目录
- 一、进程的基本概念与操作
-
- [1.1 什么叫做进程?](#1.1 什么叫做进程?)
- [1.2 描述进程 - PCB](#1.2 描述进程 - PCB)
- [1.3 task_struct](#1.3 task_struct)
-
- [1.3.1 初识上下文数据](#1.3.1 初识上下文数据)
- [1.3.2 第一个系统调用](#1.3.2 第一个系统调用)
-
- [获取父进程 pid 的系统调用 getppid](#获取父进程 pid 的系统调用 getppid)
- [1.3.3 如何通过代码的方式创建子进程?](#1.3.3 如何通过代码的方式创建子进程?)
-
- [proc 目录](#proc 目录)
- [1.3.4 重谈 fork](#1.3.4 重谈 fork)
- [1.3.5 关于 fork 的三个子问题](#1.3.5 关于 fork 的三个子问题)
-
- [1、为什么给父进程返回子进程的 pid,而给子进程返回 0 ?](#1、为什么给父进程返回子进程的 pid,而给子进程返回 0 ?)
- [2、调用一个 fork() 函数,怎么会产生两个返回值?](#2、调用一个 fork() 函数,怎么会产生两个返回值?)
- [3、一个 id 怎么可以接收两个不同的值,它既等于0,又大于0?](#3、一个 id 怎么可以接收两个不同的值,它既等于0,又大于0?)
个人主页:矢望
一、进程的基本概念与操作
1.1 什么叫做进程?
首先,什么叫做程序呢? 程序是磁盘上的一个普通文件!
那么什么是程序呢? 大部分教材都是这样讲的:进程是运行起来的程序,是内存中的程序。
在我们还没有启动程序之前,所加载的第一款程序就是操作系统。在我们的操作系统内可以同时运行很多的程序,这些程序,每一个都要加载到内存,于是一定会同时存在很多的进程,这些进程在操作系统中运行着,所以就需要操作系统对它们进行管理。
如何管理?我们上期博客已经引出来了,先描述,再组织。所以操作系统会对进程进行先描述:
c
strcut xxx
{
// 进程属性
struct xxx* next;
}再将这一个个节点组织成链表,这样对进程进行管理就转化成了对这个链表进行增、删、查、改。
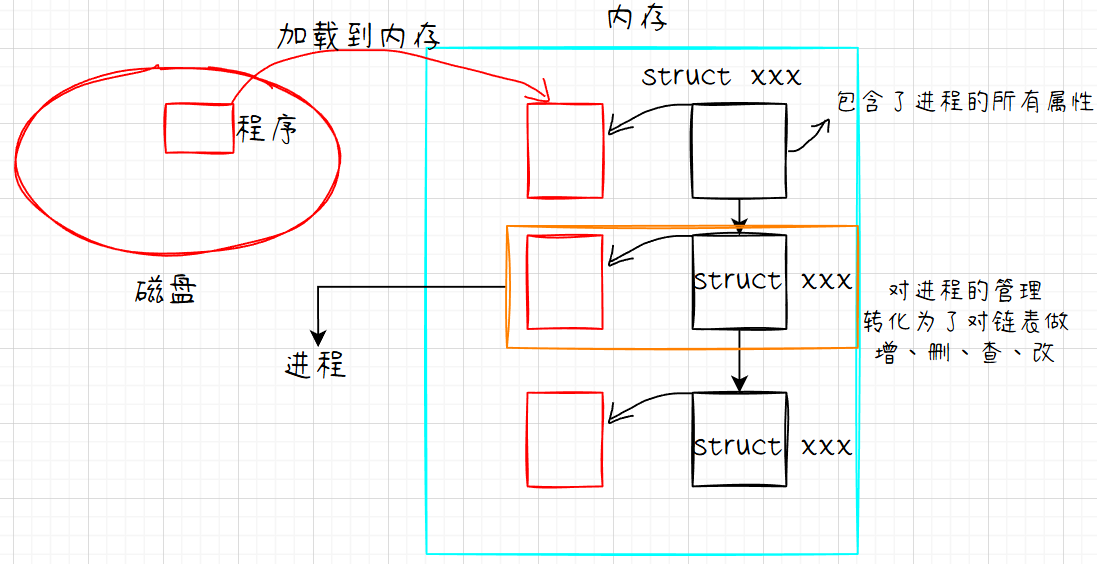
由上图,我们引出对进程更深刻的理解:进程 = 内核数据结构 + 程序的代码和数据。
1.2 描述进程 - PCB
进程信息被放在一个叫做进程控制块 PCB(process control block)的数据结构中,可以理解为进程属性的集合。Linux操作系统下的PCB是:struct task_struct。
在Linux下./cmd、Windows下双击、手机上点击app本质都是启动进程。
程序,本质是磁盘特定路径下的文件 。
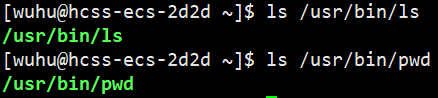

如上图,我们执行命令的本质就是启动进程。
1.3 task_struct
