TL;DR
- 场景:从零搭建 Elasticsearch 索引,需要搞清楚映射配置和文档增删改查的完整流程。
- 结论:围绕 mapping、_doc、新增/查询/更新/删除 全链路串起来,并给出常见坑位与推荐写法。
- 产出:一套可复制的索引 + 映射 + 文档 CRUD 示例,附常见错误速查表与版本适配说明。

版本矩阵
| 组件 / 版本 | 已验证 | 说明 |
|---|---|---|
| Elasticsearch 7.x(无 type) | 是 | 示例语法基于 7.x"取消自定义 type,统一为 _doc"的映射风格。 |
| Elasticsearch 8.15.x 文档语法 | 是 | 映射字段类型参考 8.15 官方 mapping-types 文档,语法基本兼容 7.x。 |
| IK 分词器(7.x/8.x 适配版) | 是 | 示例中使用 ik_max_word、ik_smart,需读者按所用 ES 版本安装对应版。 |
| 单节点 / 简单集群环境 | 是 | 示例在无鉴权、单集群场景可直接复现,安全与多租户配置未在本文展开。 |
| 其他 7.x/8.x 小版本 | 理论兼容 | 语法上应通用,遇到差异以官方文档与实际错误信息为准。 |
映射操作
索引创建之后,等于有了关系型数据库中的Database,Elasticsearch7.x取消了索引type类型的设置,不允许指定类型,默认为_doc,但字段仍然是有的,我们需要设置字段的约束信息,叫做字段映射(mapping) 字段的约束包括但不限于:
- 字段的数据类型
- 是否要存储
- 是否要索引
- 分词器
创建映射字段
语法:
shell
PUT /索引名/_mapping
{
"properties": {
"字段名": {
"type": "数据类型",
"index": true,
"store": false,
"analyzer": "分词器"
}
}
}上述内容解释如下:
- type 类型,可以是 text、long、short、date等等
- index 是否为索引 默认为true
- store 是否存储 默认为false
- analyzer 分词器
示例:
shell
# 新建索引
PUT /wzkicu-index
# 映射关系
PUT /wzkicu-index/_mapping/
{
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"job": {
"type": "text",
"analyzer": "ik_max_word"
},
"logo": {
"type": "keyword",
"index": "false"
},
"payment": {
"type": "float"
}
}
}运行结果如下图所示: 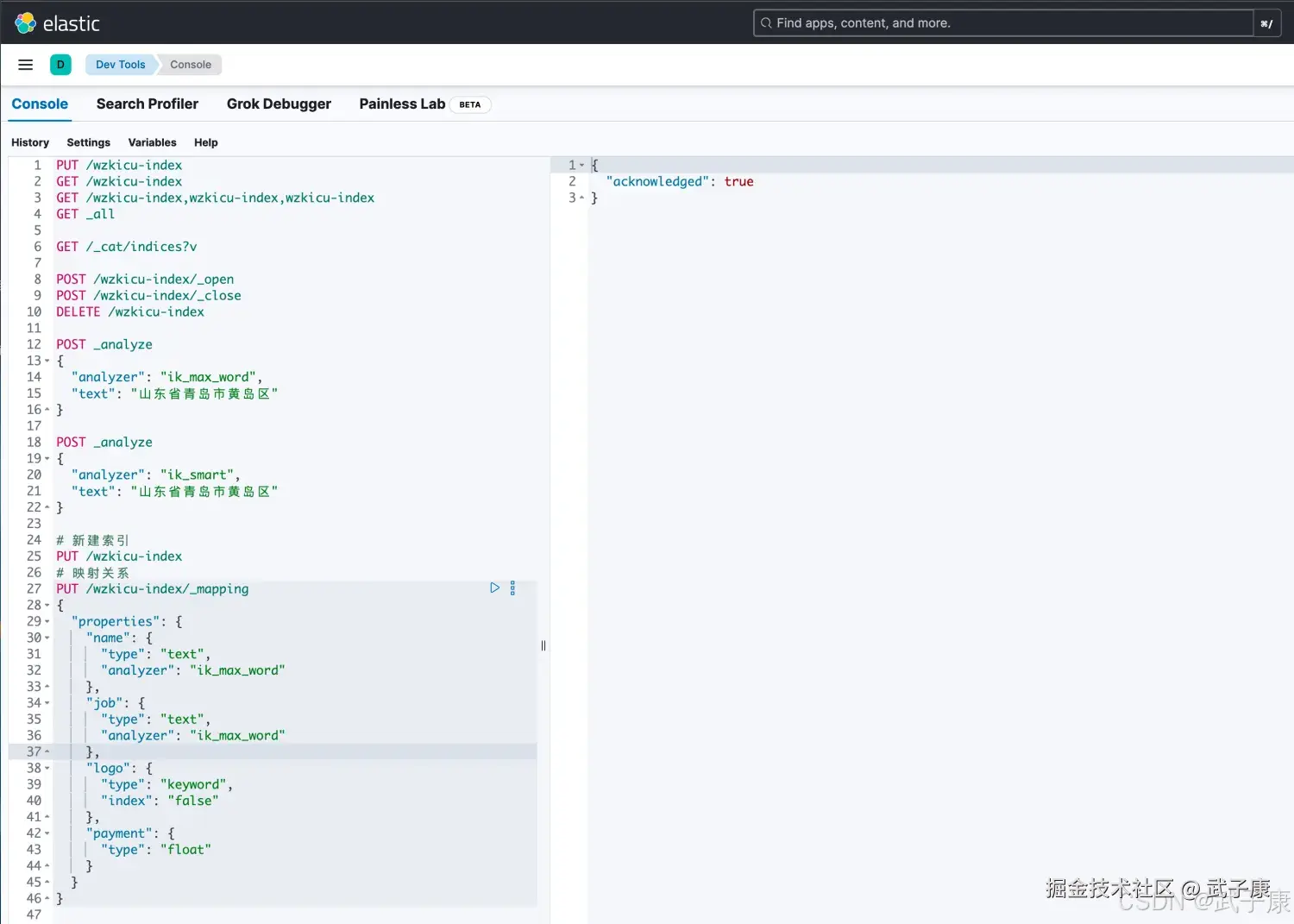 上图中,包含的字段如下所示,并且加了一些属性:
上图中,包含的字段如下所示,并且加了一些属性:
- name 企业名称
- job 需求岗位
- logo logo图片地址
- payment 薪资
映射属性详解
支持的类型非常的多,可以访问对应的文档进行查看:
shell
https://www.elastic.co/guide/en/elasticsearch/reference/8.15/mapping-types.html对应的页面如下图所示: 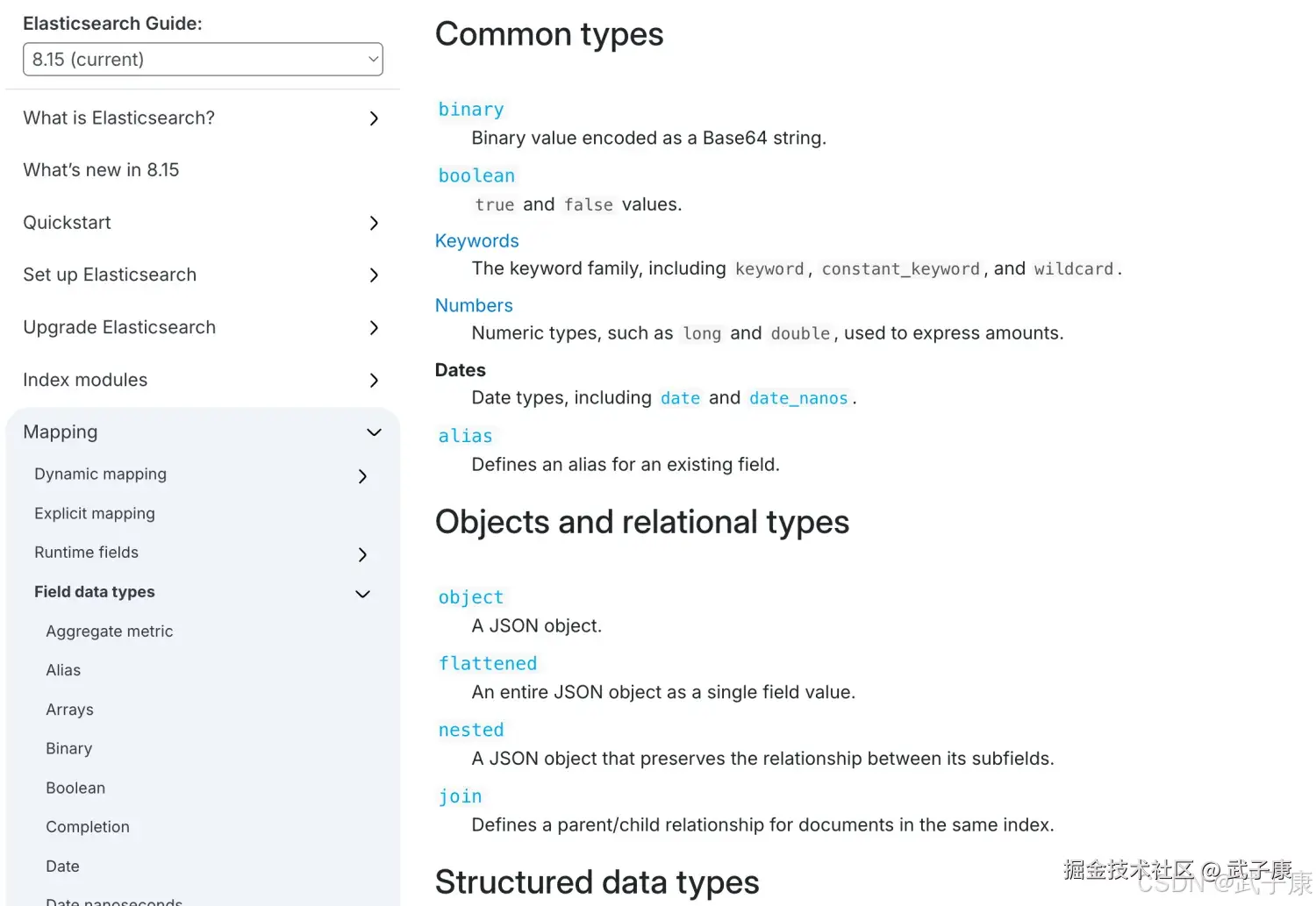 这里有几种:
这里有几种:
- String类型:text可分词,不可参与聚合。keyword不可分词,作为完整字段进行分配,可以参与聚合。
- Numerical类型:数值类型、分两类,基本数据类型、浮点数的高精度类型
- Date:日期类型,ES可以对日期格式化字符串存储,但是建议我们存储为毫秒值、存储为long、节省空间。
- Array 数组类型,进行匹配时,任意一个元素满足,都认为满足。排序时,如果升序则用数组中最小值来排序,如果降序则用数组中的最大值来排序
