)
Molmo 各模型的详细超参数如表 6 所示,核心参数包括:
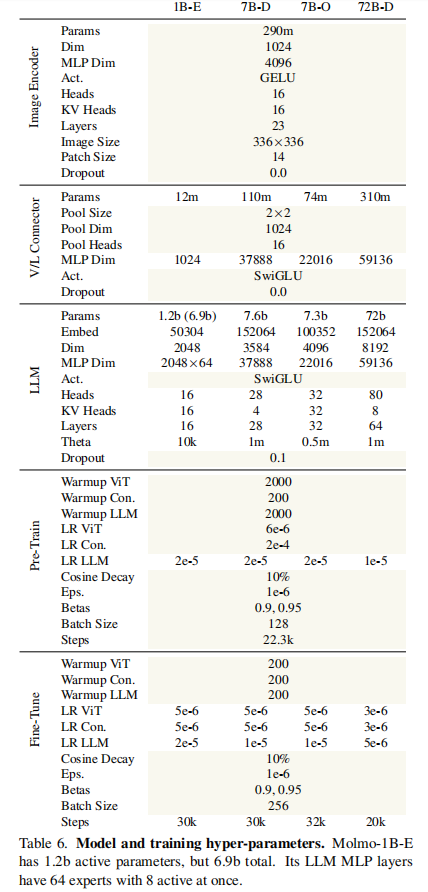
关键说明:
- MolmoE-1B 采用混合专家(MoE)结构,69 亿总参数量中仅 12 亿为活跃参数,兼顾效率与性能。
- Molmo-72B 学习率更低(LLM 5e-6)、训练步数更少(20k),因模型收敛速度更快。
- 所有模型使用余弦学习率衰减(最终为峰值的 10%),AdamW 优化器(β1=0.9,β2=0.95,ε=1e-6)。
3.3.3 实现细节与优化(§A.3 Implementation)
- 分布式训练:基于 PyTorch 的 Fully Sharded Data Parallel(FSDP),支持大规模模型(如 Molmo-72B)的训练;不使用 FlashAttention,因需支持多标注图像的复杂注意力掩码,改用 PyTorch 的 SDPA(Scaled Dot Product Attention),速度接近 FlashAttention。
- 混合精度训练:使用 PyTorch AMP 模块,大部分操作以 bfloat16 运行,但模型权重和梯度归约保留 float32(Figure 6),避免训练损失退化;层归一化和旋转位置编码(RoPE)强制用 float32 计算。
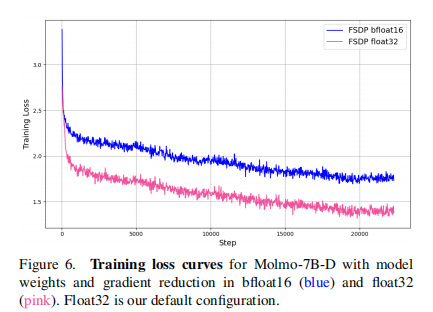
- 梯度计算优化:每个 GPU 计算小批量梯度时,按所有设备的平均损失 token 数归一化(而非单设备 token 数),避免短响应样本被过度加权(可能导致 caption 性能下降 0.5-1 个百分点)。
- 序列长度限制:预训练和微调的最大序列长度为 2304,超长样本(如 DVQA 的多标注)进行截断。
3.4 Molmo 模型家族成员
Molmo 基于不同的视觉编码器和 LLM 基座,构建了多个模型变体,保持训练数据和流程一致(仅学习率不同):
| 模型名称 | 视觉编码器 | LLM 基座 | 参数量 | 核心特点 |
|---|---|---|---|---|
| MolmoE-1B | ViT-L/14 (CLIP) | OLMoE-1B-7B(混合专家) | 12 亿(活跃)/69 亿(总) | 最高效模型,近匹配 GPT-4V 性能 |
| Molmo-7B-O | ViT-L/14 (CLIP) | OLMo-7B-1024-preview | 73 亿 | 全开源(视觉编码器 + LLM 均开源) |
| Molmo-7B-D | ViT-L/14 (CLIP) | Qwen2 7B | 76 亿 | 平衡性能与效率,介于 GPT-4V 和 GPT-4o 之间 |
