主要参考:
注意力机制的应用_哔哩哔哩_bilibili 视觉 注意力机制------通道注意力、空间注意力、自注意力-CSDN博客
神经网络学习小记录64------Pytorch 图像处理中注意力机制的解析与代码详解_注意力机制 bubbliiiing-CSDN博客
注意力机制的核心重点就是让网络关注到它更需要关注的地方。
一般而言,注意力机制可以分为通道注意力机制,空间注意力机制,以及二者的结合。
一、SENet 通道注意力
- 对输入进来的特征进行全局平均池化;
- 进行两次全连接:第一次进行神经元个数较少的全连接;第二次进行的全连接和输入参数量相同;
- 经过两次全连接之后,经过sigmoid函数将值固定到0-1之间,因此获得输入特征层每一个通道的权值。
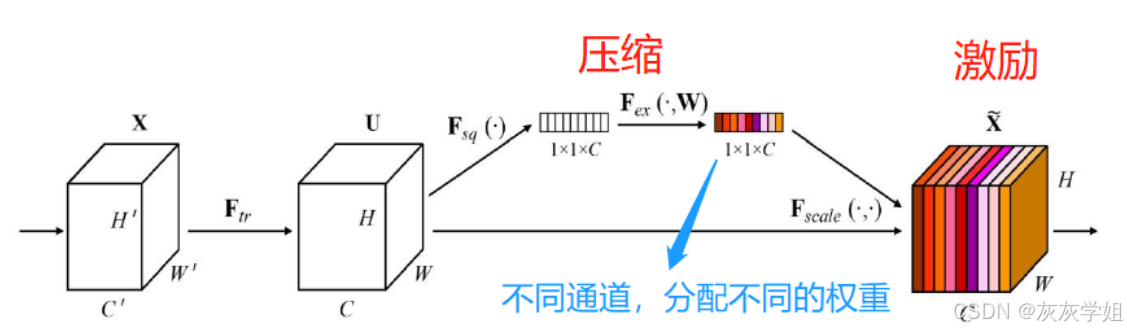
也可以理解成压缩和激励两个部分:(压缩部分)对全局空间信息进行压缩,在通道维度进行特征学习;(激励部分)对激励部分的各个通道进行权重分配,具体来说:
- 压缩部分:输入特征维度为H×W×C,分别代表高度、宽度、通道数,通过全局平均池化将维度压缩成1×1×C,即把H×W压缩成1×1
- 激励部分:将压缩得到的1×1×C维度融入全连接层,得到各个通道的重要程度,并使用sigmoid函数规范到0-1之间。
python
class SENet(nn.module):
def __init__(self, channel, ratio=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel / ratio)
nn.ReLU()
nn.Linear(channel / ratio, channel)
nn.Sigmoid()
)
def forward(self, x):
b, c, h, w = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, h, w)
return x * y
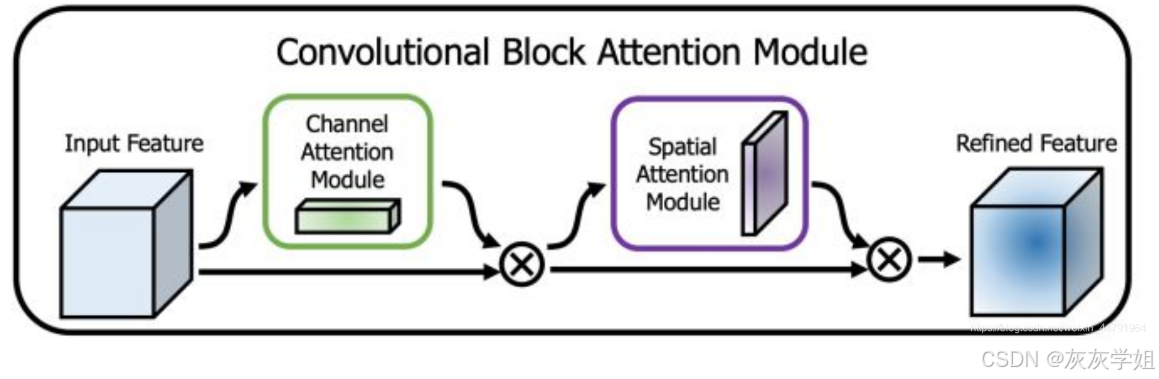
二、CBAM 通道注意力+空间注意力
CBAM对输入进来的特征层分别进行通道注意力和空间注意力处理,先通道后空间。
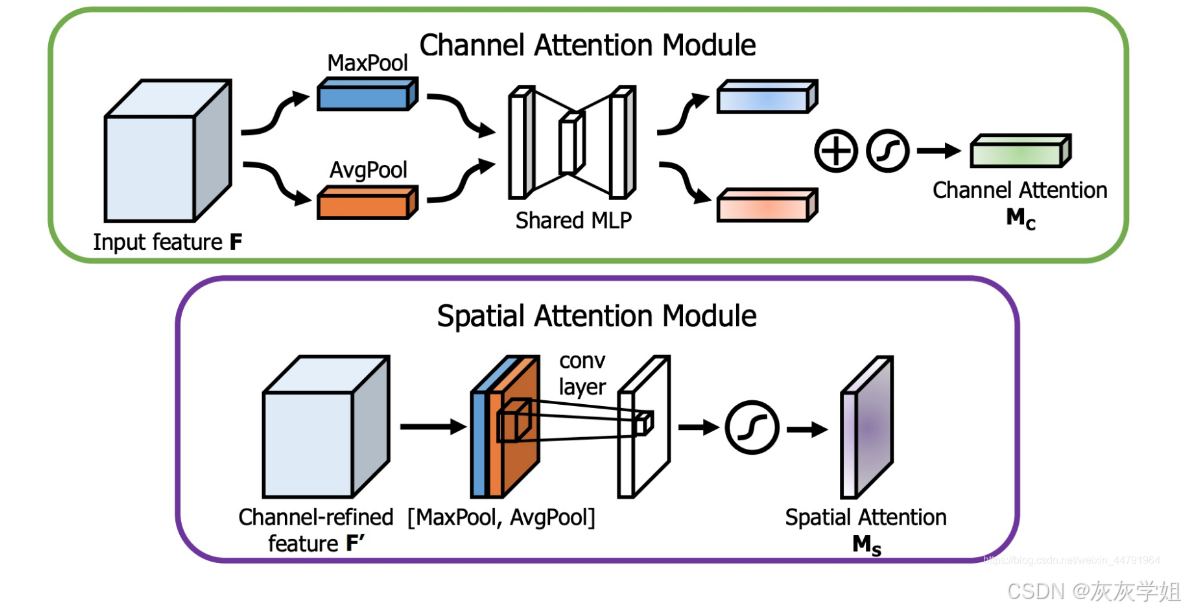
通道注意力模块:对输入特征进行全局最大值池化和全局平均池化(在空间维度进行池化压缩,压缩空间尺寸),然后将得到的特征送入多层感知机MLP学习(共享的全连接层),然后对结果进行相加,取sigmoid(0-1之间),获得通道注意力的权值。B C H W → B C 1 1 → B C H W
空间注意力模块:对输入特征进行全局最大值池化和全局平均池化(在通道维度上进行池化压缩,压缩通道大小);将全局平均池化和全局最大值池化的结果,按照通道进行拼接,得到H×W×2的特征图;然后对拼接结果进行卷积操作,得到H×W×1的特征图;接着取一个sigmoid(0-1之间)。B C H W →B 1 H W →B 2 H W →B 1 H W →B C H W
python
class ChannelAttention(nn.Module):
def __init__(self, channel, ratio=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(channel, channel//ratio, 1, bias=False)
self.relu = nn.ReLU()
self.fc2 = nn.Conv2d(channel//ratio, channel, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.sigmoid(self.fc2(self.relu(self.fc1(self.avg_pool(x)))))
max_out = self.sigmoid(self.fc2(self.relu(self.fc1(self.max_pool(x)))))
out = torch.cat((avg_out, max_out), 1)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
assert kernel_size in [3, 7]
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out = torch.max(x, dim=1, keepdim=True)
out = torch.cat((avg_out, max_out), 1)
out = self.sigmoid(self.conv(out))
return out
class CBAM(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super().__init__()
self.channelattention = ChannelAttention(channel,ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x