
为一个跨越多个国家和使用多种语言的四人家庭管理纸质和数字文档变得越来越难以管理。德语的税务文件、英语的医疗记录、散落在三个邮箱账户中的合同,以及不断堆积的我总是在需要时找不到的纸质文件。
我花了数周时间构建了一个全自动文档管理系统,现在管理着900多份文档,每天零 effort。这篇文章将带你了解整个设置过程------从我桌上的扫描仪到GitHub上的加密备份------包括你需要自己构建的所有配置文件和脚本。
1、问题
我们的家庭产生了大量文书工作。保险信件、税务评估、医疗账单、雇佣合同、幼儿园注册、车辆文件------所有这些都使用不同语言、通过不同渠道到达、属于不同家庭成员。
在这个设置之前,我的"系统"是:
- 一个总是满的但从未整理过的物理文件夹
- 散落在三个账户中的邮件附件
- 手机里满是"我稍后归档"的文档照片
- 无法搜索任何东西------我必须记住我放在哪里
我需要一个能够:
- 自动从邮件、扫描仪和手动上传摄取文档
- 使用AI按类型、人员和主题对文档进行分类
- 追踪我拥有哪些物理文档以及它们在哪里
- 可搜索且可从任何地方访问
- 自动备份到多个位置而无需我干预
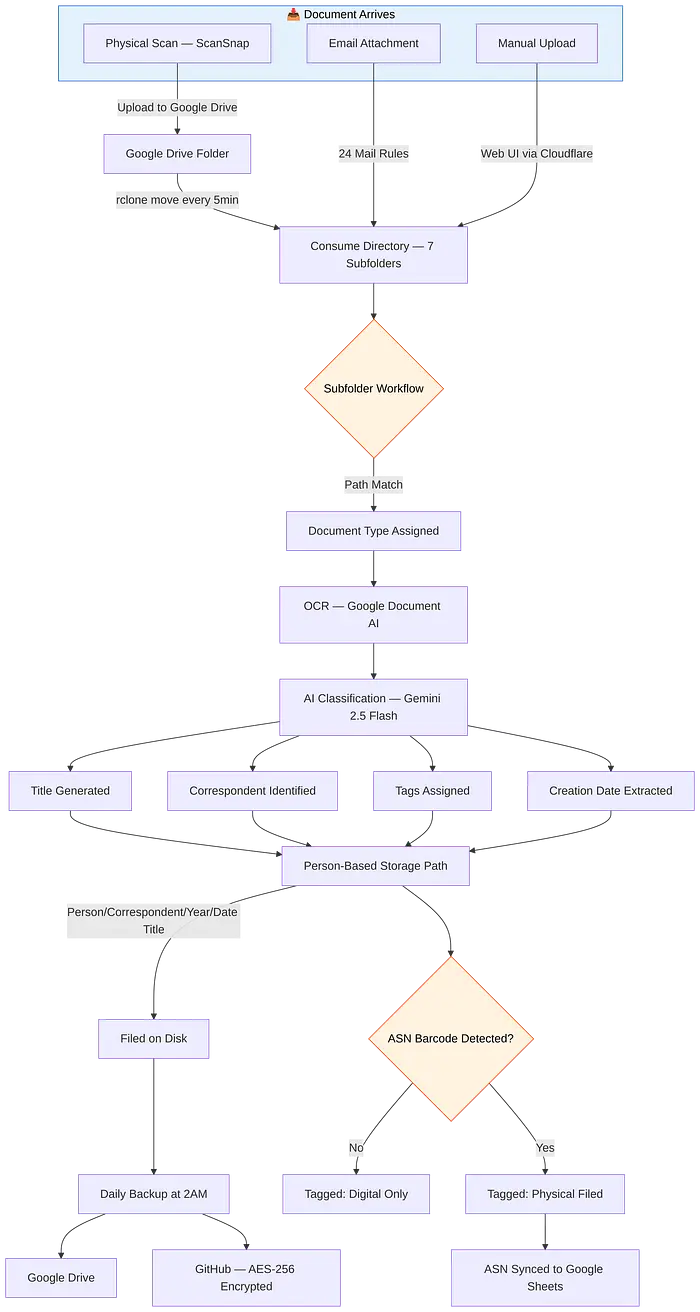
2、我的工作流:从纸张到可搜索档案
这是现在自动运行每日工作流:
物理文档
- 信件到达邮件
- 我使用Avery Zweckform L4731REV-25标签及其在线设计器打印一个ASN条形码标签,然后贴在文档上
- 我把文档放在我的Ricoh ScanSnap iX1600扫描仪上
- 扫描仪自动上传PDF到Google Drive文件夹,按类别(财务、健康、工作等)分类到子文件夹中
- 每5分钟,rclone从Google Drive移动新文件到服务器
- Paperless-NGX检测到新文件并开始处理
- 一个工作流根据来自哪个子文件夹分配文档类型
- Google Document AI执行高质量OCR,然后Gemini 2.5 Flash生成干净的标题,识别对应方,分配标签,并提取创建日期
- 文档按人员、对应方和年份归档到磁盘上
- ASN条形码被自动检测------一个cron任务标记为"已物理归档"并将ASN映射同步到Google表格
- 物理文档放入编号活页夹中,与ASN匹配
数字文档
- 发票通过邮件到达
- 24个邮件规则之一检测到它并消费附件
- 文档自动标记为"仅数字"并通过相同的AI分类管道
整个过程大约需要我30秒的时间(贴标签并把纸放到扫描仪上)。其他一切都是自动化的。
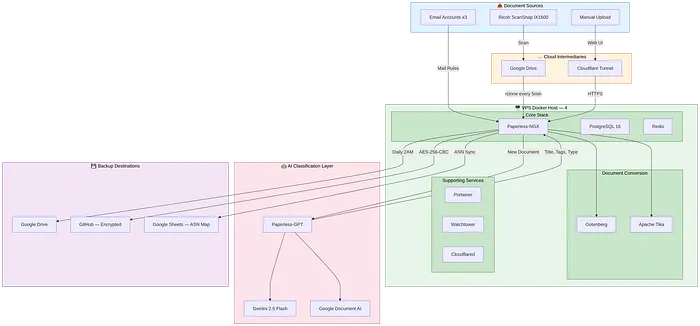
3、架构概述
该系统运行在单个VPS(4 vCPU,8GB RAM,80GB NVMe)上,包含9个Docker容器:
容器
角色
内存限制
Paperless-NGX
核心文档管理
2 GB
Paperless-GPT
AI分类(Gemini 2.5 Flash + Document AI)
256 MB
PostgreSQL 16
数据库
512 MB
Redis
缓存和任务队列
256 MB
Gotenberg
文档转换
512 MB
Apache Tika
从Office格式提取文本
512 MB
Cloudflare Tunnel
安全HTTPS访问(零开放端口)
128 MB
Portainer
容器管理UI
256 MB
Watchtower
自动容器更新
256 MB
总内存占用:低于5 GB,在8 GB VPS上有充足余量。
4、文档处理流程
5、构建指南
5.1 服务器设置
从一个全新的Ubuntu VPS开始。这个脚本安装Docker、配置防火墙、设置fail2ban、安装rclone用于Google Drive同步,并创建目录结构:
#!/bin/bash
set -e
# 更新系统
sudo apt update && sudo apt upgrade -y
# 安装Docker
curl -fsSL https://get.docker.com | sudo sh
sudo usermod -aG docker $USER
# 防火墙 - 仅SSH(所有Web流量通过Cloudflare Tunnel)
sudo ufw allow OpenSSH
sudo ufw --force enable
# 暴力攻击保护
sudo apt install -y fail2ban
sudo systemctl enable fail2ban && sudo systemctl start fail2ban
# 目录结构
mkdir -p ~/paperless/{data,media,export,consume,redis,db,prompts,backups,scripts}
