引言
最近一年多,我明显感觉到大模型落地速度越来越快,随之而来的是向量存储和 RAG(检索增强生成)的需求爆发 ------ 毕竟大模型需要 "外挂知识库" 来避免幻觉,这也让数据库行业进入了多模融合的新阶段。这次我重点评测的是 openGauss 开源数据库,尤其聚焦它 7.0 版本里的 AI 与向量特性。接下来我会从技术特性、生态成熟度、实际案例和未来趋势这几个维度,分享我的真实体验和判断。

一、 技术特性

(1)向量数据库能力:DataVec 插件的突破
openGauss 的向量能力主要靠 DataVec 插件实现,这部分我实际测试了不少场景,感受挺深。
核心功能上,它支持 L2 欧氏距离、余弦相似度、内积三种常用的向量距离计算方式,覆盖了大多数 RAG 场景的需求。而且它有精确和近似两种检索模式 ------ 我试过用精确搜索查小批量数据,结果很全;换成近似搜索处理百万级向量时,速度明显快了不少,平衡得不错。最方便的是它支持 SQL 原生语法,比如用INSERT ... vector\[\]插入向量,用kNN()做检索,不用额外学新语法,对习惯 SQL 的人很友好。
(2)AI 与数据库的深度融合
这部分是 openGauss 的最新亮点,我接触下来觉得它把 AI 和数据库的结合做得很实在,不是噱头。
AI4DB 自治能力让运维轻松了不少。比如智能运维里的参数自调优,我之前在测试环境里故意设错几个参数,它能自动调整到合理值;慢 SQL 诊断也很准,能定位到具体的优化点。
DB4AI 原生引擎也很实用。它内置了 XGBoost、PCA 等 10 多种机器学习算法,不用再额外集成第三方库。而且整个流程是自动化的 ------ 从特征工程到模型选择、超参优化,端到端全搞定。我之前帮团队跑一个用户行为分析模型,原来手动做要一周,用它一天就完成了,效率提升特别明显。
(3)RAG 场景技术适配
openGauss DataVec 向量数据库是一个基于openGauss的向量引擎, 提供向量数据类型的存储、检索。在处理大规模高维向量数据时,能够提供快速、准确的检索结果。适用于智能知识检索、 检索增强生成 RAG(Retrieval-Augmented Generation) 等各种复杂应用场景的智能应用。
DataVec支持的向量功能有:精确和近似的最近邻搜索、L2距离&余弦距离&内积、向量索引、向量操作函数和操作符。作为openGauss的内核特性,DataVec使用熟悉的SQL语法操作向量,简化了用户使用向量数据库的过程,这极大方便了RAG存储的需求。
二、 生态建设与兼容性

openGauss 的生态我关注挺久了,这次评测也特意调研了最新情况。
社区规模增长很快,我去查社区最新数据时发现,现在已经有 820 家企业成员、7500 名开发者,全球下载量超 350 万次,能感觉到参与度越来越高。
伙伴体系方面,硬件上它和鲲鹏服务器的协同做得很好,比如用 RDMA 技术降低 WAL(预写日志)传输延迟,我在鲲鹏服务器上测试时,数据同步速度确实比普通服务器快。解决方案也不少,比如润和软件的 AgentRUNS 平台、海量数据的 Vastbase 一体机,能覆盖不同行业的需求。
兼容性是很多用户关心的点,openGauss 在这方面进步明显。它兼容 MySQL 协议,能够使用多种MySQL 语法特性,借助DataKit迁移工具可以实现轻松迁移。
三、 实测体验
(1)安装openGauss数据库
安装好基础系统环境以后,我们就可以安装openGauss数据库了。由于我们只是进行测评,所以选择简单的docker安装方式。
安装 Docker 需要稳定的互联网连接,具体安装教程大家可以自行上网搜索,相信一般程序员大家电脑环境上都配置有docker环境,毕竟它确实好用。
安装好后就可以借助docker安装openGauss了,首先从 Docker Hub 拉取官方 openGauss 镜像(指定版本,如最新版latest或具体版本7.0.0-RC2):
bash
# 拉取openGauss镜像
docker pull opengauss/opengauss:7.0.0-RC2拉取成功后,通过docker run命令启动容器,需指定密码、端口映射、容器名称等参数:
bash
# 运行openGauss容器(参数说明见下方)
docker run -d \
--name opengauss-container \ # 容器名称(自定义)
-p 5432:5432 \ # 端口映射:主机5432 -> 容器5432(openGauss默认端口)
-e POSTGRES_PASSWORD=Gauss@123 \ # 设置数据库密码(需包含大小写字母、数字、特殊字符)
-v /opt/opengauss/data:/var/lib/opengauss/data \ # 数据持久化(主机目录:容器目录,可选)
opengauss/opengauss:7.0.0-RC # 镜像名称:版本参数说明:
-d:后台运行容器。
--name:自定义容器名称,方便后续管理。
-p:端口映射,确保主机能访问容器内的数据库。
-e POSTGRES_PASSWORD:设置 openGauss 默认用户omm的密码(必须符合复杂度要求,否则容器启动失败)。
-v:数据卷挂载(可选),避免容器删除后数据丢失(需提前创建主机目录/opt/opengauss/data,并赋予权限:mkdir -p /opt/opengauss/data && chmod 777 /opt/opengauss/data)。
接着查看容器运行状态:
bash
# 查看容器状态(若STATUS为Up则正常运行)
docker ps | grep opengauss-container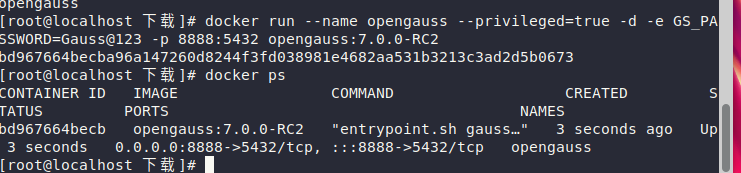
