一、背景介绍
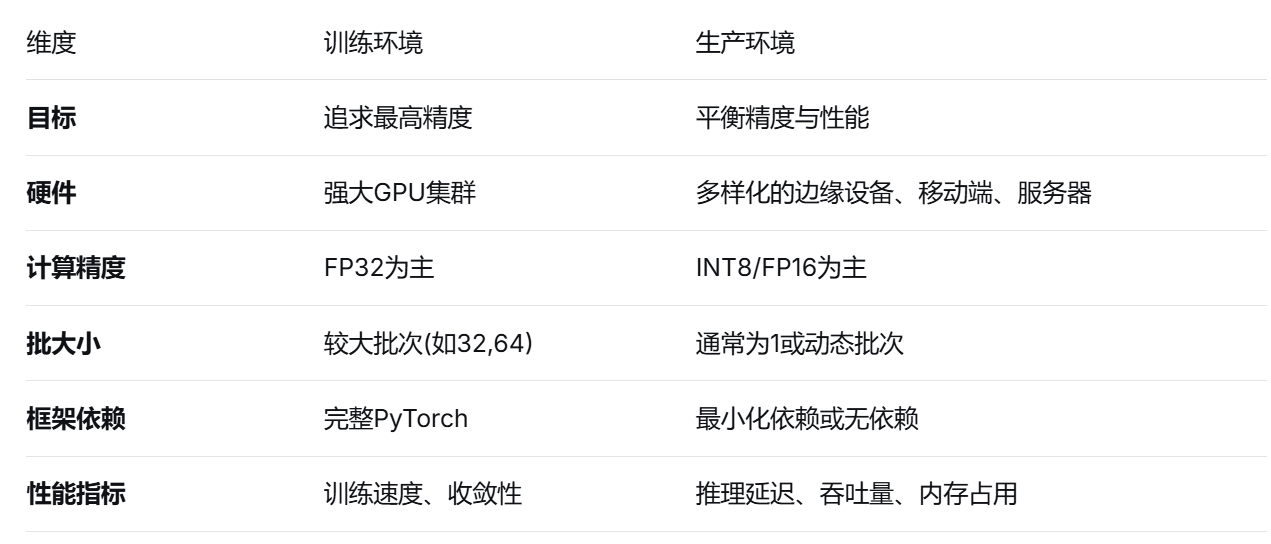
在深度学习研究和开发中,我们通常使用PyTorch这样的框架进行模型训练。在训练环境中,我们关注的是模型精度、收敛速度和实验迭代效率。然而,当模型准备投入实际应用时,面临的挑战就完全不同了。
1.1 训练环境和生产环境的区别
1.2 模型部署的核心挑战
- 硬件多样性:从服务器GPU到嵌入式ARM芯片
- 实时性要求:毫秒级响应,如自动驾驶的实时感知
- 资源限制:内存、计算力、功耗的严格约束
- 系统集成:与C++/Java等传统软件栈的融合
1.3 模型部署的典型流程
bash
PyTorch训练 → 模型导出 → 格式转换 → 推理优化 → 部署集成
↑ ↓ ↓ ↓ ↓
研究阶段 ONNX/TorchScript 中间表示 量化/剪枝/融合 C++/Python API二、ONNX格式:深度学习模型的"中间语言"
2.1 什么是ONNX?
ONNX(Open Neural Network Exchange)是一个开放的深度学习模型表示格式。它类似于软件开发中的"中间语言"(IR),允许模型在不同的深度学习框架之间进行转换和共享。
2.2 为什么选择ONNX?
