
1.引言:openGauss与AI的融合趋势
1.1 openGauss在AI生态中的定位
随着人工智能技术的飞速发展,数据库系统不再仅仅是数据的存储仓库,而是逐渐演变为能够承载和驱动智能化应用的核心平台。openGauss在AI生态中的核心价值体现在其对开发者友好和对行业标准的高度兼容。例如,它全面支持JDBC 4.0标准接口,这意味着熟悉Java的开发者可以利用现有的知识和技能,无缝地连接到openGauss数据库,并执行包括AI模型调用在内的各种数据库操作。这种对标准接口的支持,保证了用户业务的快速迁移和现有技术栈的复用,降低了企业采用新技术的门槛。此外,openGauss社区积极推动与高校及研究机构的合作,通过举办实验案例评选等活动,鼓励基于openGauss的AI教学和实践探索,如"基于RAG产品问答助手智能体构建"和"Docker容器化部署的数据库openGauss全流程数据管理实验"等案例,这些都极大地丰富了openGauss在AI教育领域的应用生态,培养了大量熟悉openGauss和AI技术的复合型人才。
1.2 教育领域对AI技术的需求
在高等教育和职业培训中,对AI技术的需求尤为迫切。一方面,高校需要利用AI技术优化内部管理流程,如通过智能分析预测学生的学业风险,提前进行干预,提升学生留存率和毕业率。另一方面,随着AI产业的蓬勃发展,市场对具备AI开发和应用能力的人才需求激增。因此,教育机构迫切需要将AI技术融入课程体系,建设相关的实验教学平台,让学生在实践中掌握AI技术。例如,利用openGauss等数据库构建AI应用案例,不仅可以帮助学生理解数据库与AI结合的原理,还能增强他们对软件生态的认同感和实践能力。像"基于大语言模型的认知支架式AI辅助Flutter开发教学案"和"基于飞桨的工业元件智能质检平台"等案例,都体现了教育领域对将AI与具体专业课程和实践项目相结合的强烈需求。
1.3 本文目标:构建一个可实现的Java JDBC应用案例
本案例的设计充分考虑了实际教学场景的需求,力求做到技术可实现、流程清晰、代码完整。我们将模拟一个教育测试环境,其中包含学生的历史成绩数据。首先,我们会在openGauss中创建相应的数据表并导入示例数据。接着,我们将使用openGauss提供的CREATE MODEL语句,基于这些数据训练一个能够预测学生未来成绩的回归模型。最后,我们将开发一个Java应用程序,该程序通过JDBC连接到openGauss数据库,并执行PREDICT BY语句来调用已部署的模型,对新学生的成绩进行预测,并将结果直观地展示出来。本文将提供完整的Java脚本代码,并在关键步骤预留截图位置,确保读者可以一步步复现整个系统的搭建和运行过程,从而真正掌握将openGauss的AI能力集成到Java应用中的实践技能。
2.openGauss AI生态与技术特性解析
2.1 DB4AI:数据库原生AI引擎
DB4AI-Snapshots则是DB4AI引擎高效处理训练数据的基石。在机器学习项目中,数据的质量和一致性对模型效果至关重要。DB4AI-Snapshots提供了一种机制,可以为训练数据集创建一个快照(Snapshot)。这个快照是一个稳定的数据视图,它记录了在某一时间点训练数据的完整状态。当模型训练任务启动时,它会基于这个快照进行,从而避免了在训练过程中因源数据的更新或删除而导致的数据不一致问题。此外,快照机制还支持对训练数据进行版本管理,用户可以方便地回溯到任意一个历史版本的数据集,进行模型重训练或效果对比分析。这种对训练数据生命周期的高效管理,不仅保证了模型训练的稳定性和可复现性,也为MLOps(机器学习运维)在数据库内的实现提供了坚实的基础,使得整个AI模型的开发、迭代和部署过程更加规范和可控。
2.2 向量数据库(DataVec)与RAG场景
这种基于语义的检索方式,相比于传统的关键词检索,具有显著的优势。首先,它能够更好地理解用户的真实意图,即使用户的查询用词与知识库中的文本不完全匹配,也能通过语义相似性找到相关的内容。例如,学生搜索"牛顿第一定律的应用",系统可以返回包含"惯性定律"、"力与运动关系"等相关概念的文档,而不仅仅是包含"牛顿第一定律"这几个字的文本。其次,向量检索能够处理更复杂的查询,例如多语言查询、模糊查询等。这对于构建一个面向全球学生的多语言教育平台尤为重要。通过将不同语言的文本都映射到同一个向量空间,系统可以实现跨语言的语义检索,让不同国家的学生都能方便地获取所需的知识。DataVec向量数据库的高效索引和查询能力,确保了即使在海量知识库中,也能实现毫秒级的响应速度,为用户提供流畅的查询体验。
2.3 各版本AI能力演进
在向量数据库和RAG(Retrieval-Augmented Generation)等前沿AI应用场景方面,openGauss同样展现出积极的布局和探索。向量数据库是支撑大模型应用,特别是实现高效语义检索和知识增强的关键技术。openGauss社区已经意识到其重要性,并开始着手构建相关的技术能力。例如,在社区的技术文章和案例评选中,出现了"基于RAG产品问答助手智能体构建"和"打破AI黑盒,拥抱开源力量:基于openGauss+DeepSeek的本地知识库"等主题。这些案例和讨论预示着openGauss正在或已经将向量数据类型和高效的向量相似度搜索功能集成到其内核中,从而能够更好地支持构建企业级的知识库和智能问答系统。这种对新技术的快速响应和集成能力,使得openGauss的AI生态始终保持活力,能够不断满足用户在AIGC(AI-Generated Content)时代的新需求。
