(8 条消息) 【必看】历史技术文章导航 - 知乎
😊文章背景
题目:MM-LLMs: Recent Advances in MultiModal Large Language Models
期刊:arxiv.org
作者:Duzhen Zhang1*‡ , Yahan Yu3* , Jiahua Dong4†, Chenxing Li1 , Dan Su1, Chenhui Chu3† and Dong Yu2
单位:腾讯AI实验室,中国 2腾讯AI实验室,美国 3京都大学,日本
发表年份: 2024
网址:2401.13601 MM-LLMs: Recent Advances in MultiModal Large Language Models
📌重要公式
公式 1:模态编码 (Modality Encoding)
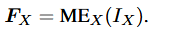
- 含义:这是处理的第一步,将原始数据转化为机器能理解的特征。
- 变量解释 :
- IX(Input):原始模态输入。XX 代表模态类型(如图像、视频、音频)。
- EX (Encoder) :模态编码器。通常是预训练好的模型(如 ViT-L/14 , CLIP 的视觉塔)。
- FX (Features):输出的特征向量。例如,一张图片经过 CLIP 编码后,可能会变成 256×1024256×1024 维度的张量。
- 注 :这一步通常不进行梯度更新(即 Frozen),目的是保留编码器强大的特征提取能力。
公式 2:输入投影/对齐 (Input Projection)
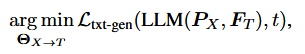
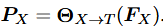
- 含义 :这是 MM-LLM 最关键的一步! 它的作用是"翻译"。因为 LLM 只能理解文本(Text, T),看不懂图像特征 (FX)。这个公式把图像特征映射到文本特征空间。
- 变量解释 :
- PX (Prompts) :对齐后的特征,我们称之为 Soft Prompts。
- FT:用户输入的文本特征
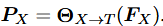 (Input Projector) :输入投影器。有两种类型:
(Input Projector) :输入投影器。有两种类型:
- 简单的 Linear Layer(如 LLaVA);
- 复杂的 Q-Former(如 BLIP-2)。
- 直观理解:经过这一步,原本的图片在 LLM 眼里就变成了"一串特殊的单词向量",LLM 可以像处理文本一样处理这些向量。
公式 3:LLM 处理与输出 (LLM Backbone)
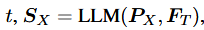
- 含义:LLM 接收多模态 Prompt 和 文本 Prompt,进行推理,并输出结果。
- 变量解释 :
- FT:用户输入的纯文本特征。
- PX:公式2得到的其他模态 Prompt。
- t:LLM 生成的文本回复(Text Response)。
- SX (Signal Token) :来自其他模态的信号token作为指令,指导生成器是否产生MM内容 。例如如果模型需要画图,LLM 会输出一个特殊的触发词(如
<Image>),这个 token 包含了生成的指令信息。
公式 4:输出投影器的对齐 (Alignment of Output Projector)
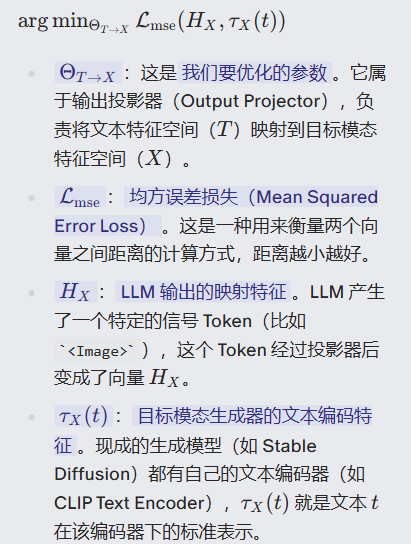 、
、
注:训练输出投影器,让它把 LLM 想要表达的内容(HX),尽可能模仿成生成模型最熟悉的文本特征(τX(t)。目的是让 LLM 的输出"伪装"成标准文本编码器的输出,这样后面的生成模型就不需要重新大规模训练,直接拿来用即可。
公式 5:基于扩散模型的生成 (Generation via Diffusion Model)

注:这是扩散模型的标准训练逻辑------去噪(Denoising) 。 模型试图预测加在图像上的噪声 ϵϵ,如果预测得准(ϵϵ 和 ϵXϵX 的差值越小),模型就能成功地从纯噪声中还原出清晰的图像。 与传统 SD 的区别在于 :这里的引导条件不是用户输入的 prompt,而是 LLM 输出并经过对齐的特征 HXHX。
🧠 核心背景与动机
-
从传统到 MM-LLMs: 过去的多模态(MM)预训练模型随着规模扩大,计算成本极高。 现在的研究趋势是利用现成的、功能强大的单模态基础模型(特别是 LLM)来降低计算成本并提高效率 。
-
MM-LLMs 的定义: 利用 LLM 作为「认知引擎(Cognitive Powerhouse)」来驱动多模态任务。 LLM 提供了语言生成、零样本迁移(Zero-shot transfer)和上下文学习(ICL)等能力。
-
核心挑战: 如何有效地连接 LLM 与其他模态模型以进行协同推理 。
⭐通用模型框架( Model Architecture)
论文提出了一个由五个组件构成的通用架构 :
- 模态编码器(Modality Encoder, MEX) :
- 负责将图像、视频、音频等输入编码为特征。