mkdir -p ~/paperless/consume/{Arbeit,Dokumente,Fahrzeuge,Finanzen,Gesundheit,Wohnen,Sonstiges}
# 安装rclone用于Google Drive同步
curl https://rclone.org/install.sh | sudo bash
# 备份cron(每天凌晨2点)
(crontab -l 2>/dev/null; echo '0 2 * * * ~/paperless/backup.sh >> ~/paperless/backup.log 2>&1') | crontab -5.2 Docker Compose配置
这是完整的docker-compose.yml。用你自己的凭证替换占位符值(YOUR_*):
services:
broker:
image: redis:7-alpine
container_name: paperless-redis
read_only: true
healthcheck:
test: ["CMD-SHELL", "redis-cli ping || exit 1"]
interval: 30s
timeout: 10s
retries: 3
security_opt:
- no-new-privileges:true
environment:
REDIS_ARGS: "--save 60 10"
restart: unless-stopped
volumes:
- ~/paperless/redis:/data
networks:
- paperless-net
deploy:
resources:
limits:
memory: 256M
gotenberg:
image: gotenberg/gotenberg:8.7
container_name: paperless-gotenberg
restart: unless-stopped
security_opt:
- no-new-privileges:true
command:
- "gotenberg"
- "--chromium-disable-javascript=true"
- "--chromium-allow-list=.*"
networks:
- paperless-net
deploy:
resources:
limits:
memory: 512M
db:
image: postgres:16-alpine
container_name: paperless-db
restart: unless-stopped
healthcheck:
test: ["CMD", "pg_isready", "-q", "-d", "paperless", "-U", "paperless"]
timeout: 45s
interval: 10s
retries: 10
security_opt:
- no-new-privileges:true
volumes:
- ~/paperless/db:/var/lib/postgresql/data
environment:
POSTGRES_DB: paperless
POSTGRES_USER: paperless
POSTGRES_PASSWORD: YOUR_DB_PASSWORD
networks:
- paperless-net
deploy:
resources:
limits:
memory: 512M
paperless:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
container_name: paperless-ngx
healthcheck:
test: ["CMD", "curl", "-fs", "-S", "--max-time", "2", "http://localhost:8000"]
interval: 30s
timeout: 10s
retries: 5
security_opt:
- no-new-privileges:true
restart: unless-stopped
depends_on:
db:
condition: service_healthy
broker:
condition: service_healthy
gotenberg:
condition: service_started
ports:
- "127.0.0.1:8001:8000"
volumes:
- ~/paperless/data:/usr/src/paperless/data