| Molmo-72B | ViT-L/14 (CLIP) | Qwen2 72B | 72 亿 | 性能最佳,仅次于 GPT-4o |
| 全开源变体 | MetaCLIP(全开源) | OLMo(全开源) | - | 所有组件均开源,无任何闭源依赖 |
3.5 训练流程设计
Molmo 采用两阶段训练流程:预训练(PixMo-Cap)+ 微调(PixMo 数据集 + 开源学术数据集),并通过优化策略简化流程、提升效率。
3.5.1 预训练阶段
- 核心任务:对图像生成密集描述或音频转录本。
- 关键设计:90% 的 prompt 包含长度提示(基于文本字符数 + 噪声调整),引导模型输出合适长度的描述,提升预训练质量。
- 优化创新:无需单独的连接器微调阶段(传统方案常需此步骤),通过为连接器设置更高学习率和更短预热期,让其在预训练初期快速适应视觉 - 语言对齐。
- 训练参数:AdamW 优化器,余弦学习率衰减(最终为峰值的 10%);学习率分别为:连接器 2e-4、ViT 6e-6、LLM 2e-5;预热步数:连接器 200 步、ViT 和 LLM 2000 步;训练 4 个 epoch。
3.5.2 微调阶段
- 数据混合:PixMo 数据集 + 开源学术数据集(VQA v2.0、TextVQA、OK-VQA、ChartQA 等 18 个数据集)。
- 采样策略:按数据集大小的平方根比例采样,对大型合成数据集(如 PlotQA、FigureQA)手动降权,对指向任务大幅升权(指向任务学习速度较慢)。
- 风格标签机制:为学术数据集添加任务特定风格标签(如 "vqa2:" 前缀),让模型仅在请求时使用对应风格(避免学术数据集的短答案风格影响用户交互);PixMo 核心数据集(AskModelAnything、Points 等)不使用风格标签。
- 指向任务格式:输出 0-100 归一化的文本坐标,多目标按 "从上到下、从左到右" 编号,支持通过指向链实现计数(如图 2 所示)。
- 训练参数:学习率降低(ViT 5e-6、连接器 5e-6、LLM 1e-5/5e-6);批量大小 256;训练步数 20k-32k。
3.6 Appendix 补充:训练细节(§B Training Details)
3.6.1 预训练任务的长度提示设计(§B.1.1)
长度提示的具体生成逻辑:
- 计算转录本 / 描述的字符数,添加标准差为 25 的高斯噪声(避免模型过度依赖精确长度)。
- 将字符数除以 15 并向下取整,得到 0-100 范围内的长度提示(如 83 表示目标输出约 1245 字符)。
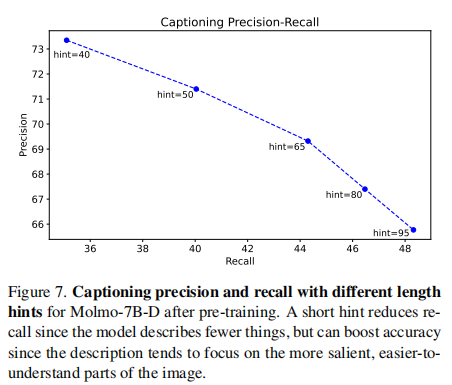