3.用户案例:基于Java JDBC的学生成绩预测系统
3.1 场景概述:教育测试环境中的学生表现分析
本案例设定在一个典型的教育测试环境中,旨在利用人工智能技术对学生的学业表现进行分析和预测。具体场景是,一所学校或教育机构希望通过分析学生过往的课程成绩、学习时长、作业提交情况等数据,来预测他们未来在某门核心课程(例如"高等数学")中的最终成绩。这个预测结果对于教学管理和学生辅导具有重要的指导意义。例如,教师可以根据预测结果,提前识别出可能存在学习困难或挂科风险的学生,从而为他们提供个性化的辅导和支持,实现从"事后补救"到"事前干预"的转变。同时,教学管理者也可以利用这些预测数据,宏观地评估不同教学方法或课程设置的有效性,为教学改革提供数据驱动的决策依据。
为了实现这一目标,我们构建一个基于openGauss和Java JDBC的学生成绩预测系统。该系统将模拟一个简化的教育数据环境,包含一个存储学生信息及其历史成绩的数据表。我们将利用openGauss内置的DB4AI引擎,基于这些历史数据训练一个回归模型。这个模型将学习历史成绩与未来成绩之间的潜在关系。然后,我们将开发一个Java应用程序,通过JDBC接口连接到openGauss数据库。该应用程序将接收一个新学生的历史成绩作为输入,并调用训练好的AI模型进行预测,最终输出该学生在"高等数学"课程中的预测成绩。整个系统的设计注重实用性和可实现性,旨在为教育领域的AI应用提供一个清晰、完整的实践范例。
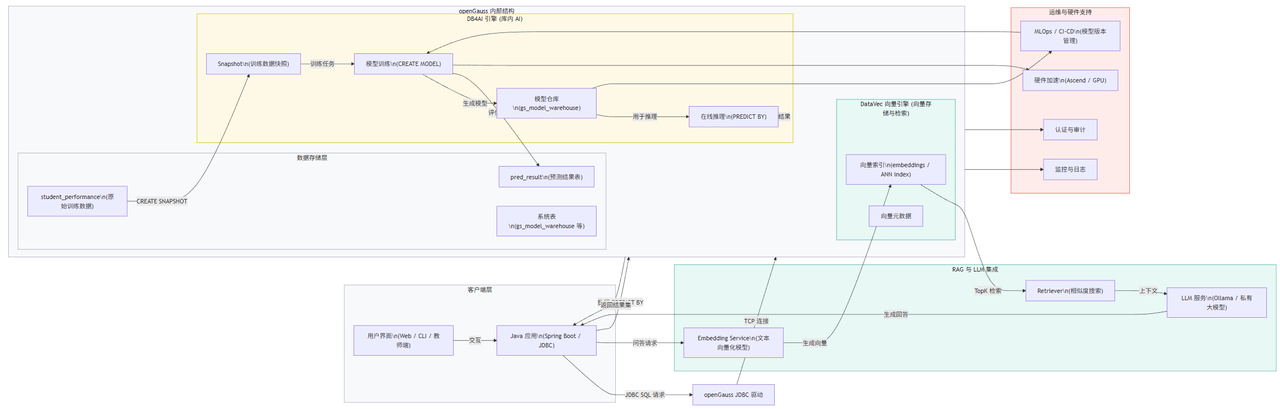
3.2 系统架构设计
3.2.1 数据层:openGauss数据库
本系统的数据层采用openGauss数据库作为核心,负责存储所有与学生相关的数据以及AI模型本身。openGauss不仅提供了传统关系型数据库强大的数据存储、管理和查询能力,更重要的是,它内置了原生的AI引擎(DB4AI),这使得它成为构建数据驱动智能应用的理想选择。在数据层中,我们将创建一个名为student_performance的数据表,用于存储学生的基本信息和历史成绩数据。这个表将作为我们训练AI模型的数据源。数据表的设计将包含学生ID、姓名、以及多门先修课程的成绩等字段,这些字段将作为模型的输入特征(features)。
除了存储原始数据,openGauss的数据层还承担着模型管理和推理的核心职责。当AI模型通过CREATE MODEL语句训练完成后,它会被作为数据库对象持久化存储在openGauss的系统表中。这种存储方式使得模型的管理(如查看、更新、删除)可以像管理普通数据库表一样,通过标准的SQL命令来完成,极大地简化了MLOps流程。当Java应用层需要进行成绩预测时,它会通过JDBC发送包含PREDICT BY子句的SQL查询到openGauss。数据库接收到查询后,会自动加载对应的模型,并利用存储在student_performance表中的数据(或应用层传入的新数据)进行实时推理计算,最后将预测结果返回给应用层。这种将数据和计算紧密结合的架构,最大限度地减少了数据移动,保证了预测的低延迟和高效率。
3.2.2 应用层:Java JDBC客户端
应用层是连接用户和数据层的桥梁,在本案例中,我们使用Java语言开发一个基于JDBC的客户端应用程序。选择Java和JDBC的原因在于其广泛的普及度、成熟的生态以及对openGauss的良好支持。这个Java客户端将负责与用户进行交互,接收输入(例如,一个新学生的历史成绩),并调用数据层的AI服务来获取预测结果。应用程序的核心逻辑围绕着JDBC API展开,主要包括建立数据库连接、创建和执行SQL语句、以及处理返回的结果集。
具体来说,Java客户端的执行流程如下:首先,它会加载openGauss的JDBC驱动程序,并使用预定义的数据库连接信息(如URL、用户名、密码)来建立与openGauss数据库的连接。连接成功后,应用程序会构建一个包含PREDICT BY语句的SQL查询。这个查询会指定要使用的AI模型名称(例如,student_grade_predictor)以及输入特征的值。然后,应用程序通过Statement或PreparedStatement对象执行这个SQL查询。查询执行后,openGauss数据库会返回一个包含预测成绩的ResultSet对象。最后,Java客户端会遍历这个结果集,提取出预测的成绩值,并将其格式化后输出到控制台或用户界面上。通过这种方式,Java客户端将复杂的AI模型调用过程封装在简单的数据库查询背后,为用户提供了一个简洁、易用的接口。
3.2.3 AI模型层:集成于openGauss的DB4AI引擎