- ~/paperless/media:/usr/src/paperless/media
- ~/paperless/export:/usr/src/paperless/export
- ~/paperless/consume:/usr/src/paperless/consume
- ~/paperless/scripts:/usr/src/paperless/scripts
environment:
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
PAPERLESS_TIKA_ENABLED: 1
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: http://gotenberg:3000
PAPERLESS_TIKA_ENDPOINT: http://tika:9998
PAPERLESS_TIME_ZONE: Europe/Berlin
PAPERLESS_SECRET_KEY: YOUR_RANDOM_SECRET_KEY
PAPERLESS_ADMIN_USER: admin
PAPERLESS_ADMIN_PASSWORD: YOUR_ADMIN_PASSWORD
PAPERLESS_URL: "https://your-domain.com"
# OCR设置
PAPERLESS_OCR_LANGUAGE: "deu+eng"
PAPERLESS_OCR_LANGUAGES: "tur aze"
PAPERLESS_OCR_MODE: "skip"
PAPERLESS_OCR_DPI: 300
PAPERLESS_OCR_SKIP_ARCHIVE_FILE: with_text
PAPERLESS_OCR_CLEAN: clean
PAPERLESS_OCR_CACHING: true
PAPERLESS_OCR_USER_ARGS: '{"invalidate_digital_signatures": true}'
# Consumer设置
PAPERLESS_CONSUMER_POLLING: 10
PAPERLESS_CONSUMER_RECURSIVE: "true"
PAPERLESS_CONSUMER_SUBDIRS_AS_TAGS: "false"
PAPERLESS_CONSUMER_RETRY_COUNT: 3
PAPERLESS_CONSUMER_DELETE_DUPLICATES: true
# 文件命名
PAPERLESS_FILENAME_FORMAT: "{{{ correspondent|slugify }}}/{{{ created_year }}}/{{{ created }} {{{ title|slugify }}}"
PAPERLESS_FILENAME_FORMAT_REMOVE_NONE: "true"
PAPERLESS_FILENAME_DATE_ORDER: "YMD"
# Workers
PAPERLESS_TASK_WORKERS: 2
PAPERLESS_THREADS_PER_WORKER: 2
# ASN条形码检测
PAPERLESS_CONSUMER_ENABLE_BARCODES: "true"
PAPERLESS_CONSUMER_ENABLE_ASN_BARCODE: "true"
PAPERLESS_CONSUMER_ASN_BARCODE_PREFIX: "ASN"
PAPERLESS_CONSUMER_BARCODE_SCANNER: "ZXING"
# 邮件(用于通知)
PAPERLESS_EMAIL_HOST: "YOUR_SMTP_HOST"
PAPERLESS_EMAIL_PORT: 465
PAPERLESS_EMAIL_HOST_USER: "YOUR_EMAIL"
PAPERLESS_EMAIL_HOST_PASSWORD: "YOUR_EMAIL_APP_PASSWORD"
PAPERLESS_EMAIL_USE_SSL: "true"
PAPERLESS_EMAIL_FROM: "YOUR_EMAIL"
PAPERLESS_EMAIL_TASK_CRON: "*/5 * * * *"
# 代理设置(用于Cloudflare Tunnel)
PAPERLESS_USE_X_FORWARD_HOST: "true"
PAPERLESS_USE_X_FORWARD_PORT: "true"
PAPERLESS_PROXY_SSL_HEADER: '["HTTP_X_FORWARDED_PROTO", "https"]'
PAPERLESS_ALLOWED_HOSTS: "localhost,paperless,your-domain.com"
