这篇文章介绍了一种名为DEIMv2的新型实时目标检测系统,它在多个模型尺寸上都实现了卓越的性能,同时保持了高效的计算效率。以下是文章的主要研究内容总结:
1. 研究背景与动机
-
实时目标检测的重要性:在自动驾驶、机器人技术和工业缺陷检测等领域,实时目标检测是关键组成部分。然而,在轻量级模型中实现检测性能和计算效率之间的良好平衡仍然是一个挑战。
-
DETR方法的优势:基于DETR(Detection Transformer)的方法因其端到端设计和由Transformer赋予的高容量而受到关注。DEIM(DEtection with Improved Matching)作为实时DETRs的主流训练框架,已经显著优于YOLO系列。
-
DINOv3的潜力:DINOv3在各种视觉任务中展示了强大的特征表示能力,但其在实时目标检测中的潜力尚未得到充分挖掘。
2. DEIMv2的设计与实现
-
模型架构:DEIMv2基于之前的DEIM框架,并引入了DINOv3的特性。它涵盖了从超轻量级(如Nano、Pico、Femto、Atto)到高性能(如X、L、M、S)的八种模型尺寸,适用于不同的部署场景。
-
关键组件:
-
空间调谐适配器(STA):STA能够将DINOv3的单尺度输出高效地转换为多尺度特征,并补充精细的细节特征,以增强目标检测的性能。
-
高效解码器:通过引入SwishFFN和RMSNorm等技术,简化了解码器的设计,提高了效率。
-
增强型Dense O2O:通过Copy-Blend技术在对象级别增加监督,进一步提升了模型性能。
-
3. 实验与结果
-
性能提升:
-
大型模型:DEIMv2-X以仅50.3M参数达到了57.8AP,超越了之前需要超过60M参数才能达到56.5AP的模型。
-
小型模型:DEIMv2-S成为首个参数少于10M的模型,其在COCO上的AP超过了50,达到了50.9AP。
-
超轻量级模型:DEIMv2-Pico仅用1.5M参数就达到了38.5AP,与YOLOv10-Nano(2.3M参数)相当,但参数减少了约50%。
-
-
与现有技术的比较:DEIMv2在多个模型尺寸上均优于现有的最新方法,无论是在参数数量、计算量(FLOPs)还是检测精度上。
4. 研究贡献与结论
-
主要贡献:
-