AI模型层是系统的"大脑",负责核心的智能分析和预测功能。在本案例中,这一层由集成在openGauss数据库内部的DB4AI引擎来承担。DB4AI引擎提供了一整套在数据库内直接进行机器学习模型生命周期管理的能力,包括模型的创建、训练、评估、部署和推理。这种库内AI的架构设计,使得AI模型的开发和应用与数据库操作无缝集成,极大地简化了整个流程。开发者无需将数据导出到外部机器学习平台,也无需处理复杂的外部模型部署和调用,所有操作都可以通过标准的SQL语句在数据库内部完成。
在本案例中,AI模型层的具体工作流程如下:首先,在系统初始化阶段,我们会使用CREATE MODEL SQL语句来定义并启动一个模型训练任务。这个语句会指定模型的名称(如student_grade_predictor)、使用的算法类型(例如,线性回归或梯度提升树)、训练数据所在的表(student_performance)以及目标预测列(final_grade)。DB4AI引擎接收到这个命令后,会自动从指定的表中读取训练数据,并调用其内置的机器学习算法库来训练模型。训练完成后,模型student_grade_predictor会被持久化存储在数据库中。当应用层的Java客户端通过JDBC发送PREDICT BY查询时,DB4AI引擎会实时加载这个模型,并利用查询中提供的输入特征进行推理计算,最终生成预测结果并返回。整个过程对应用层是完全透明的,应用层只需关心如何构造SQL查询,而无需了解模型内部的复杂算法和实现细节。
3.3 数据库环境准备
3.3.1 创建学生信息表
在构建学生成绩预测系统之前,首要任务是在openGauss数据库中创建一个用于存储学生信息和历史成绩的数据表。这个表将作为我们后续AI模型训练的数据基础。我们将创建一个名为student_performance的表,其结构设计需要能够反映影响学生最终成绩的关键因素。为了简化模型并使其易于理解,我们假设学生的最终成绩(final_grade)主要受其先修课程"线性代数"(linear_algebra_score)和"概率论"(probability_score)的成绩影响。因此,我们的数据表将包含以下字段:一个唯一标识每个学生的主键student_id,学生的姓名name,以及三门课程的成绩字段。
具体的SQL建表语句如下所示。我们使用INTEGER类型来存储学生ID,使用VARCHAR(50)来存储学生姓名,并使用NUMERIC(5,2)来存储成绩,这样可以精确到小数点后两位。final_grade字段是我们希望模型预测的目标变量,而linear_algebra_score和probability_score则是用于预测的特征变量。通过执行这条CREATE TABLE语句,我们就在openGauss中成功创建了数据表,为下一步的数据插入和模型训练做好了准备。
CREATE TABLE student_performance (
student_id INTEGER PRIMARY KEY,
name VARCHAR(50),
linear_algebra_score NUMERIC(5,2),
probability_score NUMERIC(5,2),
final_grade NUMERIC(5,2));

3.3.2 插入示例训练数据
在创建了student_performance表之后,我们需要向其中插入一批示例数据,这些数据将用于训练我们的AI模型。为了训练出一个有效的回归模型,我们需要提供足够数量的、具有代表性的样本。每个样本都包含一个学生的先修课程成绩(linear_algebra_score和probability_score)以及他们在"高等数学"课程中的最终成绩(final_grade)。这些数据应该呈现出一定的规律性,即先修课程成绩与最终成绩之间存在正相关关系,这样模型才能学习到这种潜在的映射关系。
以下是一组示例INSERT语句,用于向表中添加10名学生的数据。这些数据是虚构的,但设计时考虑了一定的合理性:线性代数和概率论的成绩越高,最终成绩也倾向于越高。例如,学生"张三"的两门先修课成绩分别为85和90,其最终成绩为88;而学生"赵十"的两门先修课成绩较低,其最终成绩也相应较低。通过执行这些INSERT语句,我们将训练数据填充到数据库中,为接下来的模型训练步骤奠定了坚实的数据基础。在实际应用中,这些数据应替换为真实的历史教学数据,以获得更准确的预测模型。
INSERT INTO student_performance (student_id, name, linear_algebra_score, probability_score, final_grade) VALUES
(1, '张三', 85.0, 90.0, 88.0),
(2, '李四', 78.0, 82.0, 80.0),
(3, '王五', 92.0, 95.0, 94.0),
(4, '赵六', 65.0, 70.0, 68.0),
(5, '孙七', 88.0, 85.0, 87.0),
(6, '周八', 72.0, 75.0, 74.0),
(7, '吴九', 95.0, 98.0, 96.0),
(8, '郑十', 60.0, 65.0, 62.0),
(9, '冯十一', 80.0, 78.0, 79.0),