PAPERLESS_CORS_ALLOWED_HOSTS: "https://your-domain.com"
PAPERLESS_CSRF_TRUSTED_ORIGINS: "https://your-domain.com"
PAPERLESS_DEBUG: false
networks:
- paperless-net
deploy:
resources:
limits:
memory: 2G
tika:
image: apache/tika:latest
container_name: paperless-tika
restart: unless-stopped
security_opt:
- no-new-privileges:true
networks:
- paperless-net
deploy:
resources:
limits:
memory: 512M
paperless-gpt:
image: icereed/paperless-gpt:latest
container_name: paperless-gpt
environment:
PAPERLESS_BASE_URL: "http://paperless:8000"
PAPERLESS_API_TOKEN: "YOUR_PAPERLESS_API_TOKEN"
PAPERLESS_PUBLIC_URL: "https://your-domain.com"
MANUAL_TAG: "paperless-gpt"
AUTO_TAG: "paperless-gpt-auto"
LLM_PROVIDER: "googleai"
GOOGLEAI_API_KEY: "YOUR_GOOGLE_AI_API_KEY"
LLM_MODEL: "gemini-2.5-flash"
TOKEN_LIMIT: 0
OCR_PROCESS_MODE: "whole_pdf"
OCR_PROVIDER: "google_docai"
GOOGLE_PROJECT_ID: "YOUR_GCP_PROJECT"
GOOGLE_LOCATION: "eu"
GOOGLE_PROCESSOR_ID: "YOUR_PROCESSOR_ID"
GOOGLE_APPLICATION_CREDENTIALS: "/app/credentials.json"
AUTO_OCR_TAG: "paperless-gpt-ocr-auto"
OCR_LIMIT_PAGES: "5"
LOG_LEVEL: "info"
volumes:
- ~/paperless/prompts:/app/prompts
- ~/paperless/google-ai.json:/app/credentials.json
ports:
- "127.0.0.1:8080:8080"
depends_on:
- paperless
networks:
- paperless-net
deploy:
resources:
limits:
memory: 256M
cloudflared:
image: cloudflare/cloudflared:latest
container_name: paperless-cloudflared
command: tunnel --no-autoupdate run --token YOUR_TUNNEL_TOKEN
restart: unless-stopped
security_opt:
- no-new-privileges:true
networks:
- paperless-net
deploy:
resources:
limits:
memory: 128M
networks:
paperless-net:
driver: bridge5.3 使用Paperless-GPT的AI分类
Paperless-GPT是系统的核心。它使用Google Gemini 2.5 Flash进行分类,使用Google Document AI进行OCR。每个新文档都会获得:
- 从内容中提取的干净的描述性标题
- 识别对应方(去除GmbH或AG等法律后缀)
- 从你的预定义类别中选择文档类型
- 从你的策划列表中选择标签
- 从文档中解析的创建日期,而不是扫描日期
- 自定义字段提取(到期日期、金额等)
关于隐私的说明:由于Google Document AI和Gemini在云中处理文档内容,我只将通过自动化管道发送非敏感文档。敏感文档------如护照复印件、带个人ID的纳税申报表、或带有详细诊断的医疗记录------在Paperless UI中手动分类和命名。这些文档的OCR仍然通过Tesseract(Paperless-NGX的内置OCR引擎)在本地运行,因此内容永远不会离开服务器。这是一个有意识的权衡:AI管道为90%不敏感的文档节省了数小时的工作,而10%敏感的文档则更加谨慎处理。
