此分类用于记录吴恩达深度学习课程的学习笔记。
课程相关信息链接如下:
- 原课程视频链接:双语字幕吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第三课的第二周内容,2.7的内容。
本周为第三课的第二周内容,本周的内容关于在上周的基础上继续展开,并拓展介绍了几种"学习方法",可以简单分为误差分析和学习方法两大部分。
其中,对于后者的的理解可能存在一些难度。同样,我会更多地补充基础知识和实例来帮助理解。
本篇的内容关于迁移学习,这是一个在现在仍广泛使用的技术方法。
1. 迁移学习出现的背景
迁移学习出现的根本原因 还是我们在DL领域里老生常谈的问题:数据不足 。
在真实场景中,大规模、高质量的数据往往非常难获取 。
例如:
- ImageNet(这是一个非常著名的超大规模数据集) 里有上千万张标注清晰的猫狗、汽车、物体照片。
- 但某些新的任务,例如 "识别工业零件缺陷",往往只有几百张甚至几十张数据。
我们之前已经提到过,在数据不足的情况下,我们有一种比较"取巧"的处理方式:数据增强
它通过扩展现有数据集来增加数据,但是我们也在前面的数据不匹配部分提到过,在数据量本就不多的情况下再进行数据扩展有很大的过拟合风险。
在这种情况下,便有人提出了另一种思路:很多任务的低层次特征都是差不多的,你的数据少,但是它的数据多,我们能不能把它的模型的前几层直接拿来用?
我们用两个例子来详细展开这句话从而帮助理解:
(1)猫狗识别和工业缺陷检测
这两个任务好像八竿子搭不到边,但在图像学习的逻辑里,它们虽然一个识别动物,一个识别零件瑕疵,但其实都依赖基础特征:
- 轮廓线
- 边缘变化
- 明暗对比
- 表面纹理
这些低层特征我们人很难系统地总结, 但机器却擅长通过像素捕捉这些特征,网络的前几层学到的正是这些通用特征。
所以,在ImageNet上学过猫和狗的模型,也能对"金属表面凹坑"这种完全不同的任务产生帮助。
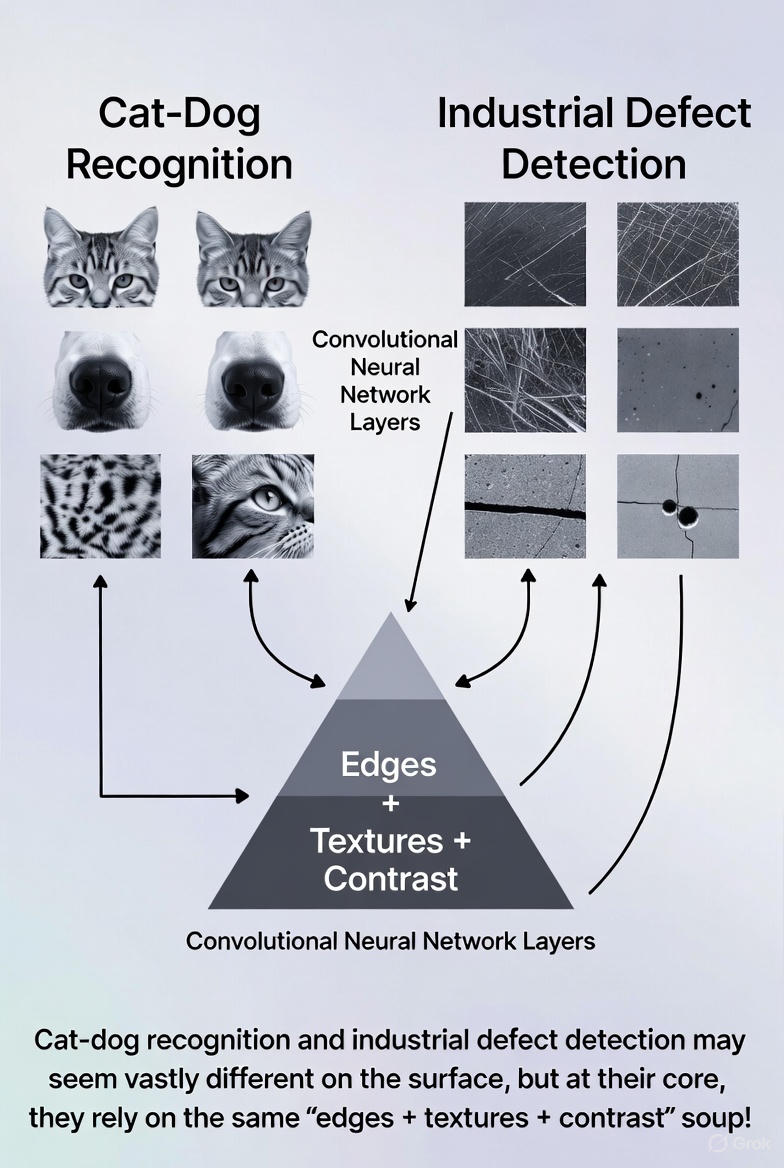
(尝试了一下使用grok来生成配图,相比GPT确实在这种逻辑上更擅长一些,但是中文显示很拉跨。)
(2)人脸识别和手写数字识别
继续来看这个任务,经过上面例子的解释,你可能已经感觉二者的联系了。
任务完全不同,但两者都需要:
- 边缘检测(数字的笔画、眉毛轮廓)