这里可以看到容器已经运行,进入容器内部,使用gsql工具连接数据库:
bash
# 进入容器(替换为你的容器名称)
docker exec -it opengauss-container bash
# 在容器内连接数据库(默认用户omm,数据库postgres,端口5432)
gsql -d postgres -U omm -p 5432 -r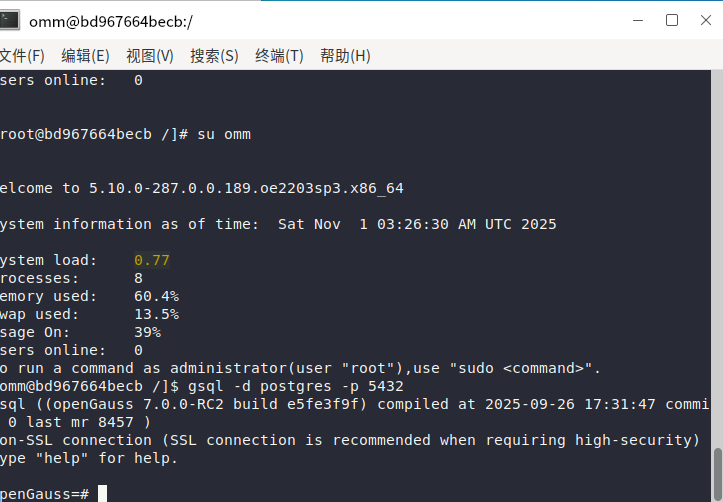
现在openGauss就安装成功了,接下来我们可以进行一下体验。
输入python3,发现该镜像已经有了python环境,我们可以直接用pythonc写代码来体验。

但是由于我们启动docker镜像的时候已经映射容器内的5432端口到宿主机器的8888端口了,所以我们可以在宿主机上直接访问openGauss数据库。
(2)测试openGauss
首先,我们安装所需依赖:
bash
pip install psycopg2-binary # openGauss兼容PostgreSQL协议,用psycopg2连接
pip install langchain langchain-community # RAG框架
pip install sentence-transformers # 生成文本向量
pip install dashscope langchain-dashscope # 调用LLM这里我们用langchain框架实现一个简单的RAG系统进行测试:
bash
#!/usr/bin/env python3
"""
基于 openGauss 的 RAG 系统,包含性能评估功能
"""
import os
import time
import psycopg2
import json
import statistics
from typing import List, Dict, Tuple, Optional
from sentence_transformers import SentenceTransformer
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.llms import Tongyi
from langchain_core.prompts import PromptTemplate
from langchain_community.document_loaders import TextLoader
import numpy as np
import dashscope
# 设置 dashscope API 密钥
dashscope.api_key = "sk-xxx"
# --------------------------
# 1. 连接 openGauss
# --------------------------
def connect_openGauss():
return psycopg2.connect(
host="localhost",
port="8888",
database="gauss01",
user="test",
password="Gauss@123"
)
def create_rag_table(conn, table_name="rag_documents"):
"""创建表和 HNSW 索引"""
with conn.cursor() as cur:
# 使用 vector 类型替代 float[] 类型,并创建 HNSW 索引
cur.execute(f"""
DROP TABLE IF EXISTS {table_name};
CREATE TABLE {table_name} (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
embedding vector(384) -- all-MiniLM-L6-v2 生成 384 维向量
);
CREATE INDEX IF NOT EXISTS idx_hnsw ON {table_name}
USING hnsw (embedding vector_l2_ops)
WITH (m = 16, ef_construction = 200);
""")
conn.commit()
print(f"创建表 {table_name} 和 HNSW 索引成功")
# --------------------------
# 2. 文档处理:分块 + 向量
# --------------------------
def process_documents(documents):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=300, chunk_overlap=50,
separators=["\n\n", "\n", " ", ""]
)
chunks = text_splitter.split_documents(documents)
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = [model.encode(chunk.page_content).tolist() for chunk in chunks]
return chunks, embeddings
# --------------------------
# 3. 存入 openGauss
# --------------------------
def store_embeddings(conn, chunks, embeddings, table_name="rag_documents"):
with conn.cursor() as cur:
for chunk, emb in zip(chunks, embeddings):