提示词存储在/prompts/中,是完全可定制的Go模板。以下是 correspondent提示词作为示例------它告诉AI避免法律后缀,并提供现有correspondent列表作为上下文:
I will provide you with the content of a document.
Your task is to suggest a correspondent that is most relevant to the document.
Try to avoid any legal or financial suffixes like "GmbH" or "AG" in the
correspondent name. For example use "Microsoft" instead of
"Microsoft Ireland Operations Limited".
If you can't find a suitable correspondent, respond with "Unknown".
Example Correspondents:
{{.AvailableCorrespondents | join ", "}}
The content is likely in {{.Language}}.
Document Content:
{{.Content}}5.4 Consume子文件夹和工作流
ScanSnap根据文档类别保存文件到Google Drive子文件夹。Paperless有7个consume子文件夹,每个通过工作流映射到文档类型:
子文件夹
文档类型
工作流过滤器
Arbeit/
Arbeit und Beruf
/Arbeit/
Dokumente/
Wichtige Dokumente
/Dokumente/
Fahrzeuge/
Fahrzeuge
/Fahrzeuge/
Finanzen/
Finanzen und Steuern
/Finanzen/
Gesundheit/
Gesundheit und Versicherungen
/Gesundheit/
Wohnen/
Wohnen
/Wohnen/
每个工作流在Consumption Started(类型1)时触发,使用filter_path匹配子文件夹。这确保文档类型在AI运行之前设置------因此即使AI不同意(例如,健康文档放在财务文件夹中),基于子文件夹的类型仍然保留。例外是Sonstiges(杂项)------扫描到这个文件夹的文档没有工作流,所以Paperless-GPT根据内容自由分类。
额外的工作流根据人员标签自动分配存储路径,在磁盘上组织文件为Person/Correspondent/Year/Date Title。
5.5 Google Drive同步
ScanSnap上传到Google Drive。一个cron任务每5分钟将新文件同步到服务器:
# /etc/cron.d/paperless-gdrive-consume
*/5 * * * * ubuntu rclone move "Gdrive:Paperless/Consume/" /home/ubuntu/paperless/consume/ \
--log-file=/tmp/paperless-gdrive-consume.log --log-level=INFO 2>/dev/nullrclone move命令移动(不是复制)文件,所以Google Drive充当临时投放区。用rclone config配置rclone并设置Google Drive OAuth。
5.6 物理文档追踪(ASN条形码)
每个物理文档都获得一个档案序列号(ASN)条形码标签。我使用Avery Zweckform L4731REV-25可移除标签(每张189个)和他们的在线设计器来打印ASN条形码。Paperless在扫描文档时使用ZXING自动读取条形码。
一个cron脚本每分钟运行以:
-
查找所有有ASN但尚未标记为"已物理归档"的文档
-
添加"已物理归档"标签并移除"仅数字"标签
-
将所有ASN到文档的映射同步到Google表格作为安全备份
#!/bin/bash
/home/ubuntu/paperless/scripts/asn-physical-filed.sh
TOKEN="YOUR_PAPERLESS_API_TOKEN"
API="http://localhost:8001/api"查找有ASN但没有"已物理归档"标签的文档
