摘要
https://papers-pdfs.assets.alphaxiv.org/2510.11090v1.pdf
无源目标检测(SFOD)能够将知识从源域迁移到无监督目标域,以进行目标检测,而无需访问源数据。大多数现有的SFOD方法要么局限于传统目标检测(OD)模型(如Faster R-CNN),要么设计为通用解决方案,没有为新颖的OD架构(特别是检测变换器DETR)量身定制适配。在本文中,我们提出了特征重加权和对比学习网络(FRANCK),这是一个专为DETR执行以查询为中心的特征增强而设计的新型SFOD框架。FRANCK包含四个关键组成部分:(1)基于目标性得分的样本重加权(OSSR)模块,在多尺度编码器特征图上计算基于注意力的目标性得分,对检测损失进行重加权以强调较少被识别的区域;(2)基于匹配记忆库的对比学习(CMMB)模块,将多级特征整合到记忆库中,增强类间对比学习;(3)不确定性加权的查询融合特征蒸馏(UQFD)模块,通过预测质量重加权和查询特征融合来改进特征蒸馏;(4)具有动态教师更新间隔(DTUI)的改进自训练流程,以优化伪标签质量。通过利用这些组件,FRANCK有效地将源预训练的DETR模型适配到目标域,并增强了鲁棒性和泛化能力。在几个广泛使用的基准测试上进行的大量实验表明,我们的方法实现了最先进的性能,突显了其有效性以及与基于DETR的SFOD模型的兼容性。
索引术语---迁移学习,目标检测,无源域自适应,对比学习。
I. 引言
最先进的检测器,如Faster R-CNN 3和检测变换器4(DETR),需要大规模、高质量的标注数据以达到最佳性能。收集和标注此类数据通常昂贵且劳动密集型。此外,现实世界场景经常表现出域偏移,其中训练数据或源域分布不同于测试数据或目标域分布5。这种偏移严重降低了传统OD模型的泛化能力,这导致了对无监督域自适应目标检测(DAOD)6--17的广泛研究。大多数DAOD方法依赖于对抗性特征对齐8,10或中间域生成6,7,这两种方法都需要访问标注的源数据。然而,在实际应用中,由于隐私问题或传输限制18,源数据通常不可用。在这种情况下,传统的DAOD技术变得不可行,需要无源目标检测(SFOD)作为替代方案。
如图1所示,SFOD解决了在没有访问标注源数据的情况下的域自适应问题。相反,它仅依赖源预训练模型来适配到目标域19--26。由于源数据的缺失,大多数SFOD方法采用带有伪标签的Mean Teacher 27框架来促进适配。虽然这些方法已显示出潜力,但它们主要关注Faster R-CNN架构,利用了诸如RPNs 21,28等组件。因此,它们缺乏对适配基于DETR的模型22,24的关键见解。最近的工作23,29以及一项并行研究26已开始探索DETR的SFOD。然而,这些努力要么忽略了DETR特定的架构组件23,29,要么过度关注师生优化26,未能充分利用DETR的独特特性。为了解决这些差距,我们提出了一个面向DETR的SFOD框架,该框架有效地结合了DETR特定的设计以实现鲁棒适配。
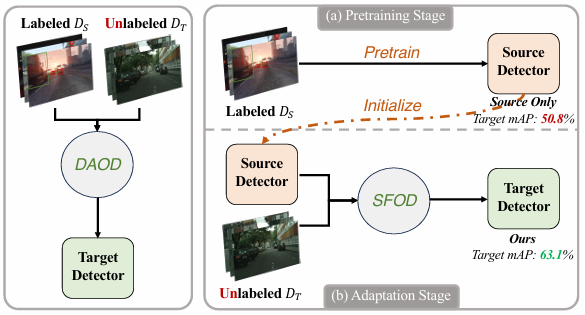
图 1. SFOD *设置示意图。左:传统的域自适应目标检测(DAOD)方法利用标注的源域 (DS)(D_{S})(DS) 和无标注的目标域 (DT)(D_{T})(DT) 将检测器迁移到目标域。右:无源目标检测(SFOD)在源数据不可用时,将源预训练模型适配到目标域。
为了解决DETR面临的无源适配挑战,我们提出了特征重加权和对比学习网络(FRANCK),一个统一的以查询为中心的框架,增强了DETR的适配能力。
我们明确地将这些挑战分解为三个相互关联的对齐层次:类别级对齐(缓解类间混淆)、实例级对齐(通过伪标签平衡和监督样本)和特征级对齐(稳定跨域特征迁移)。在这一视角的指导下,FRANCK中的每个模块直接针对一个层次,同时共享一个通用的以查询为中心的接口。CMMB通过执行带有基于匹配的记忆库的类间对比学习来增强类别级对齐,以提高查询区分度。OSSR通过基于注意力派生的目标性得分动态重加权查询损失来解决实例级对齐,缓解类别不平衡和不充分的监督。UQFD通过使用不确定性加权的查询融合掩码进行特征蒸馏来改进特征级对齐,从而实现更稳定的师生迁移。
这些模块形成了一个连贯的流程并相互促进,如图2所示。来自CMMB的更强的查询嵌入使得OSSR中的样本加权更精确;丰富的查询也指导UQFD产生更可靠的蒸馏掩码;从UQFD获得的稳定特征反馈到CMMB和OSSR。通过这种对查询表示的共同依赖,FRANCK在类别级、实例级和特征级对齐上统一了对比学习、样本重加权和特征蒸馏,从而在基于DETR的SFOD中在区分度和可迁移性方面产生了协同改进。
我们的主要贡献如下:
-
我们系统地探讨了DETR上SFOD的挑战,这是一个受到有限关注的领域,并提出了一个明确包含DETR特定架构设计的新框架。
-
我们提出了FRANCK,一个新颖的框架,引入了几个针对基于DETR的无源域自适应目标检测的关键创新。受以查询为中心的表征增强原则的驱动,这些组件协同工作,有效地将模型适配到目标域并提高检测性能。
-
我们在几个广泛使用的基准测试上进行了大量实验,证明FRANCK在DETR的SFOD中实现了最先进的性能。
本文的其余部分结构如下:第二部分全面回顾了相关工作,涵盖了目标检测(OD)、域自适应目标检测(DAOD)、无源域自适应(SFDA)和无源目标检测(SFOD)。第三部分详细介绍了提出的FRANCK框架及其关键组件。第四部分展示了实验结果,包括定量分析、消融研究和可视化实验,以及必要的实现细节。最后,第五部分总结了我们的发现并得出结论。
II. 相关工作
本节概述了与我们方法相关的研究,涵盖OD、DAOD、SFDA和SFOD。
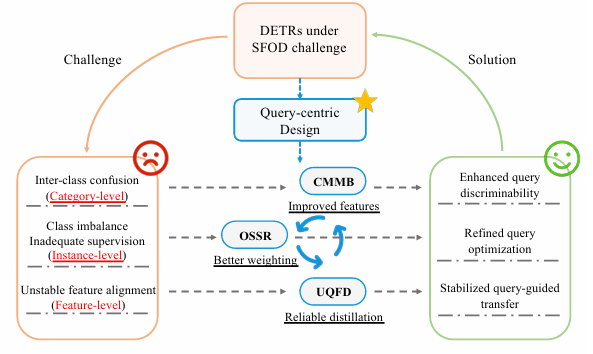
图 2. 一个概念框架,说明FRANCK如何通过统一的以查询为中心的设计解决DETR的无源挑战。这三个挑战被组织为类别级对齐(类间混淆)、实例级对齐(类别不平衡和不充分监督)和特征级对齐(不稳定的特征对齐)。每个模块(CMMB, OSSR, UQFD)针对其中一个挑战,而它们对查询表示的共同依赖形成了一个协同循环,其中改进的特征、更好的加权和可靠的蒸馏相互促进,实现鲁棒高效的适配。
A. 目标检测
目标检测(OD)旨在识别和定位图像中的物体。随着深度学习和卷积神经网络(CNN)2的兴起,OD取得了显著进展。传统方法通常分为两阶段检测器(例如,R-CNN 30,Faster R-CNN 3),它们在分类之前生成区域提议;以及单阶段检测器(例如,SSD 31,FCOS 32,YOLO 33),它们直接预测物体。虽然高效,但这些模型通常依赖于启发式组件,如非极大值抑制(NMS),使它们对超参数敏感。