提出了DEIMv2,一个涵盖多种模型尺寸的实时目标检测框架。
-
利用DINOv3的强语义特征,并通过STA高效整合到实时目标检测中。
-
通过剪枝技术优化了超轻量级模型,以满足严格的资源限制。
-
通过简化解码器和升级Dense O2O,进一步提升了性能。
-
-
结论:DEIMv2不仅在准确性上达到了新的高度,而且在效率上也表现出色,适用于从边缘设备到高性能系统的广泛场景。
文章指出,尽管DEIMv2在中型到大型目标的检测上表现出色,但在小型目标的检测上仍有改进空间。未来的研究可能会集中在如何更好地整合DINOv3的特征,以提高对小型目标的检测能力,进一步提升实时目标检测系统的性能和适用性。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:
官方项目主页地址在这里,如下所示:

项目地址在这里,如下所示:
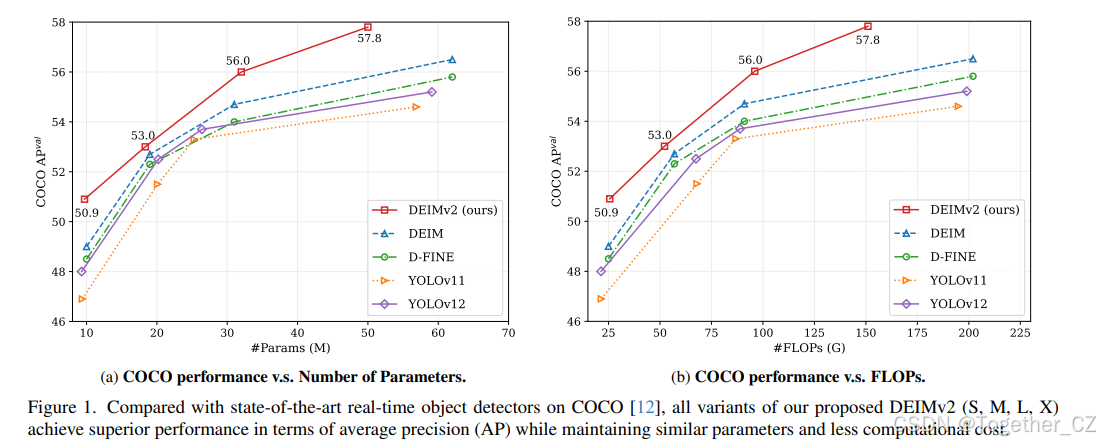
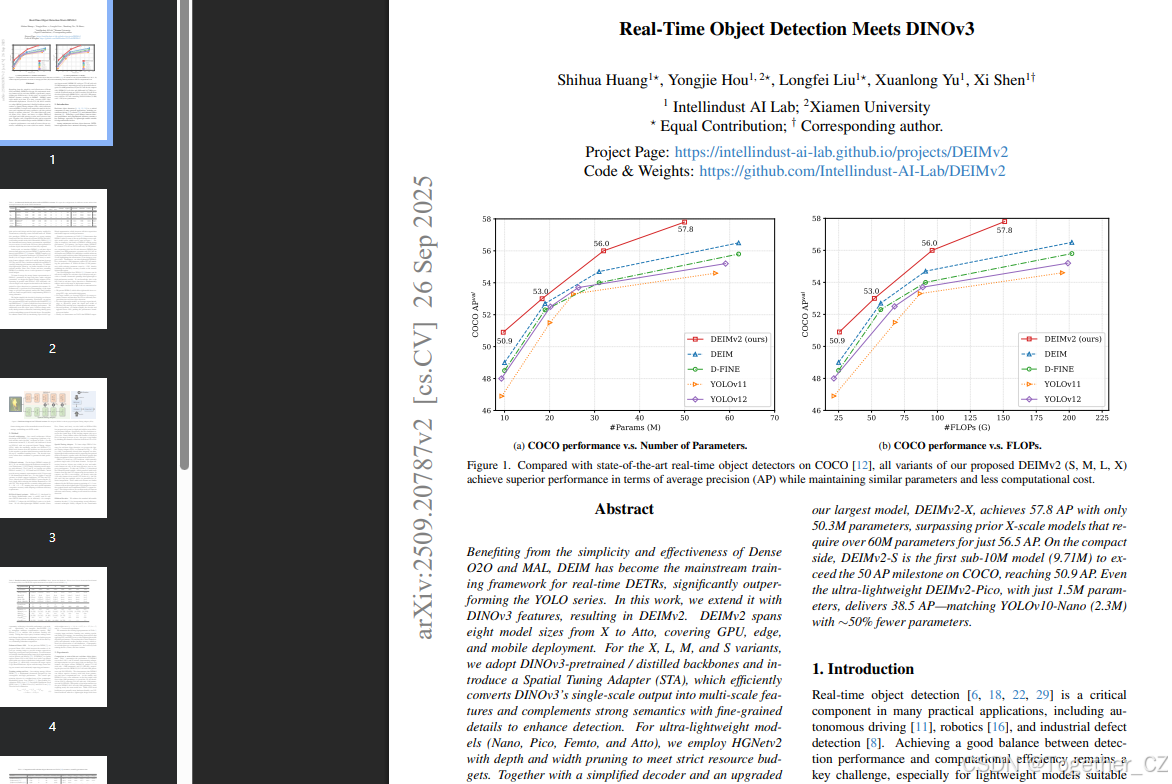
图 1. 与 COCO 12 上的最新实时目标检测器相比,我们提出的 DEIMv2(S、M、L、X)的所有变体在平均精度(AP)方面均实现了卓越性能,同时保持了类似的参数数量和较少的计算量。
摘要
得益于 Dense O2O 的简洁性和有效性以及 MAL,DEIM 已成为实时 DETRs 的主流训练框架,显著优于 YOLO 系列。在本工作中,我们将 DINOv3 特性引入其中,从而得到了 DEIMv2。DEIMv2 涵盖从 X 到 Atto 的八种模型尺寸,适用于 GPU、边缘和移动部署。对于 X、L、M 和 S 变体,我们采用了 DINOv3 预训练 / 蒸馏的骨干网络,并引入了空间调谐适配器(STA),它能高效地将 DINOv3 的单尺度输出转换为多尺度特征,并用精细细节补充强语义以增强检测效果。对于超轻量级模型(Nano、Pico、Femto 和 Atto),我们采用了深度和宽度剪枝的 HGNetv2 以满足严格的资源预算。结合简化后的解码器和升级版 Dense O2O,这种统一设计使 DEIMv2 在各种场景中均实现了卓越的性能 - 成本权衡,确立了新的最新成果。