视觉识别物体计数的基本原理
视觉识别物体计数的核心是通过算法从图像或视频中识别目标物体,并统计其数量。以下是主要技术原理和实现步骤:
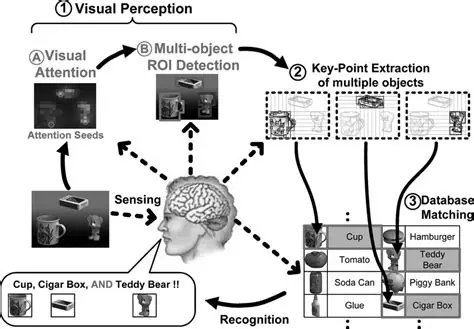
1. 基本原理
视觉计数技术通常分为以下步骤:
-
图像预处理
- 灰度化/色彩空间转换:将彩色图像转换为灰度图或特定色彩空间(如LAB、HSV),以增强目标与背景的对比度。
- 去噪与增强:通过高斯模糊、形态学操作(腐蚀/膨胀)消除噪声,突出目标区域。
-
目标检测
- 传统方法 :基于颜色阈值、边缘检测或轮廓分析(如OpenCV的
findContours)直接分割目标。 - 深度学习方法:使用预训练模型(如YOLO、SSD、Faster R-CNN)进行目标检测,输出边界框或分割掩码。
- 传统方法 :基于颜色阈值、边缘检测或轮廓分析(如OpenCV的
-
后处理与计数
- 非极大值抑制(NMS):消除重叠的检测框,保留最可能的物体位置。
- 连通域分析:通过标记连通区域统计独立物体数量。
- 区域跟踪:在视频中跟踪物体ID,避免重复计数。
2. 技术挑战
- 遮挡与重叠:物体部分遮挡时,传统方法易漏检,需依赖深度学习模型的语义理解。
- 光照变化:颜色阈值法对光照敏感,需结合自适应阈值或深度学习增强鲁棒性。
- 小目标检测:小物体特征不明显,需高分辨率输入或特征金字塔网络(FPN)。


测试代码实现(基于OpenCV)
场景说明
以检测图像中的圆形金属片为例,使用颜色阈值分割和轮廓分析实现计数。
代码实现
python
import cv2
import numpy as np
def count_objects(image_path):
# 读取图像并预处理
img = cv2.imread(image_path)
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# 定义颜色阈值(针对金色物体)
lower_gold = np.array([0, 20, 100]) # HSV下限
upper_gold = np.array([20, 255, 255]) # HSV上限
mask = cv2.inRange(hsv, lower_gold, upper_gold)
# 形态学操作去噪
kernel = np.ones((5,5), np.uint8)
mask = cv2.morphologyEx(mask, cv2.MORPH_OPEN, kernel)
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)
# 查找轮廓
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制轮廓并计数
count = 0
for cnt in contours:
area = cv2.contourArea(cnt)
if area > 1000: # 过滤小噪声
count += 1
(x, y), radius = cv2.minEnclosingCircle(cnt)
cv2.circle(img, (int(x), int(y)), int(radius), (0,255,0), 2)
# 显示结果
cv2.putText(img, f"Count: {count}", (10, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
cv2.imshow("Result", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 测试代码
count_objects("metal_pieces.jpg")代码解析
- 颜色分割:通过HSV色彩空间提取金色区域,适应不同光照条件。
- 形态学处理:开运算消除小噪点,闭运算填充目标内部空洞。
- 轮廓分析:过滤小面积噪声,绘制检测框并计数。


扩展应用:深度学习方法(YOLOv8)
代码实现
python
from ultralytics import YOLO
import cv2
# 加载预训练模型
model = YOLO("yolov8n.pt") # 使用YOLOv8 Nano版本
def count_objects_yolo(image_path):
img = cv2.imread(image_path)
results = model(img, verbose=False)[0]
# 绘制检测框并统计数量
count = 0
for result in results.boxes:
count += 1
x1, y1, x2, y2 = map(int, result.xyxy[0])
cv2.rectangle(img, (x1, y1), (x2, y2), (0,255,0), 2)
cv2.putText(img, f"Count: {count}", (10, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
cv2.imshow("YOLO Result", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 测试代码
count_objects_yolo("metal_pieces.jpg")优势对比
| 方法 | 优点 | 缺点 |
|---|---|---|
| 颜色阈值+轮廓分析 | 计算快,适合简单场景 | 依赖颜色特征,易受光照影响 |
| 深度学习(YOLO) | 鲁棒性强,支持复杂场景 | 需要GPU加速,模型部署复杂 |
实际应用建议
- 静态图像计数:优先使用颜色阈值+形态学处理,适合工业质检等简单场景。
- 动态视频计数:结合目标检测(如YOLO)和跟踪算法(如SORT),避免重复计数。
- 小样本优化:通过数据增强(旋转、缩放)和迁移学习提升模型泛化能力。
通过上述方法,可灵活应对不同场景下的物体计数需求。