基于变换器的模型通过将OD表述为一个集合预测问题重新定义了OD。DETR(检测变换器)及其变体4, 34--39消除了对NMS的需求,实现了端到端检测。诸如Deformable DETR 38和DN-DETR 37等变体改进了收敛性和鲁棒性。然而,基于DETR的模型在域偏移下通常表现不佳,并且跨域泛化能力有限1215。特别是,基于DETR的无源目标检测仍未得到充分探索。为了弥补这一差距,我们采用DETR作为基础,并研究其扩展到无源跨域目标检测。
B. 域自适应目标检测
域自适应目标检测(DAOD)旨在减轻域偏移并增强目标检测器的泛化能力。大多数DAOD研究都集中在传统检测框架上,如Faster R-CNN 40--48、FCOS811和YOLO49, 50。最近,针对DETR量身定制的DAOD方法已经出现。例如,SFA 12在编码器和解码器级别对齐特征,而MTTrans13在Mean Teacher27框架内采用多级特征对齐。其他方法,如DA-DETR 14,集成了CTBlender与Split-Merge Fusion和Scale Aggregation Fusion以更好地对齐。MTM 15利用掩码集成的对抗对齐和混合查询来确保一致学习,而BiADT 16引入了带有令牌级域嵌入的双向域对齐。类似地,ACCT 17采用对抗对齐、置信度阈值和对比学习来处理域偏移。尽管有效,但这些方法依赖于源数据和标签,使得它们在源数据不可用的情况下不适用。我们的工作通过使基于DETR的DAOD在无源设置中成为可能来解决这一限制。
C. 无源域自适应
传统的无监督域自适应(UDA)依赖于源域数据和标签,限制了其在隐私敏感场景18, 51和数据传输受限25,52下的适用性。为了解决这个问题,引入了无源域自适应(SFDA),仅使用无监督目标数据和预训练的源模型进行适配,而无需直接访问源数据。SFDA已成功应用于图像分类53, 54、语义分割55、人体姿态估计56、手势识别57和全景分割58等任务。它利用了各种模型微调策略,其中在师生框架52中的半监督知识蒸馏是一种广泛采用的方法。此外,对比学习已证明在通过学*区分性特征表示来提高泛化能力方面是有效的59, 60。
尽管SFDA在分类和分割方面取得了成功,但其直接应用于目标检测具有挑战性。与这些任务不同,目标检测需要对多个物体进行分类和定位,需要专门的架构,如Faster R-CNN 3和DETR 4。为了解决这个问题,无源目标检测(SFOD)应运而生,使得检测任务的域自适应成为可能。我们的工作将SFOD扩展到基于DETR的检测器,这是一个很大程度上未被探索的领域,增强了DETR在域偏移下的适应性。
D. 无源目标检测
为了解决目标检测中无源自适应的挑战,研究人员开发了无源目标检测(SFOD)方法。SED_19使用自熵下降和马赛克增强61提高了检测性能,而LODS 21采用风格迁移模块和多级特征对齐来最小化域差异。IRG-SFDA 20构建信息关系图以增强知识蒸馏和对比学习。AASFOD22通过蒙特卡洛采样获得的目标自划分数据上应用对抗对齐。同时,Balanced Teacher (BT) 41引入了类别平衡的实例选择和渐进式目标方差最小化以缓解不平衡问题。DACA 25通过结合区域提议融合、伪标签集成和类间对比学习将SFOD扩展到多源场景。然而,这些方法大多数要么依赖于Faster R-CNN特定组件,如区域提议网络(RPNs),要么没有考虑现代DETR架构。
值得注意的是,一些研究探索了在DETR上实现SFOD的可行性。TeST23开发了一个两阶段自训练过程,分别适配教师和学生网络,但缺乏针对DETR组件的特定设计,这些设计可能进一步提高性能。一项并行研究DRU26采用掩码图像一致性62和动态重训练更新63在DETR上实现有效的SFOD。然而,DRU26更侧重于通用的自训练和更新机制,忽略了可能进一步提高SFOD性能的有效DETR特征适配。相比之下,我们提出的方法为DETR架构精心设计,实现了高效的特征学习并提高了DETR的检测性能。
III. 提出的方法
A. 预备知识
问题设置。我们首先介绍SFOD任务的问题设置。除非另有说明,我们考虑在无监督域自适应(UDA)设置下的SFOD任务,其中目标标签完全不可用。在SFOD设置中,存在一个从源分布 pS(xS,yS)p_{S}(x_{S},y_{S})pS(xS,yS) 采样的源域 DSD_{S}DS 和一个从目标分布 pT(xT,yT)p_{T}(x_{T},y_{T})pT(xT,yT) 采样的目标域 DTD_{T}DT ,其中x表示图像,y表示相应的标签。我们遵循闭集DA设置,其中 DSD_{S}DS 和 DTD_{T}DT 都有k个前景类别。由于源数据和分布不可用于适配,只有源预训练模型 θS\theta_{S}θS 和无监督目标数据集 XT={xTi}i=1NT~X_{T}=\widetilde{\{x_{T}^{i}\}{i=1}^{N{T}}}XT={xTi}i=1NT 可用。我们的目标是执行有效的适配,获得一个在目标域上表现良好的检测模型 θT:xT→yp\theta_{T}:x_{T}\to y_{p}θT:xT→yp 。我们利用并专注于DETR4, 38结构进行检测。我们使用Deformable DETR38作为基础检测器,并将一个DETR模型中的对象查询总数表示为 nqn_{\mathbf{q}}nq 。
基于Mean Teacher的SFOD。在许多SFDA和SFOD应用中,Mean Teacher(MT)框架27是一种关键的自训练方法,可以在没有目标域监督的情况下实现模型适配13,20--22,25],26。MT最初是为半监督学习设计的,它利用强-弱增强和一致性正则化进行知识迁移。一个关键特性是其指数移动平均(EMA)更新,确保参数更新的稳定性。
在SFOD中,教师和学生模型都用相同的源预训练网络初始化。在训练期间,来自 DTD_{T}DT 的目标域样本经过强和弱增强,然后分别馈送到学生和教师网络。在没有监督的情况下,教师通过置信度阈值化弱增强样本的预测来生成伪标签。然后,学生模型通过最小化以下损失来更新其参数:
Ldet=Lcls+Lreg+Laux,\mathcal{L}{\mathrm{d e t}}=\mathcal{L}{\mathrm{c l s}}+\mathcal{L}{\mathrm{r e g}}+\mathcal{L}{\mathrm{a u x}},Ldet=Lcls+Lreg+Laux,
其中 Ldet\mathcal{L}{\mathrm{d e t}}Ldet 是DETR的检测损失,Lcls\mathcal{L}{\mathrm{c l s}}Lcls 和 Lreg\mathcal{L}{\mathrm{r e g}}Lreg 分别是分类和回归损失。Laux\mathcal{L}{\mathrm{a u x}}Laux 是辅助损失(如果适用)。遵循Deformable DETR 38,我们采用Focal Loss 64作为分类损失。学生参数 Θstu\Theta_{\mathrm{s t u}}Θstu 通过反向传播更新,而教师参数 Θtea\Theta_{\mathrm{t e a}}Θtea 遵循EMA更新:
{Θstu←Θstu+η∂(Lstu)∂Θstu,Θtea←αEMAΘtea+(1−αEMA)Θstu,\left\{\begin{aligned}&\Theta_{\mathrm{s t u}}\leftarrow\Theta_{\mathrm{s t u}}+\eta\frac{\partial(\mathcal{L}{\mathrm{s t u}})}{\partial\Theta{\mathrm{s t u}}},\\ &\Theta_{\mathrm{t e a}}\leftarrow\alpha_{\mathrm{E M A}}\Theta_{\mathrm{t e a}}+(1-\alpha_{\mathrm{E M A}})\Theta_{\mathrm{s t u}},\end{aligned}\right.⎩ ⎨ ⎧Θstu←Θstu+η∂Θstu∂(Lstu),Θtea←αEMAΘtea+(1−αEMA)Θstu,
其中η是学生的学习率,αEMA\alpha_{\mathrm{E M A}}αEMA 是EMA更新率。MT在半监督和跨域设置中提供了鲁棒的模型优化和适配,使其成为许多DAOD和SFOD方法的常见基线。
B. 概述
在本节中,我们概述了我们的问题设置、基于Mean Teacher的SFOD架构及其更新机制,以及FRANCK的关键组件。CMMB利用伪标签诱导的二分匹配构建类间记忆库进行对比学习,增强特征区分度。OSSR通过基于查询融合的目标性得分分配动态的实例级损失权重来缓解类别不平衡。UQFD通过不确定性加权的、目标性引导的特征蒸馏改进知识迁移。最后,我们介绍了总体训练损失和DTUI,它通过动态调整EMA更新间隔来增强Mean Teacher的鲁棒性。
C. 基于匹配记忆库的对比学习
虽然原始的带有伪标签的MT框架为SFOD性能奠定了坚实的基础,但特征表示仍然欠佳20, 25。为了解决这个问题,我们遵循先前的研究25,45, 65采用类间对比学习,并融合多级解码器查询特征以增强学习。此外,考虑到OD任务中的类别不平衡问题并受DETR中二分匹配的启发,我们引入了记忆库和伪二分匹配策略用于类间对比学习。
类间对比学习。对比学习通过拉近正样本和推开负样本来增强模型区分度。我们在监督对比损失(SCL)65的基础上构建我们的对比损失。假设我们有c个样本组,表示为 Ka=K0∪K1∪⋯∪\mathcal{K}{a}=\mathcal{K}{0}\cup\mathcal{K}{1}\cup\cdots\cupKa=K0∪K1∪⋯∪ Kc−1\mathcal{K}{c-1}Kc−1 ,其中每个组对应一个类别。遵循SCL,类间对比损失公式化为:
Lcont=1c∑i=0c−1−1∣Ki∣∑Q∈Ki∑K+∈Kilogexp(Q⋅K+/τ)∑K∈Kaexp(Q⋅K/τ),(3)\mathcal{L}{\mathrm{c o n t}}=\frac{1}{c}\sum{i=0}^{c-1}\frac{-1}{|\mathcal{K}{i}|}\sum{\mathcal{Q}\in\mathcal{K}{i}}\sum{K^{+}\in\mathcal{K}{i}}\log\frac{\exp(\mathcal{Q}\cdot K^{+}/\tau)}{\sum{K\in\mathcal{K}_{a}}\exp(\mathcal{Q}\cdot K/\tau)},(3)Lcont=c1i=0∑c−1∣Ki∣−1Q∈Ki∑K+∈Ki∑log∑K∈Kaexp(Q⋅K/τ)exp(Q⋅K+/τ),(3)
其中 Q\mathcal{Q}Q 是对比学习查询特征,它吸引正关键样本并排斥对比学习中的负关键样本。
查询特征融合和记忆库。对于目标检测中的对比学习,直接使用类间实例级特征作为对比样本是很直观的。然而,这可能是无效的甚至是有害的,因为(1)与Faster R-CNN通过锚点机制3, 20为每个对象生成多个对比样本不同,DETR旨在一次只分配一个查询给一个对象4;(2)现实世界的类别分布通常是不平衡的,导致显著的偏差。为了缓解这些问题,我们采用了一种简单而有效的记忆库技术25,66, 67。我们构建了 k+1k+1k+1 个记忆库 {Mi}i=0ˉk+1\{\mathcal{M}{i}\}{i=0}^{\bar{}k+1}{Mi}i=0ˉk+1 ,每个类别一个,包括一个背景记忆库 M0\mathcal{M}{0}M0 。背景特征被考虑是因为DETR将查询分配给不同的对象,并自然生成多样化的负样本,使得背景特征对于对比学习有价值。每个记忆库维护一个固定的最大大小 lMl{\mathcal{M}}lM ,并使用先进先出(FIFO)策略进行更新。非空记忆库表示为 {Mi}i=0v+1\{\mathcal{M}{i}\}{i=0}^{v+1}{Mi}i=0v+1 ,其中 M0\mathcal{M}_{0}M0 对应于背景记忆库且 v≤kv\leq kv≤k 。带有记忆库的对比损失为:
Lcont=1v∑i=1v+1−1∣Mi∣∑Q∈Mi∑K+∈Milogexp(Q⋅K+/τ)∑K∈Maexp(Q⋅K/τ),(4)\mathcal{L}{\mathrm{c o n t}}=\frac{1}{v}\sum{i=1}^{v+1}\frac{-1}{|\mathcal{M}{i}|}\sum{\mathcal{Q}\in\mathcal{M}{i}}\sum{K^{+}\in\mathcal{M}{i}}\log\frac{\exp(\mathcal{Q}\cdot K^{+}/\tau)}{\sum{K\in\mathcal{M}_{a}}\exp(\mathcal{Q}\cdot K/\tau)},(4)Lcont=v1i=1∑v+1∣Mi∣−1Q∈Mi∑K+∈Mi∑log∑K∈Maexp(Q⋅K/τ)exp(Q⋅K+/τ),(4)
其中 Ma\mathcal{M}_{a}Ma 表示所有记忆库中的样本。在方程(4)中,类别索引i从1开始,因为背景特征仅被视为负样本。为了进一步利用多尺度变换器特征中包含的语义信息,我们通过尺度求和融合了对象查询的多尺度解码器输出特征。这种策略增强了实例级特征的表示,为改进的对比学习提供了更丰富的上下文信息。
伪二分匹配分配。在SFOD的对比学习背景下,一个显著的挑战源于目标域中缺乏真实物体,这使得对比对的构建复杂化。由于DETR的集合预测机制,从主干20, 25, 45提取的基于RoI的区域特征(例如,使用RoIAlign68)与变换器和对象查询形成的实例表示解耦。因此,仅应用于主干级别的对比学习不能直接增强对象查询的区分能力,使得对象查询上的对比学习成为基于DETR方法的更合适选择。为了在对象查询上执行对比学习,一种自然的方法是选择DETR下所有 nqn_{\mathrm{q}}nq 个查询特征中的前景特征。一个直接但次优的方法是基于预测置信度过滤查询。具体来说,如果查询的最高概率对应于前景类别并且超过预定义阈值,则它被视为前景特征;否则,它被分类为背景。然而,这种方法是启发式的且缺乏鲁棒性。
