知识图谱在大模型时代的价值:原理、应用与可商业化方向
大型语言模型(LLM)的优势在于理解、生成与抽象,但其弱点同样明显:事实不稳定、逻辑链条不可控、解释性弱、无法直接利用企业内部结构化知识。知识图谱(Knowledge Graph, KG)恰好补足这些短板。
本文从技术逻辑出发,系统梳理知识图谱在 LLM 中的作用、可商业化的产品方向,以及企业如何将图谱真正用到大模型问答中。
1. 为什么 LLM 仍然需要知识图谱?
LLM 强,但它"知道"的内容本质是:
- 压缩后的统计相关性
- 概率生成
- 训练时的混合语料经验
它无法做到:
- 精准、实时、可验证的事实输出
- 多跳、关系明确的可解释推理
- 企业场景需要的可控回答
- 与结构化系统(数据库/图谱)一致性保持
知识图谱补的正是这些痛点。
2. 知识图谱能解决 LLM 的哪些根本性问题?
2.1 提供稳定的事实约束(减少幻觉)
LLM 的生成靠"语言流畅度",不是"事实正确性"。
图谱提供:
- 实体
- 属性
- 关系
- 约束
- 标准化命名
LLM 生成回答时强制对齐图谱 → 幻觉显著下降。
2.2 提供结构化推理骨架(LLM 没这个能力)
图谱天然包含:
- 多跳关系
- 拓扑结构
- 依赖链条
- 上下位分类
LLM 擅长解释,但弱于执行。
图谱擅长执行,但不会说人话。
组合后你得到:
- 可解释推理
- 供应链路径分析
- 风险传播链
- 法规条款交叉引用
- 案件因果链条
- 技术依赖图(如 Java 技术栈)
这是高商业价值场景。
2.3 与企业内部系统对齐(LLM 天生做不到)
图谱可以覆盖:
- 产品知识
- 文档结构
- 技术体系
- 操作流程
- 业务规则
- 部门权限
- 历史事件
- 人员与资产关系
LLM 的任务:
- 将用户问题映射到图谱节点/路径
- 从图谱检索结果
- 生成自然语言回答
这是"企业级检索增强"(KG-RAG)。
3. 图谱 + LLM 可衍生的商业产品
下面是你真正可以赚钱或落地的方向,而不是理想化概念。
3.1 企业内部智能问答(文档 → 图谱 → LLM)
应用:
- 技术文档问答(Java、运维、架构)
- 产品知识问答
- 客服问答
- 内部政策问答
价值:
- 高准确率
- 可审计
- 减少人工解释成本
这是图谱商业化最快的路径。
3.2 风险识别与关联推理产品(高价值场景)
例如:
- 风险事件 → 供应链依赖链分析
- 客户行为 → 欺诈链条
- 漏洞依赖图谱 → 受影响模块扫描
- 监管条款 → 违规关联推断
- 医疗路径 → 风险预测
核心能力:图谱给结构,LLM 给推理解释。
3.3 技术领域知识中台(如 Java 技术图谱)
例如:
- Java 类库关系图谱
- 框架依赖图谱
- 代码语义图谱
- Bug 传播链
- 性能瓶颈链路推断
衍生产品:
- 智能代码诊断
- 自动错误解释
- 性能优化建议
- 自动化架构文档生成
3.4 合规 / 财税 / 法律问答系统(极高商业价值)
规则天然结构化 → 适合图谱
答案必须正确 → 适合 LLM
组合产品包括:
- 智能法规咨询
- 条款对齐系统
- 合规自动检查
- 政策差异对照
这是能卖给 B 端的重产品。
3.5 智能决策辅助系统
场景:
- 运营决策
- 产品方案推荐
- 风控策略优化
- 营销投放策略
- 企业流程优化
图谱提供规则
LLM 生成策略解释
这是"智能咨询师"类应用的底座。
4. 用户提问如何"融入图谱"?
关键不是"能不能",而是"怎么做"。
典型流程如下:
4.1 步骤 1:LLM 解析用户意图
将自然语言解析为:
- 实体(classes, methods, bugs, frameworks...)
- 主题
- 关系
- 任务类型(查知识/查因果/查路径/查规则)
4.2 步骤 2:映射到图谱节点或关系
例如:
输入:
"Spring 循环依赖是怎么解决的?"
