BERT(Bidirectional Encoder Representations from Transformers)是 Google 于 2018 年提出的双向编码器架构,彻底变革了自然语言处理(NLP)领域。本文深入分析了 BERT 在核心 NLP 任务中的学术潜力与核心优势。BERT 通过创新的掩码语言模型(MLM)预训练策略,实现了真正意义上的双向语境理解 ,能够同时利用左右上下文信息学习语言表示。实验数据证明,BERT 在 11 项 NLP 任务 中取得了突破性成果:将 GLUE 基准分数提升至 80.5% (绝对提升 7.7%),MultiNLI 准确率达到 86.7% (绝对提升 4.6%),SQuAD v1.1 问答 F1 分数达到 93.2 (绝对提升 1.5 分),甚至在 SQuAD v1.1 上超越了人类表现。BERT 的双向性设计在处理一词多义、上下文依赖等复杂语言现象时具有显著优势。BERT 推动了 NLP 领域向"预训练 + 微调"的范式转变,超过 10,000 篇论文对其进行了扩展研究,确立了其作为 NLP 发展史上里程碑模型的地位。
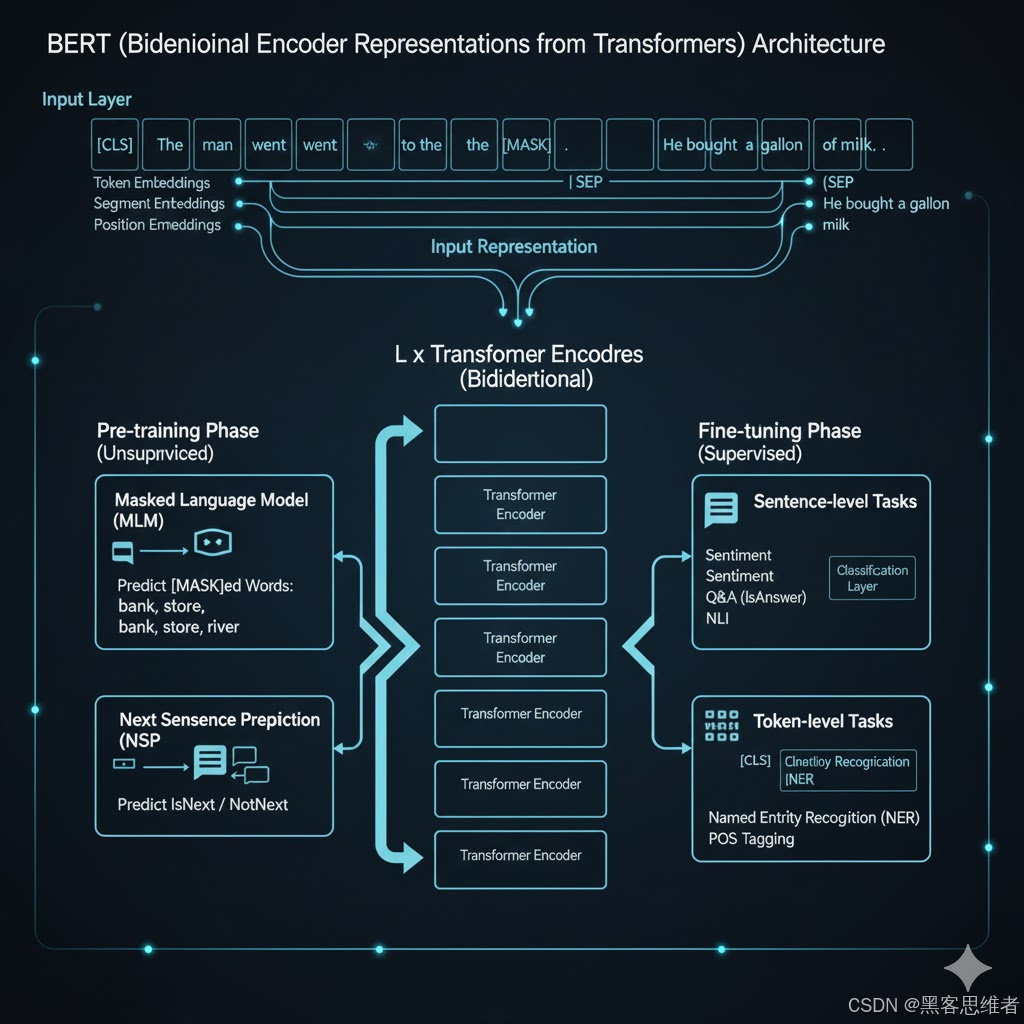
从单向序列到深度双向理解的范式革命
自然语言处理(NLP)的核心挑战在于机器对人类语言的深度理解。传统的 RNN、LSTM 等序列模型受限于单向性,难以充分捕捉语言的完整上下文依赖关系。2018 年,Google 提出的 BERT 模型,基于 Transformer 的双向编码器架构,从根本上解决了这一难题。
BERT 的核心在于其双向性设计 和掩码语言模型(MLM)预训练目标,使模型能够同时从左右两侧语境学习表示。这种能力使其在处理复杂语义关系(如一词多义、指代消解、语义推理)时表现出色。BERT 的出现标志着 NLP 领域研究的根本性哲学转变:从任务特定模型工程 转向通用语言模型预训练,通过在大规模无标注文本上预训练,只需在下游任务上进行微调即可获得最先进性能,极大地提高了模型开发效率和泛化能力。
本文旨在从学术视角,详细分析 BERT 双向编码器架构的核心技术优势,并探讨其在自然语言理解、问答系统、文本分类等关键任务中的突破性成就与研究潜力。