- 效果:模型能根据提示调整输出长度(Figure 7),短提示(40)提升精度但降低召回,长提示(95)提升召回但可能引入冗余;默认使用 65,平衡精度与召回。
3.6.2 微调数据集的采样比例(§B.1.2)
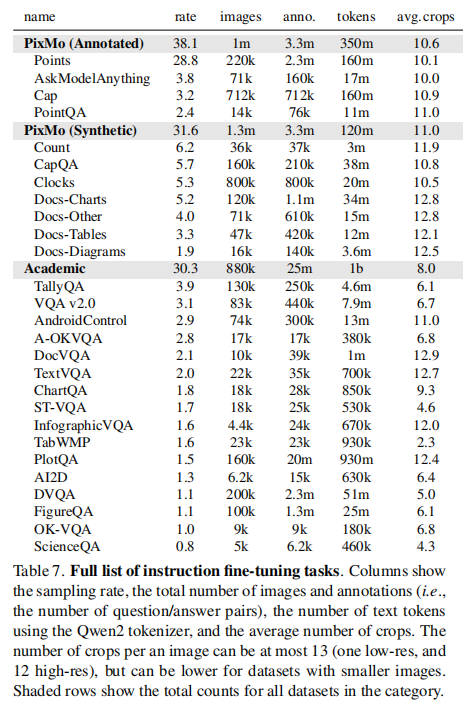
微调阶段各数据集的采样率如表 7 所示(按平方根比例调整后),核心类别占比:
- PixMo 标注数据集(Points、AskModelAnything 等):38.1%
- PixMo 合成数据集(Count、Clocks、Docs 等):31.6%
- 开源学术数据集(VQA v2.0、TextVQA 等):30.3%
- 特殊调整:指向任务采样率提升(因学习慢),大型合成数据集(如 PlotQA)采样率降低(避免噪声影响)。
3.6.3 特殊任务的格式处理(§B.2 Fine-Tuning Task Details)
-
多选题处理:在选项前添加大写字母标签(如 "A."),模型仅输出标签(如 "A");PixMo-CapQA 和 AskModelAnything 包含更复杂的多选题格式。
-
多答案处理:VQA v2.0 等数据集的多答案问题,训练时仅使用最常见答案,若有多个相同频率答案则随机选择。
-
指向格式:采用 HTML-like 格式,单指向为:
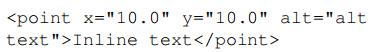
多指向为(编号确保计数清晰):
-
AI2D 任务:支持透明框和不透明框两种标注,主实验用透明框(性能更高,如 Molmo-72B 透明框 96.3% vs 不透明框 86.4%),并自建 384 张图像的验证集(原数据集无验证集)。
3.6.4 训练时间与资源消耗(§B.3 Training Time)
各模型的训练资源需求如表 8 所示(基于 H100 GPU 和 Infiniband 互联):
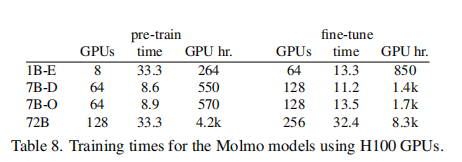
关键说明:Molmo-72B 因参数量大,预训练需 4200 GPU 小时,微调需 8300 GPU 小时,但通过混合专家(MolmoE-1B)可大幅降低资源需求。
四、实验评估:全维度验证 SOTA 性能
Molmo 的评估采用 "学术基准 + 人类评估" 双轨制,全面验证模型在各类任务上的性能,同时与专有模型和开源模型进行公平对比。
4.1 评估设置
4.1.1 学术基准
涵盖 11 个核心数据集,包括:
- 通用视觉问答:VQA v2.0、OK-VQA、A-OKVQA
- 文档 / 文本相关:DocVQA、TextVQA、ST-VQA、InfographicVQA