值得注意的是,我们最大的模型 DEIMv2-X 仅用 50.3M 参数就达到了 57.8AP,超越了之前需要超过 60M 参数才能达到 56.5AP 的 X 尺度模型。在紧凑型方面,DEIMv2-S 是首个参数少于 10M(9.71M)的模型,其在 COCO 上的 AP 里程碑达到了 50.9。即使是参数仅为 1.5M 的超轻量级 DEIMv2-Pico,也实现了 38.5AP------与 YOLOv10-Nano(2.3M)相当,但参数减少了约 50%。
1. 引言
实时目标检测 6,18,22,29 是许多实际应用中的关键组成部分,包括自动驾驶 11、机器人 16 和工业缺陷检测 8。在轻量级模型(适合边缘和移动设备)中实现检测性能和计算效率之间的良好平衡仍然是一个关键挑战。
在主流的实时目标检测器中,基于 DETR 的方法因其端到端的设计以及由 Transformer 所赋予的高容量而受到越来越多的关注,实现了更有利的权衡。在这种范式中,DEIM 已成为一个强大的训练框架,推动了实时 DETRs 的发展,并在该领域提供了领先的模型。与此同时,DINOv3 21 在各种视觉任务中展示了强大的特征表示能力。然而,其在实时目标检测中的潜力尚未得到充分挖掘。
在本工作中,我们介绍了 DEIMv2,这是一个基于我们之前的 DEIM 7 流水线构建的实时目标检测器,并引入了 DINOv3 21 特性。DEIMv2 采用了官方的 DINOv3 预训练骨干网络(ViT-Small 和 ViT-Small+),用于其最大的变体(L 和 X 尺寸),以最大化特征丰富度,而其 S 和 M 变体则利用从 DINOv3 蒸馏而来的 ViT-Tiny 和 ViT-Tiny+ 骨干网络,在性能和效率之间进行了精心平衡。为了应对超轻量级场景,我们进一步引入了四个专门的变体:Nano、Pico、Femto 和 Atto,从而扩展了 DEIMv2 在广泛计算预算中的可扩展性。
为了更好地利用在大规模数据上预训练的 DINOv3 的强大特征表示,并在实时约束下进行操作,我们设计了空间调谐适配器(STA)。STA 与 DINOv3 并行运行,以无参数的方式高效地将其单尺度输出转换为对象检测所需的多尺度特征。同时,它对输入图像进行快速下采样,以提供具有非常小感受野的精细、多尺度细节特征,补充 DINOv3 的强语义。