- 局部形状(眼睛形状、数字弧度)
- 小范围的纹理变化
所以它们实际上也有可以公用的地方。
因此,不同任务的高层语义不一样,但低层视觉特征却高度通用,因此可以直接迁移。 这正是迁移学习的根基。
现在,我们就来具体看看迁移学习本身。
2. 什么是迁移学习?
理解迁移学习的关键,是把它视为一种"借力"的思维方式。
如果你从零开始训练一个模型,那么模型需要依靠你的数据,从最底层的边缘、线条开始学习,一直到最后的任务语义 。
但就像上面的背景里说的,在数据量不足的任务中,这种"从零开始"几乎是不可能成功的。
所以,迁移学习的核心思想非常朴素:
既然别人已经在大型数据集上训练出一个很强的模型,那我能不能直接借用它已经学好的部分,让我的小任务站在它的肩膀上?
在这种思想下,使用迁移学习在实际应用中有一个更常见的说法叫做:使用预训练模型。
典型的迁移学习可以分为两种,你可以理解为"借多少"------借得少一点?还是借得多一点?
下面分别来看。
2.1 固定前几层,只训练最后几层(也叫 freeze 迁移)
这种方式的思路就像"借一本已经做满笔记的教材,只在你需要的章节上补充内容 "。
具体做法是:
- 取一个在大规模数据集(例如 ImageNet)上已经训练好的模型
- 保留它的前几层(这些层已经学会了边缘、纹理、局部形状等通用特征)
- 将最后几层替换成你自己任务的分类器或输出模块
- 只训练最后几层即可
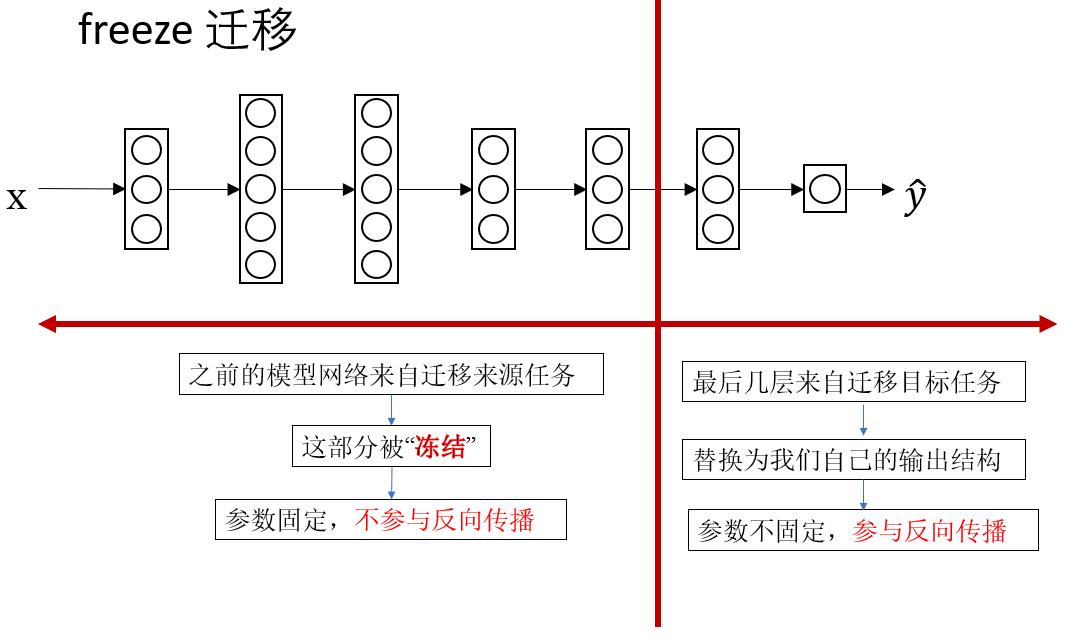
在数据量很少的情境里,这往往是最稳妥、最有效的方式。原因在于,你并不需要模型重新学习那些基础视觉技能。
例如:
- 图像中"这是一条边"
- "这是简单纹理变化"
- "这是一个局部形状的突变"
这些基础知识早已被预训练模型学得非常扎实。你需要让模型重新学习的,只是最终的"任务语义"。
因此,这种方式特别适合: - 你的数据非常少
- 新任务和原任务比较接近(例如都属于图像分类)
2.2 在预训练基础上整体微调(fine-tuning)
第二种方式比喻起来更像是:"拿到别人写好的教材,但你对其中很多部分都有自己的想法,于是你决定在原有基础上全书都修改 一点,只不过改得很轻。"
具体做法是:
- 仍然从一个预训练模型开始
- 不是只训练最后几层,而是允许整个网络都参与更新