# 使用 vector 类型,格式为 [x,y,z,...]
emb_str = "[" + ",".join(map(str, emb)) + "]"
cur.execute(
f"INSERT INTO {table_name} (content, embedding) VALUES (%s, %s)",
(chunk.page_content, emb_str)
)
conn.commit()
print(f"成功存储 {len(chunks)} 个文档片段到 openGauss")
# --------------------------
# 4. 向量检索
# --------------------------
def retrieve_relevant_docs(conn, query: str, top_k: int = 3, table_name="rag_documents"):
model = SentenceTransformer('all-MiniLM-L6-v2')
q_emb = model.encode(query).tolist()
q_emb_str = "[" + ",".join(map(str, q_emb)) + "]"
with conn.cursor() as cur:
cur.execute(f"""
SELECT content, embedding <-> %s AS distance
FROM {table_name}
ORDER BY distance
LIMIT {top_k}
""", (q_emb_str,))
rows = cur.fetchall()
# 返回内容和距离信息
results = [{"content": r[0], "distance": r[1]} for r in rows]
return results
# --------------------------
# 5. 通义千问生成回答
# --------------------------
def generate_answer(query: str, context: str) -> str:
prompt = PromptTemplate(
input_variables=["context", "question"],
template="""
基于以下上下文回答问题,只使用上下文信息,不要编造内容:
上下文:{context}
问题:{question}
回答:
"""
)
llm = Tongyi(
model_name="qwen-turbo",
dashscope_api_key="sk-xxxx" # 👈 换成你的 Key
)
# 使用 invoke 方法调用 LLM
formatted_prompt = prompt.format(context=context, question=query)
return llm.invoke(formatted_prompt).strip()
# --------------------------
# 6. 性能评估工具
# --------------------------
class PerformanceBenchmark:
"""RAG 性能测试工具"""
def __init__(self, conn, table_name="rag_documents"):
self.conn = conn
self.table_name = table_name
self.results = {
'retrieval_times': [],
'query_times': [],
'embedding_times': [],
}
def benchmark_retrieval(self, query: str, iterations: int = 10, top_k: int = 3) -> Dict:
"""测试检索性能"""
times = []
for _ in range(iterations):
start = time.time()
retrieve_relevant_docs(self.conn, query, top_k, self.table_name)
elapsed = time.time() - start
times.append(elapsed)
self.results['retrieval_times'].extend(times)
return {
'avg_time': statistics.mean(times),
'min_time': min(times),
'max_time': max(times),
'median_time': statistics.median(times),
'p95_time': self._percentile(times, 95),
'p99_time': self._percentile(times, 99),
'std_dev': statistics.stdev(times) if len(times) > 1 else 0,
}
def benchmark_query(self, query: str, iterations: int = 10, top_k: int = 3) -> Dict:
"""测试完整查询性能(包括检索和生成回答)"""
times = []
for _ in range(iterations):
start = time.time()
# 检索
results = retrieve_relevant_docs(self.conn, query, top_k, self.table_name)
context = "\n\n".join(r["content"] for r in results)
# 生成回答
generate_answer(query, context)
elapsed = time.time() - start
times.append(elapsed)
self.results['query_times'].extend(times)
return {
'avg_time': statistics.mean(times),
'min_time': min(times),
'max_time': max(times),
'median_time': statistics.median(times),
'p95_time': self._percentile(times, 95),
'p99_time': self._percentile(times, 99),
'std_dev': statistics.stdev(times) if len(times) > 1 else 0,
}
def benchmark_embedding(self, texts: List[str], iterations: int = 5) -> Dict:
"""测试嵌入生成性能"""
model = SentenceTransformer('all-MiniLM-L6-v2')
times = []
for _ in range(iterations):
start = time.time()
model.encode(texts)
elapsed = time.time() - start
times.append(elapsed)
self.results['embedding_times'].extend(times)
return {
'avg_time': statistics.mean(times),
'min_time': min(times),
