1、char 类型
char 类型用于储存字符(如,字母或标点符号),但是从技术层面看,char 是整数类型。因为 char 类型实际上储存的是整数而不是字符。计算机使用数字编码来处理字符,即用特定的整数表示特定的字符。 美国最常用的编码是ASCII 编码,本书也使用此编码。例如,在ASCII码中,整数 65代表大写字母A。因 此,储存字母A实际上储存的是整数65(许多 IBM 的大型主机使用另一种编码------EBCDIC,其原理相同。 另外,其他国家的计算机系统可能使用完全不同的编码)。
C语言把1字节定义为 char 类型占用的位(bit)数,因此无论是16位还是32位系统,都可以使用 char 类型。
1.1. 声明 char 类型变量
char 类型变量的声明方式与其他类型变量的声明方式相同。下面是一些例子:
char response;
char itable, latan;以上声明创建了3个char 类型的变量: response、itable 和latan.
1.2 字符常量和初始化
如果要把一个字符常量初始化为字母 A,不必背下 ASCII 码,用计算机语言很容易做到。通过以下初 始化把字母A赋给 grade 即可:
char grade = 'A';在C语言中,用单引号括起来的单个字符被称为字符常量(character constant)。编译器一发现'A',就 会将其转换成相应的代码值。单引号必不可少。下面还有一些其他的例子:
char broiled; /* 声明一个 char 类型的变量 */
broiled = 'T': /* 为其赋值,正确 */
broiled = T; /* 错误! 此时T是一个变量 */
broiled = "T"; /* 错误!此时"T"是一个字符串 */如上所示,如果省略单引号,编译器认为是一个变量名;如果把用双引号括起来,编译器则认为 "T"是一个字符串。字符串的内容将在后面介绍
实际上,字符是以数值形式储存的,所以也可使用数字代码值来赋值:
char grade = 65; /* 对于ASCII,这样做没问题,但这是一种不好的编程风格 */在本例中,虽然65是int 类型,但是它在char 类型能表示的范围内,所以将其赋值给 grade 没问 题。由于65 是字母 A 对应的 ASCII 码,因此本例是把A赋给 grade。注意,能这样做的前提是系统使用 ASCII 码。其实,用''代替 65 才是较为妥当的做法,这样在任何系统中都不会出问题。因此,最好使用字 符常量,而不是数字代码值。
奇怪的是,C语言将字符常量视为int 类型而非 char 类型。例如,在int 为32位、char为8位的 ASCII 系统中,有下面的代码:
char grade = 'B';本来'B'对应的数值 66 储存在32位的存储单元中,现在却可以储存在8位的存储单元中(grade)。利 用字符常量的这种特性,可以定义一个字符常量'FATE',即把4个独立的8位 ASCII 码储存在一个32位存 储单元中。如果把这样的字符常量赋给 char 类型变量 grade,只有最后8位有效。因此,grade 的值 是'E'。
1.3 非打印字符
单引号只适用于字符、数字和标点符号,浏览 ASCII 表会发现,有些 ASCII 字符打印不出来。例如, 一些代表行为的字符(如,退格、换行、终端响铃或蜂鸣)。C语言提供了3种方法表示这些字符。