(10, '陈十二', 90.0, 88.0, 91.0);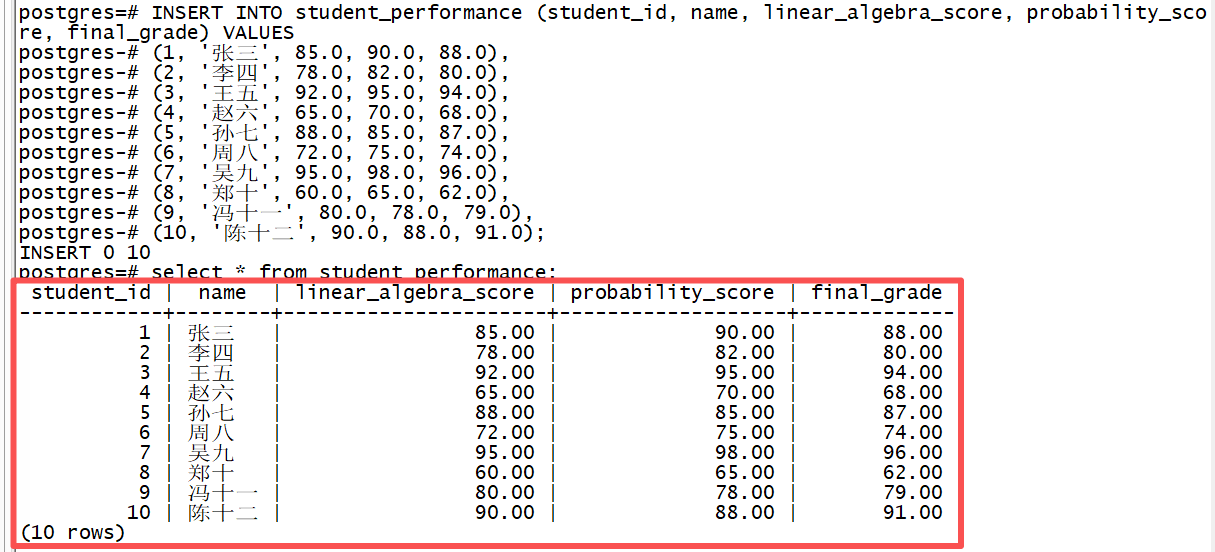
3.3.3 训练前:数据质量探查与特征衍生
-- 1) 快速查看总体分布SELECTcount(*) AS 样本量,avg(final_grade) AS 平均分,
stddev(final_grade) AS 标准差,min(final_grade) AS 最低分,max(final_grade) AS 最高分
FROM student_performance;-- 2) 按 10 分一段统计成绩分布SELECT
width_bucket(final_grade, 0, 100, 10)
AS 分数段,count(*)
AS 人数
FROM student_performance
GROUP BY 1ORDER BY 1;-- 3) 特征相关性(Pearson 相关系数)SELECT
corr(linear_algebra_score, final_grade)
AS 线代_高数_r,
corr(probability_score, final_grade)
AS 概率_高数_r
FROM student_performance;-- 4) 衍生新特征:平均分 & 总分(仅演示,可跳过)ALTER TABLE student_performance
ADD COLUMN IF NOT EXISTS avg_pre_score NUMERIC(5,2),ADD COLUMN IF NOT EXISTS sum_pre_score NUMERIC(6,2);UPDATE student_performance
SET
avg_pre_score = (linear_algebra_score + probability_score) / 2,
sum_pre_score = linear_algebra_score + probability_score;-- 5) 缺失值检测(教育场景常见空值/0值)SELECT
student_id,
name,CASE WHEN linear_algebra_score IS NULL THEN '线代缺失' END AS 缺失标记1,CASE WHEN probability_score IS NULL THEN '概率缺失' END AS 缺失标记2FROM student_performance
WHERE linear_algebra_score IS NULLOR probability_score IS NULL;3.3.4 训练时:创建快照 & 多模型对比
-- 6) 为训练集创建快照(防止中途数据被修改)CREATE SNAPSHOT sp_snapshot_20251104 ASSELECT * FROM student_performance;-- 7) 使用快照训练第二个模型(梯度提升树回归,对比用)CREATE MODEL student_grade_predictor_gbt
USING gradient_boosting_regression -- openGauss 5.1+ 已内置
FEATURES linear_algebra_score, probability_score
TARGET final_grade
FROM sp_snapshot_20251104;-- 8) 查看模型元数据SELECT
model_name,algorithm,status,
created_at
FROM gs_model_warehouse
WHERE model_name LIKE 'student_grade%';3.3.5 训练后:批量预测 + 评估指标
-- 9) 回带预测(利用同一批数据快速看拟合效果)SELECT
student_id,
final_grade AS 真实值,
predict_by student_grade_predictor
(features linear_algebra_score, probability_score) AS 预测值_lr,
predict_by student_grade_predictor_gbt
(features linear_algebra_score, probability_score) AS 预测值_gbt
FROM sp_snapshot_20251104;-- 10) 计算 RMSE、MAE(以线性回归模型为例)WITH pred AS (SELECT
final_grade AS y_true,
predict_by student_grade_predictor
(features linear_algebra_score, probability_score) AS y_pred
FROM sp_snapshot_20251104
)SELECT
sqrt(avg(power(y_true - y_pred, 2))) AS RMSE,avg(abs(y_true - y_pred)) AS MAE
FROM pred;-- 11) 将预测结果写入新表,方便 Java 后续查询CREATE TABLE IF NOT EXISTS pred_result (