一、 BERT 双向编码器架构的核心技术优势
BERT 的技术创新主要集中在其架构设计和预训练策略上,确保了模型能够构建深度、通用的语言表示。
1.1 核心突破:深度双向性语义理解
传统的自回归模型(如 GPT)只能单向处理文本。BERT 的双向编码器架构通过同时利用左右上下文信息,实现了真正的双向训练。
- 优势体现: 在理解上下文依赖和复杂语言现象时效果显著。例如,在理解因果关系、处理一词多义(如区分 "bank" 的两种语义)等场景中,双向性赋予了模型更强的语义消歧能力。
- 自注意力机制: Transformer 的自注意力机制允许序列中的每个词同时关注所有其他位置的词汇,直接捕捉远距离依赖关系,堆叠多层机制则构建出深度的双向表示。
1.2 创新策略:掩码语言模型(MLM)与下一句预测(NSP)
BERT 采用的 MLM 预训练策略是其成功的关键。通过随机掩盖输入中 15% 的词汇,模型被迫基于完整的上下文预测被掩盖的词汇,巧妙地实现了双向训练。
- MLM 策略: 并非简单替换为
[MASK],而是采用 80% 替换[MASK]、10% 随机词替换、10% 保持不变的混合策略,旨在缓解预训练和微调之间的不匹配问题。 - NSP 任务: 引入下一句预测任务,要求模型判断两个句子是否连续,这对理解篇章级关系(如问答、自然语言推理)至关重要。
1.3 架构优势:统一架构的跨任务适应性
BERT 使用统一的 Transformer 编码器,能够基于其双向上下文表示任何词元,并且对绝大多数 NLP 任务只需要最小的架构改变即可实现最先进性能。
- 统一输入: 输入序列使用特殊的
[CLS](用于分类任务的聚合表示)和[SEP](用于分隔句子对)标记,并使用**段嵌入(Segment Embeddings)**区分不同句子。 - 应用广泛性: 这种统一的输入格式和架构,使得 BERT 可通过简单的微调,适应句子级任务(如分类)和标记级任务(如命名实体识别),极大地简化了开发流程。
二、 BERT 在核心 NLP 任务中的学术研究潜力与表现
BERT 在自然语言理解(NLU)、问答系统(QA)和文本分类等领域展现了革命性的性能提升和巨大的研究潜力。
2.1 自然语言理解(NLU):GLUE 基准的突破
