近日,Google 与 DeepMind 联手推出旗下旗舰级别模型 "Gemini 3"------这不仅是一款语言模型的更新,更是一次人工智能理解与交互方式的全面升级。
在多模态理解、深度推理、跨任务协同等关键能力上,Gemini 3 实现了质的飞跃。
无论你是想用一句话生成图像、通过语音描述分析视频,还是借助 AI 助手完成深度专业任务,Gemini 3 都让「想 就 能 做」从概念变为现实。
对内容创作者、企业用户、开发者平台而言,这意味着我们进入了一个「AI 不只是工具,而是智囊」的新阶段。
亮点速览
- 突破性的推理能力:Gemini 3 在多个标准评测中大幅领先上一代,体现出更强的逻辑思维与结构化问题解决能力。
- 真正的多模态理解:它不仅能处理文本,还可同时理解图像、音频、视频;在复杂场景下能感知背景与意图,从而做出更精准响应。
- 面向每一个使用场景:开发者、企业、创作者、普通用户都能受益------在搜索、应用、IDE、生产工具中都可见其身影。
- 接入即用/可扩展:通过 Google AI Studio、Vertex AI 等平台即可接入,同时也在 Google 生态产品端同步上线。
文生图演示
提示词:航空发动机3D图,细节要用英文标注
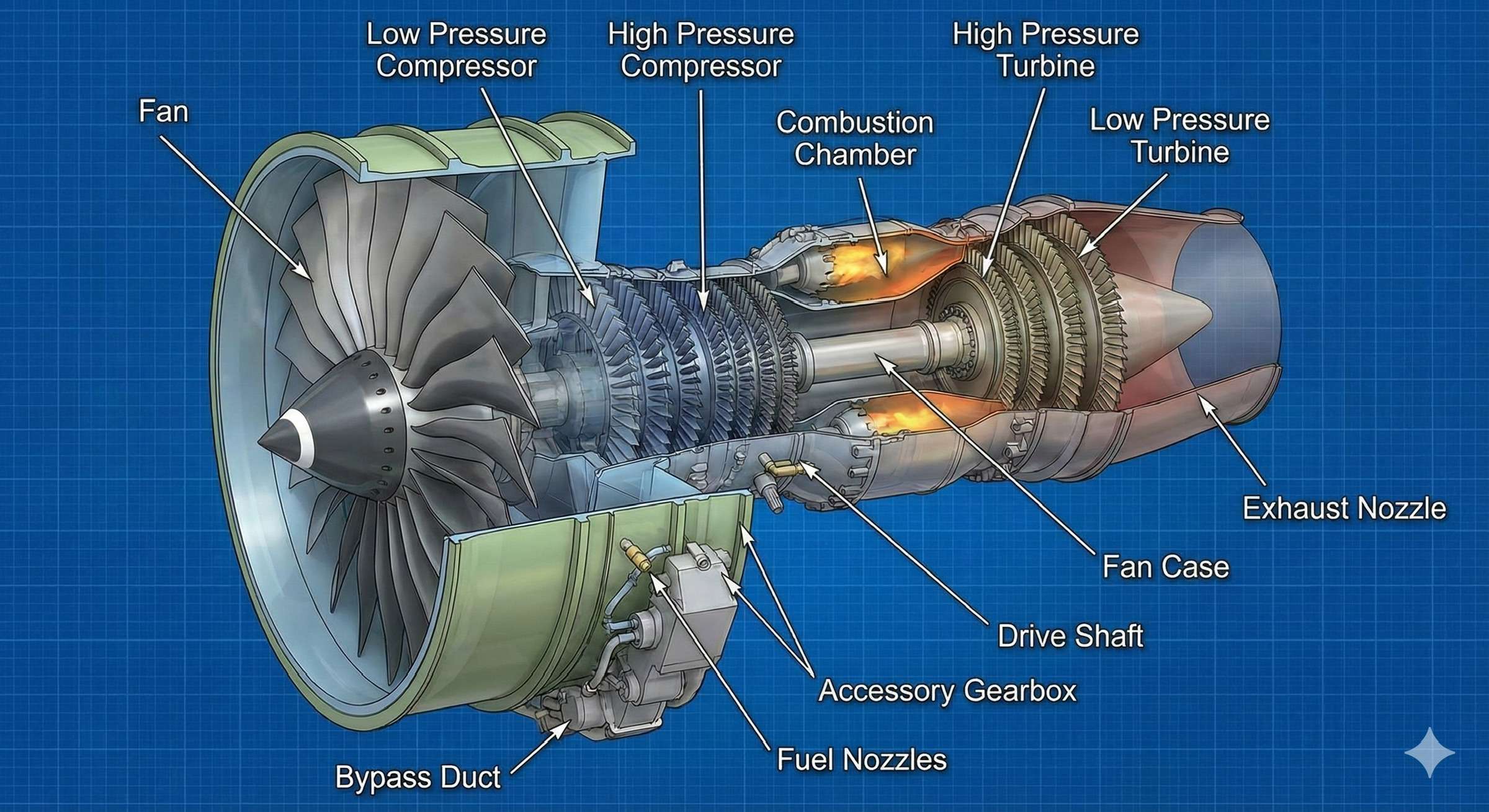
提示词:解释整架飞机的各个部位,用英文标注细节

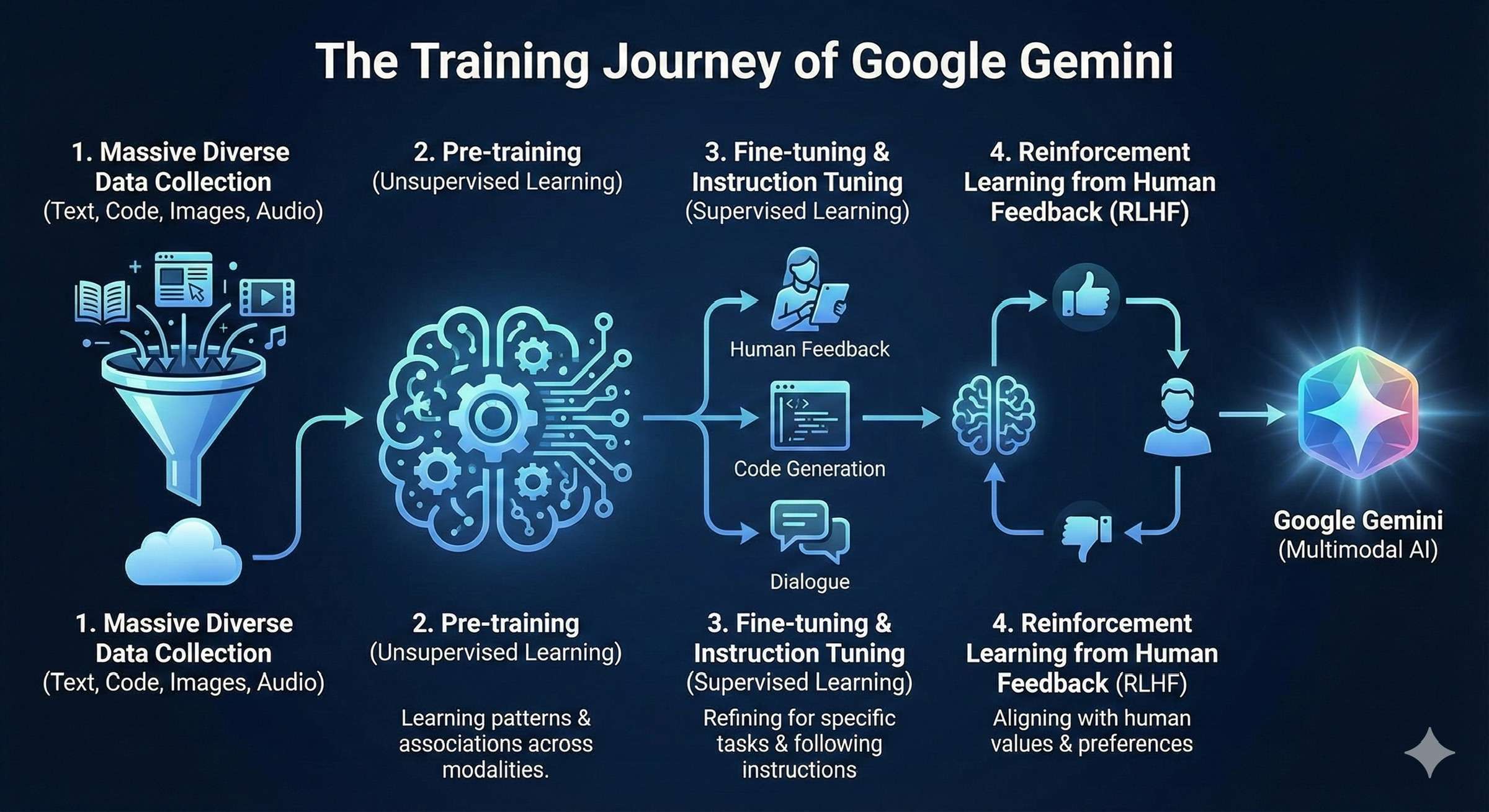
提示词:解释 Google gimini 这个大模型是怎么训练出来的
提示词:展示 iPhone 从第一代到最新历史发展

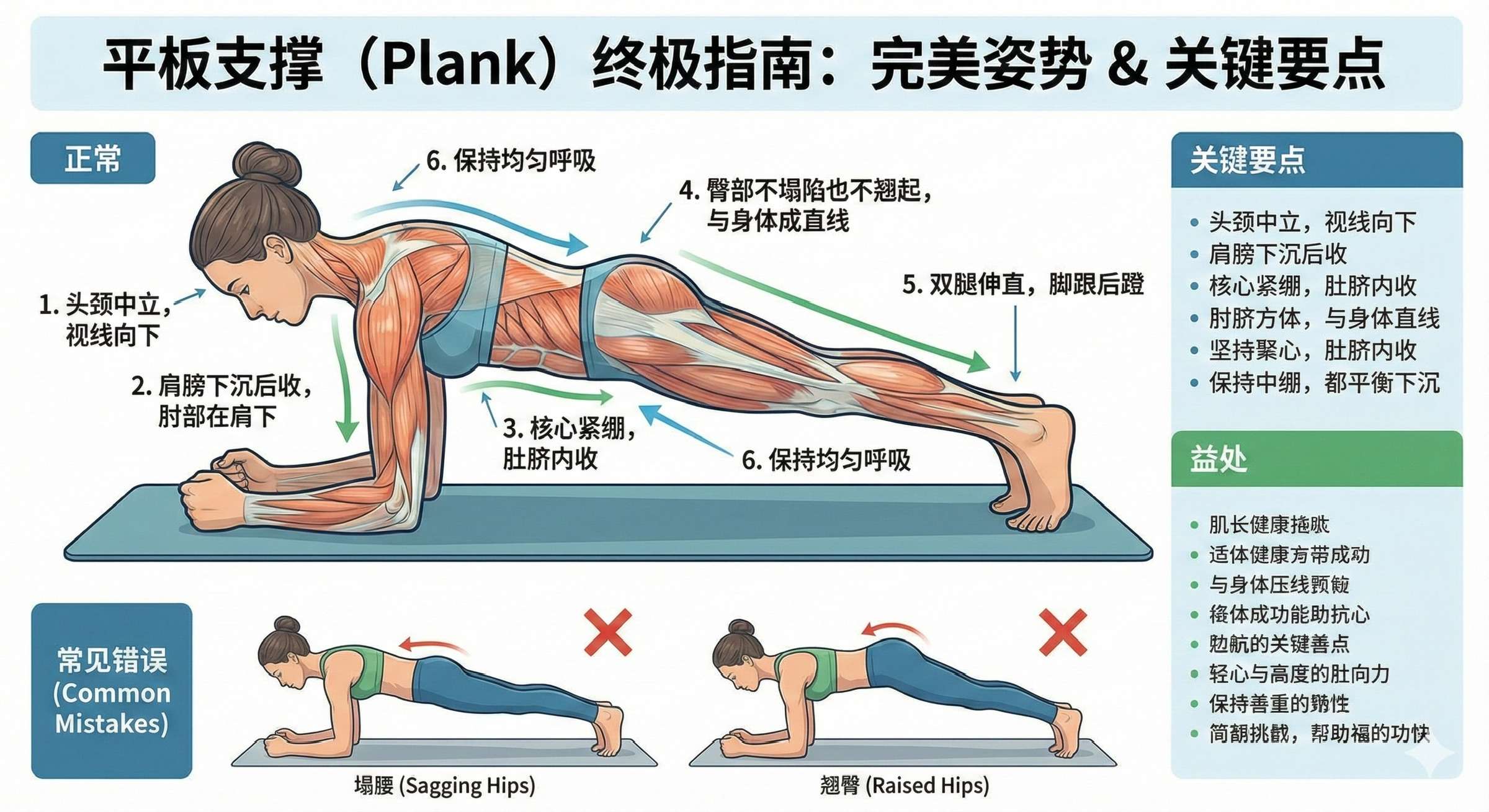