DOCS=(curl -s "{API}/documents/?archive_serial_number__isnull=false&tags__id__none=PHYSICAL_FILED_TAG_ID&page_size=100"
-H "Authorization: Token {TOKEN}") IDS=(echo "DOCS" | python3 -c " import json,sys data = json.load(sys.stdin) for d in data.get('results', []): print(d['id']) " 2>/dev/null) for doc_id in IDS; do
TAGS=(curl -s "{API}/documents/{doc_id}/" -H "Authorization: Token {TOKEN}" | python3 -c "
import json,sys
d = json.load(sys.stdin)
tags = d['tags']
if PHYSICAL_FILED_ID not in tags:
tags.append(PHYSICAL_FILED_ID)
if DIGITAL_ONLY_ID in tags:
tags.remove(DIGITAL_ONLY_ID)
print(json.dumps(tags))
" 2>/dev/null)
curl -s -X PATCH "{API}/documents/{doc_id}/"
-H "Authorization: Token {TOKEN}" \ -H "Content-Type: application/json" \ -d "{\"tags\": {TAGS}}" > /dev/null 2>&1
done
Google表格同步脚本使用gspread和Google服务账户将所有ASN映射写入电子表格。这意味着即使我丢失了整个Paperless服务器,我仍然有哪个ASN对应哪个文档的记录。
5.7 备份策略(3-2-1规则)
备份每天凌晨2:00自动运行,有三个目的地和轮换:
| 目的地 | 方法 | 保留期 | |--------|------|--------| | Google Drive | rclone上传 | 7天/4周/3月 | | GitHub(私有仓库) | AES-256-CBC加密 | 7天/4周/3月 | | 本地 | 磁盘拷贝 | 相同轮换 |
备份脚本从Paperless导出所有文档,上传到Google Drive,加密并推送到GitHub,轮换旧备份,并验证完整性。Healthchecks.io在出现任何问题时通知我。
#!/bin/bash
# backup.sh - 每日Paperless备份,带轮换和监控
set -e
DATE=$(date +%Y-%m-%d)
DAY_OF_WEEK=$(date +%u)
DAY_OF_MONTH=$(date +%d)
PAPERLESS_DIR="/home/ubuntu/paperless"
BACKUP_DIR="$PAPERLESS_DIR/backups"
CONFIG_REPO="/home/ubuntu/paperless-config"
GDRIVE_DIR="Backups/Paperless"
# 加载.env(包含HEALTHCHECK_URL和ENCRYPTION_PASSPHRASE)
source "$PAPERLESS_DIR/.env"
# Healthchecks.io集成
healthcheck_start() { curl -fsS -m 10 --retry 5 "${HEALTHCHECK_URL}/start" >/dev/null 2>&1 || true; }
healthcheck_success() { curl -fsS -m 10 --retry 5 "$HEALTHCHECK_URL" >/dev/null 2>&1 || true; }
healthcheck_fail() { curl -fsS -m 10 --retry 5 "${HEALTHCHECK_URL}/fail" >/dev/null 2>&1 || true; }
healthcheck_start
# 从Paperless导出(-sm = 分割清单以便更快导入)
cd "$PAPERLESS_DIR"
docker compose exec -T paperless document_exporter ../export --zip -sm
EXPORT_FILE=$(ls -t "$PAPERLESS_DIR/export/export-"*.zip 2>/dev/null | head -1)