- 里程碑表现: BERT 在 GLUE (通用语言理解评估)基准上实现了显著突破,将总分数提升至 80.5%(绝对提升 7.7%)。
- 推理能力: 在 MultiNLI (多体裁自然语言推理)任务中,准确率达到 86.7%(绝对提升 4.6%),证明了其强大的深度语义推理能力,能够同时考虑前提和假设的完整上下文。
- 深度机制: BERT 通过联合调节所有层中的左侧和右侧上下文,有效捕捉文本的深层语义特征,能够为每个词汇生成动态的、上下文相关的表示。
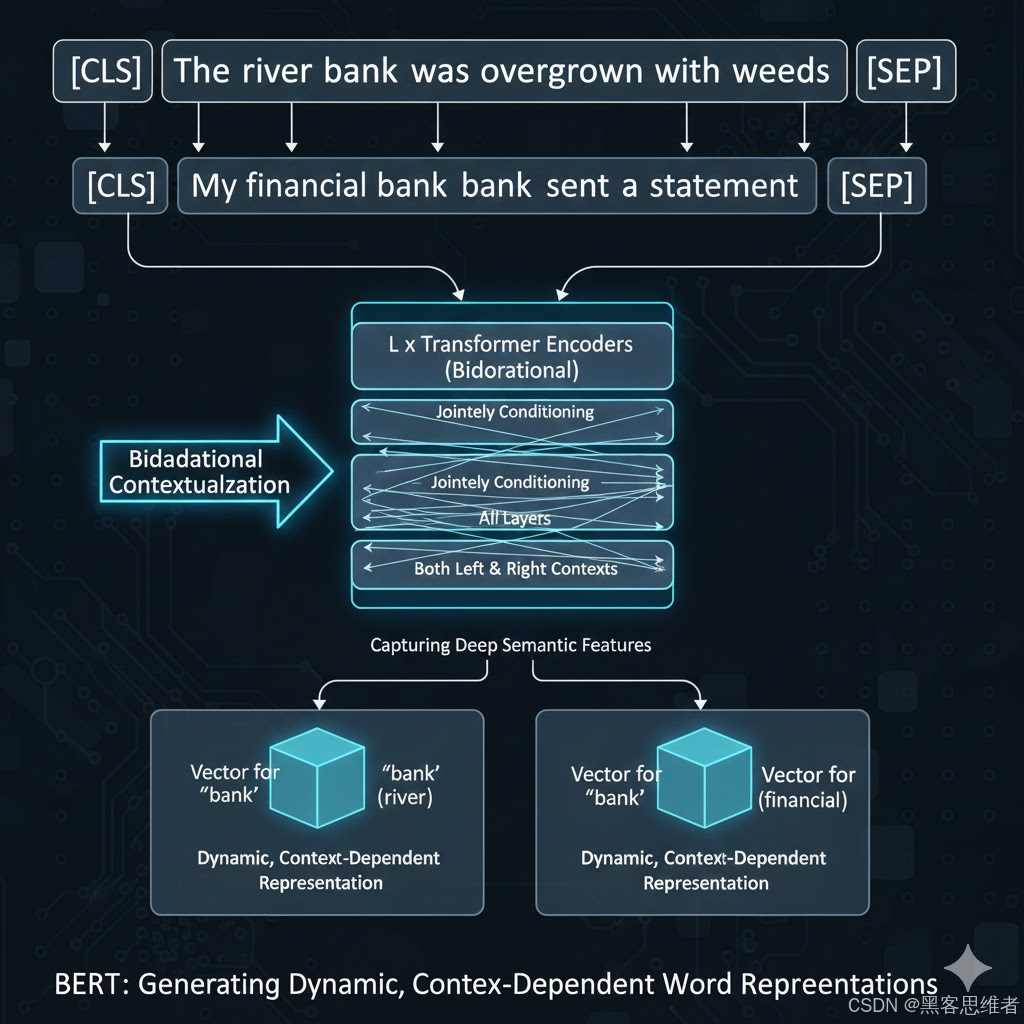
2.2 问答系统(QA):超越人类的表现
BERT 在机器阅读理解领域取得了革命性成就,尤其在 SQuAD(Stanford Question Answering Dataset)基准测试中表现惊人。
- 基础性能: SQuAD v1.1 F1 分数达到 93.2 ,SQuAD v2.0 F1 分数达到 83.1 (绝对提升 5.1 分)。在 SQuAD v1.1 上,BERT 的表现已经超越了人类水平。
- 改进模型: 研究者提出了 ForceReader 等改进模型,通过注意力分离表示 和多模式阅读策略,解决了原始 BERT 在编码问题和段落为单一序列时可能出现的"注意力分散"问题。
- 性能提升: ForceReader 在 SQuAD1.1 上的 EM/F1 指标分别提升了 4.8%/2.9% ,在 SQuAD2.0 上提升了 6%/6.1%,进一步接近甚至超越人类表现。
- 扩展应用: BERT 的多语言版本在跨语言问答中展现巨大潜力,同时能够处理 SQuAD 2.0 中的不可回答问题,增强了模型的实用性。
2.3 文本分类:多领域和多语言的适应性
BERT 在情感分析和多领域文本分类中展现出卓越性能,特别是在处理复杂上下文和多语言场景时优势明显。
- 性能数据: 在软件工程领域(GitHub、Jira、Stack Overflow)的文本分类任务中,基于 BERT 的集成模型和压缩模型 的 F1 指标比现有工具提升 6-12% 。例如,GitHub 数据集 F1 分数达 0.92。
- 情感分析优势: BERT 的双向性使其能准确捕捉情感表达中的细微差别,尤其在处理讽刺、反语等复杂情感表达时表现出色。