- 框架互操作性:实现PyTorch → TensorFlow → MXNet等框架间的模型转换
- 硬件厂商支持:NVIDIA、Intel、ARM、华为等硬件厂商都提供ONNX支持
- 工具链生态:丰富的优化工具和推理引擎支持ONNX格式
- 标准化:统一的算子定义和模型表示
2.3 ONNX的核心概念
python
# ONNX模型的基本结构示意
ONNX Model:
├── Graph
│ ├── Inputs (输入节点)
│ ├── Nodes (计算节点/算子)
│ ├── Outputs (输出节点)
│ └── Initializers (权重参数)
├── Opset Version (算子集版本)
└── Metadata (元数据)2.4 将PyTorch模型导出为ONNX
python
import torch
import torch.onnx
class SimpleCNN(torch.nn.Module):
"""一个简单的卷积网络示例"""
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1)
self.relu = torch.nn.ReLU()
self.pool = torch.nn.MaxPool2d(2, 2)
self.fc = torch.nn.Linear(16 * 112 * 112, 10)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 创建模型实例
model = SimpleCNN()
model.eval() # 切换到推理模式
# 创建示例输入
dummy_input = torch.randn(1, 3, 224, 224) # (batch, channels, height, width)
# 导出模型为ONNX格式
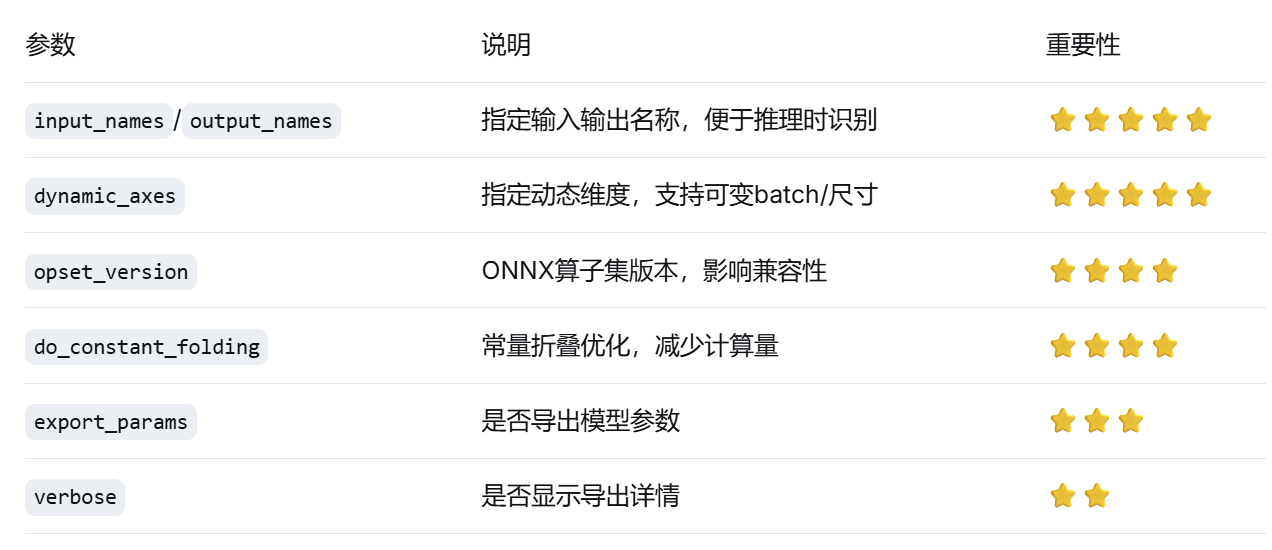
torch.onnx.export(
model, # 要导出的模型
dummy_input, # 模型输入示例
"simple_cnn.onnx", # 输出文件路径
input_names=["input"], # 输入节点名称
output_names=["output"], # 输出节点名称
dynamic_axes={
"input": {0: "batch_size"}, # 动态batch维度
"output": {0: "batch_size"}
},
opset_version=13, # ONNX算子集版本
do_constant_folding=True # 常量折叠优化
)2.5 ONNX导出关键参数详解
2.6 验证和检查ONNX模型
python
import onnx
import onnxruntime as ort
import numpy as np
# 1. 验证ONNX模型结构
onnx_model = onnx.load("simple_cnn.onnx")
onnx.checker.check_model(onnx_model) # 检查模型有效性
print(f"模型输入: {onnx_model.graph.input}")
print(f"模型输出: {onnx_model.graph.output}")
# 2. 使用ONNX Runtime进行推理验证
ort_session = ort.InferenceSession("simple_cnn.onnx")
# 准备输入数据
input_data = np.random.randn(1, 3, 224, 224).astype(np.float32)
# 运行推理
ort_inputs = {ort_session.get_inputs()[0].name: input_data}
ort_outputs = ort_session.run(None, ort_inputs)
print(f"推理结果形状: {ort_outputs[0].shape}")
# 3. 与PyTorch原始结果对比
with torch.no_grad():
torch_output = model(torch.from_numpy(input_data))
print(f"PyTorch与ONNX Runtime结果差异: {np.max(np.abs(torch_output.numpy() - ort_outputs[0]))}")2.7 常见导出问题与解决方案
- 算子不支持:
python
# 方案1:使用支持的等效算子替换
# 方案2:自定义算子实现并注册
# 方案3:降低opset_version- 动态形状问题:
python
# 确保dynamic_axes正确设置
dynamic_axes = {
'input': {0: 'batch', 2: 'height', 3: 'width'},
'output': {0: 'batch'}
}- 训练/推理模式差异:
python
model.eval() # 确保在推理模式
with torch.no_grad(): # 禁用梯度计算
torch.onnx.export(...)三、PyTorch模型部署实战示例
3.1 场景设定:部署一个图像分类模型
让我们以一个完整的图像分类模型部署为例,展示从训练到部署的全流程。
python
# 步骤1:训练一个简单的图像分类模型
import torch
import torchvision
import torchvision.transforms as transforms
from torch import nn, optim
# 数据准备
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform
)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=32, shuffle=True, num_workers=2
)
# 定义模型
class CIFAR10Model(nn.Module):
def __init__(self):
super(CIFAR10Model, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(128 * 8 * 8, 512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