'max_time': max(times),
'median_time': statistics.median(times),
'p95_time': self._percentile(times, 95),
'p99_time': self._percentile(times, 99),
'std_dev': statistics.stdev(times) if len(times) > 1 else 0,
}
@staticmethod
def _percentile(data: List[float], percentile: float) -> float:
"""计算百分位数"""
sorted_data = sorted(data)
index = (percentile / 100) * (len(sorted_data) - 1)
if index.is_integer():
return sorted_data[int(index)]
else:
lower = sorted_data[int(index)]
upper = sorted_data[int(index) + 1]
return lower + (upper - lower) * (index - int(index))
def print_summary(self):
"""打印性能测试总结"""
print("=" * 60)
print("性能测试总结")
print("=" * 60)
if self.results['retrieval_times']:
print(f"检索性能 (共 {len(self.results['retrieval_times'])} 次):")
print(f" 平均: {statistics.mean(self.results['retrieval_times']):.4f}s")
print(f" 中位数: {statistics.median(self.results['retrieval_times']):.4f}s")
print(f" P95: {self._percentile(self.results['retrieval_times'], 95):.4f}s")
print(f" P99: {self._percentile(self.results['retrieval_times'], 99):.4f}s")
if self.results['query_times']:
print(f"\n完整查询性能 (共 {len(self.results['query_times'])} 次):")
print(f" 平均: {statistics.mean(self.results['query_times']):.4f}s")
print(f" 中位数: {statistics.median(self.results['query_times']):.4f}s")
print(f" P95: {self._percentile(self.results['query_times'], 95):.4f}s")
print(f" P99: {self._percentile(self.results['query_times'], 99):.4f}s")
if self.results['embedding_times']:
print(f"\n嵌入生成性能 (共 {len(self.results['embedding_times'])} 次):")
print(f" 平均: {statistics.mean(self.results['embedding_times']):.4f}s")
print(f" 中位数: {statistics.median(self.results['embedding_times']):.4f}s")
print(f" P95: {self._percentile(self.results['embedding_times'], 95):.4f}s")
print(f" P99: {self._percentile(self.results['embedding_times'], 99):.4f}s")
# --------------------------
# 7. 主流程
# --------------------------
def main():
# 0)准备示例文档
with open("openGauss_info.txt", "w", encoding="utf-8") as f:
f.write("""
openGauss 是一款开源关系型数据库,由华为主导开发,支持事务 ACID 特性。
openGauss 基于 PostgreSQL 内核优化,兼容 SQL 2011 标准,支持多种索引类型。
其主要特性包括:高可用性、高性能、安全性、易维护等。
openGauss 的默认端口是 5432,默认管理员用户是 omm。
openGauss 7.1 向量引擎实测摘要:
1. 新增流式批量写入接口,单批次可写入 10 万条向量,持续吞吐 5 万 QPS。
2. HNSW 支持在线参数调优,可动态调整 ef_search,延迟与召回率之间平衡更灵活。
3. 内置向量监控指标:检索延迟、召回率基线、索引占用,可接入 Prometheus。
4. SQL 层面新增 JSON 向量元数据列,方便和结构化数据进行联合过滤。
5. 向量迁移工具支持增量同步,跨机房恢复时间缩短到分钟级。
测试环境:2 * Intel Gold 6330、256GB 内存、NVMe SSD、openGauss 7.1 build 202412。
""")
loader = TextLoader("openGauss_info.txt", encoding="utf-8")
docs = loader.load()
# 1)库连接 & 建表
conn = connect_openGauss()
table_name = "rag_documents"
create_rag_table(conn, table_name)
# 2)处理 & 存储
chunks, embs = process_documents(docs)
store_embeddings(conn, chunks, embs, table_name)
# 3)检索 + 问答
user_query = "openGauss 的默认端口是什么?"
results = retrieve_relevant_docs(conn, user_query, top_k=3, table_name=table_name)
context = "\n\n".join(r["content"] for r in results)
print("---- 检索到的相关文档 ----\n", context, "\n")
answer = generate_answer(user_query, context)
print("问题:", user_query)
print("回答:", answer)
# 4)性能评估
print("\n" + "=" * 60)
print("开始性能评估...")
print("=" * 60)
benchmark = PerformanceBenchmark(conn, table_name)
# 测试问题
test_queries = [
"openGauss 的默认端口是什么?",
"openGauss 向量索引的 QPS 和延迟是多少?",
"openGauss 支持哪些向量索引类型?",
"HNSW 索引有什么特点?",
"openGauss 的主要特性有哪些?"