- Object对象,{ name: "jack", age: 21, girl: {name: "Rose", age: 21}},如果存储到索引库是对象类型,例如上面的girl,会把girl变成girl.name和girl.age
- index,true字段会被索引,则可以用来进行搜索,默认值就是true。false字段不会被索引,不能用来搜索。比如LOGO的图片地址,这种不需要索引,就可以设置为False。
- store,是否将数据进行独立存储,原始的文本存储在 _source里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提取出来的。当然你也可以独立的存储某个字段,只要设置store:true即可,获取独立存储的字段要比_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需要来设置,默认为false
- analyzer:指定分词器 一般使用IK分词器 ik_max_word ik_smart
查看映射关系
单个映射关系 语法:
shell
GET /索引名称/_mapping示例:
shell
GET /wzkicu-index/_mapping执行的结果如下图所示: 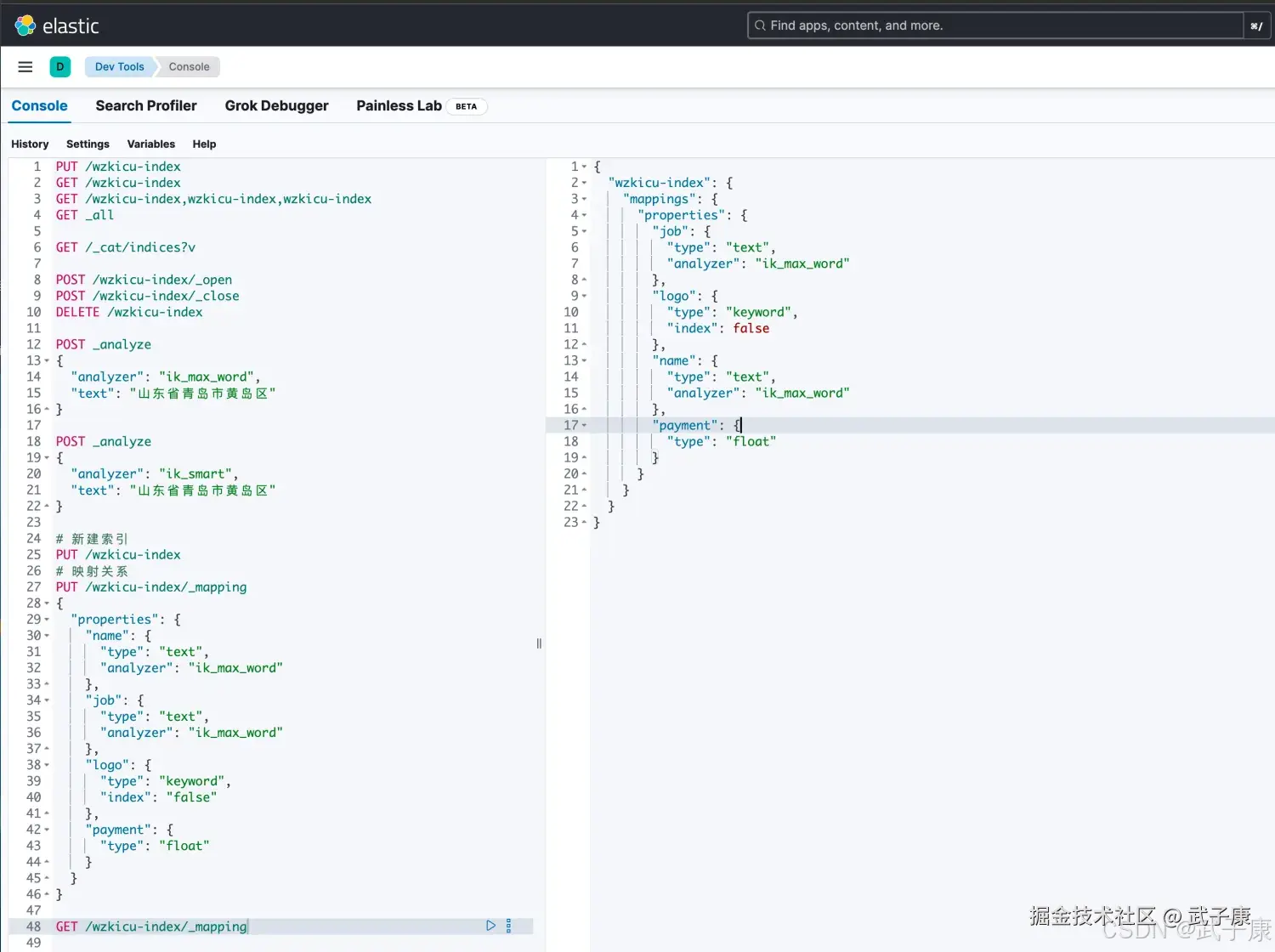
所有映射关系
语法:
shell
GET _mapping
GET _all/_mapping执行结果如下图所示: 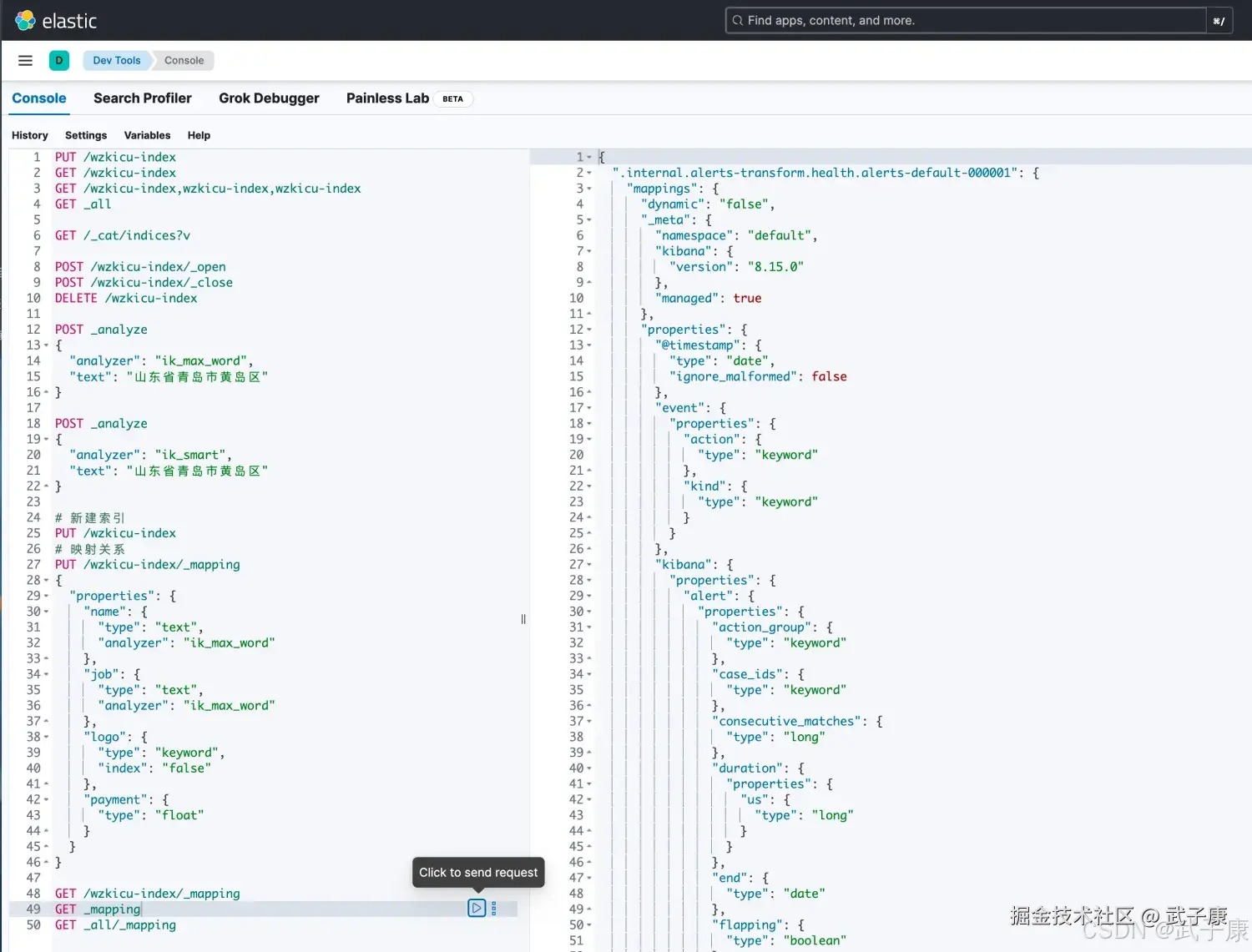
修改映射关系
shell
PUT /索引库名/_mapping
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
}
}
}主要注意的是:修改映射只能是增加字段的操作,其他的更改只能删除索引重新建立索引来实现。