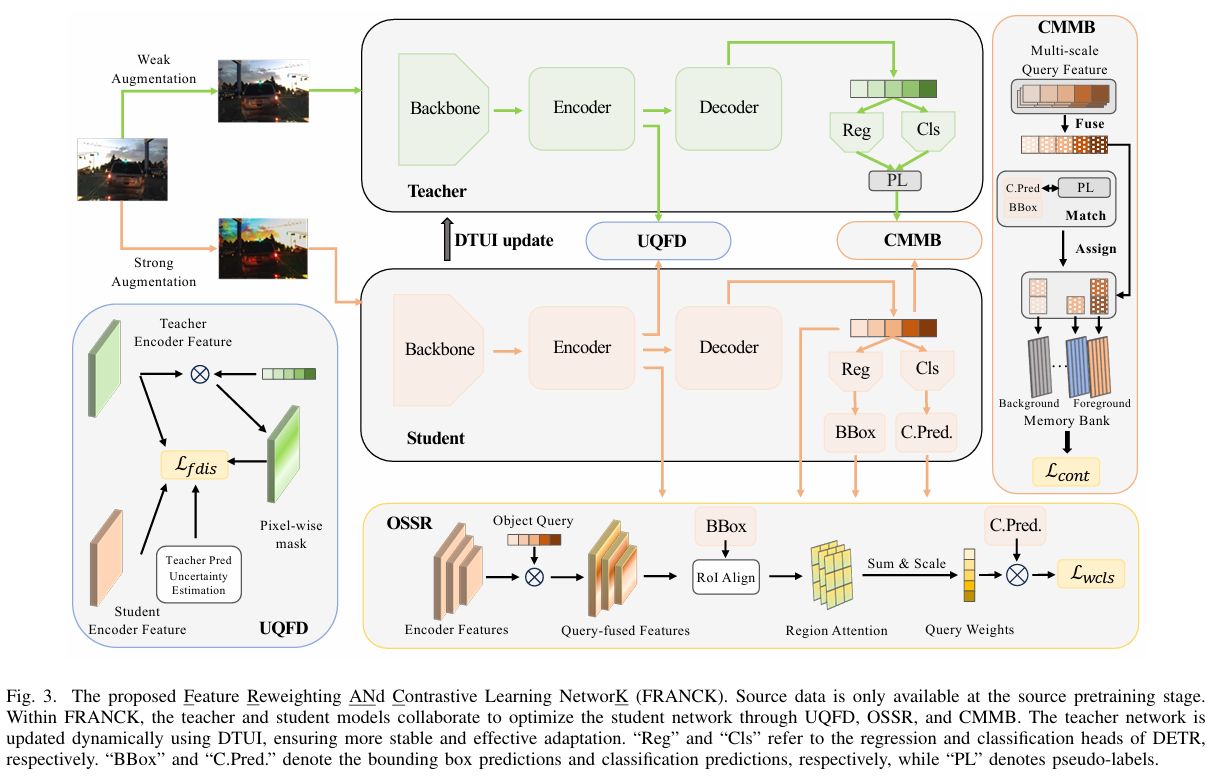
相反,我们利用二分匹配,这是DETR4中的核心分配机制之一。由于DETR通过二分匹配将查询分配给真实标签,我们将这一原则扩展到对比对构建。更具体地说,与第i个前景类别的伪标签匹配的查询直接作为前景特征,而未匹配的查询被分类为背景。这种分配策略自然地与DETR集成,并提供了更稳定和无偏的特征选择机制。为此,我们采用基于二分匹配的对比对分配,在学生查询特征和伪标签之间进行,作为构建对比对的最终策略,如图3所示。通过利用伪二分匹配和记忆库,我们在DETR的SFOD中实现了鲁棒的类间对比学习。
D. 目标性得分样本重加权
类别不平衡是目标检测任务中的常见挑战。一个常见的解决方案是软采样,即基于预测质量64,69或IoU质量0进行重加权。然而,在SFOD任务中,真实标签的缺失使得难以准确估计预测质量。
为了克服这一点,受71-73的启发,我们采用目标性得分,它利用特征图的内在特征属性。遵循这些方法,我们首先提取并归一化多尺度编码器特征 {Fei∣i=3,4,5}\{\mathcal{F}{\mathrm{e}}^{i}|i=3,4,5\}{Fei∣i=3,4,5} 和解码器查询特征 Fq,\mathcal{F}{\mathrm{q}},Fq, ,其中 Fei∈RHi×Wi×C\mathcal{F}{\mathrm{e}}^{i}\in\mathbb{R}^{H{i}\times W_{i}\times C}Fei∈RHi×Wi×C 和 Fq∈Rnq×C\mathcal{F}{\mathrm{q}}\in\mathbb{R}^{n{\mathrm{q}}\times C}Fq∈Rnq×C ,以及查询边界框 bbox ∈Rnq×4\mathbb{R}^{n_{\mathrm{q}}\times4}Rnq×4 :。为了使编码器特征聚焦于查询相关的对象信息,我们执行查询级融合和求和以获得查询融合的编码器特征 {Feqi∣i=3,4,5}\{\mathcal{F}_{\mathrm{e q}}^{i}|i=3,4,5\}{Feqi∣i=3,4,5} :
Feqi=1nq∑j=0nq−1Fei⋅FqTj,\mathcal{F}{\mathrm{e q}}^{i}=\frac{1}{n{\mathrm{q}}}\sum_{j=0}^{n_{\mathrm{q}}-1}\mathcal{F}{\mathrm{e}}^{i}\cdot\mathcal{F}{\mathrm{q}}^{T}j,Feqi=nq1j=0∑nq−1Fei⋅FqTj,
其中 Feqi∈RHi×Wi\mathcal{F}{\mathrm{e q}}^{i}\in\mathbb{R}^{H{i}\times W_{i}}Feqi∈RHi×Wi 表示跨所有 nqn_{\mathrm{q}}nq 个查询的融合编码器特征。请注意,由于Mean Teacher(MT)框架中的教师模型经历了更稳定的更新过程并与学生相比编码了更鲁棒的特征,我们利用来自教师编码器的 Fei\mathcal{F}{\mathrm{e}}^{i}Fei 来确保稳定可靠的知识迁移。一旦获得注意力图,先前的工作71, 73通常将特征图上采样到原始图像尺度,并使用近似整数坐标池化边界框特征。然而,这种朴素方法可能导致信息丢失和小物体特征提取不足,引入显著偏差。相反,我们采用RoIAlign 68,它使用双线性插值74进行精确的特征提取和信息丢失缓解。请注意,这里使用RoIAlign与我们之前在CMMB中关于其局限性的陈述并不矛盾。这里,RoIAlign被采用来提高注意力得分池化的精度,特别是在小物体的情况下,而不是通过对比学习来增强目标检测模型。因此,它作为直接池化的自然而有效的替代品。具体来说,我们应用RoIAlign从相应的查询融合编码器特征 Feqi;\mathcal{F}{\mathrm{e q}}^{i};Feqi; 中提取提议特征 Faligni\mathcal{F}_{\mathrm{a l i g n}}^{i}Faligni
Faligni=RoIAlign(Feqi,bbox),\mathcal{F}{\mathrm{a l i g n}}^{i}=\mathrm{R o I A l i g n}(\mathcal{F}{\mathrm{e q}}^{i},b b o x),Faligni=RoIAlign(Feqi,bbox),
其中 Faligni∈Rnq×Ha×Wa\mathcal{F}{\mathrm{a l i g n}}^{i}\in\mathbb{R}^{n{\mathrm{q}}\times H_{a}\times W_{a}}Faligni∈Rnq×Ha×Wa ',其中 HcH_{c}Hc 和 WaW_{a}Wa 分别表示RoIAlign输出的高度和宽度。然后每个查询被分配一个 Ha×WaH_{a}\times W_{a}Ha×Wa 的注意力得分,使我们能够计算一组目标性得分:
S={∑i=3,4,5∑Ha×WaFalignij}j=0nq−1,\mathcal{S}=\{\sum_{i=3,4,5}\sum_{H_{a}\times W_{a}}\mathcal{F}{\mathrm{a l i g n}}^{i}j\}{j=0}^{n_{\mathrm{q}}-1},S={i=3,4,5∑Ha×Wa∑Falignij}j=0nq−1,
计算出的目标性得分 S\mathcal{S}S 编码了查询级对多尺度特征的注意力。我们观察到利用所有对象查询通常会导致对容易检测的前景或背景对象具有更高的目标性注意力,这与DETRDistill 72中的发现一致。为了缓解前景-背景类别不平衡并提高模型对困难样本的区分度,我们为前景区域和具有低注意力得分的困难样本分配更高的权重。具体来说,我们使用这些归一化的权重来改进Deformable DETR 38中用于分类的原始Focal Loss 64:
Lwcls=1nq∑i=0nq−1wi−αt(1−pt)γlog(pt),(8)\mathcal{L}{\mathrm{w c l s}}=\frac{1}{n{\mathrm{q}}}\sum_{i=0}^{n_{\mathrm{q}}-1}w_{i}\left-\\alpha_{t}(1-p_{t})\^{\\gamma}\\log(p_{t})\\right,(8)Lwcls=nq1i=0∑nq−1wi−αt(1−pt)γlog(pt),(8)
和