第1种方法前面介绍过------使用 ASCII 码。例如,蜂鸣字符的 ASCII 值是7,因此可以这样写:
char beep = 7;第2种方法是,使用特殊的符号序列表示一些特殊的字符。这些符号序列叫作转义序列(escape sequence)。表 3.2 列出了转义序列及其含义。
把转义序列赋给字符变量时,必须用单引号把转义序列括起来。例如,假设有下面一行代码:
char nerf = '\n';稍后打印变量nerf 的效果是,在打印机或屏幕上另起一行。
现在,我们来仔细分析一下转义序列。使用C90 新增的警报字符(\a)是否能产生听到或看到的警报, 取决于计算机的硬件,蜂鸣是最常见的警报(在一些系统中,警报字符不起作用)。C标准规定警报字符不 得改变活跃位置。标准中的活跃位置(active position)指的是显示设备(屏幕、电传打字机、打印机等) 中下一个字符将出现的位置。简而言之,平时常说的屏幕光标位置就是活跃位置。在程序中把警报字符输 出在屏幕上的效果是,发出一声蜂鸣,但不会移动屏幕光标。
接下来的转义字符\b、\f、 \n、\r、\t 和\v是常用的输出设备控制字符。了解它们最好的方式是查 看它们对活跃位置的影响。换页符(\f)把活跃位置移至下一页的开始处;换行符(\n)把活跃位置移至 下一行的开始处;回车符(\r)把活跃位置移动到当前行的开始处;水平制表符(\t) 将活跃位置移至下 一个水平制表点(通常是第1个、第9个、第17个、第25个等字符位置);垂直制表符(\v)把活跃位置 移至下一个垂直制表点。
这些转义序列字符不一定在所有的显示设备上都起作用。例如,换页符和垂直制表符在PC 屏幕上会生 成奇怪的符号,光标并不会移动。只有将其输出到打印机上时才会产生前面描述的效果。
接下来的3个转义序列(\\、\'、\")用于打印\、'、"字符(由于这些字符用于定义字符常量,是 printf()函数的一部分,若直接使用它们会造成混乱)。如果打印下面一行内容:
Gramps sez, "a \ is a backslash."应这样编写代码:
printf("Gramps sez, \"a \\ is a backslash.\"\n");表3.2 中的最后两个转义序列(\0oo 和\xhh) 是 ASCII 码的特殊表示。如果要用八进制 ASCII 码表 示一个字符,可以在编码值前面加一个反斜杠()并用单引号括起来。例如,如果编译器不识别警报字符 (\a),可以使用 ASCII 码来代替:
beep ='\007';可以省略前面的 0, '07'甚至\7,都可以。即使没有前缀0,编译器在处理这种写法时,仍会解释 为八进制。
1.4 打印字符
printf() 函数用%c指明待打印的字符。前面介绍过,一个字符变量实际上被储存为1字节的整数值。 因此,如果用%d 转换说明打印 char 类型变量的值,打印的是一个整数。而c转换说明告诉 printf() 打印该整数值对应的字符。程序清单3.5演示了打印 char 类型变量的两种方式。
#include <stdio.h>
int main(void)
{
char ch;
printf("Please enter a character: \n");
scanf("%c", &ch);