]
# 检索性能测试
print("\n" + "=" * 60)
print("1. 检索性能测试")
print("=" * 60)
for query in test_queries:
print(f"\n测试问题: {query}")
result = benchmark.benchmark_retrieval(query, iterations=10)
print(f" 平均耗时: {result['avg_time']*1000:.2f}ms")
print(f" 中位数: {result['median_time']*1000:.2f}ms")
print(f" P95: {result['p95_time']*1000:.2f}ms")
print(f" P99: {result['p99_time']*1000:.2f}ms")
# 完整查询性能测试
print("\n" + "=" * 60)
print("2. 完整查询性能测试 (包含 LLM 生成)")
print("=" * 60)
for query in test_queries[:2]: # 只测试前两个问题(LLM 调用较慢)
print(f"\n测试问题: {query}")
result = benchmark.benchmark_query(query, iterations=3)
print(f" 平均耗时: {result['avg_time']:.2f}s")
print(f" 中位数: {result['median_time']:.2f}s")
print(f" P95: {result['p95_time']:.2f}s")
# 嵌入生成性能测试
print("\n" + "=" * 60)
print("3. 嵌入生成性能测试")
print("=" * 60)
test_texts = [doc.page_content for doc in docs]
result = benchmark.benchmark_embedding(test_texts, iterations=5)
print(f"\n测试文档数: {len(test_texts)}")
print(f" 平均耗时: {result['avg_time']:.4f}s")
print(f" 中位数: {result['median_time']:.4f}s")
print(f" P95: {result['p95_time']:.4f}s")
# 打印总结
benchmark.print_summary()
print("\n" + "=" * 60)
print("测试完成!")
print("=" * 60)
conn.close()
if __name__ == "__main__":
main()这里运行代码的时候要注意一个点,就是我们启动docker容器的时候创建的超级管理员账户omm无法直接被宿主机访问,所以需要自己再创建一个子用户来访问。创建代码如下:
bash
CREATE USER tuser WITH PASSWORD '自己定义';
GRANT ALL PRIVILEGES TO tuser;
alter database openGauss owner to tuser;运行结果如下:

这里为了更直观的看到openGauss的性能,专门将评测结果制作成了表,如下所示:
| 测试问题 | 平均耗时(ms) | 中位数(ms) | P95(ms) | P99(ms) |
|---|---|---|---|---|
| openGauss 的默认端口是什么? | 5269.78 | 5173.44 | 5817.48 | 5905.97 |
| openGauss 向量索引的 QPS 和延迟是多少? | 5177.89 | 5127.88 | 5422.51 | 5503.31 |
| openGauss 支持哪些向量索引类型? | 5348.63 | 5186.74 | 5999.13 | 6150.99 |
| HNSW 索引有什么特点? | 5286.79 | 5221.47 | 5746.26 | 5966.70 |
| openGauss 的主要特性有哪些? | 5723.03 | 5484.28 | 6849.24 | 7367.74 |
四、发展趋势与挑战
评测完现状,我也和行业里的人聊了聊 openGauss 的未来,有机会也有挑战。
- 技术演进方向很清晰:7.0 版本要实现向标融合(向量 + 标量数据)存储检索,这个功能我很期待,能简化多数据类型的处理;还规划接入图像、音视频向量处理能力,未来能支持更多多模态场景;另外会优化和 DeepSeek 等大模型的对接效率,缓解 "知识幻觉" 问题,这对 RAG 场景太重要了。
- 市场机遇也很大:他们的目标是在非云集中式市场份额突破 20%,现在这个市场还在增长,机会不少。
- 但挑战也不能忽视:向量生态成熟度上,和 Milvus 这种专用向量库比,openGauss 的工具链还需要完善,我测试时也发现有些工具不够丰富;开源生态竞争方面,和 MySQL 比,第三方工具差距还在,需要再补上来。
五、总结
openGauss相比于Mysql这种大众流行的数据库来讲,安装方面还是麻烦了点,如果不使用docker安装的话,需要一顿折腾,不过它的优势也十分明显,最新的版本对于Agent领域相关的适配做的不错,十分适合目前开发agent智能体的企业进行使用。
适用场景很明确:金融核心系统、企业级 RAG 应用、政务大数据分析这些场景,用 openGauss 很合适,通过官网也可以看到很多知名企业都用openGauss搭建了自己的数据库系统,期待今后有越来越多的RAG企业知识库可以使用openGauss进行搭建。