wi=(1−MinMaxScaler(Si))β,(9)w_{i}=(1-\mathrm{M i n M a x S c a l e r}(\mathcal{S}i))^{\beta},(9)wi=(1−MinMaxScaler(Si))β,(9)
其中 MinMaxScaler r(Si)=Si−min(S)max(S)−min(S)\begin{array}{r}{\mathsf{r}(\mathcal{S}i)=\frac{\mathcal{S}i-\operatorname*{m i n}(\mathcal{S})}{\operatorname*{m a x}(\mathcal{S})-\operatorname*{m i n}(\mathcal{S})}}\end{array}r(Si)=max(S)−min(S)Si−min(S) ,且 β\betaβ 是一个平滑超参数。 αt 和 γ\gammaγ 是Focal Loss的平衡参数。通过使用基于注意力的目标性得分对查询损失进行重加权,我们的方法鼓励模型更多地关注前景区域和困难样本。这增强了在教师模型伪监督下的相互学习,并提高了模型区分度。
E. 不确定性加权的查询融合特征蒸馏
为了确保SFOD中教师和学生网络之间的鲁棒蒸馏,一致性正则化20, 25, 75是一种广泛采用的方法。然而,现有方法主要是为Faster R-CNN设计的,其中共享提议自然地对齐分类和定位得分以进行一致性正则化。相比之下,DETR采用基于查询的机制,其中不同的查询对应不同的对象,使得基于预测索引的直接一致性损失计算(例如,KL散度)不可行。例如,在大多数情况下,来自教师和学生网络的第i个预测对应不同的对象,使得直接强制执行一致性不切实际。
为了应对这一挑战,我们选择特征模仿而不是对数模仿进行知识蒸馏,这种策略在目标检测任务72, \[\],77中已被证明有效。鉴于原始Mean Teacher框架中的学生网络处理强增强图像,我们引入了这些增强图像通过教师模型的额外前向传播。此外向传播仅用于提取用于蒸馏的图像级特征。遵循DETRDistill 72,我们基于预测质量对查询融合特征进行重加权,并制定了一个统一的特征蒸馏损失,表示为 Lfdis\mathcal{L}_{\mathrm{f d i s}}Lfdis 。
不确定性基于查询加权。我们首先描述我们提取用于蒸馏的特征的方法。利用对象查询和图像级特征,我们构建了目标性加权的特征图,类似于OSSR。然而,DETRDistill 72发现朴素的目标性加权特征蒸馏是无效的,因为查询的贡献不同。为了解决这个问题,DETRDistill应用了带有从GT标签和教师预测导出的质量得分78的软注意力掩码。然而,这不适用于SFOD任务,其中GT标签不可用。为了克服这个限制,我们利用不确定性估计,使用预测熵作为质量得分。具体来说,我们从查询中提取预测得分,并计算教师模型预测的熵,表示为 E∈Rnq\mathcal{E}\in\mathbb{R}^{n_{\mathrm{q}}}E∈Rnq 。为了给由鲁棒教师模型识别的更可靠区域分配更高的权重,我们使用 Wq=(1\mathcal{W}_{\mathrm{q}}=(1Wq=(1 - MinMaxScaler (E))β′(\mathcal{E}))^{\beta^{'}}(E))β′ 对查询权重进行归一化,其中我们为简单起见设置 β′=1\beta^{'}=1β′=1 。
查询融合特征蒸馏。遵循DETRDistill,我们通过跨查询应用软掩码来计算特征蒸馏损失,并导出统一的加权损失。给定单个查询特征 Fqj\mathcal{F}{\mathrm{q}}^{j}Fqj 和最后一个编码器层特征 Fe.\mathcal{F}{\mathrm{e}}.Fe. ,我们通过以下方式导出查询融合特征 Feqj∈RH×Wˇ\mathcal{F}_{\mathrm{e q}}^{j}\in\mathbb{R}^{H\times\check{W}}Feqj∈RH×Wˇ :
Feqj=Fe⋅(Fqj)T.(10)\mathcal{F}{\mathrm{e q}}^{j}=\mathcal{F}{\mathrm{e}}\cdot(\mathcal{F}_{\mathrm{q}}^{j})^{T}.(10)Feqj=Fe⋅(Fqj)T.(10)
然后通过使用 Feqj\mathcal{F}_{\mathrm{e q}}^{j}Feqj 作为基于目标性的软掩码,我们可以通过以下方式执行加权特征模仿:
Lfdis=1nqHWC∑j=0nq−1Wqj∥Feqj⊙(FT−FS)∥22,(11)\mathcal{L}{\mathrm{f d i s}}=\frac{1}{n{\mathrm{q}}H W C}\sum_{j=0}^{n_{\mathrm{q}}-1}\mathcal{W}{\mathrm{q}}^{j}\left\|\mathcal{F}{\mathrm{e q}}^{j}\odot\left(\mathcal{F}{\mathcal{T}}-\mathcal{F}{\mathcal{S}}\right)\right\|_{2}^{2},(11)Lfdis=nqHWC1j=0∑nq−1Wqj Feqj⊙(FT−FS) 22,(11)
其中 Wqj\mathcal{W}{\mathrm{q}}^{j}Wqj 和 Feqj\mathcal{F}{\mathrm{e q}}^{j}Feqj 分别表示 Wq\mathcal{W}{\mathrm{q}}Wq 和查询融合特征的第 jjj 个元素。FT\mathcal{F}{\mathcal{T}}FT 和 FS\mathcal{F}_{\mathcal{S}}FS 分别表示教师和学生模型的最后一个编码器层特征,⊙\odot⊙ 表示哈达玛积。通过结合加权特征蒸馏,教师指导学生生成更稳定的特征表示,提高了知识迁移的鲁棒性。
F. 动态教师更新间隔
为了增强传统的Mean Teacher自训练方法,我们引入了一种改进的更新机制,称为动态教师更新间隔(DTUI)。如第III-A节所述,我们采用Mean Teacher框架以确保鲁棒高效的适配方案。具体来说,在执行教师和学生网络的前向传播之后,我们首先通过将0.3的置信度阈值应用于教师的预测来过滤伪标签。然后我们计算总损失函数如下:
Ltotal=Lwcls+Lreg+Laux+ω1Lcont+ω2Lfdis,(12)\mathcal{L}{t o t a l}=\mathcal{L}{\mathrm{w c l s}}+\mathcal{L}{\mathrm{r e g}}+\mathcal{L}{\mathrm{a u x}}+\omega_{1}\mathcal{L}{\mathrm{c o n t}}+\omega{2}\mathcal{L}_{\mathrm{f d i s}},(12)Ltotal=Lwcls+Lreg+Laux+ω1Lcont+ω2Lfdis,(12)