- 常见选择:Visual (ViT, CLIP, NFNet-F6), Audio (C-Former, HuBERT), 3D (ULIP-2) 等 。
- 输入投影器 (Input Projector, ΘX→T) :
- 负责将其他模态的特征对齐到文本特征空间,使其能被 LLM 理解。
- 实现方式:线性投影器 (Linear Projector)、MLP、Cross-attention、Q-Former (BLIP-2)、P-Former 等 。
- LLM 骨干 (LLM Backbone) :
- 核心代理,负责语义理解、推理和决策。
- 常见模型:Flan-T5, LLaMA, Vicuna, Qwen 等 。
- 高效微调 (PEFT):通常使用 LoRA, Prefix-tuning 等方法,仅训练极少量的参数(<0.1%)。
- 输出投影器 (Output Projector, ΘT→X) :
- 将 LLM 输出的信号 token 映射为后续生成器可理解的特征 。
- 实现方式:Tiny Transformer 或 MLP 。
- 模态生成器 (Modality Generator, MGX) :
- 负责生成特定的多模态输出(如图像、视频)。
- 常见模型:Stable Diffusion (图像), Zeroscope (视频), AudioLDM (音频) 。
注:专注于"理解"的模型通常只包含前三个部件 。
🗡 训练流程 (Training Pipeline)
MM-LLMs 的训练主要分为两个阶段 :
-
MM PT (多模态预训练):利用 X-Text 数据集(如图形-文本对)训练输入和输出投影仪,以实现模态间的对齐 。
-
MM IT (多模态指令微调):
-
SFT (监督微调):使用指令格式的数据集微调模型,使其能遵循新指令并泛化到未见过的任务 。
- RLHF (基于人类反馈的强化学习):进一步根据人类反馈(如 NLF)进行微调,以对齐人类意图并增强互动能力 。
🌙 发展趋势和分类( SOTA MM-LLMs)
论文将 126 个 SOTA 模型进行了分类 :
-
功能演进:
-
从专注于 MM 理解( 如 BLIP-2, LLaVA) 。
-
发展到 特定模态生成 (如 MiniGPT-5, SpeechGPT) 。
-
最终迈向 任意模态转换 (Any-to-Any) (如 NEXT-GPT, Gemini) 。
-
-
主要趋势 :
-
从单一理解向任意模态转换发展 。
-
训练流程不断优化(PT -> SFT -> RLHF)。
-
扩展到更多样化的模态(如 3D、视频)。
-
使用更高质量的训练数据集 。
-
采用更高效的模型架构(从复杂的 Q-Former 转向简单的线性投影器)。
-
🍎 性能与训练秘诀 (Benchmarks & Recipes)
通过对18个视觉-语言基准测试的分析,论文总结了提升MM-LLMs性能的关键秘诀:
-
图像分辨率: 更高的分辨率(如 336x336 或 448x448)能提供更多细节,有利于细粒度任务,但会增加成本 。
-
高质量 SFT 数据: 加入高质量的指令微调数据(如 ShareGPT4V)能显著提升性能 。
-
**数据混合策略:**交错的(Interleaved)图像-文本数据比单纯的图文对更有利 。在 SFT 期间混合纯文本指令数据有助于保持 LLM 的纯文本能力并提升视觉语言任务的准确性
🔮 未来研究方向
- 更通用与智能的模型: 扩展更多模态(如网页、热力图)、多样化 LLM 选择、提升 MM 生成能力(结合检索增强 RAG)。
- 更具挑战性的基准测试: 构建更大规模、包含更多模态且评估标准统一的基准(如评估幻觉、信任度、数学推理等)。
- 移动/轻量化部署: 在资源受限设备上运行(如 MobileVLM, TinyGPT-V)。
- 具身智能(Embodied Intelligence): 应用于机器人,使其能像人类一样感知和与环境互动(如 PaLM-E)。
- 持续学习 (Continual Learning): 让模型能学习新任务而不遗忘旧知识(解决灾难性遗忘问题)。
- 减少幻觉( Mitigating Hallucination): 解决模型生成与视觉事实不符的描述问题 。
📕专业名词
🔷 一、模型总体概念
| 术语 / 缩写 | 全称 | 专业定义 | 外行解释 |
|---|---|---|---|
| MM-LLM | MultiModal Large Language Model | 能处理图像、文本、视频、音频等多种模态的大模型 | "不仅能看文字,还能看图、听声音的视频版 ChatGPT" |
| Modality(模态) | --- | 信息格式,如图像/文本/音频等 | 一种"感知方式",比如视觉、听觉等 |
| Any-to-Any 模态转换 | --- | 输入/输出任意模态的统一模型 | "给什么都能理解,要什么都能生成" |
🔷 二、训练流程相关
| 术语 / 缩写 | 全称 | 专业定义 | 外行解释 |
|---|---|---|---|
| PT | Pre-Training | 大规模预训练阶段,学习基础知识 | 打基础:让模型"识字""看图" |
| MM PT | MultiModal Pre-Training | 多模态预训练,用图文/视频文等训练 | 让模型既能看图又能看字 |