内容分类:
- 标识符 : 描述本进程的唯一标识符,用来区别其他进程,
pid。 - 状态: 任务状态,退出代码,退出信号等。
- 优先级:相对于其他进程的优先级。因为资源有限,所以才需要优先级。
- 程序计数器 : 程序中即将被执行的下一条指令的地址。作用 : 决定进程的执行流 ,没有程序计数器,进程就无法知道自己下一步该做什么,代码将无法执行;实现进程切换和并发执行,进程切换时,原来执行进程的执行状态需要被保存,等到再次轮到这个进程时,这个进程才能从上次中断的位置继续执行。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
- 上下文数据: 进程执行时处理器的寄存器中的数据。
I/O状态信息 : 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其它信息。
1.3.1 初识上下文数据
首先引入一个问题,一个进程执行代码,占有CPU,是把自己的代码执行完才放弃CPU的吗?
答案肯定是不是 。试想一下,如果真是执行完才离开CPU,那么当你写了一个死循环代码并运行,此时你的操作系统就立刻卡死了,因为它除了这个代码什么都做不了了。
当代计算机都会给每一个进程分配一个时间片 ,时间片执行完毕,进程就会让出CPU,让接下来的进程执行,这叫做基于时间片的轮转调度 。注 :时间片是操作系统分配给每个正在运行的进程的一段最大CPU执行时间。
所以一个进程可能没有执行完成,就把CPU让给了另一个进程。只要时间片一到,就会存在进程的切换和调度的工作。
那么假设一个进程执行代码到了中间某一行,时间片结束了,此时最重要的就是保存它的上下文数据 ,因为如果不保存,那不是意味着执行数据丢失,难道下次还要从头开始吗?所以在进程切换时需要保存上下文数据,等再次轮到该进程进行恢复上下文数据 。上下文数据是进程私有的 ,它是进程对应CPU内寄存器中的临时数据。
补充:程序计数器属于上下文数据的一部分。
1.3.2 第一个系统调用
一个进程如何获取自己的标识符呢?我们知道标识符是task_struct内部的属性值,操作系统肯定不会让你直接访问的。所以想要访问它,操作系统就必须给我们提供一个系统调用接口,来获取自己的PID。
系统调用getpid :
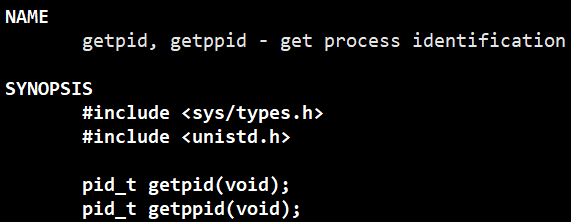
写程序获取自身进程的PID:
c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
while(1)
{
pid_t id = getpid();
printf("当前进程的 pid: %d\n", id);
sleep(1);
}
return 0;
} 上面的代码中pid_t是int封装的一个宏定义,本质就是整型。
编译运行 :
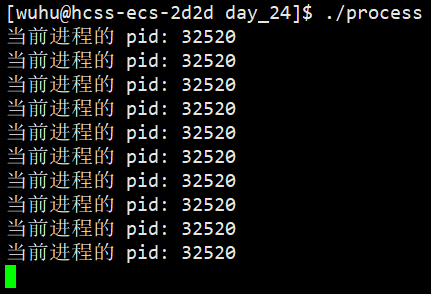
此时它就把自身这个进程的PID打印出来了,那么如何证明它是一个进程呢?