我们进一步通过借鉴 Transformer 社区的进展来简化解码器。具体来说,我们用 SwishFFN 20 和 RMSNorm 27 替换了传统的 FFN 和 LayerNorm,这两种方法都被证明在不影响性能的情况下效率更高。此外,我们注意到在迭代细化过程中,目标查询位置的变化极小,这促使我们在所有解码器层之间共享查询位置嵌入。除此之外,我们通过引入对象级别的 Copy-Blend 增强来增强 Dense O2O,这增加了有效的监督并进一步提高了模型性能。
在 COCO 12 上的大量实验表明,DEIMv2 在多个模型尺寸上均实现了最新水平的性能,如图 1 所示。尽管其结构简单,但 DEIMv2 系列展现出了强大的性能。例如,我们最大的变体 DEIMv2-X 在 COCO 上以仅 50.3M 参数实现了 57.6AP,超越了之前需要超过 60M 参数但仅达到 56.5AP 的最佳 X 尺度检测器 DEIM-X。在较小的一端,DEIMv2-S 作为一个重要的里程碑,成为首个参数少于 10M 的模型,其在 COCO 上的 AP 超过了 50,突出了我们在紧凑尺寸上的设计有效性。此外,我们的超轻量级 DEIMv2-Pico 仅用 1.5M 参数就达到了 38.5AP,与 YOLOv10-Nano(2.3M 参数)的性能相当,同时将参数数量减少了约 50%,从而在极轻量级领域重新定义了效率 - 准确性边界。
我们的工作突出了如何有效地将 DINOv3 21 特性适应于实时目标检测,并提供了一个涵盖超轻量级到高性能模型的多功能框架。据我们所知,这是实时目标检测领域中首次同时涵盖如此广泛部署场景的工作。
本工作的主要贡献总结如下:
-
我们提出了 DEIMv2,它提供了八种模型尺寸,涵盖 GPU、边缘和移动部署。
-
对于较大的模型,我们利用 DINOv3 提供强大的语义特征,并引入了 STA 以高效地将其整合到实时目标检测中。
-
对于超轻量级模型,我们利用专业知识有效剪枝 HGNetv2-B0 的深度和宽度,以满足严格的计算限制。
-
除了骨干网络之外,我们还进一步简化了解码器并升级了 Dense O2O,进一步推动了性能边界。
-
最后,我们在 COCO 上证明了 DEIMv2 在所有资源设置中均优于现有的最新方法,确立了新的 SOTA 结果。