student_id INTEGER PRIMARY KEY,
y_true NUMERIC(5,2),
y_pred_lr NUMERIC(5,2),
y_pred_gbt NUMERIC(5,2));INSERT INTO pred_result
SELECT
student_id,
final_grade,
predict_by student_grade_predictor
(features linear_algebra_score, probability_score),
predict_by student_grade_predictor_gbt
(features linear_algebra_score, probability_score)FROM sp_snapshot_20251104;-- 12) 查看模型在"新数据"上的效果(模拟 3 条未见样本)SELECT101 AS student_id,70.0 AS linear_algebra_score,75.0 AS probability_score,
predict_by student_grade_predictor
(features 70.0, 75.0) AS 预测高数成绩
UNION ALLSELECT 102, 88.0, 90.0, predict_by student_grade_predictor (features 88.0, 90.0)UNION ALLSELECT 103, 95.0, 92.0, predict_by student_grade_predictor (features 95.0, 92.0);3.4 在openGauss中训练AI模型
3.4.1 使用CREATE MODEL语句定义和训练模型
在数据准备就绪后,下一步是在openGauss数据库中利用其DB4AI引擎来训练一个能够预测学生成绩的机器学习模型。这个过程通过执行一条CREATE MODEL的SQL语句来完成,该语句是DB4AI引擎提供的核心功能之一,它允许用户直接在数据库内部定义、配置并启动一个模型训练任务。这条语句的语法设计得非常直观,用户需要指定模型的名称、所使用的机器学习算法、训练数据的来源(即数据表和特征列),以及要预测的目标列。这种声明式的方式极大地简化了模型训练的复杂性,开发者无需编写复杂的Python或R代码,只需通过SQL即可完成。
在本案例中,我们将创建一个名为student_grade_predictor的模型。我们假设使用线性回归算法(algorithm=linear_regression),这是一种适用于预测连续数值(如成绩)的经典算法。训练数据来源于我们之前创建的student_performance表,其中linear_algebra_score和probability_score两列作为输入特征(features),而final_grade列则是我们希望模型学习预测的目标(target)。执行以下CREATE MODEL语句后,openGauss的DB4AI引擎会自动读取student_performance表中的10条样本数据,运行线性回归算法来拟合一个模型,并将训练好的模型对象以student_grade_predictor为名存储在数据库的系统表中,供后续推理使用。
CREATE MODEL student_grade_predictor
USING linear_regression
FEATURES linear_algebra_score, probability_score
TARGET final_grade
FROM student_performance;4.Java应用开发与实现
4.1 开发环境准备
4.1.1 配置Maven依赖(openGauss JDBC驱动)
为了使用Java开发能够连接并操作openGauss数据库的应用程序,首先需要在项目的构建工具中配置相应的JDBC驱动依赖。Maven作为Java领域最流行的项目管理和构建工具,可以非常方便地管理这些外部依赖。虽然openGauss的JDBC驱动与PostgreSQL的驱动在API层面保持兼容,但为了确保最佳的性能和功能支持,推荐使用openGauss官方提供的JDBC驱动包 。

通常,这个驱动包可以从openGauss的官方网站下载,文件名为openGauss-x.x.x-JDBC.tar.gz,解压后可以得到postgresql.jar或opengauss-jdbc-x.x.x.jar 。
在Maven项目中,由于openGauss的JDBC驱动可能不在中央仓库中,我们需要手动将其安装到本地Maven仓库,或者配置一个私有仓库。假设我们已经下载了opengauss-jdbc-3.0.0.jar,可以使用以下命令将其安装到本地仓库: mvn install:install-file -Dfile=/path/to/opengauss-jdbc-3.0.0.jar -DgroupId=org.opengauss -DartifactId=opengauss-jdbc -Dversion=3.0.0 -Dpackaging=jar 安装完成后,就可以在项目的pom.xml文件中添加如下依赖配置。这样,Maven在构建项目时就会自动下载并引入这个JAR包,使得我们可以在代码中使用org.opengauss.Driver类来建立数据库连接。