ps axj:用于查看进程信息 。
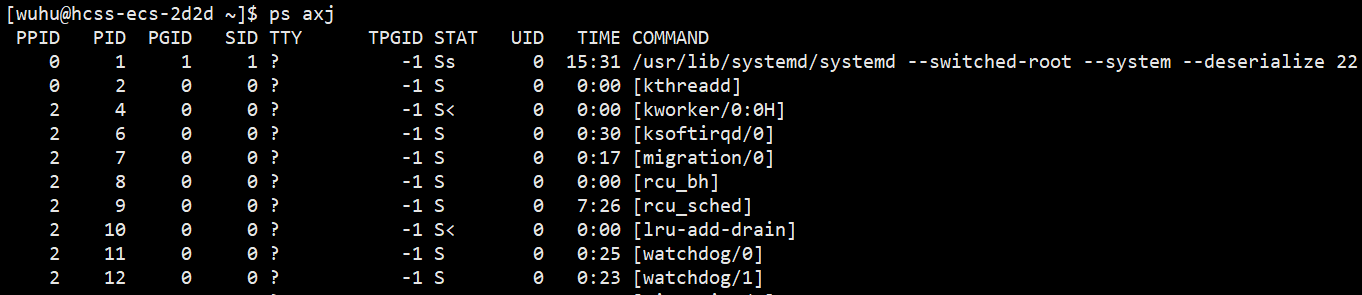
它会显示一长串,我们进行过滤一下,只要第一行和指定进程的信息。ps axj | head -1; ps axj | grep -i process。

如上图,我们所执行的程序就是一个进程,它的PID是32520。
当我们把程序停止掉,相应的进程信息也就不存在了。

上面显示还有信息,是因为我们在过滤时启动了grep进程。
此外当你不断执行程序时,你会发现对应的PID是变化的。
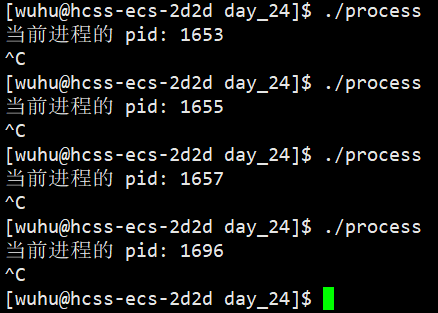
这是因为 PID 通常是一个递增的数值,它每创建一个新进程自身就会++,但并非无限增长,达到最大值后会回绕。
获取父进程 pid 的系统调用 getppid
除了获取自身的id值pid外,还存在一个ppid,它是父进程的id值。
这里为了编译方便,写一下Makefile:
c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
while(1)
{
//pid_t id = getpid();
printf("当前进程的 pid: %d, 父进程 ppid: %d\n", getpid(), getppid());
sleep(1);
}
return 0;
}编译运行 :

在Linux系统当中,子进程 往往通过父进程创建出来。
那么从上图中的运行结果,我们也看到父进程了,我们再多运行几次观察一下。
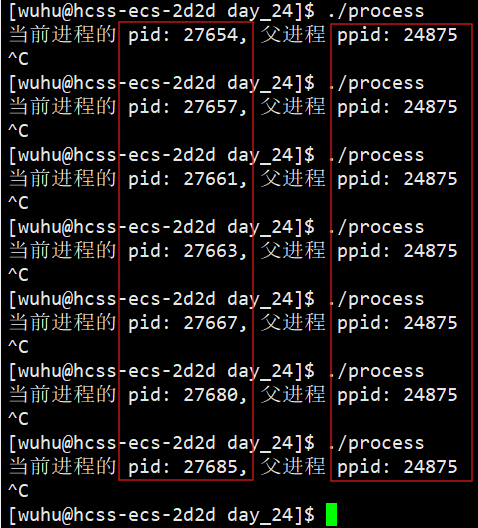
由上图可见,父进程ppid一直不变,子进程pid一直改变,那这个父进程是谁呀?
我们直接进行查询:ps axj | head -1 && ps axj | grep 24875。
哦!我们执行自己写的程序,执行系统命令,它们的父进程都是bash ,也就是命令行解释器!bash也是一个进程。
1.3.3 如何通过代码的方式创建子进程?