一次性建立索引与映射
实际上创建索引和映射是可以放到一起来做的, 在创建索引的同时,直接指定映射。
shell
PUT /索引库名称
{
"settings":{
"索引库属性名":"索引库属性值"
},
"mappings":{
"properties":{
"字段名":{
"映射属性名":"映射属性值"
}
}
}
}案例:
shell
PUT /wzk-index
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}执行结果如下图所示: 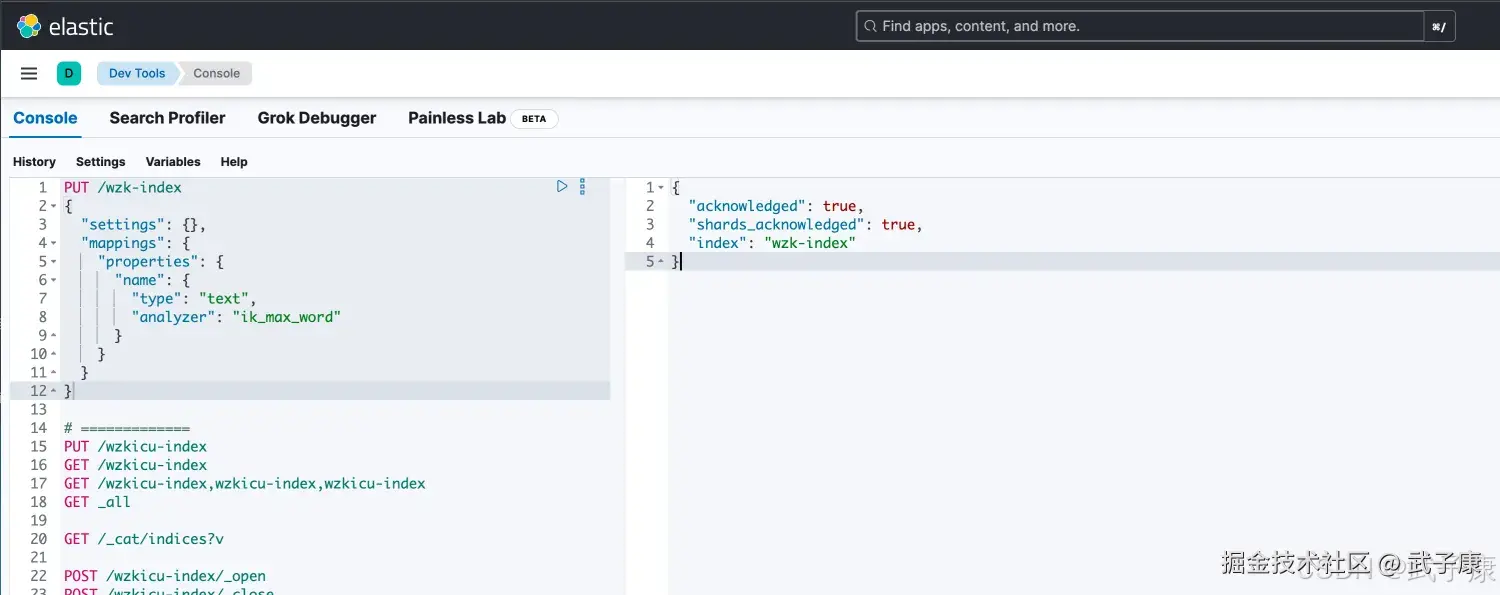
文档增删改查与局部更新
文档,即索引库中的数据,会根据规则创建索引,将用来搜索,可以类比做数据库中的一行数据。
新增文档
新增文档时,涉及到的ID的创建方式,手动指定或者自动生成。
手动新增
shell
POST /索引名称/_doc/{id}示例:
shell
POST /wzkicu-index/_doc/1
{"name" : "百度",
"job" : "小度用户运营经理",
"payment" : "30000",
"logo" : "https://profile-avatar.csdnimg.cn/755ff10be62f4e7081bc36028fa9eafe_w776341482.jpg!1"
}
POST /wzkicu-index/_doc/2
{"name" : "百度",
"job" : " 百度用户运营经理",
"payment" : "50000",
"logo" : "https://profile-avatar.csdnimg.cn/755ff10be62f4e7081bc36028fa9eafe_w776341482.jpg!1"
}执行的结果如下图所示: 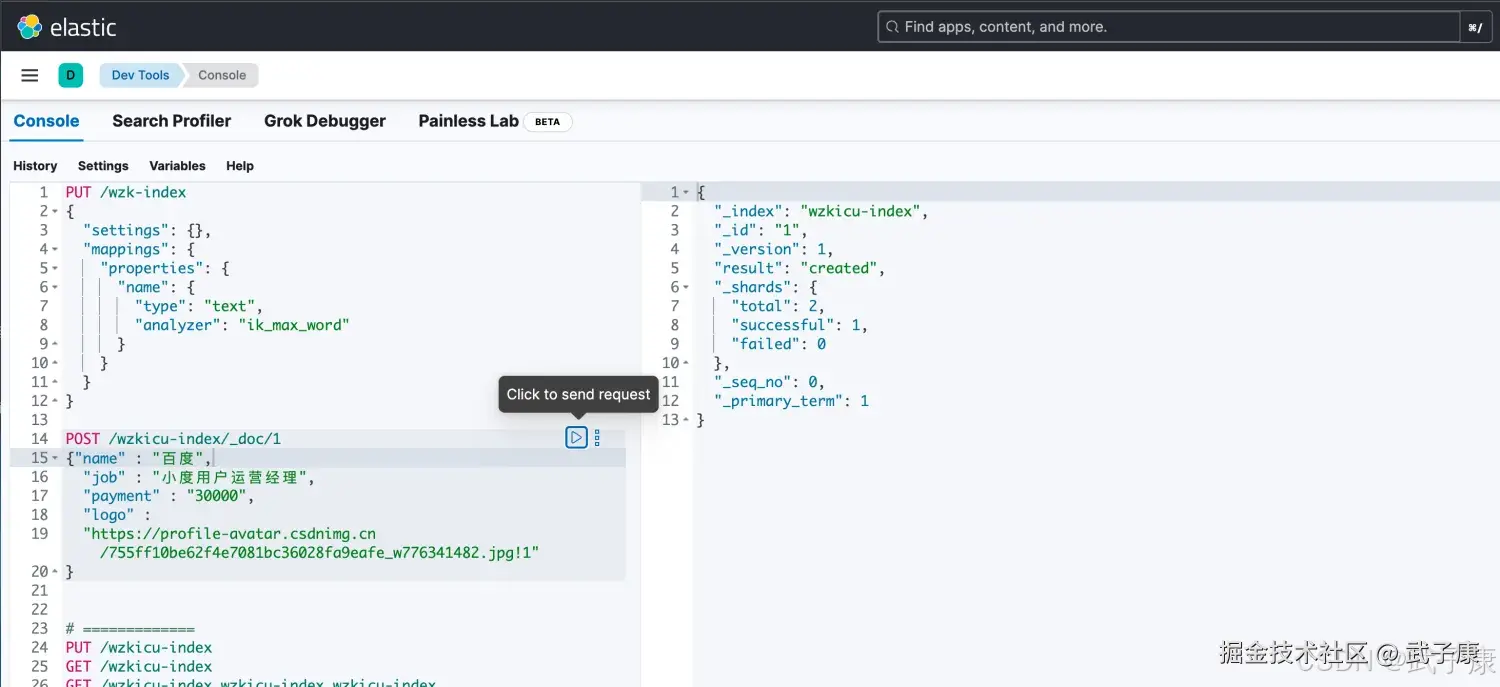
自动新增
语法:
shell
POST /索引名称/_doc