printf("The Code fof %c is %d.\n", ch, ch);
return 0;
}运行该程序后,示例输出如下:
Please enter a character:
d
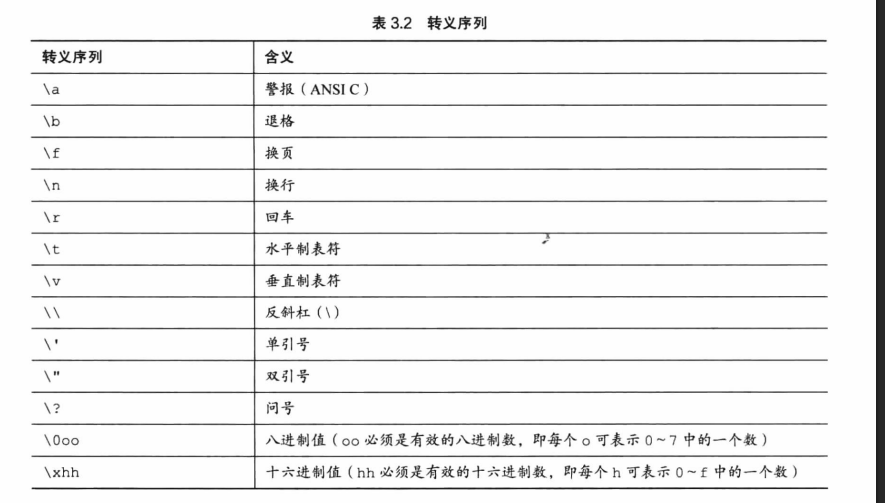
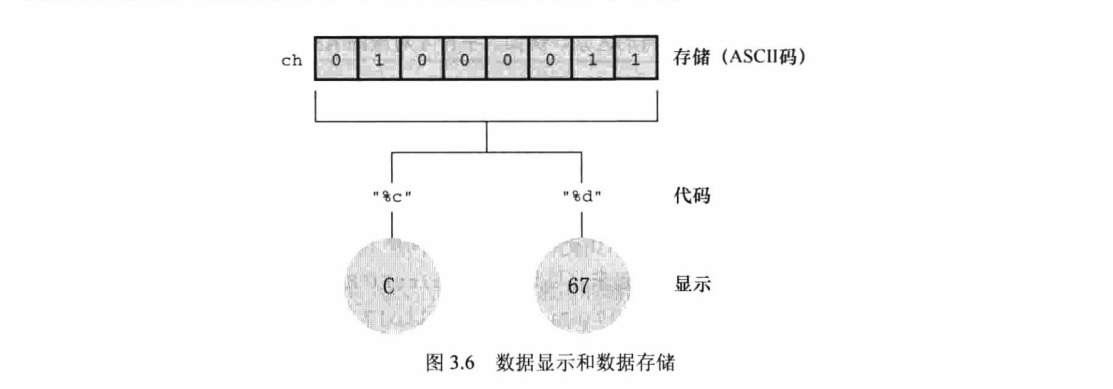
The Code fof d is 100.运行该程序时,在输入字母后不要忘记按下 Enter 或 Return 键。随后,scanf()函数会读取用户输 入的字符,符号表示把输入的字符赋给变量 ch。接着,printf()函数打印 ch 的值两次,第1次打印一 个字符(对应代码中的%c),第2次打印一个十进制整数值(对应代码中的d)。注意,printf()函数中 的转换说明决定了数据的显示方式,而不是数据的储存方式(见图 3.6)。
1.5 有符号还是无符号
有些C编译器把 char 实现为有符号类型,这意味着 char 可表示的范围是-128~127。而有些C编译 器把 char实现为无符号类型,那么 char 可表示的范围是0~255。请查阅相应的编译器手册,确定正在 使用的编译器如何实现 char 类型。或者,可以查阅 limits.h头文件。下一章将详细介绍头文件的内容。
根据 C90 标准,C语言允许在关键字 char 前面使用 signed 或 unsigned。这样,无论编译器默认 char 是什么类型, signed char 表示有符号类型,而 unsigned char 表示无符号类型。这在用 char 类型处理小整数时很有用。如果只用 char处理字符,那么 char 前面无需使用任何修饰符。
2. _Bool 类型
C99 标准添加了_Bool 类型,用于表示布尔值,即逻辑值 true 和 false。因为 C 语言用值1表示 true,值0 表示 false,所以_Bool 类型实际上也是一种整数类型。但原则上它仅占用1位存储空间, 因为对0和1而言,1位的存储空间足够了。
程序通过布尔值可选择执行哪部分代码。我们将在后面中详述相关内容。
3. 可移植类型:stdint.h 和 inttypes.h
C语言提供了许多有用的整数类型。但是,某些类型名在不同系统中的功能不一样。C99 新增了两个 头文件 stdint.h 和inttypes.h,以确保 C语言的类型在各系统中的功能相同。
1. <stdint.h>:定义固定大小的整数类型
提供了具有明确位宽的整数类型(如 8 位、16 位、32 位、64 位),以及最小/最大宽度类型、最快类型等。
| 类型 | 含义 | 典型取值范围(十进制) |
|---|---|---|
int8_t |
8 位带符号整数 | -128 ~ 127 |
uint8_t |
8 位无符号整数 | 0 ~ 255 |
int16_t |
16 位带符号整数 | -32768 ~ 32767 |
uint16_t |
16 位无符号整数 | 0 ~ 65535 |
int32_t |
32 位带符号整数 | -2147483648 ~ 2147483647 |
uint32_t |
32 位无符号整数 | 0 ~ 4294967295 |
int64_t |
64 位带符号整数 | -9223372036854775808 ~ 9223372036854775807 |
