同步至个人网站:LLM扫盲: 什么是tokens

LLM 基础:什么是 Tokens?
GPT 5.1 发布已经有一段时间了,LLM(大语言模型)的能力边界再一次被拓宽。对于应用开发者而言,虽然模型越来越智能,但 API 的计费逻辑和底层限制依然没有变:Token 始终是那个核心计量单位。
很多人对 Token 有误解,认为它等同于字符(Character)或单词(Word)。这种误解往往导致两个问题:一是预估 API 成本时出现较大偏差,二是无法精确控制 Prompt 的上下文长度,导致模型"失忆"。
今天,我们再来系统地梳理一下 Token 的概念。
机器如何阅读文本?
计算机只能处理数字,不能直接处理文本。因此,当我们向 LLM 发送一段话时,必须经历一个转码过程。
- 输入文本:人类语言。
- Tokenization(分词):将文本切分成一个个具备语义的最小单位(Token),并转换为数字 ID。
- 模型计算:模型对这些数字 ID 进行预测和计算。
Token 就是这个中间层的最小单位。
为什么不直接用"汉字"或"单词"做单位?
- 字符粒度太细 :如果用字符(如
a,b,c),语义太稀疏,模型计算量会呈指数级上升。 - 单词粒度太粗:人类语言词汇量太大,且不断有新词产生,这会导致模型的词表(Vocabulary)过于庞大。
因此,LLM 采用的是 Sub-word(子词) 方案:常用的词是一个 Token,不常用的词拆分成多个 Token。
Token 的切分原理
Token 的切分规则并非一成不变,不同模型使用的编码器(Encoding)不同,结果也不同。
英文与中文的差异
- 英文 :通常一个单词是一个 Token,但复杂的词会被拆分。例如
smart是一个,但合成词或生僻词会被拆解。 - 中文:在 GPT-3 时,中文非常"吃亏",一个汉字往往需要 2-3 个 Token。
到了现在的 GPT-5.1 ,Token 编码(如 o200k_base 或更新的编码集)对多语言进行了深度优化。 目前,绝大多数常用汉字,1 个汉字 = 1 个 Token。只有极少数生僻字或复杂的古文,才会被拆解。
这意味着,同样的预算,现在能处理的中文内容比两三年前多了将近一倍。
代码演示(Node.js)
光说概念比较抽象,我们直接看代码。
在 Web 开发或 Node.js 环境中,我们通常使用 npm 包 @dqbd/tiktoken 来在本地计算 Token 数,这比每次调用 API 估算要快得多,也更省钱。
安装:
bash
npm install @dqbd/tiktoken代码示例:
javascript
import { encoding_for_model } from "@dqbd/tiktoken"
// 获取 GPT-5.1
const enc = encoding_for_model("GPT-5.1")
const text = "AI技术"
// 将文本转换为 Token ID 数组
const tokens = enc.encode(text)
console.log(tokens)
// 输出可能是: Uint32Array(2) [ 12345, 67890 ]
// 解释:'AI' 是一个 Token,'技术' 作为一个常用词可能被编码为一个 Token,或者两个汉字各一个。
console.log("Token Count:", tokens.length)
// 记得释放内存
enc.free()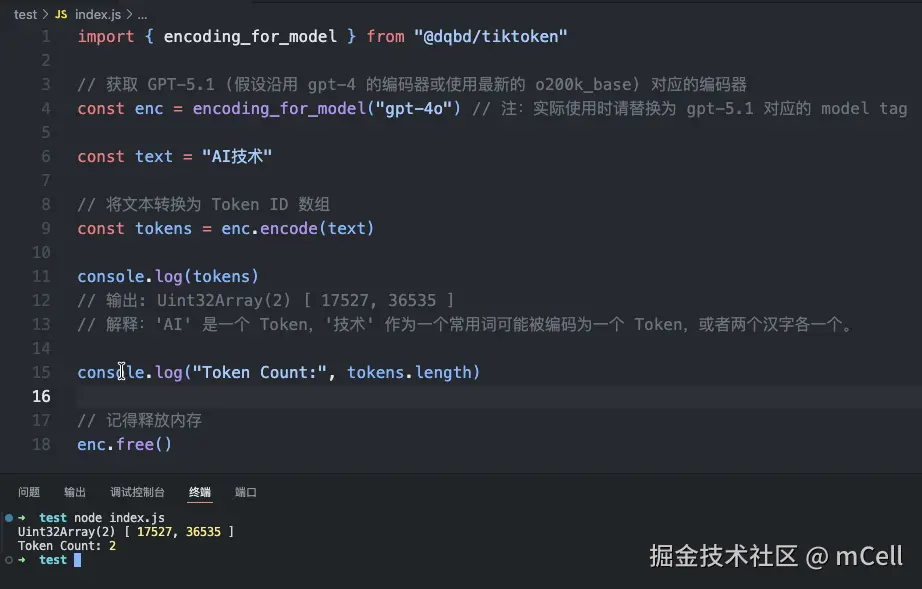
通过这种方式,你可以在发送请求前,精确地知道这段文本会消耗多少 Token。
Token 的实际影响
理解 Token 主要为了解决两个现实问题。
计费(Cost)
API 计费公式通常是:(Input Tokens + Output Tokens)× 单价。
值得注意的是,随着模型迭代(如 GPT-5.1),推理成本虽然在下降,但 Output(生成内容)的价格通常依然高于 Input(输入内容)。
- Input:你发给模型的 Prompt。
- Output:模型生成的回答。
如果你的业务场景是"读长文、写摘要",成本相对可控;如果是"读短句、写长文",成本会显著增加。
上下文窗口(Context Window)
这是 Token 最关键的物理限制。
虽然 GPT-5.1 的上下文窗口已经非常大(通常在 128k 甚至 200k tokens 以上),但它依然不是无限的。
- 早期模型:GPT-3.5 只有 4k context(约 3000 汉字),稍微聊几句就得"遗忘"前面的对话。
- 当前模型:128k context 意味着你可以一次性把几本长篇小说塞给模型。
但是,"能塞进去"不代表"效果好"。虽然 Token 容量变大了,但输入的内容越多,模型对中间信息的"注意力"(Attention)可能会被稀释。因此,开发者依然需要利用 RAG(检索增强生成)等技术,精简输入给模型的 Token,这不仅是为了省钱,更是为了提高回答的准确率。
四、 总结
- Token 是计费和计算的单位:它介于字符和单词之间。
- 中文效率已大幅提升:在 GPT-5.1 时代,中英文的 Token 效率差距已大大缩小,基本可以按 1 字 = 1 Token 估算。
- 开发者应当在本地计算 :使用
@dqbd/tiktoken等库在本地预计算 Token,是控制成本和上下文管理的最佳实践。
理解 Token,是开发 LLM 应用的第一步,也是从"用户"进阶为"开发者"的必修课。
(完)