{
"field": "value"
}示例:
shell
POST /wzkicu-index/_doc
{
"name" : "百度",
"job" : " 百度测试",
"payment" : "20000",
"logo" : "https://profile-avatar.csdnimg.cn/755ff10be62f4e7081bc36028fa9eafe_w776341482.jpg!1"
}执行结果如下图所示: 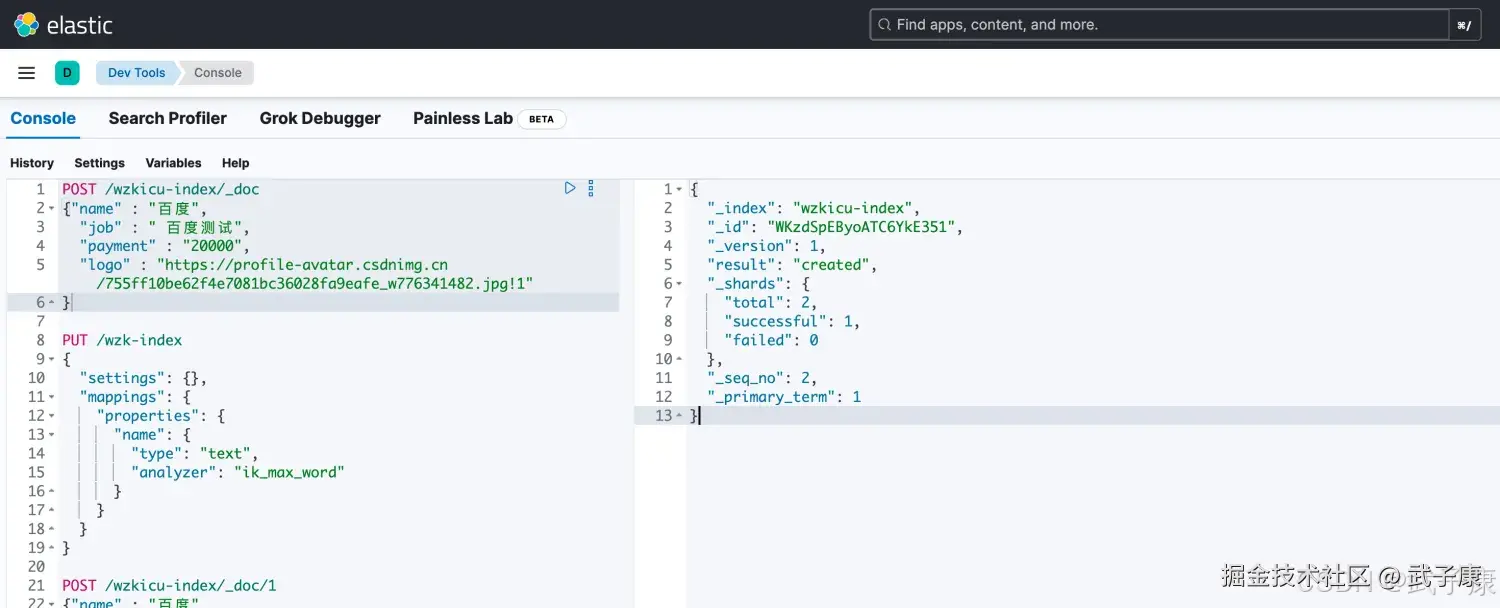
查询文档
单个文档
语法:
shell
GET /索引名称/_doc/{id}示例:
shell
GET /wzkicu-index/_doc/1执行结果如下图所示: 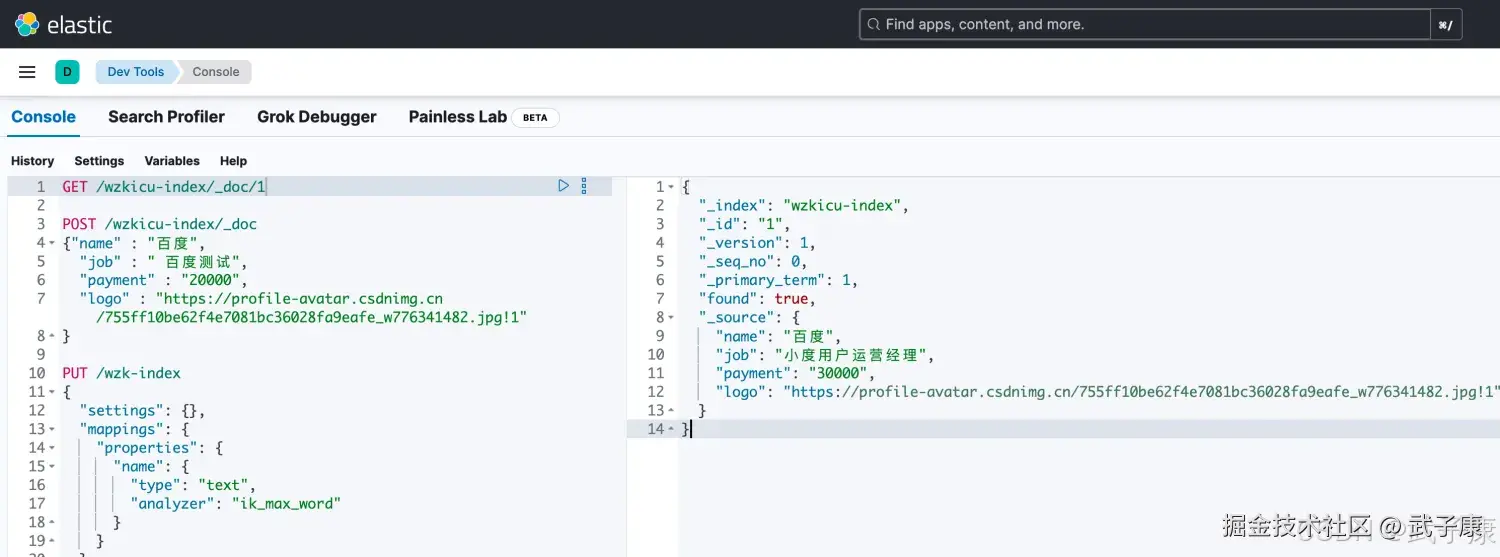 对返回的结果的格式解释如下:
对返回的结果的格式解释如下: 
所有文档
语法:
shell
POST /索引名称/_search示例:
shell
POST /wzkicu-index/_search
{
"query":{
"match_all": {
}
}
}测试运行的结果如下图所示: 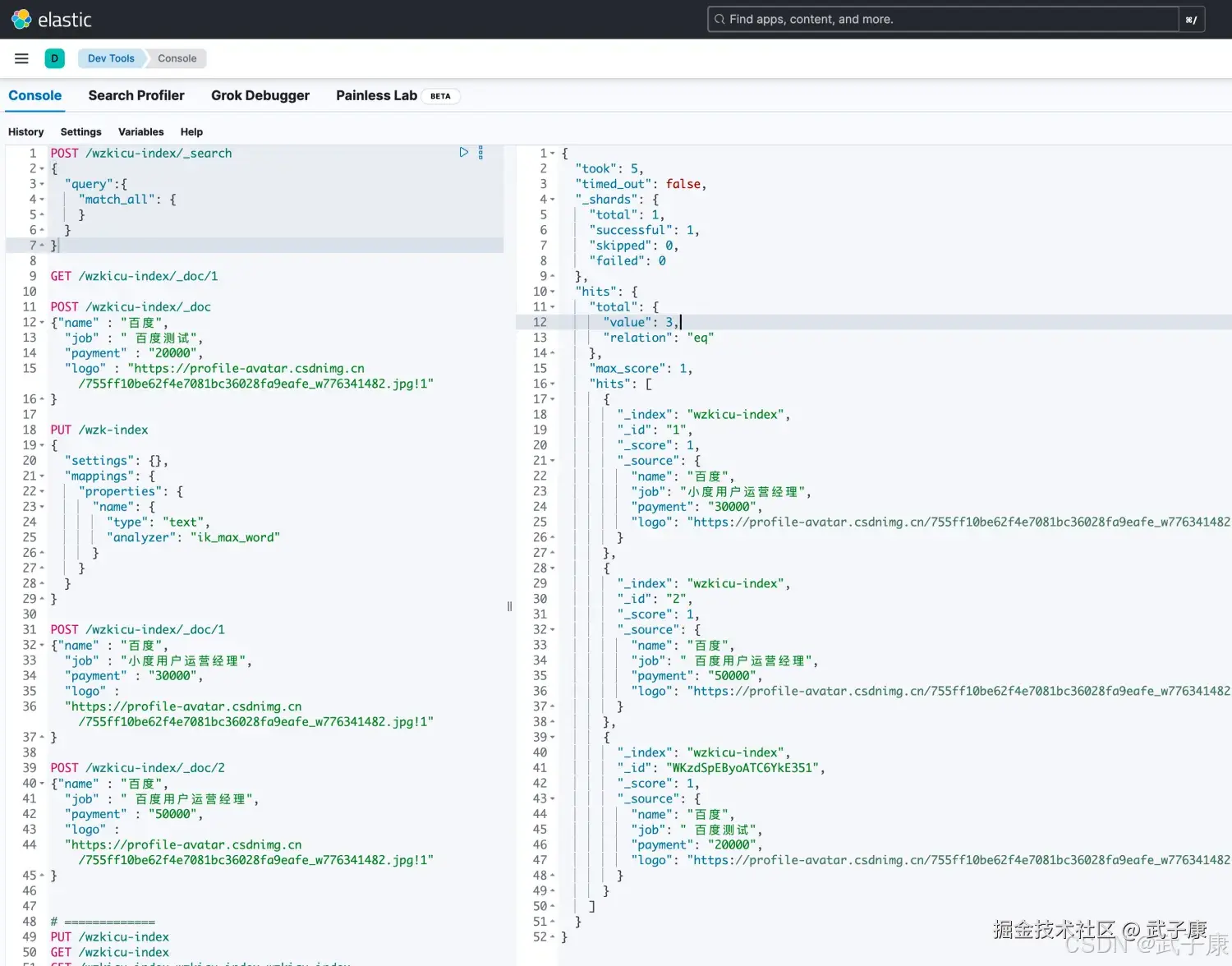
定制返回字段
很多业务场景下,我们不需要返回这么多字段: 示例:
shell
GET /wzkicu-index/_doc/1?_source=name,job执行结果如下图所示,可以看到根据需要,只返回了 name 和 job: 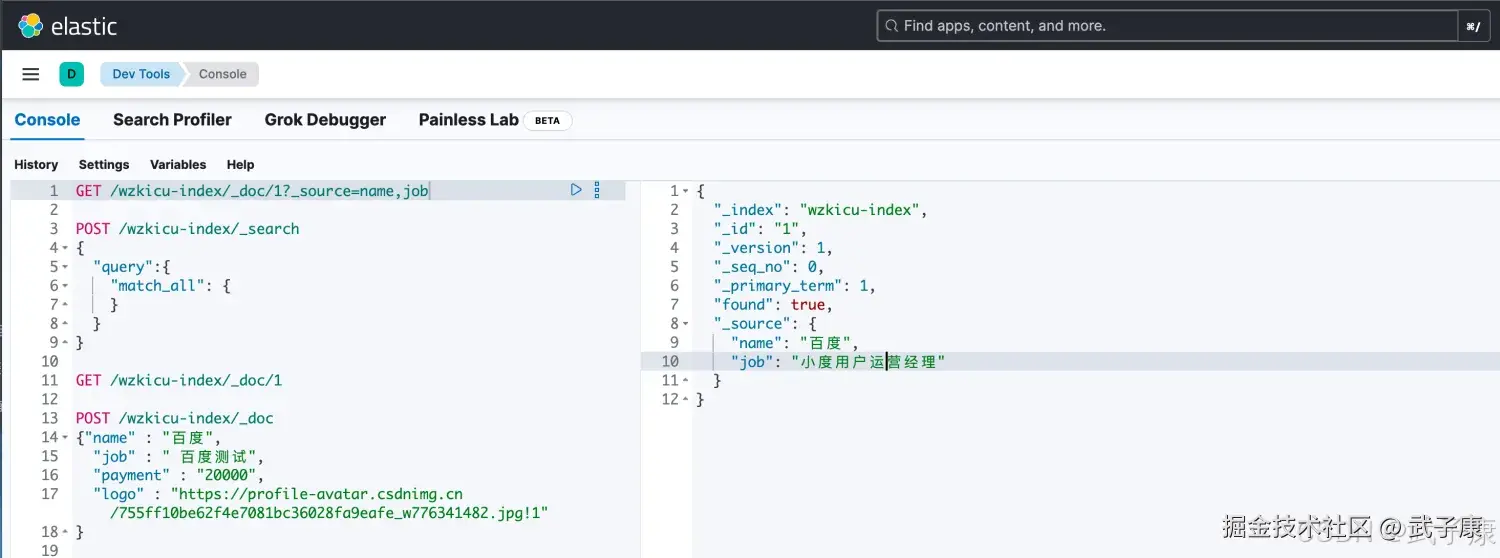
更新文档
全部更新
新增方式相同,只不过新增是POST,而更新是PUT,而且修改必须指定ID才可以。
- id对应的文档存在,则修改
- id对应的文档不存在,则新增
shell
PUT /wzkicu-index/_doc/5
{
"name" : "百度",