uint64_t |
64 位无符号整数 | 0 ~ 18446744073709551615 |
2. <inttypes.h>:提供格式化输入输出宏
为 <stdint.h> 中定义的类型提供对应的 printf 和 scanf 格式化宏(如 PRId32、SCNu16 等),确保跨平台的输入输出兼容性。
由于可移植类型的实际大小可能变化(如 int32_t 在某些平台可能是 long,在另一些平台是 int),直接使用 %d、%u 等格式符可能导致错误。<inttypes.h> 提供了对应的格式化宏,确保跨平台兼容性。
| 类型 | 打印带符号十进制 | 打印无符号十进制 | 打印无符号十六进制(小写) | 打印无符号十六进制(大写) |
|---|---|---|---|---|
int32_t |
PRId32 |
- | - | - |
uint32_t |
- | PRIu32 |
PRIx32 |
PRIX32 |
int64_t |
PRId64 |
- | - | - |
uint64_t |
- | PRIu64 |
PRIx64 |
PRIX64 |
intmax_t |
PRIdMAX |
- | - | - |
uintmax_t |
- | PRIuMAX |
PRIxMAX |
PRIXMAX |
其实在我们平常的开发中更多的还有size_t 和 ssize_t 这种类型
ssize_t 是 C 语言中一个带符号整数类型 (signed size type),专门用于表示字节数、长度或索引 ,其设计目的是能够容纳 size_t 类型的所有非负值,同时还能表示负数(通常用于错误码,如 -1 表示失败)。
一、核心定义与特性
1. 定义来源
ssize_t 并非 C 标准(C89/C99/C11)的一部分,而是POSIX 标准 (如 Unix、Linux、macOS 等类 Unix 系统)引入的类型,定义在 <sys/types.h> 头文件中。
- 在 Windows 系统中,类似的类型是
SSIZE_T(注意大写,定义在<BaseTsd.h>中),功能完全一致。
2. 大小与取值范围
- 大小 :通常与
size_t相同(size_t是无符号类型,用于表示"大小",如sizeof的返回值)。- 在 32 位系统中,
ssize_t和size_t均为 4 字节(32 位)。 - 在 64 位系统中,均为 8 字节(64 位)。
- 在 32 位系统中,
- 取值范围 :
- 由于是带符号类型,其范围为
[-2^(N-1), 2^(N-1)-1](N 为位宽)。 - 例如,64 位
ssize_t的范围是-9223372036854775808到9223372036854775807,刚好能容纳size_t的所有非负值(size_t范围是0到18446744073709551615),同时多出一个符号位用于表示负数。
- 由于是带符号类型,其范围为
| 类型 | 符号性 | 用途 | 典型函数返回值/参数 |
|---|---|---|---|
size_t |
无符号 | 表示非负大小、长度、索引 | sizeof 结果、malloc 参数 |
ssize_t |
带符号 | 表示可正可负的长度(含错误码) | read、write、send 返回值 |
二、常见使用场景
