索引是数据库性能优化的核心工具,能够极大提升查询效率。
然而,不当使用索引也可能带来写入性能下降、维护成本增加等问题。
本文将系统讲解MySQL索引的原理、结构、类型、创建与优化策略,帮助你深入理解索引工作机制。
一、索引的核心作用
索引的主要作用是提高数据库的查询速度,尤其是在大数据量表中,通过索引可以快速定位到目标数据,避免全表扫描。
代价: 索引需要维护,会降低增、删、改操作的效率。
因此,是否创建索引、创建什么样的索引,需要根据业务场景权衡。
二、索引背后的数据结构
索引的本质是在原有数据之上建立一种高效的数据结构 ,以加速查找。MySQL中最常用的索引数据结构是B+树。
为什么是B+树?
B+树具有以下优势:
- 矮胖结构,高度低:减少磁盘I/O次数。
- 叶子节点有序且用链表连接:支持高效的范围查询。
- 非叶子节点只存目录(指针):可存储更多目录项,管理更多数据页。
相比之下:
- 链表:查找效率O(N)
- 二叉搜索树:可能退化成链表,且高度高
- AVL/红黑树:高度依然较高,I/O多
- Hash索引:大量数据哈希冲突严重,并且不支持范围查询,InnoDB默认不支持
三、MySQL索引类型
| 索引类型 | 说明 |
|---|---|
| 主键索引(PRIMARY KEY) | 唯一且不为空,一张表只能有一个 |
| 唯一索引(UNIQUE) | 值必须唯一,允许为空 |
| 普通索引(INDEX) | 最基本的索引,无唯一性约束 |
| 全文索引(FULLTEXT) | 用于全文搜索,仅MyISAM支持(中文需插件) |
四、索引的物理存储:Page与Buffer Pool
1. MySQL与磁盘交互单位
- 操作系统IO单位:4KB(块)
- MySQL InnoDB IO单位:16KB(Page)
2. Buffer Pool
MySQL启动时会申请一块大内存(默认128MB)作为Buffer Pool,用于缓存磁盘中的Page,减少直接磁盘I/O。
3. Page管理
每个Page用结构体描述,通过链表组织。数据加载时从磁盘读入Buffer Pool,修改后再刷回磁盘。
五、主键索引为什么有序?
我们创建一个表并乱序插入数据:
sql
CREATE TABLE user (
id INT PRIMARY KEY,
age INT NOT NULL,
name VARCHAR(32) NOT NULL
);查询时发现结果按id排序:
+----+-----+-----------+
| id | age | name |
+----+-----+-----------+
| 1 | 56 | 欧阳锋 |
| 2 | 26 | 黄蓉 |
| 3 | 18 | 杨过 |
| 4 | 16 | 小龙女 |
| 5 | 36 | 郭靖 |
+----+-----+-----------+原因:主键索引在物理存储上是按主键值排序的,便于构建B+树目录结构,提高查询效率。
六、B+树索引结构图示
1. 单Page目录
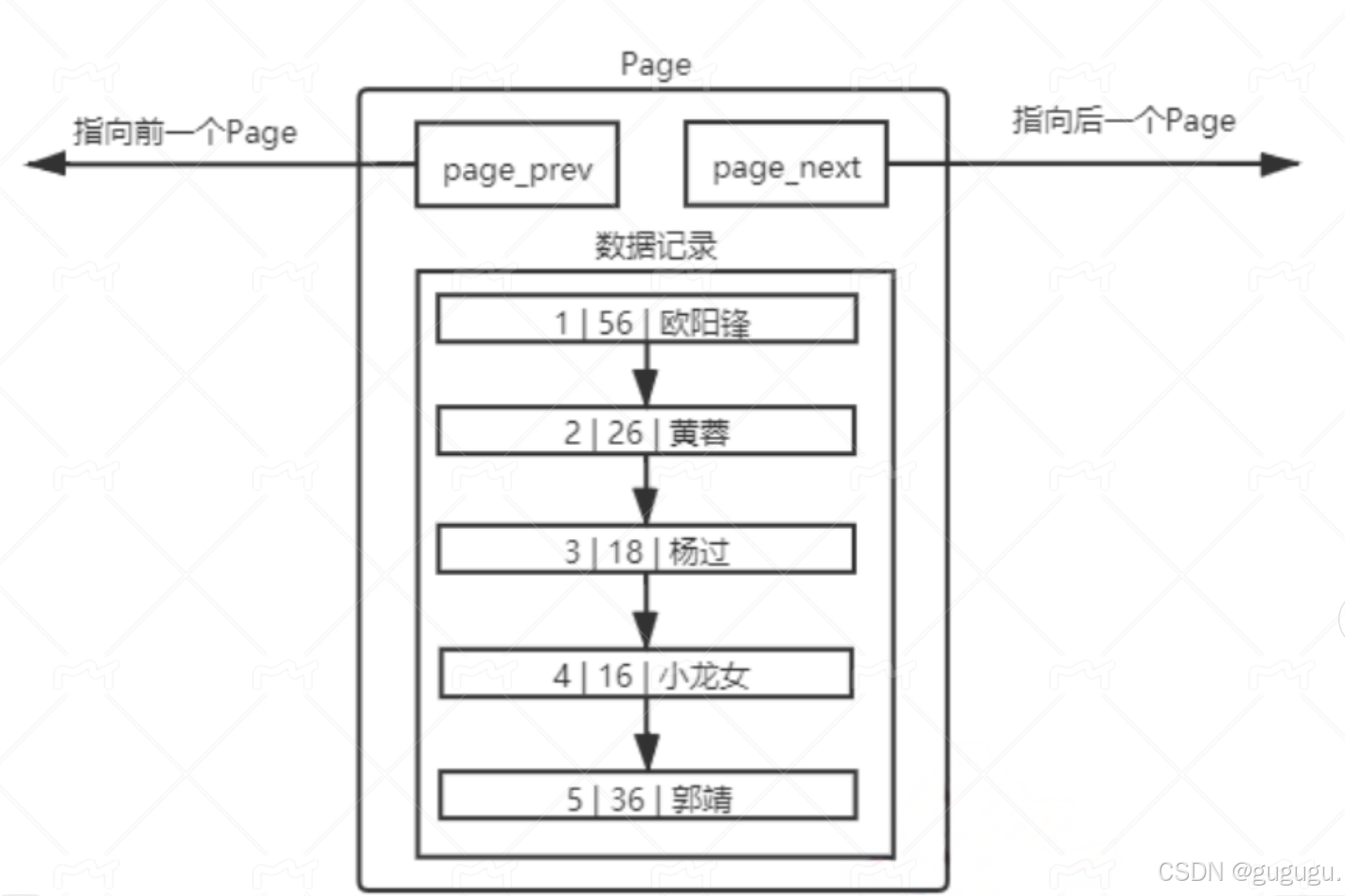
2. 多级Page目录 → B+树
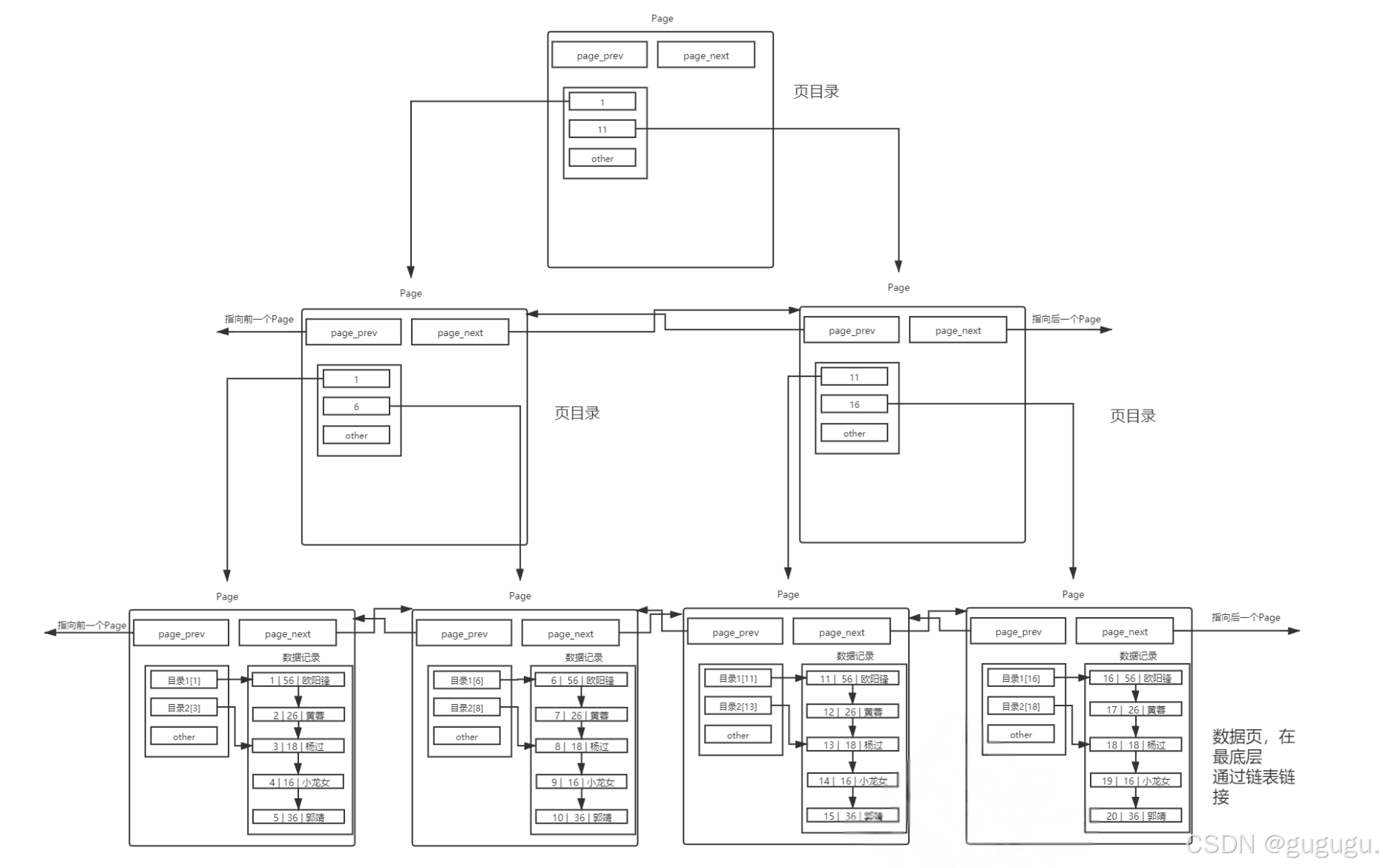
B+树特点:
- 非叶子节点只存储指针(目录)
- 叶子节点存储数据,并用链表连接
- 支持高效的范围查询
七、聚簇索引 vs 非聚簇索引
| 类型 | 存储方式 | 引擎 |
|---|---|---|
| 聚簇索引 | 索引与数据存放在一起(叶子节点存数据) | InnoDB |
| 非聚簇索引 | 索引与数据分离(叶子节点存数据地址) | MyISAM |
InnoDB辅助索引(回表查询)
InnoDB的辅助索引叶子节点存储的是主键值,而不是数据地址。查询时需要:
- 在辅助索引B+树中找到主键值
- 再回到主键索引中查找完整数据
为什么存主键值而不存地址?
因为数据地址可能变化,存主键值可避免频繁同步更新辅助索引,维护成本更低。
八、索引操作语法
1. 查看索引
sql
SHOW INDEX FROM user;
-- 或
DESC user;2. 创建索引
sql
-- 普通索引
ALTER TABLE user ADD INDEX(name);
CREATE INDEX idx_name ON user(name);
-- 唯一索引
ALTER TABLE user ADD UNIQUE(age);
-- 主键索引
ALTER TABLE user ADD PRIMARY KEY(id);3. 删除索引
sql
ALTER TABLE user DROP INDEX idx_name;
ALTER TABLE user DROP PRIMARY KEY;九、复合索引与最左匹配原则
1. 创建复合索引
sql
CREATE INDEX idx_age_name ON user(age, name);2. 最左匹配原则