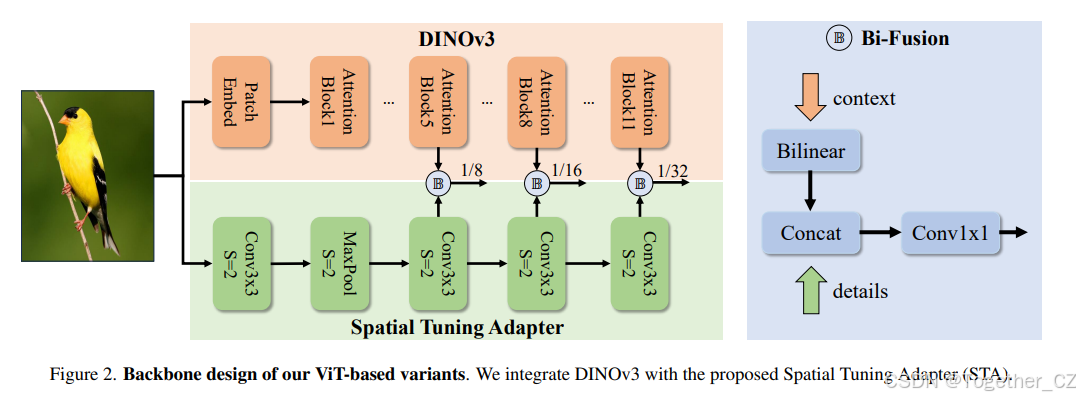
2. 方法
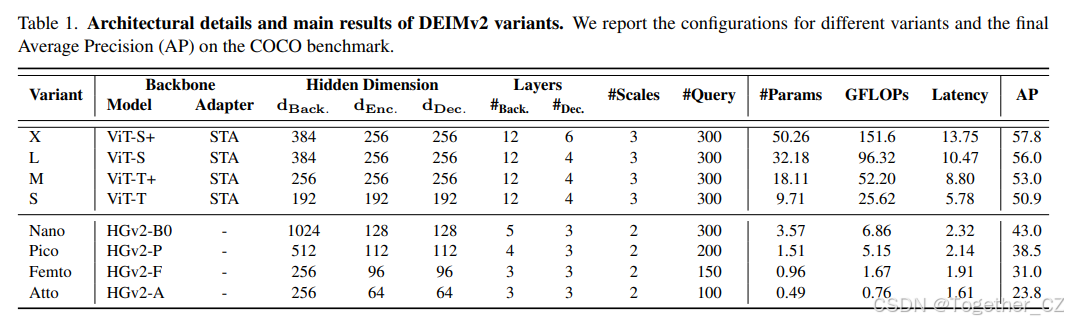
总体架构。我们的总体架构遵循 RT-DETR 14 的设计,包括一个骨干网络、一个混合编码器和一个解码器。如表 1 所示,对于主流变体 X、L、M 和 S,骨干网络基于带有我们提出的空间调谐适配器(STA)的 DINOv3,而其余变体则使用 HGNetv2 1。来自骨干网络的多尺度特征首先由编码器处理,以产生初始检测结果并选择顶部 K 个候选边界框。解码器迭代地细化这些候选对象,以生成最终预测。
基于 ViT 的变体。对于较大的 DEIMv2 变体(S、M、L、X),我们围绕 Vision Transformer 3(ViT)家族精心设计了骨干网络,在模型容量与效率之间取得了平衡。对于 L 和 X,我们利用了两个公开的 DINOv3 模型 21:ViT-Small 和 ViT-Small+,它们提供了具有 12 层和 384 维隐藏大小的强语义表示。对于较轻的 S 和 M 变体,我们直接从 ViT-Small DINOv3 蒸馏出紧凑的骨干网络,即 ViT-Tiny 和 ViT-Tiny+,保留了 12 层深度,同时将隐藏维度分别降低到 192 和 256。这种设计在 S → M → L → X 之间提供了一条平滑的扩展路径,确保每个变体在适应不同的效率要求的同时保持了竞争力的准确性。
基于 HGNetv2 的变体。HGNetv2 1 是由百度 PaddlePaddle 团队开发的,在实时 DETR 框架中因其效率而被广泛使用------例如,D-FINE 17 采用了完整的 HGNetv2 系列作为其骨干网络。在我们的超轻量级 DEIMv2 模型(Nano、Pico、Femto 和 Atto)中,我们同样基于 HGNetv2-B0 构建,但逐步剪枝其深度和宽度以满足不同的参数预算。具体来说,Pico 骨干网络移除了 B0 的第四阶段,仅保留到 1/16 尺度的输出。Femto 进一步将 Pico 最后阶段的块数量从两个减少到一个。Atto 更进一步,将该最后块的通道数量从 512 缩小到 256。