它的本质是操作系统中多了一个子进程,也就意味着多了一份task_struct + 代码和数据,操作系统是不允许用户直接创建一个task_struct,并填写属性数据的,所以想要创建子进程,操作系统就必须给我们相关的系统调用,这个系统调用叫做fork。
接下来,我们对代码进行修改。
c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("我是一个进程 pid: %d, ppid: %d\n", getpid(), getppid());
fork();
printf("我是一个(fork)进程 pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
return 0;
}编译运行 :
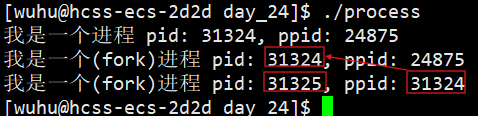
我们发现后面的一句代码竟然执行了两次,并且其中一句说它的父进程是31324,并且之前的进程的pid就是31324。这说明fork之后出现了两个执行流,一个是fork之前的父进程,一个是fork之后的子进程。
为了证明它们是两个进程,再次修改代码。
c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("我是一个进程 pid: %d, ppid: %d\n", getpid(), getppid());
fork();
while(1)
{
printf("我是一个(fork)进程 pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
return 0;
}编译运行 :

如上图,出现了两种打印结果,很明显,一个是子进程打印的,一个是父进程打印的。
proc 目录
我们的进程信息会实时在/proc目录下显示,/proc 文件是瞬时的,读取时生成,不保存;进程退出后,对应目录消失。

如上图,当我们运行我们的进程时,我们的进程信息会记录在/proc目录下,结束进程之后,。/proc下对应的目录就消失了。
其中在对应的进程的目录文件中,存在一个cwd,这是一个符号链接,指向进程的当前工作目录 。
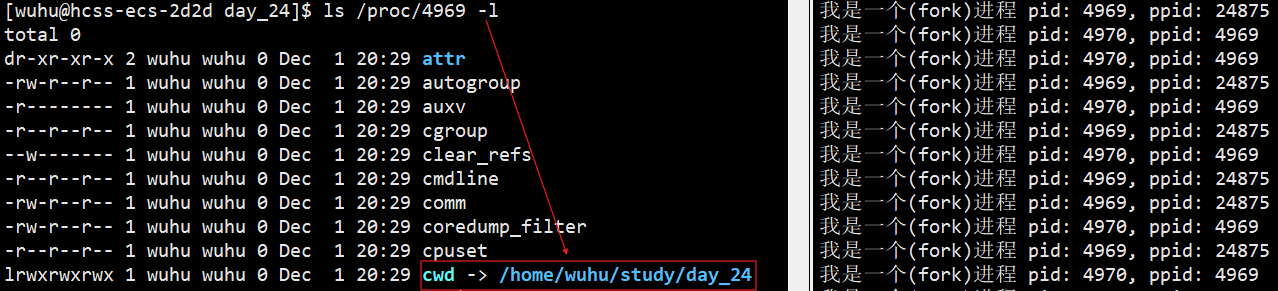
我们之前学C语言时,学过一个fopen函数,这个函数执行fopen("log.txt", "w");时,文件如果不存在,就会在当前路径下创建它,那么什么时当前路径呢?
再次对process.c进行修改。
c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
FILE* fp = fopen("log.txt", "w");
fclose(fp);
printf("我是一个进程 pid: %d, ppid: %d\n", getpid(), getppid());
fork();
while(1)
{
printf("我是一个(fork)进程 pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
return 0;
}编译运行 :
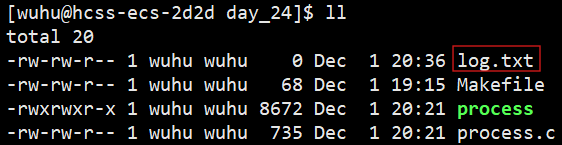
由上图,再结合cwd对应的路径,我们得知当前路径就是当前进程的工作路径。
