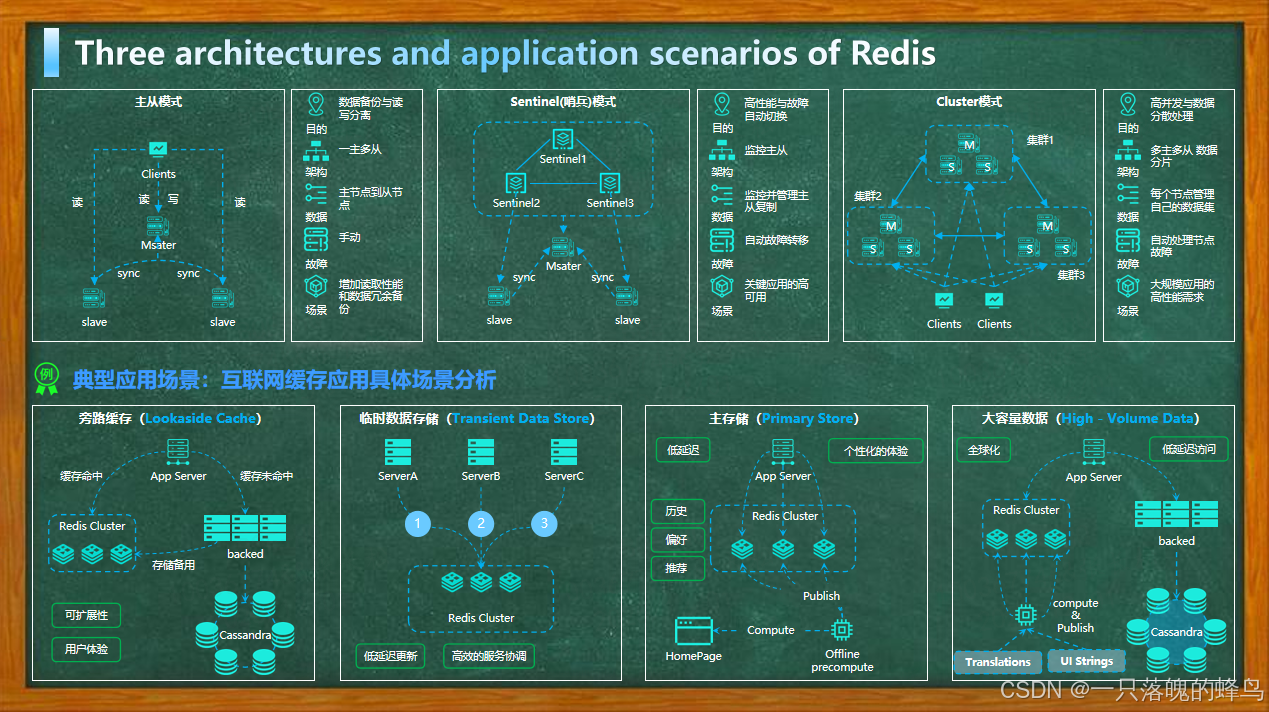
Redis Architectures and Application Scenarios
1. Standalone Architecture
- Description: The simplest deployment mode where Redis runs as a single instance, storing all data in memory.
- Use Cases :
- Development and testing environments where high availability is not required.
- Small-scale applications with low traffic and no need for failover.
- Caching layer for read-heavy workloads (e.g., session storage, API response caching).
2. Master-Slave Replication
- Description: A primary-replica setup where the master node handles writes, and one or more replicas replicate data for read scaling and backup.
- Use Cases :
- Read-heavy applications (e.g., news feeds, product catalogs) where replicas serve read requests.
- Disaster recovery, ensuring data redundancy by replicating to slave nodes.
- Temporary scaling for analytics workloads by directing queries to replicas.
3. Redis Cluster
- Description: A distributed architecture that partitions data across multiple nodes (sharding) while providing automatic failover and high availability.
- Use Cases :
- Large-scale applications requiring horizontal scalability (e.g., social media platforms, real-time leaderboards).
- High-availability systems where node failures must not disrupt service.
- Geographically distributed deployments to reduce latency (e.g., global session storage).
Each architecture serves different needs, from simplicity (standalone) to scalability (cluster) and read optimization (master-slave). The choice depends on performance, availability, and data consistency requirements.