- 使用较小的学习率,避免把原来已经学得很好的特征破坏掉

再举一个例子,你可以把它想象成:
模型已经是一个受过良好训练的学生,但你希望他再进一步按照你的任务风格来调整思路,于是让他重新复习你修改过的知识,但修改幅度非常小。
这种方式适用于:
- 新任务的数据量比刚才那种情况更多
- 新任务和原任务差别较大(例如原任务是动物分类,你的任务是医学影像)
- 你希望模型能真正为你的任务"深入适配"
微调整个网络的好处是:灵活、适应性强,能更充分地利用你提供的新数据。
但它需要更多数据,同时也更容易过拟合。
2.3 两种方式的选择逻辑
一句话总结:
- 如果你的数据很少,只训练最后几层更保险
- 如果数据量适中,或者新旧任务差异明显,微调整个网络会有更好的表现。
我会在本周的代码实践部分着重演示如何使用迁移学习和它的实际效果,在如今的的实际任务中,它是很常见的一种调试方向。
3. 在应用迁移学习的几点注意事项
- 确保迁移来源任务和迁移目标任务拥有相同类型的输入,比如同样大小的图片或相同数量的特征,这样才能进行训练。
- 只有在迁移来源任务的数据量更多的情况下,把它的模型迁移到目标任务才是更有意义的。
- 当迁移来源任务和迁移目标任务的低层次特征更相似时,迁移学习往往能起到更大的帮助。
4. 总结
| 概念 | 原理 | 比喻 |
|---|---|---|
| 迁移学习 | 利用在大数据集上训练好的模型,把已学到的低层特征(如边缘、纹理、局部形状)迁移到数据量少的新任务上,只训练新任务相关的部分或微调整个网络 | "借力"------站在别人肩膀上学习 |
| 迁移学习的出现背景 | 数据量不足,高质量标注数据难获取 | 比如工业零件缺陷识别,数据只有几十张,无法从零训练深度网络 |
| 迁移学习的 核心思想 | 低层视觉特征通用,高层语义任务差异大 | 猫狗识别模型也能帮助工业零件瑕疵检测,因为轮廓、边缘、纹理等特征通用 |
| 固定前几层(freeze) | 保留预训练模型前几层,只替换最后几层分类器,新任务只训练最后几层 | "借一本已经做满笔记的教材,只在你需要的章节上补充内容" |
| 微调整个网络(fine-tuning) | 在预训练模型基础上,允许整个网络都参与更新,使用小学习率调整已有特征以适应新任务 | "拿到别人写好的教材,但你对其中很多部分都有自己的想法,轻微修改全书内容" |