索引按列顺序存储,查询时必须从最左列开始匹配:
- ✅
WHERE age = 20 AND name = '张三' - ✅
WHERE age = 20 - ❌
WHERE name = '张三'(无法使用该复合索引)
3. 索引覆盖
如果查询的列都在索引中,则无需回表:
sql
SELECT name FROM user WHERE age = 20;此时直接在索引中即可获取数据,效率极高。
十、索引创建原则
- 频繁作为查询条件的列应建索引
- 区分度高的列适合建索引(如ID、手机号)
- 频繁更新的列谨慎建索引(维护成本高)
- 不在WHERE中出现的列不应建索引
- 小表不建议建索引(全表扫描可能更快)
十一、全文索引(FULLTEXT)
仅MyISAM支持,适用于文本内容搜索:
sql
CREATE TABLE articles (
id INT,
title VARCHAR(256),
body TEXT,
FULLTEXT(title, body)
) ENGINE=MyISAM;
-- 使用全文索引查询
SELECT * FROM articles WHERE MATCH(title, body) AGAINST('database');注意:MySQL默认全文索引不支持中文,需安装插件(如ngram)。
十二、索引失效常见场景
- 使用
LIKE '%xxx'左模糊匹配 - 对索引列进行函数或表达式计算
- 类型转换(如字符串列用数字查询)
- 使用
OR且部分列无索引 - 复合索引未遵循最左匹配原则
十三、使用EXPLAIN分析查询
EXPLAIN是MySQL提供的查询执行计划分析工具,可显示索引使用情况、扫描行数等关键信息:
sql
EXPLAIN SELECT * FROM user WHERE age = 20;输出结果包含:
type:访问类型(如ref、index、all)key:实际使用的索引rows:预估扫描行数Extra:额外信息(如Using index、Using where)
总结
索引是数据库性能调优的双刃剑:
- ✅ 正确使用可极大提升查询性能
- ❌ 滥用或不当使用会导致写入性能下降、存储浪费
理解B+树结构、聚簇/非聚簇索引区别、最左匹配原则等核心概念,结合实际业务场景合理设计索引,才能让数据库既跑得快又跑得稳。
本文基于MySQL InnoDB引擎讲解,部分特性在其他引擎中有所不同。实际使用时请结合存储引擎特性进行决策。