- 图表理解:ChartQA、PlotQA、FigureQA
- 计数专用:CountBenchQA、PixMo-Count(新增更具挑战性的计数基准)
评估时使用对应风格标签(如 VQA 任务使用 "vqa2:"),确保模型输出符合基准预期格式;Molmo 使用 36 个裁剪块评估(训练时使用 12 个),计数任务除外(保持训练 / 测试裁剪块数量一致)。
4.1.2 人类评估
- 数据规模:1.5 万条多样化图像 - 文本提示对,覆盖 10 个类别(输出格式、细粒度 QA、通用、文档、描述、计数、作业、图表、命名实体、创意)。
- 评估方式:870 名人类标注者对模型 pairwise 偏好排序,每个模型对收集约 450 条评分,总计 32.5 万条评分。
- 排名方法:使用 Bradley-Terry 模型计算 Elo 分数,反映用户偏好排序。
4.2 核心实验结果
4.2.1 学术基准性能(Table 1 关键结果)
Molmo 家族在 11 个学术基准上的表现如下(核心模型对比):
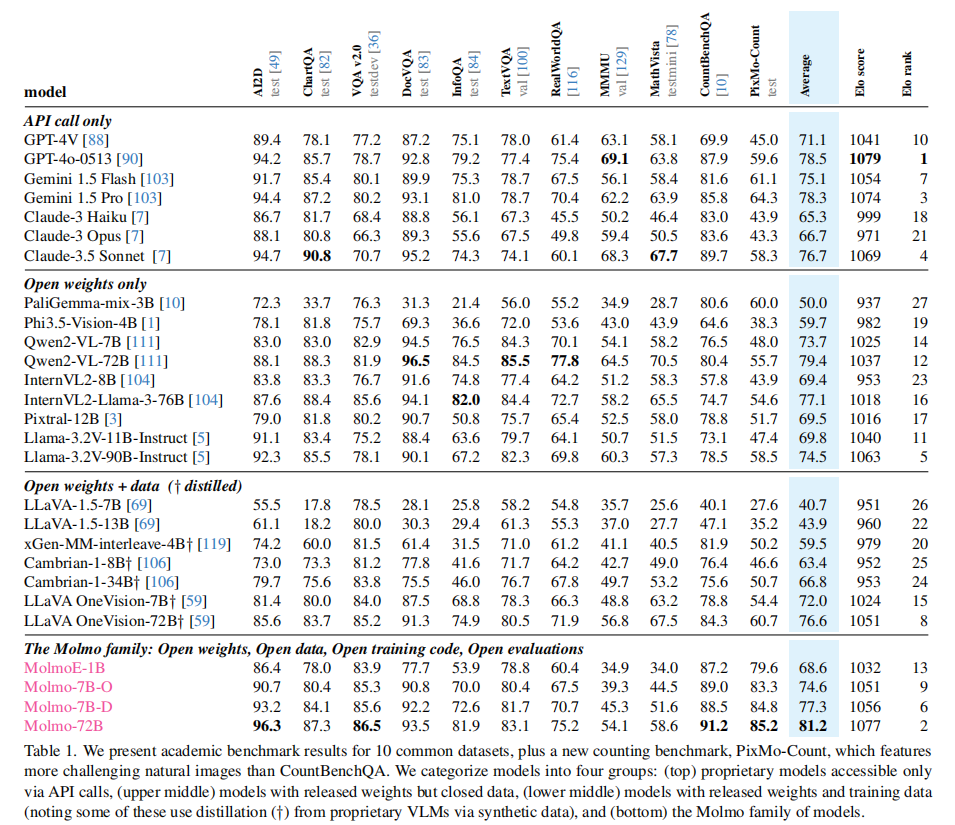
关键结论:
- Molmo-72B 在学术基准上平均准确率达 81.2%,排名第二(仅落后 GPT-4o),超越 Claude 3.5 Sonnet(76.7%)、Gemini 1.5 Pro(78.3%)等专有模型。
- 优势任务:自然图像问答(RealWorldQA 零 - shot 表现最佳)、VQA v2.0(SOTA)、计数任务(CountBenchQA 和 PixMo-Count 领先所有模型)。
- 短板任务:推理任务(MMMU、MathVista),因训练数据中缺乏高级推理相关数据。
- 效率亮点:MolmoE-1B(12 亿活跃参数)近匹配 GPT-4V 的性能,展现极高的参数效率。
4.2.2 人类评估结果
人类评估的 Elo 排名与学术基准高度一致:
- Molmo-72B Elo 分数 1077,排名第二,仅落后 GPT-4o(1079)。
- Molmo-7B-D(1056)排名第六,超越 Llama-3.2V-90B(1063)等开源模型。
- 例外情况:Qwen2-VL-72B 在学术基准上表现强劲,但人类评估中相对落后,可能因学术数据集的答案风格与用户交互需求不匹配。
4.2.3 专项能力评估
(1)计数能力

Molmo 的计数能力得益于 PixMo-Points 的指向数据,采用 "先指向后计数" 的链思维策略:
- 关键发现:"指向→计数" 策略显著优于 "仅计数" 或 "计数→指向"(CountBenchQA 准确率 89.4% vs 87.9%)。