- 优化策略: 采用集成学习 (结合 BERT、RoBERTa、ALBERT 等变体)和模型压缩 (如 DistilBERT 保持 97% 语言理解能力,模型大小减少 40%)来优化部署成本和性能。
三、 理论贡献、研究意义与未来展望
BERT 不仅仅是一个性能优越的模型,它更是 NLP 研究史上的一次哲学和范式上的根本性转变。
3.1 推动预训练和迁移学习范式转变
- 核心贡献: BERT 将 NLP 领域从任务特定模型工程 转向预训练通用模型 + 微调特定任务的新范式。
- 意义: 这一转变使得研究者能够利用大规模无标注文本获取通用语言知识,并大大减少了对大量标注数据的依赖,提高了模型的泛化能力。
3.2 对 NLP 研究生态的深远影响
- 学术催化剂: 自发布以来,BERT 及其开源代码极大地促进了研究。Google Scholar 引用数据显示,超过 10,000 篇论文对其进行了扩展研究。
- 催生变体: BERT 催生了 BioBERT、SciBERT(领域适应)、ERNIE(持续预训练)、DistilBERT(模型压缩)等大量变体模型,覆盖了模型改进、领域适应和多模态理解等多个方向。
3.3 跨领域应用与未来研究方向
BERT 的成功为跨领域应用和未来研究指明了方向:
- 跨领域迁移: BERT 的语言表示被成功应用于信息检索(IR)、数学推理和软件理解任务,证明了通用语言表示的巨大价值。
- 规模扩展: 未来研究方向将继续沿着 BERT 的架构理念,扩展到数十亿参数和多语言表示,同时通过 Switch Transformer 等架构减少计算负担。
- 理论指引: BERT 的深度双向调节和 MLM 目标为后续大型语言模型(LLM)的设计提供了核心技术基石。
结论
BERT 双向编码器架构通过其革命性的 MLM 预训练 和深度双向语境理解能力 ,确立了其在自然语言处理领域的里程碑地位。它不仅在 GLUE、SQuAD 等基准测试中取得了超越人类的表现,更重要的是推动了 NLP 研究从"任务驱动"向"预训练 + 微移"的通用范式转变。展望未来,BERT 的理论贡献和架构理念将继续作为下一代大语言模型(LLM)发展的基石,推动自然语言处理技术向更深层次的理解和应用迈进。