LLM → 提取实体:
- Spring
- BeanFactory
- Circular Dependency
- three-level cache
映射到图谱中对应节点。
4.3 步骤 3:从图谱检索事实或路径
- 查属性
- 查依赖链
- 查上下位分类
- 查原因链条
- 查规则
4.4 步骤 4:LLM 重写为自然语言回答
模型负责:
- 解释
- 总结
- 补充背景
- 用例子讲清楚
但必须基于图谱检索的事实。
5. 结语:图谱不是点缀,而是 LLM 商业化的基础设施
一句话总结核心价值:
图谱提供结构化世界观,LLM 提供语言与推理能力。
二者结合,才能做出真正可商用、高可信度的智能系统。
如果你准备做企业内部智能问答(尤其是 Java/技术文档类),图谱不只是"可以融合",而是必须用。
rag 开源项目 https://github.com/HKUDS/LightRAG?tab=readme-ov-file
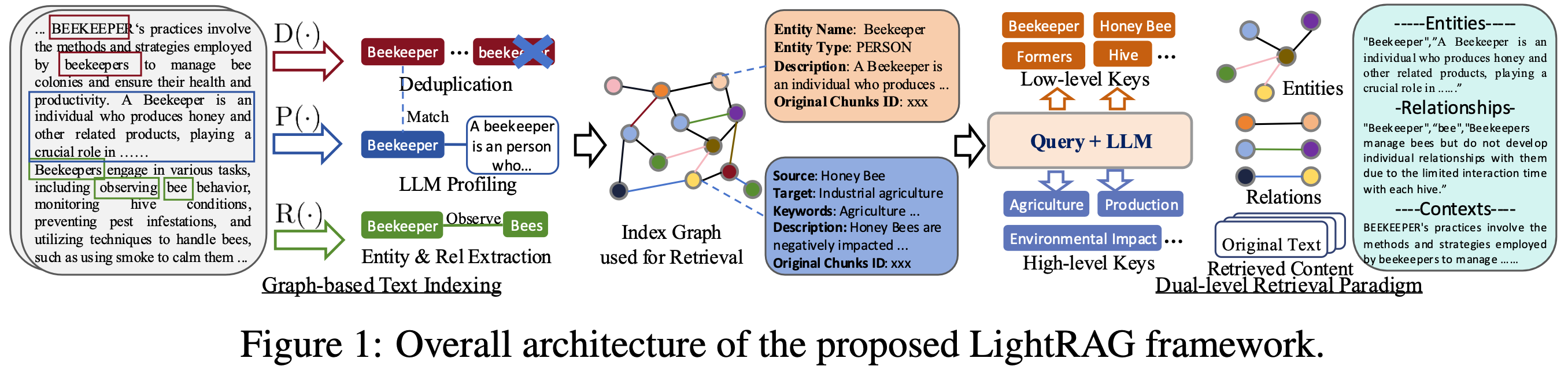
这张图你要的不是"解释",而是"拆穿它到底在干什么、结构在哪、你有没有漏掉关键机制"。
我就直接来,不铺垫。
一句话总结:
这张图展示了 LightRAG 的完整架构流程 ,本质上就是:
把原文本拆成实体、关系、上下文三层索引 → 构建图结构 → 让 LLM 用"图检索 + 文本检索"双通道查找信息 → 输出更准确的答案。
换句话说,它不是在"增强 RAG",它是在 给 LLM 建一个轻量知识图谱 + 两级检索系统。
拆成四段,你真正应该看到的东西:
① 左侧:文本预处理 → 实体和关系抽取(D, P, R 三步)
图左边你看到高亮的 "Beekeeper", "beekeepers", "bee", "observing" ......
这块做了三件事:
D(·) = Deduplication
把所有写法不同但语义一样的实体统一成一个,比如:
- Beekeeper
- beekeepers
- beekeper(错拼)
统统视为同一个节点。
你要注意:这是为了避免知识图谱里出现重复节点,让检索精确。
P(·) = Profiling
LLM 给实体补上"类型 + 描述"。
例如:
Beekeeper →
- Type: PERSON
- Description: A beekeeper is a person who produces honey...
本质上:LLM 在为每个节点写简介,方便后续检索。
R(·) = Relation extraction
提取关系:
- Beekeeper --- observe → Bees
- Beekeeper --- manage → Hive
这些关系最后变成图结构的边。
这一步是整个系统的灵魂:它决定你的知识能否结构化而不是一锅粥。
② 中间:构建 Index Graph(核心图索引)
所有实体 + 关系 + 文本片段 → 一个轻量知识图谱。
注意:
这不是 Neo4j 那种大图。
它只是一个 局部、稀疏、专为检索优化的小图。
图中的小圈圈 + 彩色边就是它的可视化示意。
意义:
传统 RAG 做向量检索只能找"相似",但 LightRAG 的图可以找"关联":
- 从 Beekeeper 找到 Bee
- 从 Bee 找到 Hive
- 再从 Hive 找到相关文本 chunk
这是传统 RAG 做不到的。
③ 右侧:Dual-level Retrieval(双层检索)
LightRAG 检索是"两套引擎同时跑":
Low-level Keys(底层检索)
直接根据实体名、关系名查图:
比如用户问:
"养蜂人如何管理蜂箱?"
系统会先查图中的键:
- Beekeeper
- manage
- Hive
拉到它们的上下文。
High-level Keys(高层语义)
这是 LLM 生成的抽象关键词:
例如:
- Agriculture
- Production
- Environmental Impact
这些不一定出现在原文中,但 LLM 根据 query 推断出来。
然后用这些高层关键词再去查图或查原文本 chunk。
目的很明确:
图索引找"结构化关联",
文本向量查语义相关,
两者结合提高 recall(召回)与 precision(精度)。
④ 最右侧:最终返回内容
最终检索结果包含:
- Entities(实体介绍)
- Relationships(关系)
- Context(原文片段)
LLM 用这些材料来生成答案。
关键点:
这不是把 vector store 变强,而是给 LLM 提供"结构化知识 + 文本知识"的组合输入。
你可能没看懂但必须注意的 3 件事
① LightRAG 是"轻量 KG + RAG",不是单纯升级版 RAG
如果你只看它像"提取实体关系 → 建图",那你就只理解了 60%。
真正的价值:
它让 LLM 具备 沿着图谱推理的能力(例如二跳查询:A→B→C),而不是只靠 embedding 搜索词向量。
② 它是为了补齐"大模型的弱点"
模型在以下场景都会翻车:
- 长链条逻辑
- 复杂事实关系
- 概念之间的层级结构
- 不同段落的隐式联系
LightRAG 的知识图谱本质上是 让 LLM 获得一个外置的符号推理辅助工具。
③ 这玩意适合"小领域、高精度场景",不适合大规模通用知识
比如:
- 法律法规
- 产品文档
- 工业规范
- 技术 API 文档
- 科技论文
- 金融监管文本
不适合用来存百科类大知识库。