- 排序影响:按 "从上到下、从左到右" 的有序指向训练,比无序指向性能高 12% 以上。
- 格式优化:点坐标用纯文本表示比特殊标记更有效(准确率 89.4% vs 85.8%)。
(2)时钟读取能力
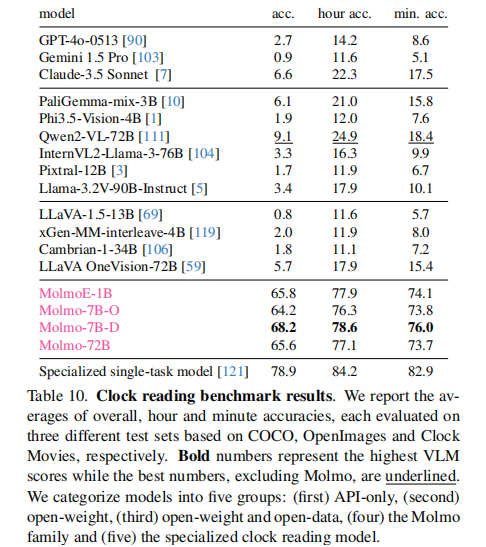
PixMo-Clocks 数据集让 Molmo 在时钟读取任务上实现碾压式优势:
- Molmo 全系列模型准确率达 64.2%-68.2%,远超其他 VLM(专有模型最高仅 9.1%,其他开源模型最高 6.6%)。
- 虽不及专用时钟读取模型(78.9%),但已展现极强的泛化能力(训练数据为合成时钟,测试数据为真实场景时钟)。
(3)指向能力
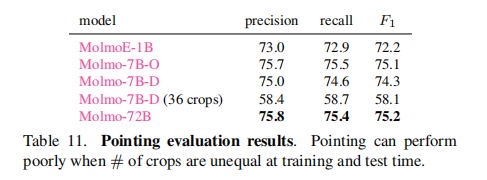
Molmo 在指向基准上的 F1 分数达 72.2%-75.2%,证明:
- 训练 / 测试裁剪块数量一致至关重要(36 裁剪块测试时 F1 降至 58.1%)。
- 点标注数据能有效支持 "语言→像素" 的接地能力,为机器人交互等下游应用奠定基础。
(4)Android 控制能力
Molmo-72B 在 AndroidControl 基准上实现 88.7% 低级别准确率和 69.0% 高级别准确率,接近专用模型的 83.2% 和 70.8%,证明其具备通过视觉指导动作的潜力。
4.3 消融实验:关键设计的有效性验证
4.3.1 模型设计消融
核心验证了六大设计的必要性:

4.3.2 数据消融

验证了 PixMo 数据的核心价值:
- PixMo-Cap 缩放:从 0 到 71.2 万张图像,cap F1 从 - 提升至 54.1,11-avg 从 74.9 提升至 76.9,证明数据规模与质量的重要性。
- 预训练数据对比:PixMo-Cap 的人工标注数据与 GPT-4o 生成的描述数据性能相当(cap F1 54.1 vs 52.9),证明高质量人工标注可媲美专有模型生成数据。
- 微调数据影响:移除 PixMo-Points(指向数据)后,11-avg 从 76.9 降至 76.2,计数任务性能显著下降;PixMo-Docs 提升文档相关任务表现。
4.3.3 计数策略消融

确认 "指向" 是计数能力的核心:
- 指向 + 计数的链思维策略最优,纯计数或计数后指向性能均下降。
- 真实点坐标 + 正确计数的组合比随机点 + 正确计数(85.9%)或随机点 + 随机计数(76.3%)性能高 10% 以上。
五、全开源生态:Molmo 的学术价值与影响
5.1 全开源链路:四大核心组件公开
Molmo 实现了真正的 "全开源",公开内容包括:
- 模型权重:所有 Molmo 变体(MolmoE-1B、Molmo-7B-O、Molmo-7B-D、Molmo-72B)的权重。
