ZegFormer
创新点
核心思想是:对于像素进行分类的操作不符合人类的思维方式,我们擅长对于一个区域(Segment)进行分类。
因此,论文提出将 ZS3 解耦为两个独立子任务:
- 类无关的图像分组
- 把像素分成不同区域(segments),不依赖类别信息 ,因此具有天然的泛化性。
区域级别 zero-shot 分类(Segment-level Zero-Shot Classification)
对每个 segment 做类别预测。由于这是区域级别而非像素级别,因此可以自然使用像 CLIP 这样的大规模视觉-语言模型。
这一解耦使得模型更贴近人类的分割过程(先分块再识别)。
*新定义
作者对于ZS3和GZS3的新定义方式,还是比较有意思
简单来说就是把语义分割看成两个部分:
- 先对图像进行分块 ,例如R\mathcal{R}R表示多个区域,这些区域不重叠
- 然后找到一种标签映射关系 L\mathcal{L}L,用于将这些区域映射到标签集合

方法
块嵌入
-
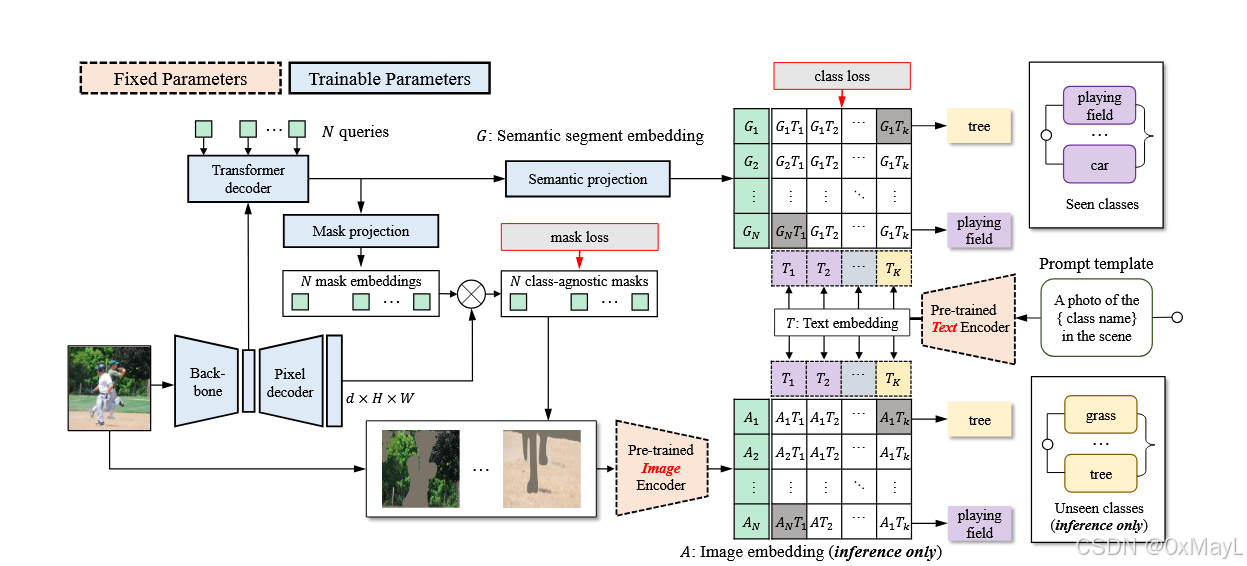
作者借助了MaskFormer 的经典思想,引入N个可以学习的块嵌入,用于编码图像中的嵌入 ,G∈RN×DG\in R^{ N \times D}G∈RN×D
-
借助一个视觉模型如ResNet+像素级解码器得到特征图F(I)∈RD×H×WF (I) ∈ R^{D×H×W}F(I)∈RD×H×W,这个特征图大小与原始图像一致。
-
将块嵌入和特征图送入一个解码器得到学习后的块嵌入 G∈RN×DG\in R^{ N \times D}G∈RN×D,这个块嵌入可以直接用于CLIP的分类。

- 利用该块嵌入与文本嵌入进行相似度计算,得到每一个块嵌入的分布p∈RN×Cp\in R^{N \times C}p∈RN×C

- 与MaskFormer不同的是,由于是零样本语义分割,没有基于MLP的线性层 ,而是通过将CLIP文本编码器的嵌入与块嵌入进行相似度计算来实现学习类别的概率分布。
- 与MaskFormer一致,引入了no object用于学习分类概率 。

掩码嵌入
- 与MaskFormer一致,作者引入了一个块掩码嵌入B∈RN×DB \in R^{ N \times D}B∈RN×D,用于学习特征图中的掩码m∈RH×Wm\in R^{ H \times W}m∈RH×W。

- 作者对原始图像和掩码图像 进行融合操作,然后送给CLIP的视觉编码器 提取图像嵌入 A∈RN×DA\in R^{N\times D}A∈RN×D
- 这一部是不需要训练的。


- 类似块嵌入,计算相似度 ,得到如下概率分布:p′∈RN×Cp' \in R^{N \times C}p′∈RN×C
训练
- 使用二分图匹配得到最接近的类别
- 对于每一个块嵌入,计算交叉熵损失。
- 对于生成的掩码损失,与真实掩码计算DICE和FOCAL损失。
推理
- 未完待续
推理阶段就是结合两个概率分布,乘以得到掩码,进行求和。