[ -z "$EXPORT_FILE" ] && { healthcheck_fail; exit 1; }
# 确定备份类型
if [ "$DAY_OF_MONTH" == "01" ]; then
BACKUP_TYPE="monthly"
elif [ "$DAY_OF_WEEK" == "7" ]; then
BACKUP_TYPE="weekly"
else
BACKUP_TYPE="daily"
fi
BACKUP_NAME="paperless-${BACKUP_TYPE}-${DATE}.zip"
# 本地复制并上传到Google Drive
cp "$EXPORT_FILE" "$BACKUP_DIR/$BACKUP_NAME"
rclone copy "$BACKUP_DIR/$BACKUP_NAME" "Gdrive:$GDRIVE_DIR/$BACKUP_TYPE/"
# 轮换本地和远程备份
find "$BACKUP_DIR" -name "paperless-daily-*.zip" -mtime +7 -delete
find "$BACKUP_DIR" -name "paperless-weekly-*.zip" -mtime +28 -delete
find "$BACKUP_DIR" -name "paperless-monthly-*.zip" -mtime +90 -delete
rclone delete "Gdrive:$GDRIVE_DIR/daily/" --min-age 7d 2>/dev/null || true
rclone delete "Gdrive:$GDRIVE_DIR/weekly/" --min-age 28d 2>/dev/null || true
rclone delete "Gdrive:$GDRIVE_DIR/monthly/" --min-age 90d 2>/dev/null || true
# 验证完整性
unzip -t "$BACKUP_DIR/$BACKUP_NAME" >/dev/null 2>&1 || { healthcheck_fail; exit 1; }
# 加密备份到GitHub
if [ -n "$ENCRYPTION_PASSPHRASE" ] && [ -d "$CONFIG_REPO" ]; then
mkdir -p "$CONFIG_REPO/encrypted-backups/$BACKUP_TYPE"
openssl enc -aes-256-cbc -salt -pbkdf2 \
-in "$BACKUP_DIR/$BACKUP_NAME" \
-out "$CONFIG_REPO/encrypted-backups/$BACKUP_TYPE/paperless-${BACKUP_TYPE}-${DATE}.zip.enc" \
-pass pass:"$ENCRYPTION_PASSPHRASE"
# 轮换加密备份
find "$CONFIG_REPO/encrypted-backups/daily" -name "*.enc" -mtime +7 -delete 2>/dev/null || true
find "$CONFIG_REPO/encrypted-backups/weekly" -name "*.enc" -mtime +28 -delete 2>/dev/null || true
find "$CONFIG_REPO/encrypted-backups/monthly" -name "*.enc" -mtime +90 -delete 2>/dev/null || true
cd "$CONFIG_REPO" && git add -A
git diff --staged --quiet || git commit -m "Backup $DATE - $BACKUP_TYPE (encrypted)" && git push origin main
fi
healthcheck_success5.8 安全加固
有两种方法可以使Paperless远程访问。我两种都用------选择适合你威胁模型的。
选项A:Tailscale VPN(仅私有访问)
Tailscale是一个零配置WireGuard网格VPN。在你的服务器和设备上安装它,Paperless就只能从你的私有网络上的机器访问------对互联网的其余部分不可见。
# 安装Tailscale
curl -fsSL https://tailscale.com/install.sh | sh
sudo tailscale up --ssh