# 训练模型(简化版)
model = CIFAR10Model()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(2): # 简化为2个epoch
for i, (inputs, labels) in enumerate(trainloader):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if i % 100 == 0:
print(f'Epoch {epoch}, Batch {i}, Loss: {loss.item()}')
# 保存训练好的模型
torch.save(model.state_dict(), 'cifar10_model.pth')3.2 模型导出与优化
python
# 步骤2:加载训练好的模型并导出为ONNX
model.load_state_dict(torch.load('cifar10_model.pth'))
model.eval()
# 创建示例输入
dummy_input = torch.randn(1, 3, 32, 32)
# 导出ONNX
torch.onnx.export(
model,
dummy_input,
"cifar10_model.onnx",
input_names=["input"],
output_names=["output"],
dynamic_axes={
"input": {0: "batch_size"},
"output": {0: "batch_size"}
},
opset_version=13,
do_constant_folding=True
)
print("模型已导出为 cifar10_model.onnx")
# 步骤3:模型量化(减少模型大小,提升推理速度)
def quantize_model():
# 动态量化
quantized_model = torch.quantization.quantize_dynamic(
model, # 原始模型
{torch.nn.Linear}, # 要量化的模块类型
dtype=torch.qint8 # 量化数据类型
)
# 导出量化后的模型
torch.onnx.export(
quantized_model,
dummy_input,
"cifar10_model_quantized.onnx",
input_names=["input"],
output_names=["output"],
opset_version=13
)
print("量化模型已导出为 cifar10_model_quantized.onnx")
# 对比模型大小
import os
original_size = os.path.getsize("cifar10_model.onnx") / 1024
quantized_size = os.path.getsize("cifar10_model_quantized.onnx") / 1024
print(f"原始模型大小: {original_size:.2f} KB")
print(f"量化模型大小: {quantized_size:.2f} KB")
print(f"压缩比例: {original_size/quantized_size:.2f}x")
quantize_model()3.3 使用不同推理引擎部署
python
# 步骤4:使用多种推理引擎进行部署比较
def benchmark_inference(model_path, input_shape=(1, 3, 32, 32), iterations=100):
"""基准测试函数,比较不同推理引擎的性能"""
import time
import numpy as np
# 准备测试数据
test_data = np.random.randn(*input_shape).astype(np.float32)
# 1. ONNX Runtime (CPU)
import onnxruntime as ort
ort_session = ort.InferenceSession(model_path)
ort_inputs = {ort_session.get_inputs()[0].name: test_data}
# 预热
for _ in range(10):
ort_session.run(None, ort_inputs)
# 正式测试
start_time = time.time()
for _ in range(iterations):
ort_outputs = ort_session.run(None, ort_inputs)
ort_time = (time.time() - start_time) / iterations * 1000 # 毫秒
print(f"ONNX Runtime (CPU): {ort_time:.2f} ms/次")
# 2. 如果可用,测试GPU版本
try:
ort_session_gpu = ort.InferenceSession(
model_path,
providers=['CUDAExecutionProvider', 'CPUExecutionProvider']
)
start_time = time.time()
for _ in range(iterations):
ort_session_gpu.run(None, ort_inputs)
ort_gpu_time = (time.time() - start_time) / iterations * 1000
print(f"ONNX Runtime (GPU): {ort_gpu_time:.2f} ms/次")
except:
print("GPU推理不可用")
return ort_time
print("\n性能基准测试:")
print("=" * 50)
print("原始模型性能:")
benchmark_inference("cifar10_model.onnx")
print("\n量化模型性能:")
benchmark_inference("cifar10_model_quantized.onnx")3.4 C++部署示例
cpp
// 步骤5:C++部署示例 (使用ONNX Runtime C++ API)
#include <onnxruntime/core/session/onnxruntime_cxx_api.h>