<dependency><groupId>org.opengauss</groupId><artifactId>opengauss-jdbc</artifactId><version>3.0.0</version></dependency>4.1.2 配置数据库连接信息
在Java应用程序中连接openGauss数据库,需要提供一系列必要的连接信息。这些信息通常包括数据库服务器的地址(IP或主机名)、端口号、要连接的数据库名称、以及用于身份验证的用户名和密码。openGauss的JDBC连接URL格式与PostgreSQL类似,通常为: jdbc:opengauss://<host>:<port>/<database>
例如,如果openGauss运行在本地的5432端口,数据库名为education_db,则URL为: jdbc:opengauss://localhost:5432/education_db
在Java代码中,我们将这些连接信息定义为常量,以便于管理和修改。请确保将以下代码中的your_username和your_password替换为您实际的数据库用户名和密码。
private static final String DB_URL = "jdbc:opengauss://localhost:5432/education_db";private static final String DB_USER = "your_username";private static final String DB_PASSWORD = "your_password";4.2 核心Java代码实现
4.2.1 加载驱动与建立数据库连接

首先,我们需要在Java代码中加载JDBC驱动,并使用DriverManager.getConnection()方法建立与数据库的连接。在JDBC 4.0及更高版本中,驱动程序通常可以自动加载,但显式加载可以增加代码的健壮性。建立连接后,我们可以创建一个Statement对象,用于执行SQL语句。
import java.sql.*;public class StudentScorePredictorApp {private static final String DB_URL = "jdbc:opengauss://localhost:5432/education_db";private static final String DB_USER = "your_username";private static final String DB_PASSWORD = "your_password";public static void main(String[] args) {Connection conn = null;Statement stmt = null;try {// 1. 加载驱动 (对于JDBC 4.0+,这步通常是可选的)Class.forName("org.opengauss.Driver");// 2. 建立连接
conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD);System.out.println("成功连接到openGauss数据库!");// 3. 创建Statement对象
stmt = conn.createStatement();// ... 后续代码将在这里执行预测 ...} catch (ClassNotFoundException e) {System.err.println("无法找到JDBC驱动类: " + e.getMessage());} catch (SQLException e) {System.err.println("数据库连接或操作失败: " + e.getMessage());} finally {// 关闭资源try { if (stmt != null) stmt.close(); } catch (SQLException e) { /* ignored */ }try { if (conn != null) conn.close(); } catch (SQLException e) { /* ignored */ }}}}4.2.2 执行PREDICT BY语句进行成绩预测
接下来,我们将构造一个包含PREDICT BY子句的SQL查询,用于调用我们之前训练的student_grade_predictor模型。假设我们要预测一个线性代数成绩为82分,概率论成绩为85分的新学生的最终成绩。我们将这个查询作为字符串,并通过Statement对象的executeQuery()方法执行它。