# 通过Tailscale HTTPS暴露Paperless(只能从你的tailnet访问)
tailscale serve --bg --https=443 http://localhost:8001
# 将SSH锁定到仅Tailscale
sudo ufw allow in on tailscale0 to any port 22
sudo ufw delete allow 22结果:Paperless可以在https://<your-machine>.tail*.ts.net访问,有有效的TLS证书,可以从tailnet上的任何设备访问------笔记本电脑、手机、平板电脑。零开放端口,无证书管理,无动态DNS。
优点:最大安全性。服务器完全没有面向公众的端口。甚至SSH也是仅VPN。 缺点:每个设备都需要安装Tailscale。如果需要公共访问则不适合。
选项B:Cloudflare Tunnel(面向互联网)
如果你需要从任何浏览器访问Paperless而不安装VPN客户端,Cloudflare Tunnel给你一个公共URL,有DDoS保护,无暴露端口。
# 安装cloudflared
curl -fsSL https://pkg.cloudflare.com/cloudflare-main.gpg | sudo tee /usr/share/keyrings/cloudflare-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/cloudflare-archive-keyring.gpg] https://pkg.cloudflare.com/cloudflared $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/cloudflared.list
sudo apt update && sudo apt install cloudflared
# 认证并创建隧道
cloudflared tunnel login
cloudflared tunnel create paperless
cloudflared tunnel route dns paperless docs.yourdomain.com
# 运行隧道(指向Paperless)
cloudflared tunnel --url http://localhost:8000 run paperless优点:可从任何浏览器访问,无需客户端软件,免费DDoS保护。 缺点:你的应用暴露在互联网上。添加Cloudflare Access或其他认证层(Authelia、Authentik)在前面以增加保护。
我的建议:使用Tailscale进行日常访问并将所有内容锁定在VPN后面。如果你需要偶尔的公共访问用于特定用例,在上面添加带有Zero Trust Access策略的Cloudflare Tunnel。
任一选项的基本加固:
- 所有容器都使用
no-new-privileges: true运行 - 每个容器都有内存限制以防止失控进程
- 随机化的66字符
SECRET_KEY - Redis处于只读模式
- 所有端口绑定到
127.0.0.1(仅localhost) - fail2ban用于SSH暴力攻击保护
6、数据
运行几周后:
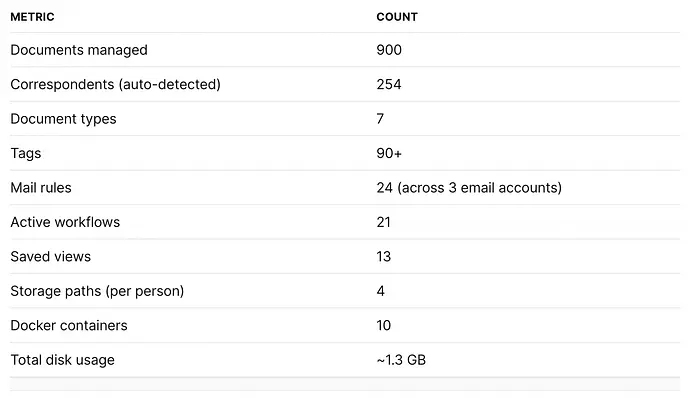
指标
数量
管理的文档
900
识别到的对应方
254
文档类型
7
标签
90+
邮件规则
24(跨3个账户)
活跃工作流
21
保存的视图
13
存储路径(每人)
4
Docker容器
10
总磁盘使用
~1.3 GB
7、我学到的
**基于子文件夹的分类优于基于标签的方法。**我尝试了三种不同的方法:使用consume子目录作为标签,用enforce工作流追踪标签,以及简单的基于路径的工作流。最简单的方法(子文件夹→文档类型工作流)胜出。扫描到一个命名文件夹比仅依赖AI更快更可靠。
**AI需要文档类型的护栏。**Gemini擅长生成标题和识别对应方,但它有时会基于内容而不是意图重新分类文档。一份关于工作伤害的健康保险账单可能会在你归档到"工作"下时被分类为"健康"。在AI之前运行的子文件夹工作流解决了这个问题。
**物理-数字桥梁很重要。**带有Google表格备份的ASN条形码系统意味着我永远不会丢失物理文档存储位置的追踪。即使我的服务器死了,我也可以通过ASN编号查找任何文档。
**备份冗余值得复杂性。**三个备份目的地(Google Drive + 加密GitHub + 本地)带自动轮换意味着我可以在新服务器上在一小时内从头重建整个系统。
**从更少的标签开始。**我最终有90+个标签,这有点太多了。AI标签建议在专注的策划列表上效果更好。如果我重新开始,我会瞄准30-40个精心选择的标签。