- I/O 操作返回值 :
read、write、recv、send、pread等。 - 字符串/内存操作 :如
getline(读取一行字符串,返回读取的字节数,失败返回-1)。 - 系统调用返回值 :如
accept(返回新连接的文件描述符,失败返回-1)、waitpid(返回子进程 ID,失败返回-1)。 - 自定义函数 :当函数需要返回"长度或错误码"时(如解析协议数据,成功返回字节数,失败返回
-1)
4、float、double和long double
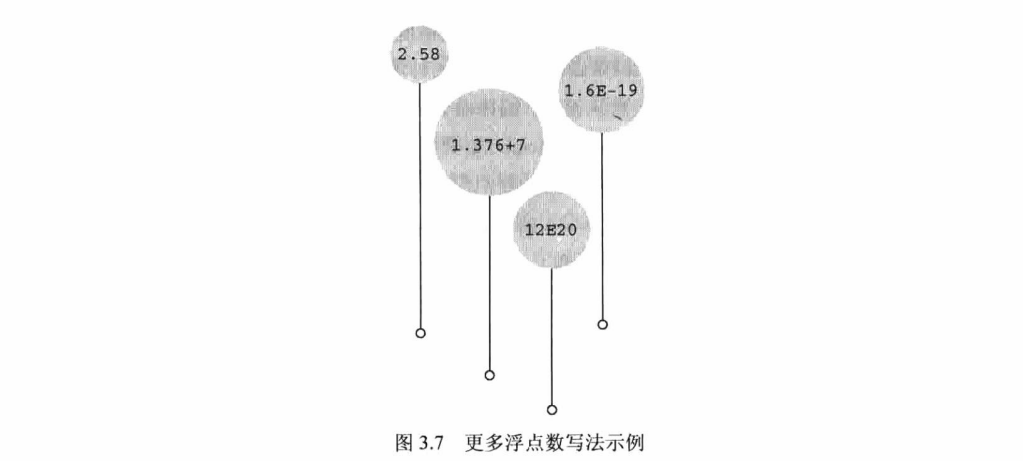
各种整数类型对大多数软件开发项目而言够用了。然而,面向金融和数学的程序经常使用浮点数。 C语言中的浮点类型有 float、double 和 long double 类型。它们与 FORTRAN 和 Pascal 中的 real 类型一致。前面提到过,浮点类型能表示包括小数在内更大范围的数。浮点数的表示类似于科学记数法 (即用小数乘以10的幂来表示数字)。该记数系统常用于表示非常大或非常小的数。表 3.3 列出了一些 示例。
 第1列是一般记数法;第2列是科学记数法;第3列是指数记数法(或称为e记数法),这是科学记数 法在计算机中的写法,后面的数字代表10的指数。图3.7 演示了更多的浮点数写法。
第1列是一般记数法;第2列是科学记数法;第3列是指数记数法(或称为e记数法),这是科学记数 法在计算机中的写法,后面的数字代表10的指数。图3.7 演示了更多的浮点数写法。
C标准规定,float 类型必须至少能表示6位有效数字,且取值范围至少是10的负37次方~10的正37次方。前一项规定 指 float 类型必须至少精确表示小数点后的6位有效数字,如33.333333。后一项规定用于方便地表示诸 如太阳质量(2.0e30千克)、一个质子的电荷量(1.6e-19 库仑)或国家债务之类的数字。通常,系统储存一 个浮点数要占用32位。其中8位用于表示指数的值和符号,剩下24位用于表示非指数部分(也叫作尾数 或有效数)及其符号。
C语言提供的另一种浮点类型是double (意为双精度)。double 类型和 float 类型的最小取值范围 相同,但至少必须能表示10位有效数字。一般情况下, double 占用64位而不是32位。一些系统将多出 的32位全部用来表示非指数部分,这不仅增加了有效数字的位数(即提高了精度),而且还减少了舍入误 差。另一些系统把其中的一些位分配给指数部分,以容纳更大的指数,从而增加了可表示数的范围。无论 哪种方法,double 类型的值至少有13位有效数字,超过了标准的最低位数规定。
C语言的第3种浮点类型是long double, 以满足比 double 类型更高的精度要求。不过,只保证 long double 类型至少与double 类型的精度相同。
5. 打印浮点值
printf()函数使用%转换说明打印十进制记数法的float 和 double 类型浮点数,用e 打印指数 记数法的浮点数。如果系统支持十六进制格式的浮点数,可用a和A分别代替e和E。打印 long double 类型要使用%Lf、%Le 或La 转换说明。给那些未在函数原型中显式说明参数类型的函数(如,printf()) 传递参数时,C编译器会把 float 类型的值自动转换成 double 类型