KNN有监督分类器
KNN 分类器(K Nearest Neighbors Classifier) 的原理

核心思想:
KNN是有监督的分类方法,其思想就是:对于一个新的样本,找出和他最近的K个样本,这K个样本中出现的最多的类别就是该样本的类别
代码实现:
python
import numpy as np
from collections import Counter
class KNNClassifier:
def __init__(self, k=3):
self.k = k
def fit(self, X, y):
self.X_train = np.array(X)
self.y_train = np.array(y)
def predict(self, X):
X = np.array(X)
preds = []
for x in X:
# 计算欧氏距离
dists = np.linalg.norm(self.X_train - x, axis=1) # = sqrt( sum_j (X_train[i][j] - x[j])^2 )
# 找出距离最小的 k 个索引
idx = np.argsort(dists)[:self.k] # 把 dists 从小到大排序后的索引
# 多数投票
votes = self.y_train[idx]
preds.append(Counter(votes).most_common(1)[0][0])
# most_common(1) 会取出现次数最多的前 1 项,返回一个列表,列表元素是 (元素, 出现次数) 的元组
# # → [('cat', 3)]
return np.array(preds)
X_train = [[1,2],[2,3],[3,3],[8,8],[9,8],[8,9]]
print("X_train shape:", np.array(X_train).shape)
y_train = [0,0,0,1,1,1]
knn = KNNClassifier(k=3)
knn.fit(X_train, y_train)
print(knn.predict([[2,2], [9,9]]))
# results:
# X_train shape: (6, 2)
# [0 1]KMeans无监督聚类算法
KMeans 是一种 无监督聚类算法 ,目标是把数据分成 K 个簇,使得:**同簇内的数据相似,不同簇之间差异大。**它不需要标签,而是根据数据分布自动分群。
核心思想:
找到 K 个"中心点"(centroids),让每个点归到最近的中心。
不断更新中心,直到收敛。
聚类算法的K是超参数,手动指定,假设K等于3
1,首先随机初始化3个中心,
2,计算每个点到三个聚类中心的距离,到最近的聚类中心即为该点的标签
3,根据这些点,重新计算一次新的中心
4,重复迭代上述过程
得到的结果如下图所示:
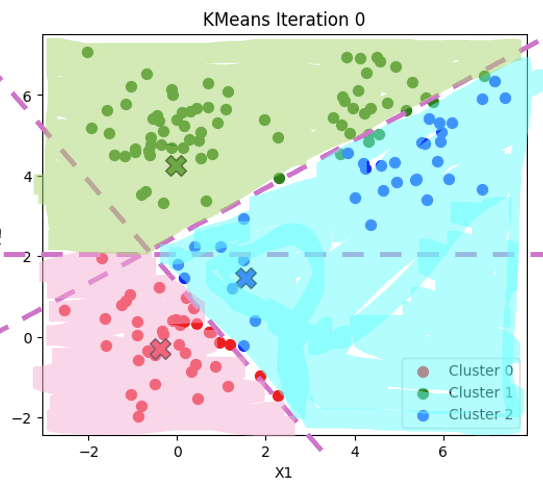
第二次迭代:

第三次迭代:
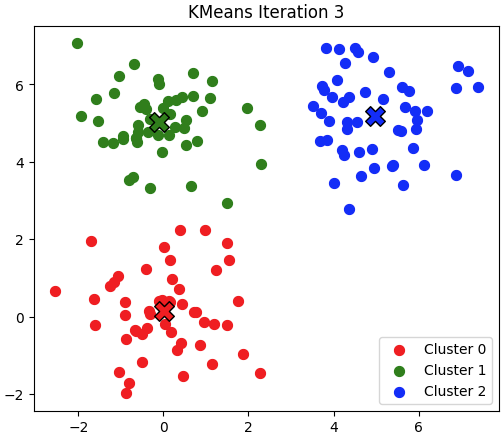
代码实现
python
import numpy as np
class KMeans:
def __init__(self, k=3, max_iters=100):
self.k = k
self.max_iters = max_iters
self.centers = None
def fit(self, X):
# 随机挑选 k 个样本作为初始中心
idx = np.random.choice(len(X), self.k, replace=False)
# idx = np.random.choice(len(X), self.k, replace=False),self.k 表示要抽取的数量,self.k 表示要抽取的数量,也就是每个索引只能被选一次
self.centers = X[idx]
for _ in range(self.max_iters):
# 计算每个点到每个中心的距离
# X 是所有样本,形状 (n_samples, n_features)
# self.centers 是当前的 k 个聚类中心,形状 (k, n_features)
# X[:, None]这里的 : 表示保留原来的第一维(行),None 表示在这个位置插入一个新维度,
# X[:, None] 会把新维度插在 : 后面,也就是 第一维之后、第二维之前,因此形状变为:(n_samples, 1, n_features)
# self.centers[None, :] 会把新维度插在第一维之前,因此形状变为:(1, k, n_features)
# 广播后结果形状:(n_samples, k, n_features),每个样本对应所有 k 个中心点的差值向量
distances = np.linalg.norm(X[:, None] - self.centers[None, :], axis=2)
# 分配簇
# (n_samples, k, n_features) labels属于 {0,1,...,k-1}
labels = np.argmin(distances, axis=1) # 找到每个样本距离最近的中心点索引 形状: (n_samples,)
# 根据分配结果重新计算中心
new_centers = np.array([X[labels == i].mean(axis=0) for i in range(self.k)])
# 如果中心不再变化, 结束
# np.allclose用来判断两个数组在元素级别上是否"足够接近",通常用于浮点数比较,避免直接用 == 导致精度问题。
# np.allclose(a, b, rtol=1e-05, atol=1e-08)
if np.allclose(self.centers, new_centers):
break
self.centers = new_centers
return labels
def predict(self, X):
distances = np.linalg.norm(X[:, None] - self.centers[None, :], axis=2)
return np.argmin(distances, axis=1)
# 测试代码
if __name__ == "__main__":
X = np.array([
[1, 2],
[1, 4],
[1, 0],
[10, 2],
[10, 4],
[10, 0]
])
kmeans = KMeans(k=2)
labels = kmeans.fit(X)
print("labels:", labels)
print("centers:", kmeans.centers)np.allclose()