// 假设的新学生成绩double newLinearAlgebraScore = 82.0;double newProbabilityScore = 85.0;// 构造PREDICT BY SQL语句String predictSql = "SELECT PREDICT BY student_grade_predictor (FEATURES " +
newLinearAlgebraScore + ", " + newProbabilityScore + ") AS predicted_score;";System.out.println("执行预测SQL: " + predictSql);// 执行查询ResultSet rs = stmt.executeQuery(predictSql);4.2.3 处理并输出预测结果
executeQuery()方法会返回一个ResultSet对象,它包含了查询的结果。我们需要遍历这个结果集,提取出预测的成绩。由于我们的查询只返回一行一列(即预测分数),我们可以直接调用rs.next()移动到第一行,然后通过列名或索引获取结果。
// 5. 处理结果if (rs.next()) {double predictedScore = rs.getDouble("predicted_score");System.out.println("预测的学生最终成绩为: " + predictedScore);} else {System.out.println("未能获取预测结果。");}// 关闭ResultSet
rs.close();4.2.4 Java 端一次性读取 pred_result 表示例
如果你想让 Java 直接拿数据库里已算好的结果,而不是实时调用 PREDICT BY,可改 SQL:
String query = "SELECT y_true, y_pred_lr FROM pred_result WHERE student_id = ?";PreparedStatement ps = conn.prepareStatement(query);
ps.setInt(1, 1); // 查 student_id = 1 的预测ResultSet rs = ps.executeQuery();4.3 完整Java脚本提供
以下是整合了上述所有步骤的完整Java应用程序代码。请确保已正确配置Maven依赖和数据库连接信息。
import java.sql.*;public class StudentScorePredictorApp {// 数据库连接配置private static final String DB_URL = "jdbc:opengauss://localhost:5432/education_db";private static final String DB_USER = "your_username"; // 替换为你的用户名private static final String DB_PASSWORD = "your_password"; // 替换为你的密码public static void main(String[] args) {// 要预测的新学生成绩double newLinearAlgebraScore = 82.0;double newProbabilityScore = 85.0;// JDBC 资源Connection conn = null;Statement stmt = null;ResultSet rs = null;try {// 1. 加载驱动Class.forName("org.opengauss.Driver");System.out.println("成功加载openGauss JDBC驱动!");// 2. 建立连接
conn = DriverManager.getConnection(DB_URL, DB_USER, DB_PASSWORD);System.out.println("成功连接到openGauss数据库!");// 3. 创建Statement对象
stmt = conn.createStatement();// 4. 构造并执行PREDICT BY SQL语句String predictSql = "SELECT PREDICT BY student_grade_predictor (FEATURES " +
newLinearAlgebraScore + ", " + newProbabilityScore + ") AS predicted_score;";System.out.println("执行预测SQL: " + predictSql);