"job" : " 百度测试",
"payment" : "20000",
"logo" : "https://profile-avatar.csdnimg.cn/755ff10be62f4e7081bc36028fa9eafe_w776341482.jpg!1"
}第一次执行,可以看到右侧是:created: 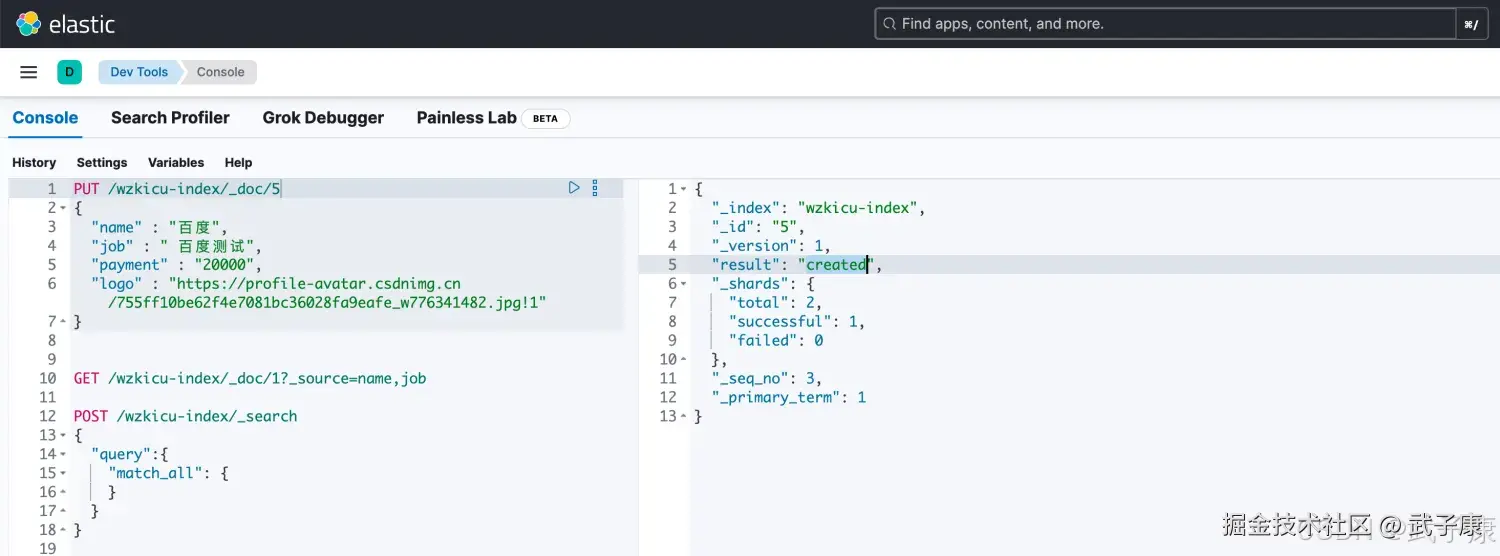 再执行一次,可以看到右侧是:updated:
再执行一次,可以看到右侧是:updated: 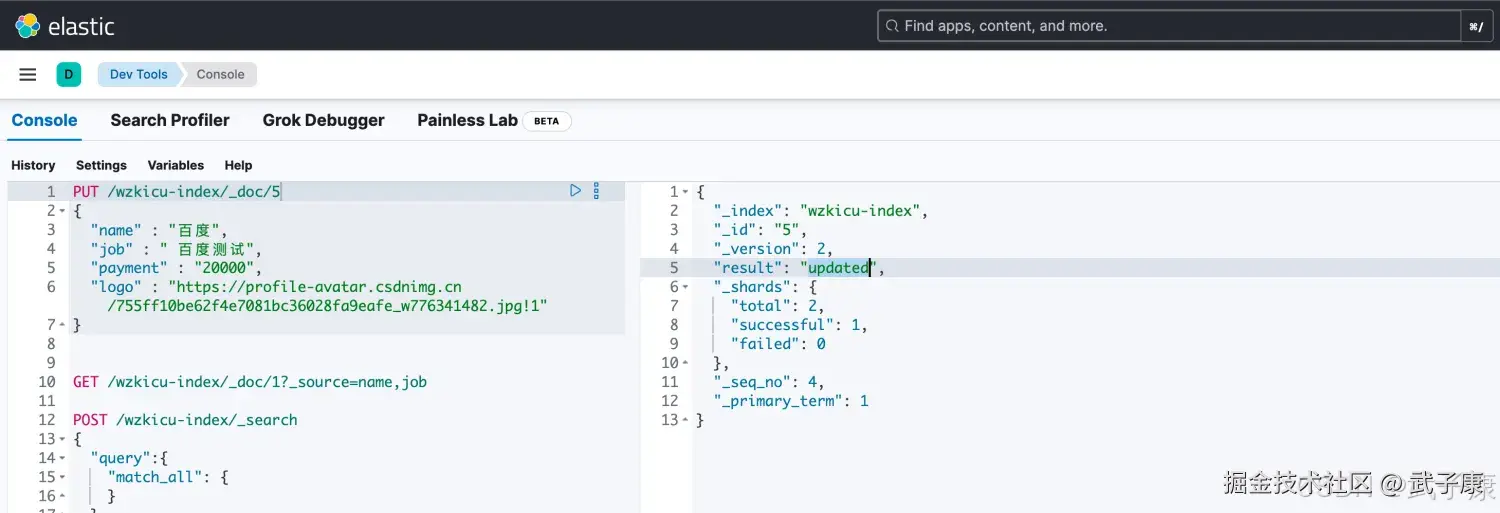
局部更新
ES可以使用PUT或者POST进行更新,如果指定ID存在,则执行更新操作。 注意:
- ES执行更新操作的时候,ES是先将旧的标记为删除,再添加新的文档。
- 旧的文档不会立即消失,但是你也无法访问,ES会在添加更多数据的时候,后台清理已经标记为删除的数据。 全部更新是直接把之前的老数据,标记为删除状态,然后再添加一条更新的数据(PUT或者POST),局部更新,只是修改某个字段(POST)。
shell
POST /索引名/_update/{id}
{
"doc":{
"field":"value"
}
}示例:
shell
POST /wzkicu-index/_update/2
{
"doc":{
"name":"淘宝"
}
}执行的结果如下图所示: 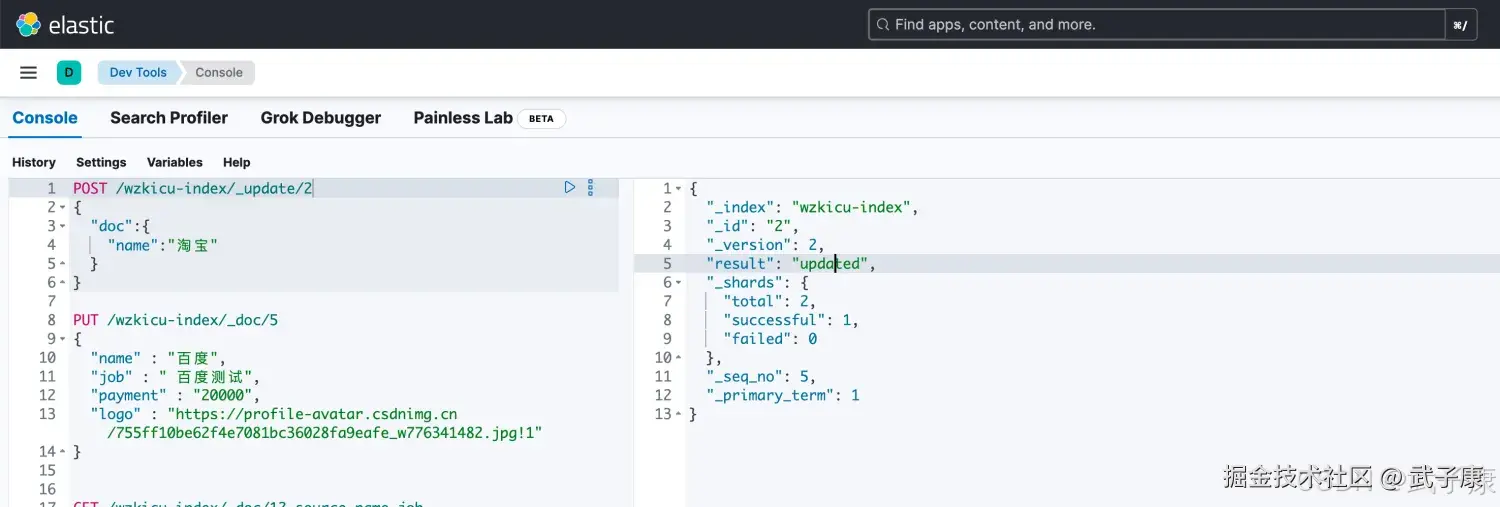
删除文档
ID删除 语法:
shell
DELETE /索引名/_doc/{id}示例
shell
DELETE /wzkicu-index/_doc/3执行结果如下图所示: 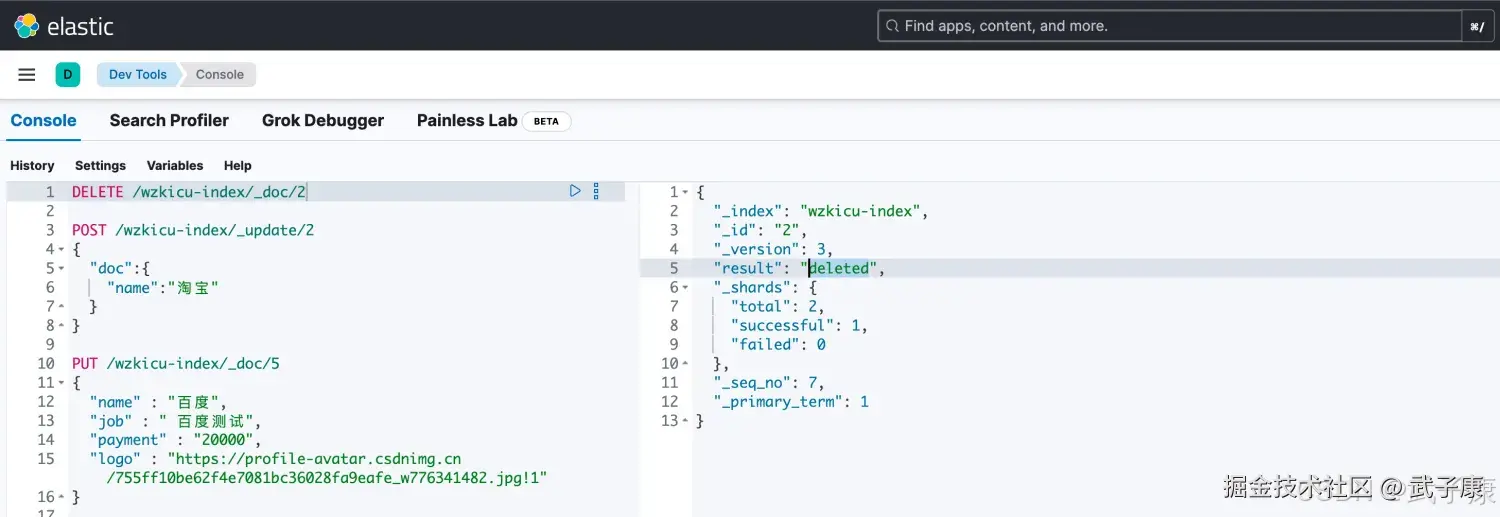
条件删除
语法:
shell
POST /索引名/_delete_by_query
{
"query": {
"match": {
"字段名": "搜索关键字"