如何证明呢?我们可以改变cwd,看看log.txt是否还会出现在当前路径下。更改cwd也就是更改进程的内核属性,操作系统不会允许你直接更改的,所以它会给你提供系统调用,chdir。
chdir :
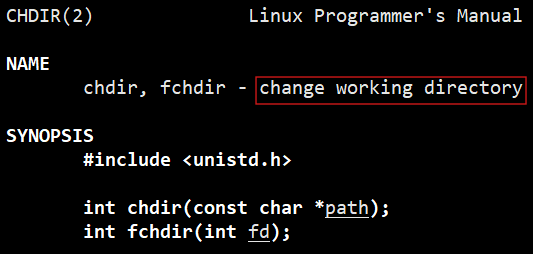
修改代码:
c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
chdir("/home/wuhu/study");
FILE* fp = fopen("log.txt", "w");
fclose(fp);
printf("我是一个进程 pid: %d, ppid: %d\n", getpid(), getppid());
fork();
while(1)
{
printf("我是一个(fork)进程 pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
return 0;
}如上面的代码所示,我把工作路径更改到了上级目录,接下来,我们编译运行:
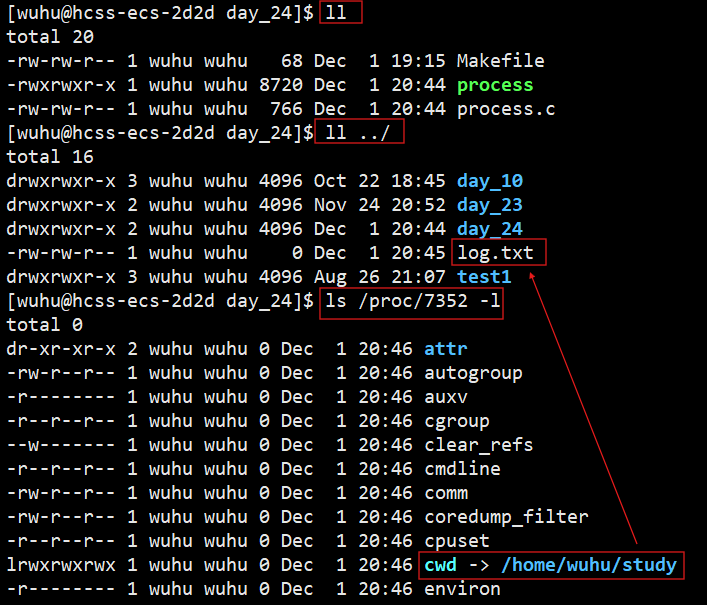
随着我们cwd的更改,再次执行程序,我们发现log.txt果然没有出现在当前目录下,而是在上级目录进行了创建。
所以当前工作路径,本质是你的进程的工作路径。
1.3.4 重谈 fork
在上面的知识中,我们了解到fork语句执行之后,会出现两个执行流,fork语句之后的代码是被这两个执行流共享的。
我们创建子进程通常是为了让它完成新的任务的,而不是和我们的父进程掺和到一起,如何让它执行新的任务呢?
此时就需要了解fork的返回值了,关于fork的返回值,在man指令的交互界面输入/return value即可显示:

什么意思呢? pid_t id = fork();如果fork成功,子进程的pid将会返回给父进程,而0将会返回给子进程,如果fork失败,将会给父进程返回-1。
所以我们可以使用它的返回值给父子进程进行分流。
c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("我是父进程 pid: %d, ppid: %d\n", getpid(), getppid());
pid_t id = fork();
if(id < 0) perror("fork");
else if(id == 0)
{
//子进程
while(1)
{
printf("我是子进程 pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
}
else
{
//父进程
while(1)
{
printf("我是父进程 pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
}
return 0;
}编译运行 :

这样就可以进行父进程子进程分流了。
再次观察我们的代码,编译运行后是两个死循环同时在运行,这就是一份代码,两个进程。
1.3.5 关于 fork 的三个子问题
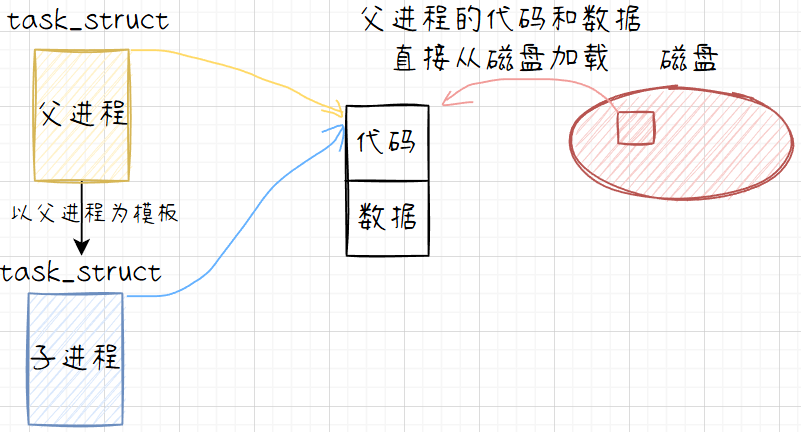
如上图所示,子进程是以父进程为模板创建的。默认情况下,fork()之后,代码和数据一般都是父子进程所共享的。
1、为什么给父进程返回子进程的 pid,而给子进程返回 0 ?