其中 Lwcls, Lreg,\mathcal{L}{\mathrm{w c l s}},\;\mathcal{L}{\mathrm{r e g}},Lwcls,Lreg, 和 Laux\mathcal{L}{\mathrm{a u x}}Laux 共同构成检测损失 Ldet\mathcal{L}{\mathrm{d e t}}Ldet ;通过用方程(8)替换原始分类损失。然后使用 Ltotal\mathcal{L}_{t o t a l}Ltotal 优化学生模型,而教师模型使用带有动量因子αEMA的EMA进行更新:
DTUI。在SFOD任务中,域偏移和真实标签的缺失可能使学生模型的预测和优化不稳定,导致有偏的教师更新并降低相互学习的有效性25, 63。为了缓解这个问题,AASFOD22和DACA25为每个实验采用固定的EMA更新间隔,这虽然有用但忽略了随时间推移的适配进度。相比之下,我们提出了一个动态EMA间隔 iEMA,公式化为:
iEMA=δ+⌊e/ϵ⌋,(13)i_{\mathrm{E M A}}=\delta+\lfloor e/\epsilon\rfloor,(13)iEMA=δ+⌊e/ϵ⌋,(13)
其中 δ 是一个控制稳定知识积累步数的基础间隔,e 表示当前周期索引,ϵ 表示增加率。在这种动态策略下,虽然学生网络在每次迭代时使用方程(2a)更新,但教师网络每 iEMA 次迭代更新一次。这种线性间隔调整允许在适配的早期阶段频繁进行参数探索,促进参数空间的有效搜索,并随着训练的进行逐渐稳定模型的更新。
IV. 实验
本节介绍了数据集、实验设置、实验结果以及来自定量、消融和可视化研究的全面分析,以验证我们的方法。
A. 数据集
我们在四个广泛使用的目标检测数据集上评估我们的方法:Cityscapes81、Foggy_Cityscapes 82、Sim10k83和BDD100K84,以及一个合成的雨天Cityscapes数据集。我们的实验涵盖了跨天气、合成到真实和跨场景自适应。
跨天气自适应。Cityscapes 81是一个城市场景数据集,包含来自不同城市的2,975张训练图像和500张验证图像。Foggy Cityscapes 82通过合成雾生成扩展了它。我们使用Cityscapes及其雾化变体(雾密度为0.02)分别作为源域和目标域。为了进一步评估在恶劣天气下的鲁棒性,我们使用RainMix85引入了Cityscapes的雨天版本,遵循先前的工作79, 86,使得能够跨不同天气条件进行评估79, 87, 88。
合成到真实自适应。Sim10k 83从GTA V游戏生成,包含9,000张训练图像和1,000张验证图像。在此设置中,Sim10k是源域,Cityscapes是目标域。此设置评估了从合成数据泛化到真实数据分布的能力,提供了诸如降低数据收集成本和增强现实世界场景中数据多样性等好处。
跨场景自适应。BDD100K_84是一个大规模自动驾驶数据集,涵盖了一天中的不同时间。遵循先前的工作12, 13, 26,我们仅使用白天图像,包括_36,728张训练图像和5,258张验证图像。在此设置中,Cityscapes用作源域,BDD100K白天用作目标域。这评估了检测模型跨不同场景的适应性。
跨数据集自适应。KITTI89是一个从多样化现实世界场景收集的自动驾驶数据集。在我们的设置中,来自KITTI的所有7,481张标注图像用作源域,而Cityscapes作为目标域。此设置评估检测模型跨不同相机系统和数据集特征的适应能力。
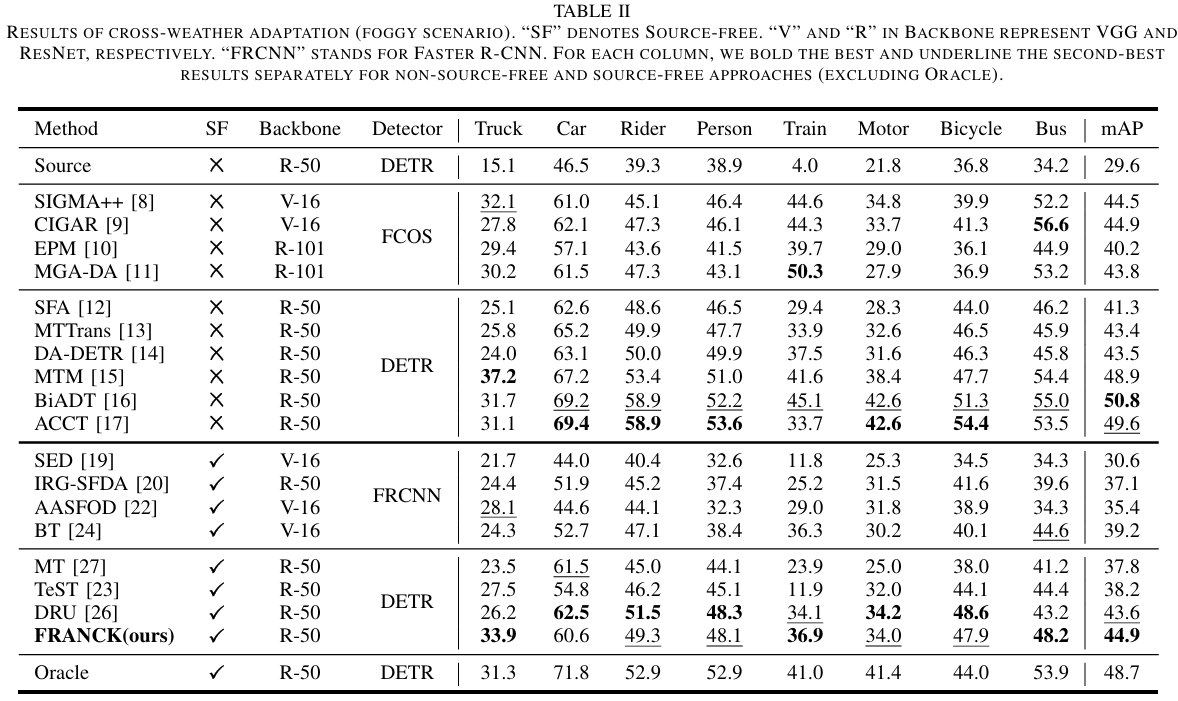
表 III
跨天气自适应结果(雨天场景)。"SF"表示无源。"V"和"R"在主干中分别表示VGG和ResNet。"FRCNN"代表Faster R-CNN。对于每一列,我们分别对非无源和无源方法(不包括Oracle)加粗最佳结果并下划线次佳结果。
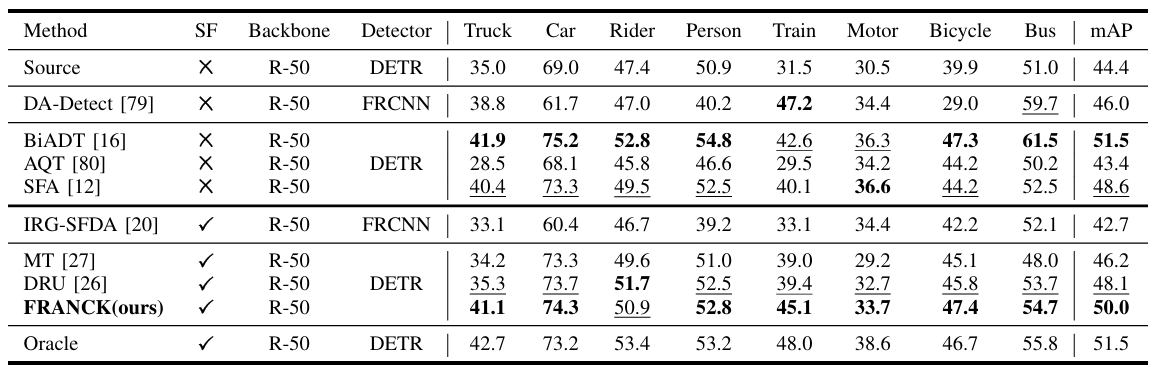
表 IV
合成到真实自适应结果。"SF"表示无源。"V"和"R"在主干中分别表示VGG和ResNet。"FRCNN"代表Faster R-CNN。对于每一列,我们分别对非无源和无源方法(不包括Oracle)加粗最佳结果并下划线次佳结果。
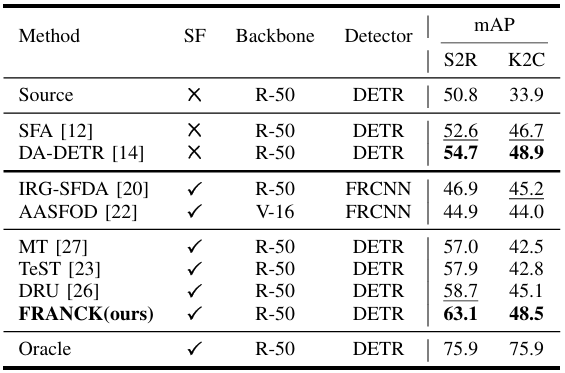
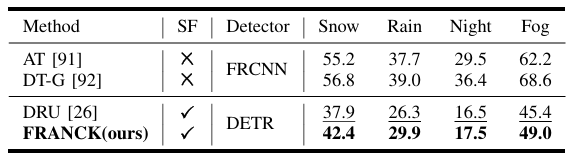
Cityscapes到ACDC自适应。ACDC90是一个为自动驾驶场景的全面理解设计的数据集。它包含了四种具有挑战性的现实世界天气条件,包括雪、雨、夜晚和雾。此自适应设置用于进一步评估我们的方法在多样化和复杂的现实世界域偏移下的有效性和鲁棒性。
B. 基线
我们将我们的方法与多个基线设置进行比较,包括仅源、DAOD、SFOD和Oracle。
仅源。对于仅源基线,源预训练模型直接在目标域上评估而不进行适配,作为域自适应的下限。
DAOD。我们将我们的方法与先前的基于DETR的DAOD方法进行比较,包括SFA12、MTTrans13、DA-DETR14、MTM15、BiADT16和ACCT17。其中,只有BiADT使用DAB-Deformable-DETR 36,这是Deformable DETR_38的一个变体,作为其基础检测器,而所有其他方法都采用Deformable_ DETR。此外,我们还与基于不同检测器的方法进行比较,包括SIGMA++ 8、CIGAR9、EPM 10和MGADA 11。这些比较提供了关于DETR上DAOD性能的见解,并突出了我们方法的优势。
SFOD。我们包括基于DETR的SFOD方法,如TeST23和并行工作DRU26。由于TeST不是开源的,我们实现并复现了它,并调整超参数以获得最佳结果。DA-DETR29由于与普通Mean Teacher相似而被省略,我们为此进行了单独实验。鉴于基于DETR的SFOD工作数量有限,我们还与基于Faster R-CNN的SFOD方法进行比较,包括SED19、IRGSFDA 20、AASFOD22和BT24。
Oracle。对于Oracle基线,模型直接在标注的目标域上训练和测试,没有源预训练,在某种程度上代表了DAOD的上限。
遵循先前的工作,检测性能使用平均精度(mAP)和IoU=0.5进行评估。从表II到表IV,我们使用R-50和R-101来指代ResNet-50和ResNet-1012,V-16来指代VGG-1693网络。我们的比较包括基于FCOS32、DETR 4, 38和Faster RCNN (FRCNN) 3的方法。值得注意的是,除了采用DAB-Deformable DETR36(这是Deformable_ DETR38的一个变体)的BiADT 16之外,我们研究中的所有基于DETR的方法都建立在Deformable DETR 38之上。