| IT | Instruction Tuning | 指令微调 | 教模型听懂命令 |
| MM IT | MultiModal Instruction Tuning | 多模态指令微调(图+文指令) | 教模型听懂"看图后做事"的命令 |
| SFT | Supervised Fine-Tuning | 有标注的数据微调 | 通过例子教模型规范回答 |
| RLHF | Reinforcement Learning from Human Feedback | 人类反馈强化学习 | 人类告诉模型"怎么回答更好" |
🔷 三、模型结构组件
| 术语 / 缩写 | 全称 | 专业定义 | 外行解释 |
|---|---|---|---|
| Modality Encoder(ME) | --- | 把图/音/视频转为模型可处理的特征 | 把图片变成数字 |
| Input Projector | --- | 把非文本模态特征投射到文本空间 | 把"图像特征"翻译成"文本语言" |
| LLM Backbone | --- | 核心文字大脑(如 LLaMA、Qwen) | 模型的"语言引擎" |
| Output Projector | --- | 把 LLM 输出转为可供图像/音频生成器使用的特征 | 让模型能把想法变成图片 |
| Modality Generator(MG) | --- | 负责生成图像/视频/音频的模块 | 模型的"画图器 / 合成器" |
🔷 四、常见子模块结构
| 术语 / 缩写 | 全称 | 专业定义 | 外行解释 |
|---|---|---|---|
| Q-Former | Query-Former | 用可学习 query 提取多模态关键信息 | "只抓图像里最重要的细节" |
| P-Former | Prompt-Former | 生成参考提示,指导对齐 | 让模型学会"按规则提取信息" |
| MQ-Former | Multi-Scale Q-Former | 多尺度对齐视觉与文本特征 | 更精细地"看图" |
| Cross-Attention | --- | 让不同模态互相关注 | 告诉模型:图片哪个部分与这句话相关 |
🔷 五、编码器(视觉/音频等)
| 术语 / 缩写 | 全称 | 专业定义 | 外行解释 |
|---|---|---|---|
| ViT | Vision Transformer | Transformer 架构的视觉编码器 | 把图切成小块再理解 |
| CLIP | Contrastive Language--Image Pretraining | 学会对齐图像与文字 | "看图 + 配对文字"模型 |
| EVA-CLIP / OpenCLIP | --- | 加强版 CLIP | 更强的"图文对齐器" |
| BEATs / HuBERT | --- | 自监督音频编码器 | 听声音并转成特征 |
| ImageBind | --- | 把多模态统一到同一个向量空间 | 图像、声音等"同一种语言" |
🔷 六、生成模型相关术语
| 术语 / 缩写 | 全称 | 专业定义 | 外行解释 |
|---|---|---|---|
| LDM | Latent Diffusion Model | 潜空间扩散模型(如 Stable Diffusion) | AI 画图的主流方法 |
| Stable Diffusion | --- | 常用 LDM 图像生成器 | AI 画图软件本体 |
| Zeroscope | --- | 视频扩散模型 | AI 生成视频 |
| AudioLDM | --- | 音频扩散模型 | AI 生成声音 |
| VAE | Variational AutoEncoder | 将图像压缩到 latent 空间 | 把图像压成"潜在数字" |
🔷 七、训练目标与损失
| 术语 / 缩写 | 全称 | 外行解释 |
|---|---|---|
| Ltxt-gen | 文本生成损失 | 让模型"用图片生成正确文字" |
| LX-gen | X 模态生成损失 | 让模型画图/生成音频时更逼真 |
| Lmse | MSE 损失(均方误差) | 让投影后的特征更接近真正生成器需要的特征 |
🔷 八、评测与任务数据集
| 缩写 | 全称 | 外行解释 |
|---|---|---|
| VQAv2 | Visual Question Answering v2 | 看图问答 |
| OKVQA | Open Knowledge VQA | 需要常识的看图问答 |
| MMBench | Multi-Modal Benchmark | 综合多模态能力测评 |
| MM-Vet | MultiModal Vet | 评估推理能力的测试 |
🔷 九、典型能力与现象
| 术语 | 含义 | 外行解释 |
|---|---|---|
| Hallucination(幻觉) | 模型胡编不存在的内容 | "AI 乱说" |
| CoT(Chain-of-Thought) | 思维链推理 | "展示解题步骤" |
| Catastrophic Forgetting(灾难性遗忘) | 持续学习忘旧知识 | 学新任务忘老任务 |