}
}
}示例:
shell
# 查询一下 包含百度关键字的
POST /wzkicu-index/_search
{
"query":{
"match":{
"name":"百度"
}
}
}
# 删除name字段为百度的doc
POST /wzkicu-index/_delete_by_query
{
"query":{
"match":{
"name":"百度"
}
}
}执行结果如下图所示: 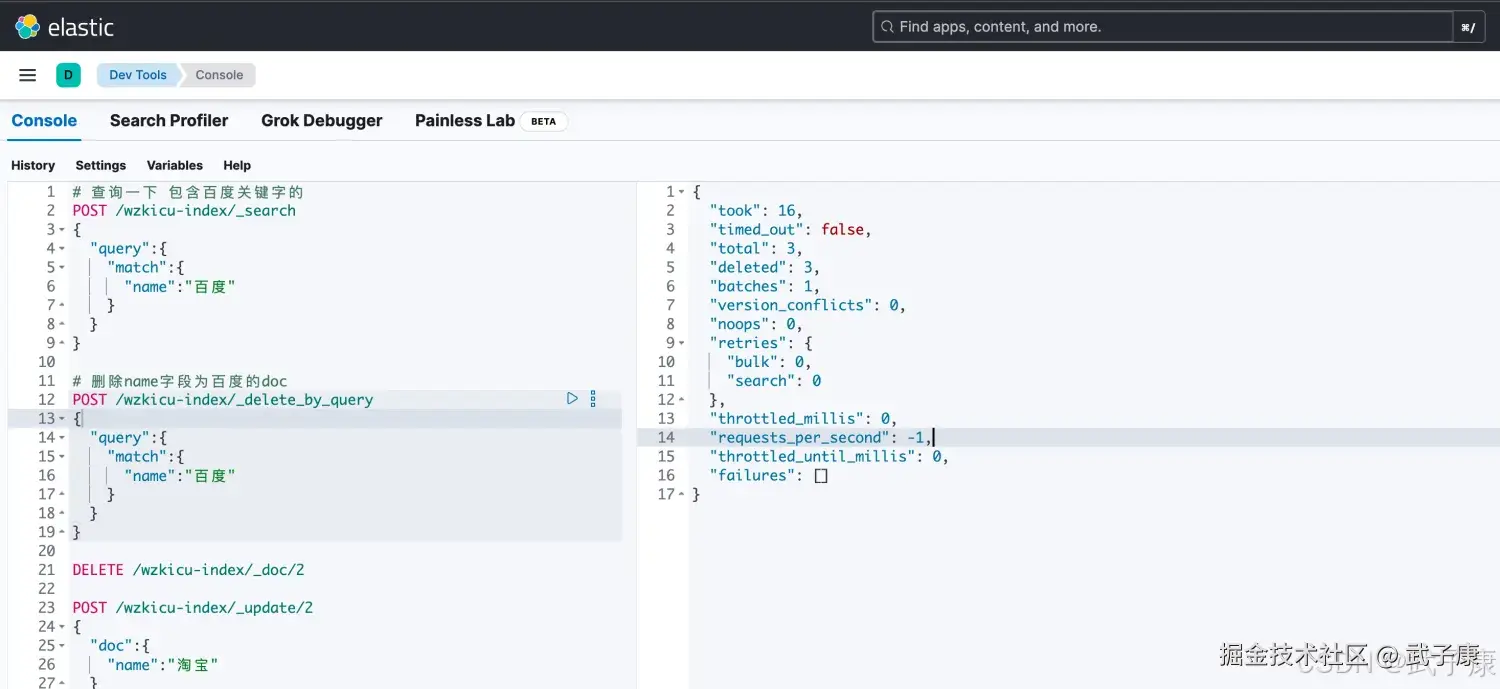
删除所有
shell
POST /索引名/_delete_by_query
{
"query": {
"match_all": {}
}
}错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| PUT 索引/_mapping 报错:mapper_parsing_exception | 已存在字段类型与本次提交的 type / analyzer 不兼容 | 查看索引当前 _mapping,比对字段类型与新配置 |
| ES 中映射基本不可改类型,只能新增字段或重建索引 + 重建数据 | 修改已有字段类型后,旧数据查询行为"怪异"或结果不稳定 | 映射没真正变(老 segment 仍按旧映射),只是你以为改成功了 |
| _mapping 对比前后,结合 _cat/indices 查看 segment 情况 | 坚持"映射设计好再建索引",需要调整时走"新索引 + reindex"方案 | 查询命中数为 0,但确认数据在 _source 中存在 |
| 字段 index:false 或被映射为 keyword,而查询使用了分词匹配 | 看 _mapping 中该字段的 type 和 index 配置 | 需要全文检索就用 text + analyzer;只做精确匹配用 keyword |