提示词:教我怎么做平板支撑
提示词:教我做"干锅土豆片",要用手账的形式

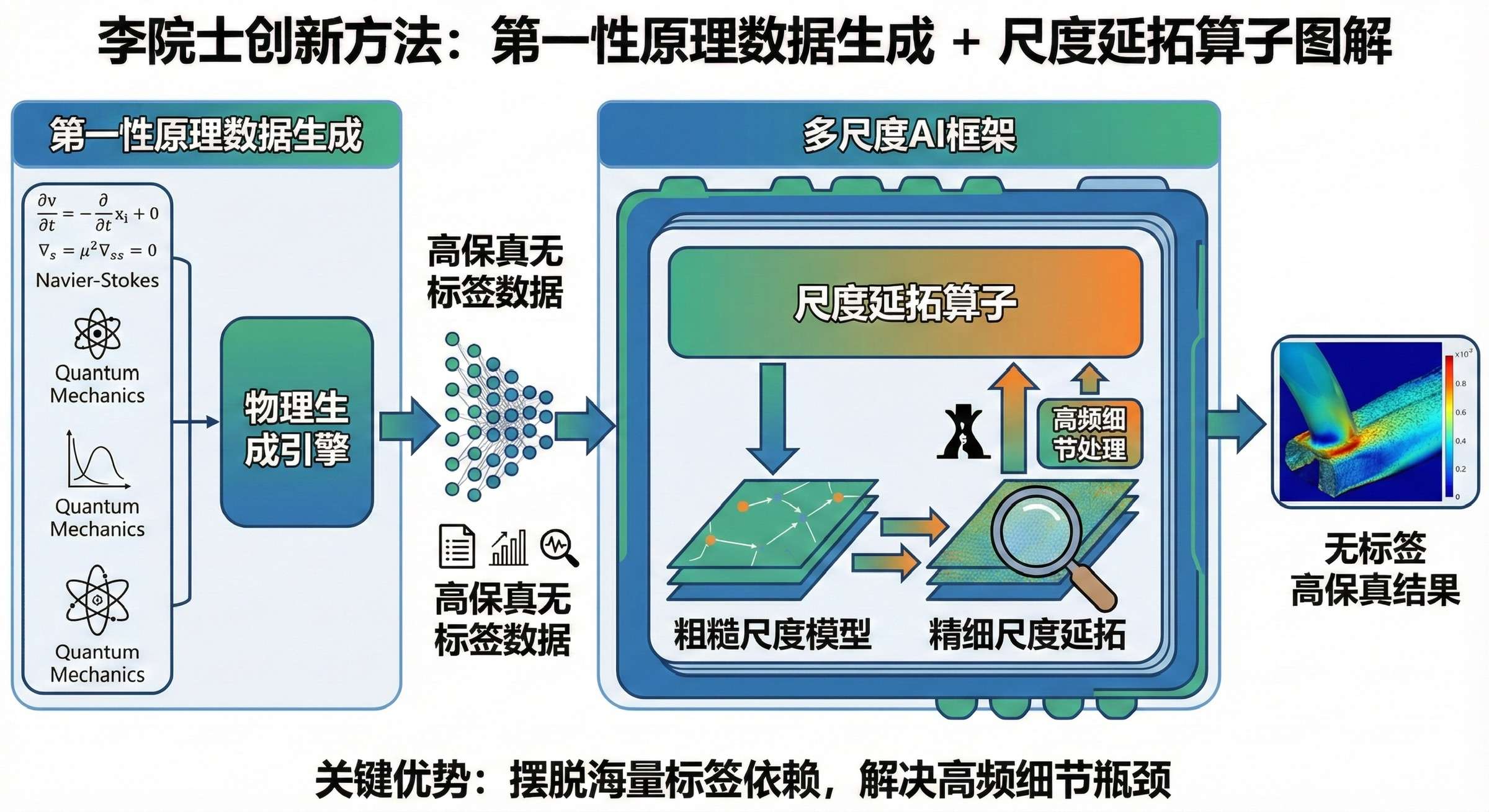
提示词:李院士在报告中提出"用第一性原理生成数据+尺度延拓算(不再依赖海量标签,也不再被高频细节卡脖子)"的创新性方法,用一张图解释上面的方法
提示词:解释内容分发网络的原理并用英文标注细节,学术论文格式
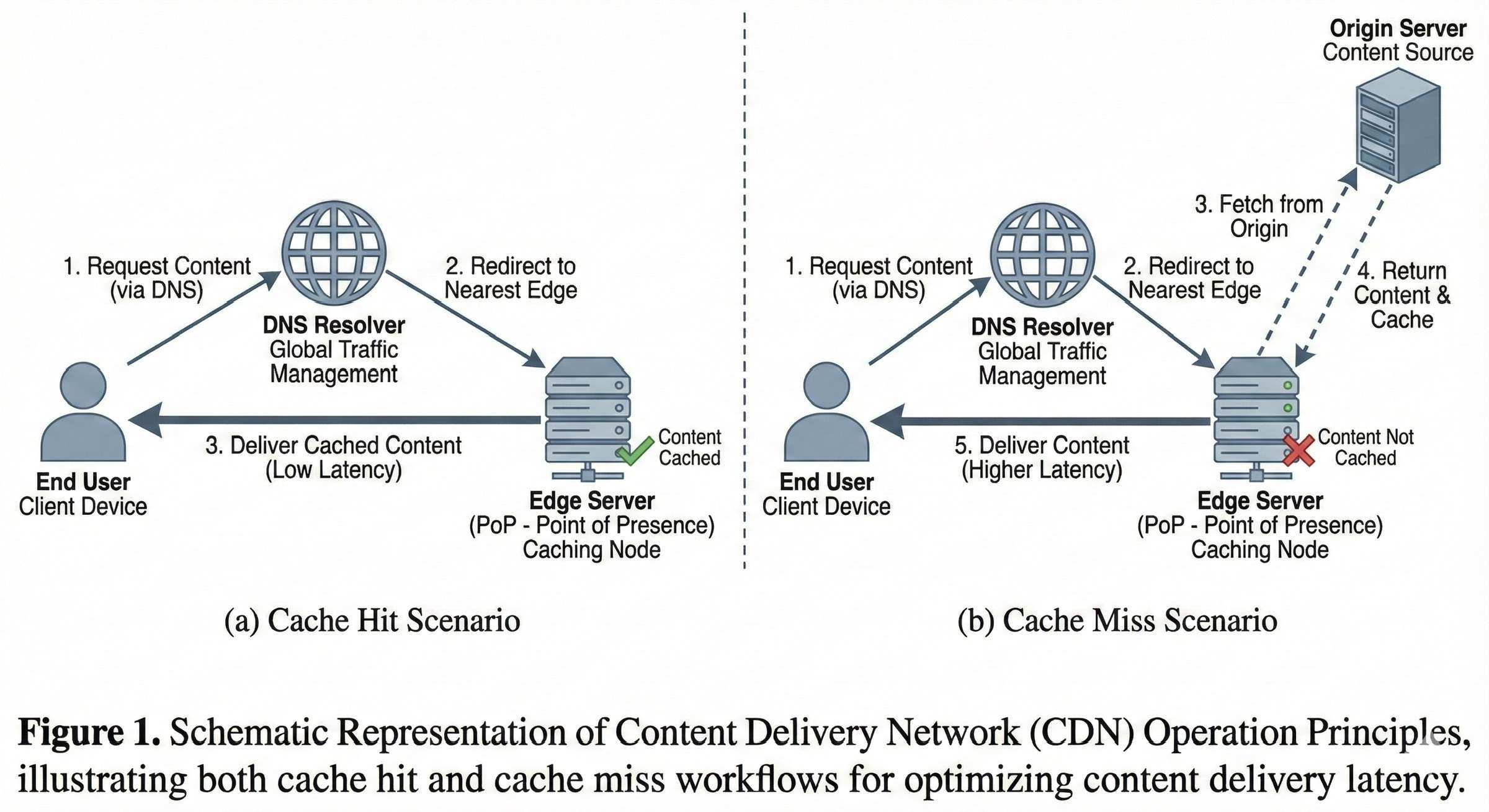
为什么值得关注
在「一句话生成图」、「一段语音化图像理解」、「跨媒介任务协作」成为趋势的今天,Gemini 3 不仅是技术升级,更是一种使用体验的革命。
AI 从"你问我答"走向"你说我做",这一变化将深刻影响内容生产、创意设计、教育培训、商业流程等方方面面。
回顾以上演示中生成的系列图像,可以看出 AI 大模型在视觉创作领域近乎"全能"的惊人实力。
从精准的专业标注到多样的艺术风格切换,AI大模型证明了其在各个领域赋能内容创作的强大潜力,让想象力落地变得前所未有的简单和震撼。
用 AI 探索无限可能,展示科技与创意的碰撞。