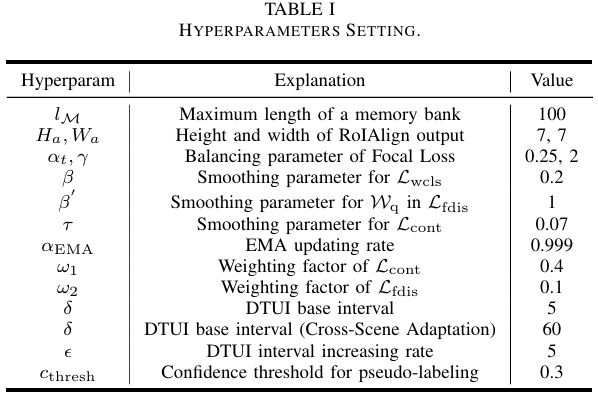
C. 实现细节
在本节中,我们提供了实验的实现细节。超参数及其符号、描述和值总结在表I中。在源预训练阶段,我们训练模型50个周期,初始学习率为 2×10−42\times10^{-4}2×10−4 ,在40个周期后减少0.1倍。在适配阶段,模型以固定的学习率训练30个周期
表 V
跨场景自适应结果。"SF"表示无源。"V"和"R"在主干中分别表示VGG和ResNet。"FRCNN"代表Faster R-CNN。对于每一列,我们分别对非无源和无源方法(不包括Oracle)加粗最佳结果并下划线次佳结果。
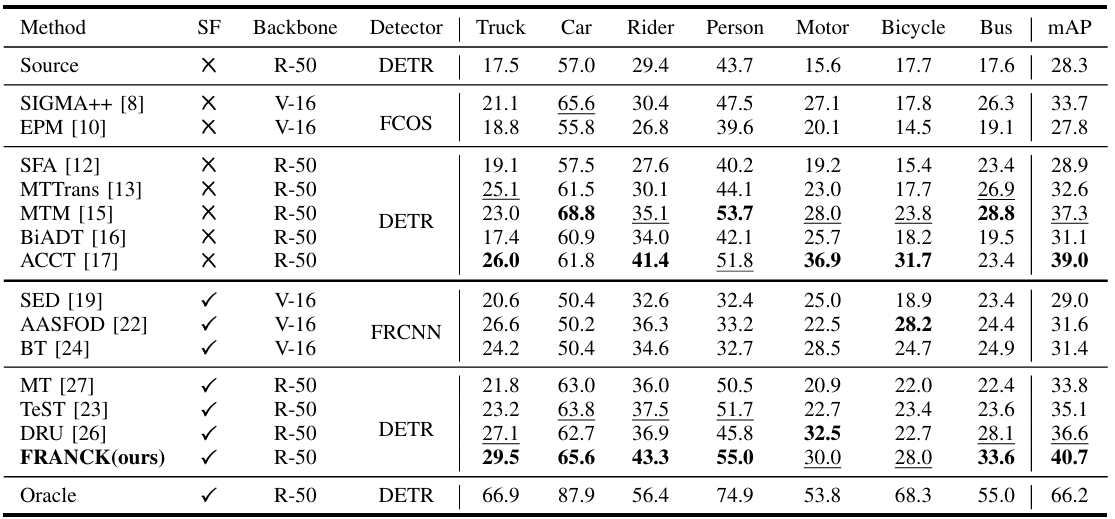
表 VI
Cityscapes到ACDC自适应在四种不同天气条件下的结果。"SF"表示无源。"FRCNN"代表Faster R-CNN。我们对无源方法加粗最佳结果并下划线次佳结果。
为 5×10−55\times10^{-5}5×10−5 '。所有实验使用每GPU 2的批大小,在4个NVIDIA RTX 4090 GPU上进行训练。
D. 与最先进技术的比较
在本节中,我们展示了与最先进方法的定量比较。结果总结在表II、表III、表IV、表V和表VI中,最佳mAP(%)值和次佳mAP值(不包括Oracle结果)分别加粗和下划线。我们的方法在多个域自适应设置中实现了最先进的结果。在跨天气自适应中,它在Cityscapes到Foggy Cityscapes上达到44.9 mAP,表明即使物体可见性严重降低,模型仍然保持鲁棒并有效克服域偏移,并在雨天条件下达到50 mAP。在合成到真实自适应中,它达到63.1 mAP,展示了从经济高效的合成数据到复杂真实场景的强大可迁移性。在Cityscapes到ACDC自适应中,它在所有天气条件下都超过了DRU,增益从1.0到4.6 mAP,证实了其处理多样化环境的能力。在跨场景和跨数据集自适应中,它分别达到40.7 mAP和48.5 mAP,进一步证明了其在不同位置和数据源之间的鲁棒性。
E. 消融研究
在本节中,我们提出了几个消融研究来评估我们方法的设计和有效性。除非指定,否则我们在跨天气设置下的Cityscapes到Foggy Cityscapes自适应上进行所有消融研究。
组件消融。我们通过比较有和没有每个组件的性能来评估不同组件的影响。如表IX所示,消融结果表明(1)Mean Teacher策略和动态MT更新间隔通过增强鲁棒训练和知识蒸馏提高了SFOD性能,以及(2)提出的方法,包括CMMB、OSSR和UQfD,各自对最终检测性能有贡献,基于带有DTUI的Mean Teacher,仅增加28.5%的训练时间就带来了3.2 mAP的增益。
跨主干的有效性。虽然我们的主要实验使用ResNet-50,但我们进一步评估了基于变换器的主干,包括ViT-Base94和不同尺度的Swin Transformers 95---Swin-T(微小)、Swin-S_(小)、Swin-B(基础)和Swin-L_(大)。如表VII所示,普通ViT由于单尺度、低分辨率特征96整体表现更差,但趋势保持一致:(1)域偏移导致所有主干的性能类似下降,SFOD方法有效缓解了这个问题;(2)我们的方法在测试的每个主干上都持续超过MT 27和DRU 26,突出了其鲁棒性以及跨不同特征提取器的泛化能力。
跨DETR变体的有效性。由于我们的主要实验基于Deformable DETR38,我们进一步
表 VII
不同主干的性能比较。我们使用Deformable DETR作为基础检测器。我们分别对每个主干加粗最佳结果并下划线次佳结果。
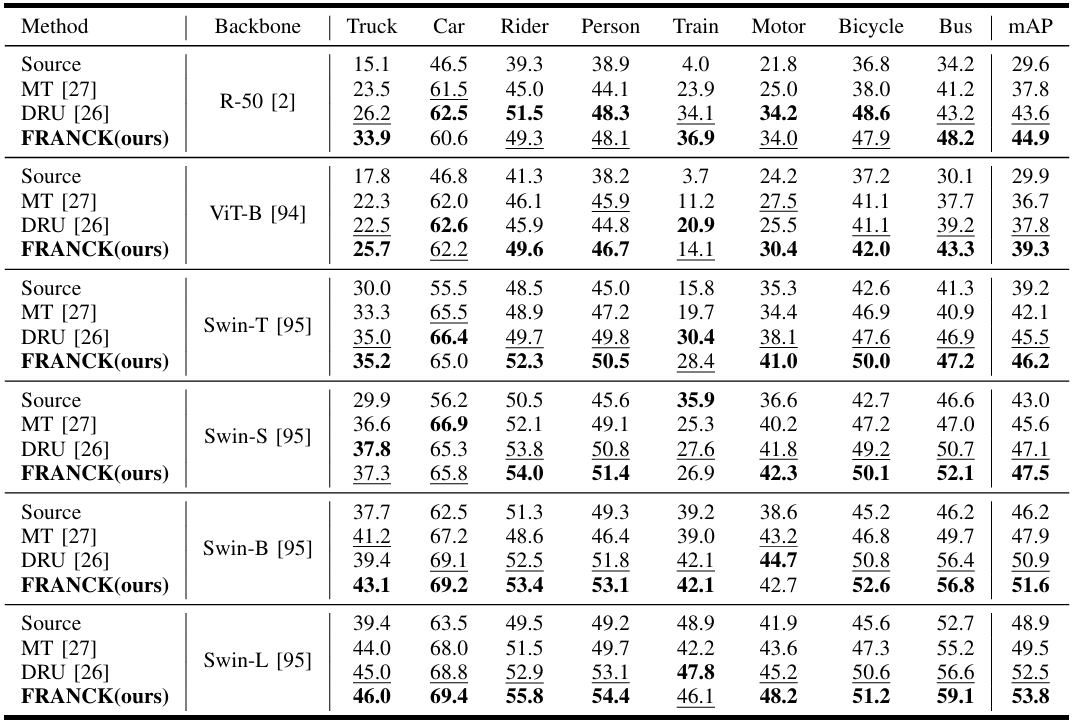
表 VIII
不同DETR变体的性能比较。我们使用ResNet-50作为主干。我们分别对每种检测器加粗最佳结果并下划线次佳结果。

超参数敏感性。为了评估所提出组件的鲁棒性,我们对几个关键超参数进行了敏感性分析:(1)ωi和ω2,它们平衡了额外损失,(2)β和β′,它们分别控制了基于查询的样本重加权和特征蒸馏的权重。如图5所示,所提出的方法对这些超参数的小变化表现出强大的鲁棒性,进一步验证了其有效性。
对比对构建策略性能和噪声鲁棒性。我们评估了CMMB中的两种对比对构建策略:阈值和匹配。对于阈值,我们首先通过基于IoU的分配将学生预测与教师伪标签关联,然后使用学生置信度阈值过滤匹配的对。对于匹配,我们改为在学生和教师输出之间执行全局一对一二分分配。如图4©所示,阈值策略在阈值0.3/0.6/0.8下产生43.7/44.4/44.3的mAP,而匹配达到44.9。这表明依赖学生置信度会引入来自不稳定预测的偏差,而带有教师指导的二分匹配导致更可靠的对比对。我们通过注入标签噪声进一步测试鲁棒性,如图4(d)所示。在10%噪声下,两者保持接近(44.7 vs. 44.5),但当噪声上升到70%时,阈值降至42.1,而匹配保持在43.3。这表明匈牙利匹配的全局分配减轻了错误标记样本的影响并保持了更纯净的记忆库,而局部阈值允许更多噪声条目进入。

图 4. 消融研究的实验结果:(a) 不同特征对目标性估计的影响。(b) 不同编码器特征融合层的影响。(c) CMMB中阈值化和匹配的比较。(d) CMMB中受控噪声水平的影响。(e) 记忆库(MB)大小的影响。(f) 记忆库(MB)组成的影响,包括先进先出(FIFO)、随机替换(RR)和中心引导替换(CGR)。

图 5. 超参数敏感性分析。我们说明了四个关键超参数的敏感性:ω1, ω2, β, β′, ϵ, 和 c_{\\mathrm{t h r e s h}}(置信度阈值)。每个图显示了在调整单个超参数同时保持其他超参数固定时的性能变化。这些超参数的定义在表I中提供。
动态MT更新。最近的几项研究探索了基于不确定性估计的动态教师更新,利用了诸如对数方差(Var)26、预测熵(Ent)63和软邻域密度(SND)63, 97等技术。为了进一步研究这一点,我们进行了一项消融研究,比较了三种不同的更新策略:
- 固定间隔。教师在恒定迭代后更新,元间隔定义更新周期。
- 基于不确定性的更新(Var, Ent, SND)。当不确定性度量减少时发生更新,元间隔作为最大间隔,遵循DRU 26。
- 提出的DTUI。提出的更新机制,其中元间隔对应于方程(13)中的δ。
遵循先前的工作26,我们为基于不确定性的更新(Var, Ent, SND)设置元间隔为5。如表X所示,DTUI和基于不确定性的策略都优于普通Mean Teacher,其中DTUI产生最佳结果。然而,除非与像DRU的学生重训练26这样的技术结合,否则基于不确定性的方法显示出有限的增益,可能是由于DETR中嘈杂的背景查询和不稳定的提议。我们还观察到过大或过小的间隔提供最小的好处,突出了在DTUI中平衡更新频率的重要性。此外,图5(e)显示DTUI对控制间隔增长的小变化ϵ具有鲁棒性。只有当ϵ太大(例如,2)时,性能才会下降,延迟了必要的教师更新。