空间调谐适配器。为了更好地将 DINOv3 特性适应于实时目标检测,我们提出了空间调谐适配器(STA),如图 2 所示。STA 是一个全卷积网络,它整合了一个超轻量级前馈网络,用于提取精细的多尺度细节,以及一个 Bi-Fusion 操作符,进一步加强来自 DINOv3 的特征表示。
DINOv3 基于一个 ViT 骨干网络,其自然地产生单尺度(1/16)密集特征。然而,在目标检测中,对象的大小变化很大,多尺度特征是提高性能的最有效方法之一。为此,ViTDet 10 引入了 Feature2Pyramid 模块,该模块使用反卷积从最终的 ViT 输出生成多尺度特征。相比之下,我们的 STA 更为简单:我们直接通过无参数的双线性插值,将来自几个 ViT 块(例如,第 5、8 和 11 个)的 1/16 尺度特征调整为多个尺度。这些多尺度特征进一步通过 Bi-Fusion 操作符增强,该操作符由 1×1 卷积组成,设计了一个超轻量级 CNN 以提取精细细节并补充 DINOv3 的输出特征。这种设计在效率和准确性之间取得了极佳的权衡,使其非常适合实时检测。
高效解码器。我们通过整合 Transformer 社区广泛采用的几种效率导向技术,增强了标准的可变形注意力解码器 31,实现了有利的性能 - 成本权衡。具体来说,我们整合了 SwiGLUFFN 20 以增强非线性表示能力,RMSNorm 27 以高效地稳定和加速训练。注意到在迭代细化过程中目标查询位置的变化极小,我们进一步提出在所有解码器层之间共享单个位置嵌入,消除了冗余计算。
增强型 Dense O2O。在我们之前的 DEIM 7 中,我们提出了 Dense O2O,它增加了每张训练图像上的对象数量,以提供更强的监督,从而改善收敛性和性能。其有效性最初是通过像 Mosaic 和 MixUp 28 这样的图像级增强来证明的。在 DEIMv2 中,我们进一步在对象级别探索 Dense O2O,采用 Copy-Blend,它在没有背景的情况下添加新对象。与完全覆盖目标区域的 Copy-Paste 4 不同,Copy-Blend 将新对象与图像融合,更适合我们的场景,并且始终能够提高性能。
训练设置和损失。我们的训练策略遵循 DEIM 7,这是一个为快速收敛和高性能而设计的基本框架。总体优化目标是五个组成部分的加权和:匹配感知损失(MAL)7、细粒度定位(FGL)损失 17、解耦蒸馏焦点(DDF)损失 17、BBox 损失(L1)和 GIoU 损失 19。总损失定义为:
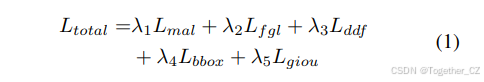
权重设置为 λ1=,λ2=,λ3=1.5,λ4=5,以及 λ5=2,在所有实验中保持不变。
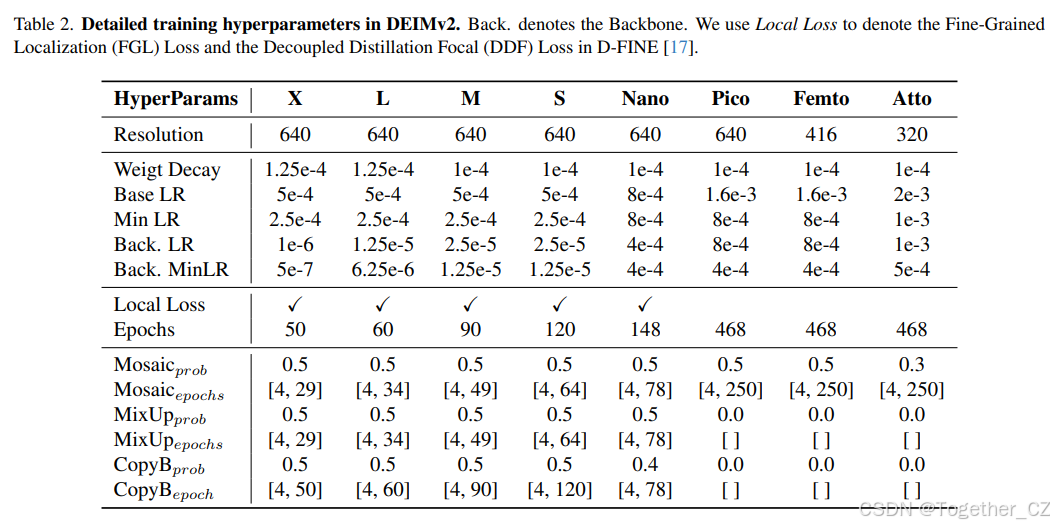
我们在表 2 中总结了训练超参数,涵盖输入分辨率、学习率、训练周期以及 Dense O2O 设置。一个有趣的观察结果是,将 FGL 和 DDF 损失应用于超轻量级模型会降低性能。我们将其归因于它们有限的容量以及固有基准准确性的降低,这降低了自蒸馏的有效性。因此,我们在训练 Pico、Femto 和 Atto 变体时排除了这两个组件(即,局部损失)。
3. 实验
与最新实时目标检测器的比较。表 3 总结了 DEIMv2 在 S、M、L 和 X 变体上的性能,显示出与之前最新检测器相比的显著改进。例如,最大的变体 DEIMv2-X 达到了 57.8AP,仅约有 50M 参数和 151GFLOPs,超过了之前的最佳 DEIM-X(56.5AP,62M 参数和 202GFLOPs)。这表明 DEIMv2 能够以更少的参数和更低的计算成本提供更高的准确性。在较小的一端,DEIMv2-S 成为首个参数少于 10M 的模型,在 COCO 上的 AP 阈值超过了 50,仅用 11M 参数和 26GFLOPs 达到了 50.9AP。这标志着与之前的 DEIM-S(49.0AP,10M 参数)相比有了明显的改进,同时几乎保持了相同的模型大小。尽管基于 CNN 的骨干网络通常更受硬件青睐,但我们的 ViT 基骨干网络以更少的参数和更低的 FLOPs 实现了轻量化设计,提供了更好的可扩展性和部署灵活性。值得一提的是,所提出方法的延迟尚未经过优化。例如,像 Yolov12 22 中的 Flash Attention 2 这样的技术,可以进一步加速推理。总体而言,减少的 FLOPs 突显了 ViT 基骨干网络在经过适当优化后实现低延迟性能的潜力。
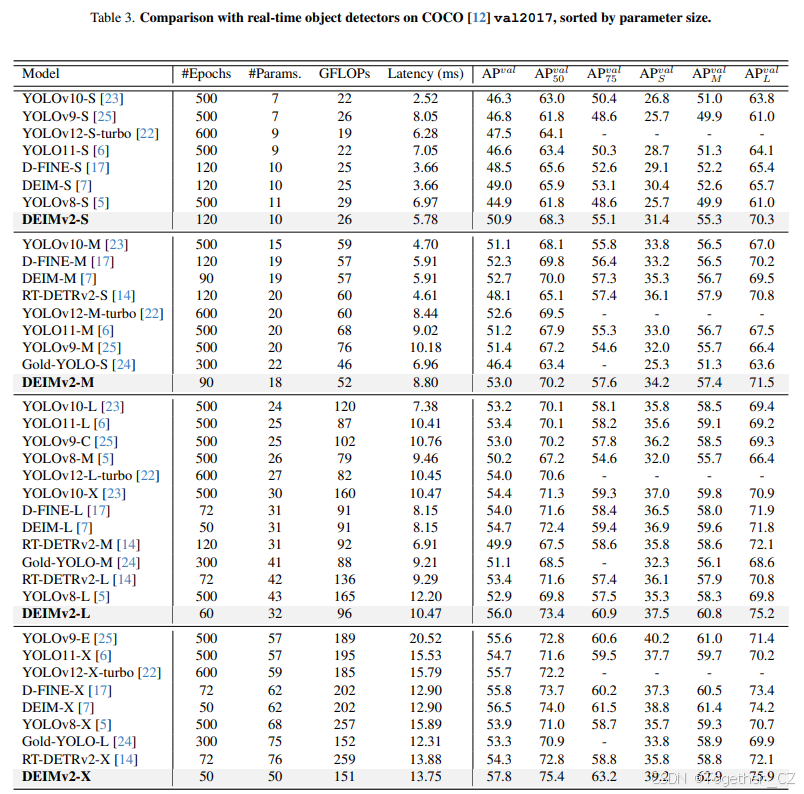