- 训练数据:完整的 PixMo 数据集(7 个数据集的所有样本)。
- 训练代码:预训练、微调的完整代码,包含所有超参数设置。
- 评估方法:学术基准评估脚本、人类评估流程与数据。
特别值得关注的是全开源变体:基于 MetaCLIP(全开源视觉编码器)和 OLMo(全开源 LLM),实现 "每一个模型组件 + 每一份训练数据" 的完全开源。
5.2 与其他 VLM 的开放性对比
Molmo 在开放性上独树一帜,对比其他 VLM 的关键差异:
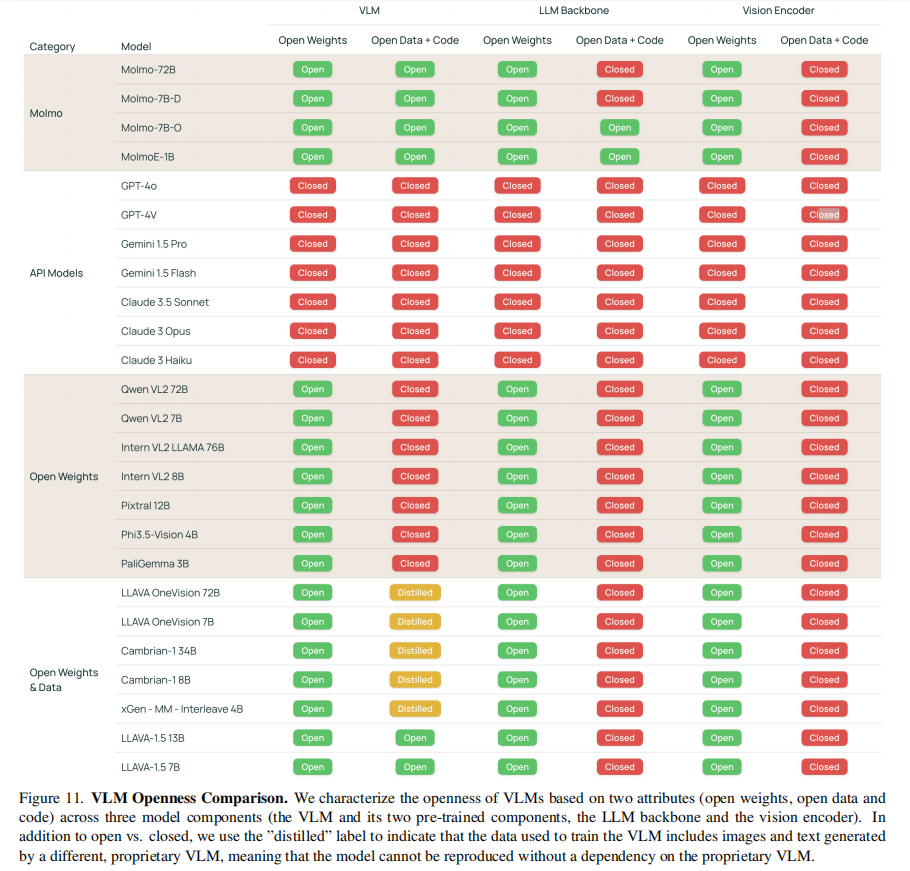
5.3 Appendix 相关工作对比(§H Related Work)
5.3.1 视觉 - 语言对比模型
- 传统模型:CLIP、ALIGN 等依赖噪声 web 数据,虽提供语言对齐的视觉编码器,但细节识别能力弱(如无法区分 "不同表盘样式")。
- 开源改进:MetaCLIP 实现全开源,但需高质量数据才能发挥性能;Molmo 结合 MetaCLIP 与 PixMo,既保持开源性,又提升细节理解能力。
5.3.2 多模态 LLM
- 现有方案:
- 蒸馏依赖型:LLaVA、InstructBLIP 等依赖 CLIP 编码器和专有 VLM 生成数据(如 ShareGPT4V),无法脱离封闭模型。
- 权重开源型:Qwen2-VL、PaliGemma 等开源权重,但数据专有,训练流程不透明。
- Molmo 创新:不依赖任何 VLM 蒸馏,通过 PixMo 数据和架构优化实现 SOTA,且全链路开源,支持科研社区追溯技术细节。
5.3.3 视觉 - 语言指令微调数据集
- 常见方法:
- 视觉模型标注 + LLM 生成:如 LLaVA 用 CLIP 标注 + GPT-4 生成问答,噪声高(如 CLIP 误判物体类别)。
- 专有 VLM 标注:如 ShareGPT4V 用 GPT-4V 生成描述,依赖封闭模型。
- PixMo 优势:人类主导 + 纯语言 LLM 辅助,平衡质量与开源性;指向数据、时钟数据等填补现有数据集空白。
5.4 学术价值:填补三大研究空白
- 方法论空白:提供了 "从零构建 SOTA VLM" 的完整方法论,证明不依赖专有 VLM 即可实现高性能。
- 数据基准空白:PixMo 为学术社区提供了高质量、全开源的多模态数据集,降低研究门槛。
- 评估标准空白:公开的评估流程与人类评估数据,为 VLM 的公平对比提供了基准。
5.5 应用前景:从科研到产业
Molmo 的开源特性使其具备广泛的应用潜力:
- 科研领域:为 VLM 的结构优化、数据增强、效率提升等研究提供基础平台。