父进程可以有很多个子进程,但子进程只有一个父进程,因此,父进程需要一对多的管理能力,而子进程只需要一对一的身份识别。
给父进程返回子进程的pid,这样可以标识特定的子进程,将来能够更好的管理和跟踪子进程。给子进程返回0,这样可以让子进程能够轻松地识别自己是子进程。
再次对我们的代码进行修改:
c
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("我是父进程 pid: %d, ppid: %d\n", getpid(), getppid());
pid_t id = fork();
if(id < 0) perror("fork");
else if(id == 0)
{
while(1)
{
printf("我是子进程 pid: %d, ppid: %d, id: %d\n", getpid(), getppid(), id);
sleep(1);
}
}
else
{
while(1)
{
printf("我是父进程 pid: %d, ppid: %d, id: %d\n", getpid(), getppid(), id);
sleep(1);
}
}
return 0;
}编译运行 :
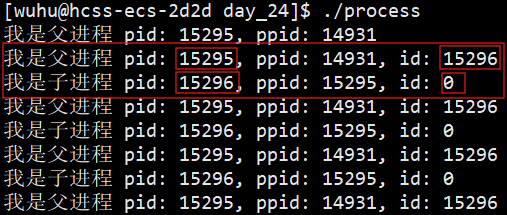
如上,父进程获得子进程的pid,子进程获得的id是0。另外,这里因为我重启了一下命令行解释器,所以bash的pid变了,不用感到疑惑。
2、调用一个 fork() 函数,怎么会产生两个返回值?
如果一个函数准备返回了,那么它的核心工作已经做完了,也就是说,在fork()返回之前就有了父进程和子进程!

如上图所示,return语句本身也是代码,而默认情况下,fork之后,父子进程共享之后的代码和数据,所以父进程和子进程会各自执行return语句! 所以这就是fork()返回两次的原因。
3、一个 id 怎么可以接收两个不同的值,它既等于0,又大于0?
pid_t id = fork();,id怎么能够接收两个不同的值呢?
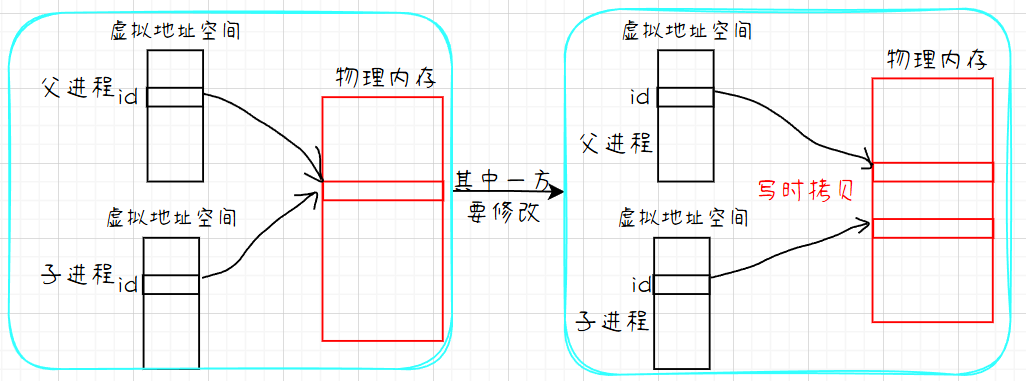
当 fork() 创建子进程时,最关键的是:父进程和子进程有各自独立的内存空间(虚拟地址空间 ),每个进程都有自己独立的变量副本。这意味着:父进程有一个 id 变量,子进程有另一个 id 变量。它们只是名字相同,但物理上存储在不同的内存位置,属于不同的进程。
写时拷贝的核心过程:
- 初始状态(共享) :
fork()刚完成时,父子进程的id变量确实指向同一块物理内存。 - 触发分离(写时) :当任何一个进程试图修改这个变量时,操作系统才会为修改方创建独立的副本。(
return返回的本质就是写入,就是修改id的值) - 最终状态(独立) :修改完成后,两个进程的
id变量就指向了不同的物理内存。
流程图 :
总结:
以上就是本期博客分享的全部内容啦!如果觉得文章还不错的话可以三连支持一下,你的支持就是我前进最大的动力!
技术的探索永无止境! 道阻且长,行则将至!后续我会给大家带来更多优质博客内容,欢迎关注我的CSDN账号,我们一同成长!
(~ ̄▽ ̄)~