目标性估计策略。为了评估OSSR在不同目标性估计策略下的优越性,我们进行了一项消融研究,比较了以下方法:
- Backbone:仅使用主干特征。
- E:仅使用编码器特征。
- E+AQ:使用与分配查询融合的编码器特征(即,通过二分匹配与伪标签匹配的查询)。
- E+Q\mathbf{E}\mathbf{+}\mathbf{Q}E+Q :使用与所有查询融合的编码器特征。
如图4(a)所示,当使用与分配查询融合的编码器特征(E+AQ)时,实现了最高性能。这一结果突出了目标性估计和查询融合特征加权的有效性。此外,这些定量发现补充了图7中的可视化结果,进一步验证了我们方法的影响。
伪标签阈值。我们还对伪标签阈值 cthreshc_{\mathrm{t h r e s h}}cthresh 1进行了消融研究,该阈值在我们的主要实验中设置为0.3。如图5(f)所示,过低和过高的阈值都会导致次优的检测性能,而大约0.3的阈值产生最佳结果。这一发现与DRU 26一致,后者也为基于DETR的伪标签使用0.3阈值。
CMMB中的记忆库。我们对记忆库大小和更新策略都进行了消融。大小范围从0(禁用记忆库)到每类几个容量,更新策略包括FIFO、随机替换(RR)和中心引导替换(CGR),其中新特征替换离当前类中心最远的条目。如
表 IX
组件分析消融研究。报告的Time表示每次迭代处理时间,∆Time表示相对于MT+DTUI基线的相对增加。
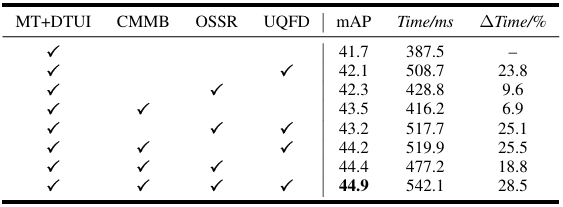
表 X
动态MT(Mean Teacher)更新分析消融研究。"VAR"、"ENT"和"SND"分别表示对数方差、预测熵和软邻域密度,如第IV-E节所述。MI表示元间隔。

图4(e)和(f)所示,中等大小(大约100-200个条目)给出最佳mAP,而非常小或非常大的大小略微降低性能。在更新策略中,FIFO表现最佳,RR和CGR产生略低的结果。这些发现表明,平衡的记忆大小和稳定的FIFO更新为CMMB中的对比学习提供了最有效的组成。
多尺度编码器特征融合。为了评估OSSR中多尺度编码器特征融合的影响,我们使用第3、4、5层对不同的融合策略进行了消融研究。我们实验了融合来自单个层以及多个层的特征。如图4©所示,(1)基于较低层编码器特征的重加权导致次优性能,因为它们强调高级语义而非对象级注意力。虽然将第5层与其他层融合仅产生边际增益,但它证实了多层融合比单层提供更全面的特征,最终增强了整体性能。
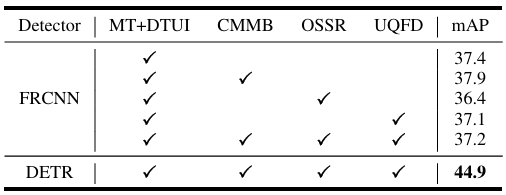
跨不同检测器的有效性。为了进一步说明DETR特定设计,我们通过用RoI和主干特征替换查询和编码器特征,直接将我们的方法迁移到Faster R-CNN3。如表XI所示,与DETR上的明显改进相比,这些模块仅带来边际甚至降低的增益。这源于我们的DETR特定设计:OSSR和UQFD依赖于查询-编码器融合的目标性,而RoI特征缺乏DETR查询的全局语义上下文,削弱了监督和蒸馏;CMMB也表现不佳,因为它是围绕可学习查询而不是局部RoI构建的。此外,对数千个RPN提议进行匈牙利匹配会产生额外的成本和不稳定性。这些发现强调了我们方法的以查询为中心的性质,并表明未来工作的一个有希望的方向是泛化基于DETR的SFOD的关键思想和设计,以便它们可以有效地适配到更广泛的检测器架构。
表 XI
不同检测器上不同模块组合的消融研究。
F. 可视化研究
为了进一步说明我们方法的有效性,我们在本节中提出了一个可视化研究。
检测结果可视化。为了展示有效的域自适应,我们可视化了来自三个设置的检测结果:(1)仅源,(2)FRANCK,和(3)真实标签。如图6所示,我们的方法显著改善了目标域中的物体定位和分类,减少了误报并提高了检测质量。
物体注意力可视化。为了说明查询融合目标性得分对编码器特征的影响,我们比较了OSSR目标性注意力生成方法,包括 "E"\text{"}\mathbf{E}\text{"}"E" 、E+AQ\mathbf{E}+\mathbf{A}\mathbf{Q}E+AQ 和 E+Q\mathbf{E}+\mathbf{Q}E+Q ,如前所述。为了更好地可视化权重分布,我们还从1中减去了 \`\`\\mathbf{E}+\\mathbf{Q}'' 的缩放注意力得分,因为方程(9)为低注意力得分分配高权重。
如图7所示,域偏移通常导致编码器特征过度关注背景区域。查询融合通过将注意力重新导向物体来缓解这个问题,其中 ''E+AQ′′``\mathrm{E}+\mathrm{AQ}''''E+AQ′′ 显示出最大的改进。然而,平等对待所有查询("E+Q")可能会抑制对前景和难以检测物体的注意力,这与DETRDistill 72中的发现一致。我们的重加权策略通过为未被充分识别的区域分配更高的权重来纠正这一点,解决了前景-背景和简单-困难样本不平衡问题。这提高了特征区分度,如图4(a)进一步验证。
G. 局限性
虽然我们的方法实现了最先进的性能,但它有局限性,指出了未来的方向。首先,尽管较低的置信度阈值在各种场景下表现良好,但在精度关键的情况下可能表现不佳。动态阈值,从低开始以挖掘潜在物体,然后增加以提高精度,可以更好地平衡召回率和精度。其次,随着视觉基础模型(VFM)如CLIP 98的兴起,结合VFM引导的线索(例如,用于细化记忆库样本的文本-图像相似性)可以进一步增强对比学习,特别是对于计算约束较少的应用。
V. 结论
在本文中,我们解决了无源域自适应目标检测(SFOD)的挑战,特别关注将源预训练的DETR网络适配到目标域

图 6. 适配前后的检测结果和真实标签的可视化。从上到下:仅源结果、FRANCK结果和真实标签。我们在此实验中展示了跨天气自适应结果和合成到真实自适应结果。

图 7. 使用不同策略的物体注意力可视化。"E"仅使用编码器特征,"E+AQ"使用编码器特征和分配查询特征的融合,"E+Q"使用编码器特征和所有查询特征的融合。在所提出的方法中,我们为低E+Q注意力得分分配高权重,反之亦然。
而无需访问源数据。为此,我们提出了FRANCK,一个新颖的框架,通过结合四个关键组件充分利用DETR特定特征:(1)基于目标性得分的样本重加权(OSSR)模块,(2)基于匹配记忆库的对比学习(CMMB)模块,(3)不确定性加权的查询融合特征蒸馏(UQFD)模块,和(4)具有动态教师更新间隔(DTUI)的增强自训练流程。我们的方法实现了最先进的性能,在多个广泛使用的基准测试上超越了先前的SFOD方法。对于未来的工作,我们旨在将我们的框架扩展到更现实的场景,例如多源自适应。我们希望这项工作为推进DAOD和SFOD提供宝贵的见解和灵感,进一步为更广泛的研究社区做出贡献。