| keyword 字段做模糊搜索 / 中文搜索效果极差 | keyword 不分词,只存整值;中文必须配合分词器使用 text 类型 | 观察 mapping:字段是否仅有 keyword 而无 text 子字段 |
| 常用模式:text + keyword 多字段;查询/聚合分别打到对应字段 | POST 索引/_update/id 报版本冲突或覆盖了不该改的字段 | 误把"局部更新"和"全量覆盖"混用;或高并发下版本冲突 |
| 检查请求是否是 _update + doc,以及响应中的 _version 变化 | 局部更新统一用 _update + doc;高并发场景考虑乐观锁或重试策略 | 使用 DELETE_BY_QUERY 删除后,磁盘空间短期内几乎没变化 |
| ES 先"标记删除",等待 segment merge 才真正回收空间 | _cat/segments 查看段数,监控 merge 情况 | 属于正常行为,等待后台合并;空间压力大时考虑 force merge |
| 查询 _source 返回字段过大,接口延迟与网络开销明显 | 默认返回完整 _source,包含所有字段 | 检查响应体大小与字段数量 |
| 使用 ?_source=字段1,字段2 限制返回字段,或结合 store:true 优化 | 全量更新 PUT 索引/_doc/id 后发现"新增了一条数据" | 之前该 id 不存在,ES 将其视为新文档创建 |
| 查看返回 JSON 中的 result 字段(created 或 updated) | 确认业务语义:需要"仅当存在才更新"时,需先 GET 或使用脚本更新条件 | 删除后,查询仍能看见"似乎被删掉的数据" |
| 查询命中了还未 refresh 的 segment 视图 | 查看响应中 took、deleted,并尝试手动 POST 索引/_refresh | 依赖近实时特性即可;强一致要求场景下,删除后显式执行 _refresh |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解