有趣的是,当比较在参数和 FLOP 预算相当的情况下基于 DINOv3 的 DEIMv2 模型与其之前的 DEIM 对应物时,准确性提升主要来自于对中型和大型对象的改进,而对小型对象的性能基本保持不变。例如,DEIMv2-S 达到了 55.3APM 和 70.3APL,明显超过了 DEIM-S(52.6APM 和 65.7APL),然而小型对象的得分几乎相同(31.4 对比 30.4APS)。在较大的模型中也观察到了类似的趋势:DEIMv2-X 将 APM 从 61.4 提高到 62.8,APL 从 74.2 提高到 75.9,而其小型对象的 AP(39.2)仍然接近 DEIM-M(38.8)。这些结果表明,DEIMv2 的主要优势在于增强中型到大型对象的表示和检测,而小型对象的检测仍然是跨尺度的挑战。这一观察结果进一步证实了 DINOv3 在捕捉强全局语义方面表现出色,但在表示精细细节方面能力有限。因此,探索如何更好地将 DINOv3 特征整合到实时检测器中代表了未来的一个有趣方向。
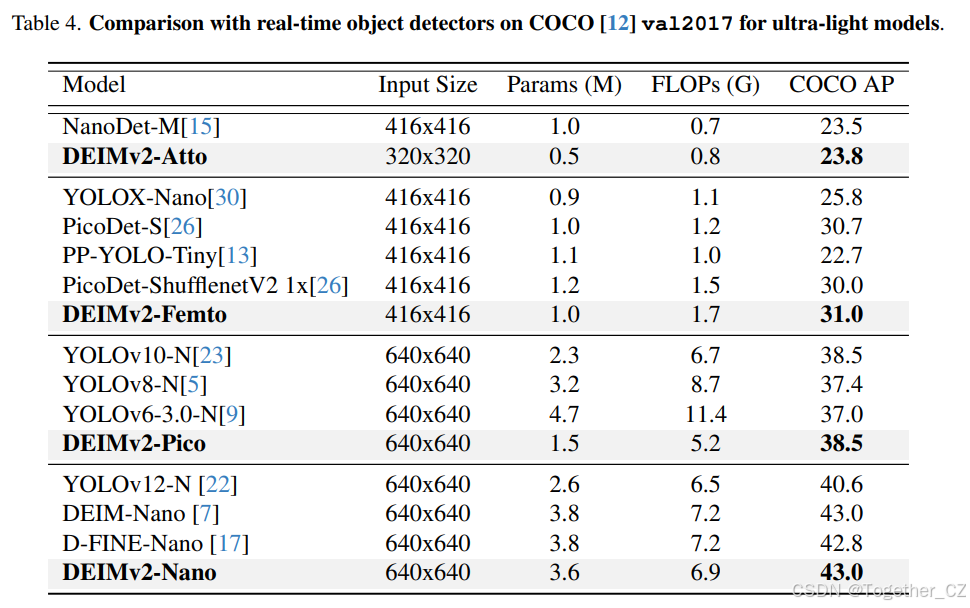
与超轻量级目标检测器的比较。DEIMv2 的超轻量变体也展现出了强大的性能,如表 4 所总结。DEIMv2-Atto 仅拥有 0.49M 参数,尽管其尺寸大幅缩小,但其性能与 NanoDet-M 相当。同样,DEIMv2-Pico 达到了与 YOLOv10-N 23 相当的性能,但参数却不到其一半。这些结果突出了 DEIMv2 在极其紧凑的领域中的有效性,并强调了其在资源受限的边缘设备上部署的适用性。
4. 结论
在本报告中,我们介绍了 DEIMv2,这是新一代的实时目标检测器,它将 DINOv3 的强大语义表示与我们轻量级的 STA 结合在一起。通过精心设计和扩展,DEIMv2 在整个模型尺寸范围内实现了最新水平的性能。在高端,DEIMv2-X 以显著更少的参数提供了 57.8AP。在紧凑端,DEIMv2-S 是首个达到 50AP 的该尺寸模型,而超轻量级的 DEIMv2-Pico 在使用超过 50% 更少参数的情况下与 YOLOv10-N 匹配。这些结果共同表明,DEIMv2 不仅高效,而且高度可扩展,提供了一个统一的框架,推动了准确性 - 效率边界。这种多功能性使得 DEIMv2 非常适合在各种场景中部署,从资源受限的边缘设备到高性能检测系统,为实时检测在实际应用中的更广泛采用铺平了道路。