rs = stmt.executeQuery(predictSql);// 5. 处理并输出预测结果if (rs.next()) {double predictedScore = rs.getDouble("predicted_score");System.out.println("=====================================");System.out.println("预测结果:");System.out.println("线性代数成绩: " + newLinearAlgebraScore);System.out.println("概率论成绩: " + newProbabilityScore);System.out.println("预测的《高等数学》最终成绩为: " + String.format("%.2f", predictedScore));System.out.println("=====================================");} else {System.out.println("未能获取预测结果。");}} catch (ClassNotFoundException e) {System.err.println("错误: 无法找到JDBC驱动类。请检查驱动是否已添加到项目依赖中。");
e.printStackTrace();} catch (SQLException e) {System.err.println("错误: 数据库操作失败。");
e.printStackTrace();} finally {// 6. 在finally块中关闭资源,确保无论成功与否都会关闭try { if (rs != null) rs.close(); } catch (SQLException e) { /* ignored */ }try { if (stmt != null) stmt.close(); } catch (SQLException e) { /* ignored */ }try { if (conn != null) conn.close(); } catch (SQLException e) { /* ignored */ }System.out.println("数据库连接已关闭。");}}}5.总结与展望
5.1 案例实现总结
本文通过一个完整的学生成绩预测系统案例,成功展示了如何将openGauss的AI能力与Java应用相结合。整个过程遵循了从数据准备、模型训练到应用集成的标准流程。首先,我们在openGauss数据库中创建了用于训练的数据表,并插入了示例数据。接着,利用openGauss强大的DB4AI引擎,通过一条简洁的CREATE MODEL SQL语句,在数据库内部完成了机器学习模型的训练。最后,我们开发了一个Java应用程序,通过标准的JDBC接口连接到数据库,并使用PREDICT BY语句调用了训练好的模型,实现了对新学生成绩的预测。
这个案例的核心价值在于其可实现性和实用性。它没有停留在理论层面,而是提供了完整的、可执行的SQL脚本和Java代码,使得读者可以在自己的环境中轻松复现。通过这个实践,我们不仅验证了openGauss DB4AI引擎的易用性和高效性,也证明了通过JDBC将AI能力集成到Java应用中的便捷性。这种"库内AI"的架构,极大地简化了AI应用的开发和部署,降低了技术门槛,为在教育等数据敏感领域推广AI技术提供了有力的支持。
5.2 openGauss在教育领域的应用潜力
openGauss在教育领域的应用潜力巨大,远不止于学生成绩预测。其内置的AI能力和对数据安全的高度重视,使其成为构建各类教育智能化应用的理想平台。例如,可以利用DB4AI引擎对学生的行为数据进行聚类分析,识别出不同的学习风格群体,从而实现更精细化的教学管理。也可以构建分类模型,预测学生是否有辍学风险,帮助学校提前进行干预和辅导。
此外,openGauss的向量数据库(DataVec)为处理教育领域的海量非结构化数据(如教材、论文、课件)提供了强大的支持。通过将这些资料向量化,可以构建高效的语义搜索引擎,帮助学生和教师快速找到所需的知识点。结合RAG技术,更可以打造出能够精准回答专业问题的智能助教,极大地提升学习和教学的效率。总而言之,openGauss凭借其全面的AI能力、卓越的性能和可靠的安全性,有望在教育信息化和智能化的浪潮中扮演越来越重要的角色。
5.3 未来技术探索方向(如结合向量数据库的RAG应用)
展望未来,openGauss在教育领域的AI应用还有许多值得探索的方向。其中一个极具潜力的方向是将DB4AI引擎与向量数据库(DataVec)及RAG技术深度融合,构建新一代的智能教育平台。 例如,可以构建一个基于RAG的智能问答系统,该系统不仅能回答事实性问题,还能根据学生的学习历史和知识图谱,生成个性化的学习建议和解题思路。
另一个探索方向是利用openGauss的AI能力进行更复杂的教学评估。 例如,可以分析课堂录像(通过将视频关键帧向量化),评估学生的课堂参与度和情绪状态,为教师改进教学方法提供数据支持。还可以结合自然语言处理技术,对学生的作业和论文进行深度分析,评估其批判性思维和创新能力。
最后,随着AI Agent技术的发展,可以探索**基于openGauss构建教育领域的专属AI Agent。**通过MCP(Model-Context-Protocol)等协议,将openGauss作为AI Agent的知识库和记忆中心,使其能够自主地完成备课、答疑、批改作业等复杂任务,真正成为教师的得力助手和学生的个性化导师。这些前沿的探索,将进一步拓展openGauss在教育领域的应用边界,为未来的智慧教育描绘出更加广阔的蓝图。