#include <opencv2/opencv.hpp>
#include <vector>
#include <chrono>
class OnnxInference {
private:
Ort::Env env;
Ort::Session session;
std::vector<const char*> input_names;
std::vector<const char*> output_names;
public:
OnnxInference(const std::string& model_path)
: env(ORT_LOGGING_LEVEL_WARNING, "CIFAR10_Inference") {
// 创建会话选项
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(1);
session_options.SetGraphOptimizationLevel(
GraphOptimizationLevel::ORT_ENABLE_ALL);
// 加载ONNX模型
session = Ort::Session(env, model_path.c_str(), session_options);
// 获取输入输出信息
Ort::AllocatorWithDefaultOptions allocator;
input_names.push_back(session.GetInputName(0, allocator));
output_names.push_back(session.GetOutputName(0, allocator));
}
std::vector<float> inference(const cv::Mat& input_image) {
// 图像预处理
cv::Mat resized, float_img;
cv::resize(input_image, resized, cv::Size(32, 32));
resized.convertTo(float_img, CV_32FC3);
// 转换为CHW格式并归一化
std::vector<float> input_tensor;
for (int c = 0; c < 3; ++c) {
for (int h = 0; h < 32; ++h) {
for (int w = 0; w < 32; ++w) {
float pixel = float_img.at<cv::Vec3f>(h, w)[c];
input_tensor.push_back((pixel / 255.0 - 0.5) / 0.5);
}
}
}
// 创建输入tensor
std::vector<int64_t> input_shape = {1, 3, 32, 32};
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(
OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
Ort::Value input_tensor_ort = Ort::Value::CreateTensor<float>(
memory_info, input_tensor.data(), input_tensor.size(),
input_shape.data(), input_shape.size());
// 运行推理
auto start = std::chrono::high_resolution_clock::now();
auto output_tensors = session.Run(
Ort::RunOptions{nullptr},
input_names.data(), &input_tensor_ort, 1,
output_names.data(), 1);
auto end = std::chrono::high_resolution_clock::now();
// 获取输出结果
float* floatarr = output_tensors.front().GetTensorMutableData<float>();
auto shape = output_tensors.front().GetTensorTypeAndShapeInfo().GetShape();
std::vector<float> output(floatarr, floatarr + shape[1]);
// 计算推理时间
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "推理时间: " << duration.count() << "ms" << std::endl;
return output;
}
};
// 使用示例
int main() {
OnnxInference inference_engine("cifar10_model.onnx");
cv::Mat image = cv::imread("test_image.jpg");
auto result = inference_engine.inference(image);
// 处理结果...
return 0;
}3.5 部署最佳实践总结
- 模型设计阶段考虑部署
避免动态控制流(if/for)
使用标准算子
考虑量化友好性
- 导出阶段注意事项
始终使用model.eval()模式
明确指定动态维度
验证导出模型的正确性
- 优化策略
量化:INT8量化可减少75%模型大小
剪枝:移除不重要的权重
层融合:减少计算图复杂度
- 性能监控
监控延迟、吞吐量、内存使用
建立性能基准线
定期进行性能回归测试
四、总结
PyTorch模型部署是一个系统工程,涉及模型格式转换、优化、硬件适配等多个环节。ONNX作为中间表示格式,在其中扮演着关键角色,它架起了PyTorch训练环境与多样化部署环境之间的桥梁。
掌握模型部署的核心要点:
- 理解训练与部署的差异,明确部署目标
- 熟练使用ONNX进行模型转换,处理好动态形状等复杂情况
- 掌握多种推理引擎的使用,根据场景选择最佳方案
- 重视性能优化,量化、剪枝等技术能显著提升推理效率
随着边缘计算和移动AI的发展,模型部署的重要性日益凸显。希望这篇博客能为你打下坚实的基础,让你在PyTorch模型部署的道路上走得更远!