- 产业应用:可直接部署或二次开发,适用于图像理解、视觉问答、机器人交互、文档分析等场景。
- 下游延伸:指向数据支持机器人导航、物体拾取等动作级应用;全开源特性适合隐私敏感场景(本地部署)。
六、局限与未来方向
6.1 现有局限
- 推理能力不足:在 MMMU、MathVista 等高级推理任务上仍落后于 GPT-4o,需补充高级推理数据(如数学证明、逻辑推理场景)。
- 训练成本较高:Molmo-72B 的训练需要 128 张 H100 GPU 预训练(4.2k GPU 小时)、256 张 H100 微调(8.3k GPU 小时),对学术社区仍有门槛。
- 裁剪块一致性问题:计数、指向任务对训练 / 测试裁剪块数量敏感,需额外高分辨率微调才能统一,增加训练复杂度。
- 文本 - only 任务性能下降:纯语言任务(如 MMLU)性能略低于基础 LLM(Molmo-72B MMLU 54.1% vs Qwen2 72B 58.3%),需补充文本数据优化。
6.2 未来方向
- 数据增强:增加高级推理、多图像推理、视频理解等场景的数据,弥补当前短板。
- 效率优化:
- 模型层面:探索 MoE 结构(如 MolmoE-1B)的更大规模版本,平衡性能与成本。
- 训练层面:引入参数高效微调(PEFT)技术,降低微调成本。
- 能力扩展:
- 多模态:支持音频、视频输入,实现 "图像 - 文本 - 音频" 跨模态理解。
- 长上下文:提升视觉上下文长度(如处理多页文档、长视频)。
- 下游应用:基于指向能力开发机器人交互(如导航、物体拾取)、图像编辑(如 "指出并修改图像中的错别字")等实际应用。
七、总结:开源 VLM 的里程碑
Molmo 与 PixMo 的发布,是开源视觉语言模型领域的里程碑事件。它通过 "高质量全开源数据 + 合理建模优化 + 全链路开源" 的组合,证明了不依赖任何专有 VLM,依然可以构建出媲美甚至超越多数专有模型的 SOTA VLM。
核心贡献可概括为三点:
- 数据层面:PixMo 数据集创新地解决了高质量多模态数据的收集难题,为开源 VLM 提供了可持续的燃料。
- 模型层面:通过重叠裁剪、优化连接器、差异化 dropout 等关键设计,在标准架构基础上实现性能飞跃。
- 生态层面:实现了 "权重 + 数据 + 代码 + 评估" 的全开源闭环,为科研社区提供了从零构建 SOTA VLM 的完整模板。
Molmo 的成功不仅验证了开源 VLM 的巨大潜力,更打破了 "专有模型垄断高性能" 的固有认知,为 VLM 的民主化发展奠定了坚实基础。对于科研人员和开发者而言,这不仅是一个可直接使用的模型,更是一个可探索、可修改、可扩展的研究平台,必将推动 VLM 领域的新一轮创新浪潮。