一、基础原理
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(归约)是函数式编程中的核心概念。在大模型训练中,MapReduce被广泛应用于数据处理、特征提取和分布式训练。
大模型 MapReduce 是将分布式计算经典的 MapReduce 范式与大模型能力结合的技术架构,核心解决大模型处理超长文本 / 海量任务时的算力瓶颈、上下文窗口限制、任务并行效率低 三大问题。
1. 核心思想
- **分而治之:**将一个无法单次放入大模型上下文窗口的超大任务(如万字文档总结、百万级文本分类)拆解为多个可独立处理的子任务(Map 阶段)。
- **并行处理:**利用本地大模型对所有子任务并行推理,避免单任务占用模型过久。
- **结果聚合:**将所有子任务的输出整合为最终结果(Reduce 阶段),还原对原任务的完整响应。
2. 与传统 MapReduce 的差异
| 维度 | 传统 MapReduce(Hadoop) | 大模型 MapReduce |
|---|---|---|
| 处理对象 | 结构化 / 半结构化数据 | 自然语言文本、复杂语义任务 |
| 核心算力 | 集群 CPU / 磁盘 IO | 本地 GPU/CPU(大模型推理) |
| 处理目标 | 数据计算 / 统计 | 语义理解 / 生成 / 分析 |
| 拆分依据 | 数据分片(按大小 / 行数) | 语义完整性(句子 / 段落 / 主题) |
| 聚合逻辑 | 数值汇总 / 归并 | 语义融合 / 总结 / 逻辑整合 |
二、传统 Hadoop MapReduce 简介
1. 核心架构
Hadoop MapReduce是Apache Hadoop的核心组件之一,是一个批处理计算框架,专门设计用于处理海量数据(TB/PB级别)。
Hadoop MapReduce架构:
- JobTracker(主节点) - 调度作业,分配任务
- TaskTracker(从节点) - 执行Map/Reduce任务
- HDFS(分布式文件系统) - 存储输入输出数据
- 数据本地化优化 - 计算靠近数据存储
2. 主要特点
- 容错性强:任务失败自动重试
- 高扩展性:支持数千节点集群
- 数据本地性:计算靠近数据,减少网络传输
- 批处理:适合离线大规模数据处理
- 磁盘密集型:中间结果写入磁盘
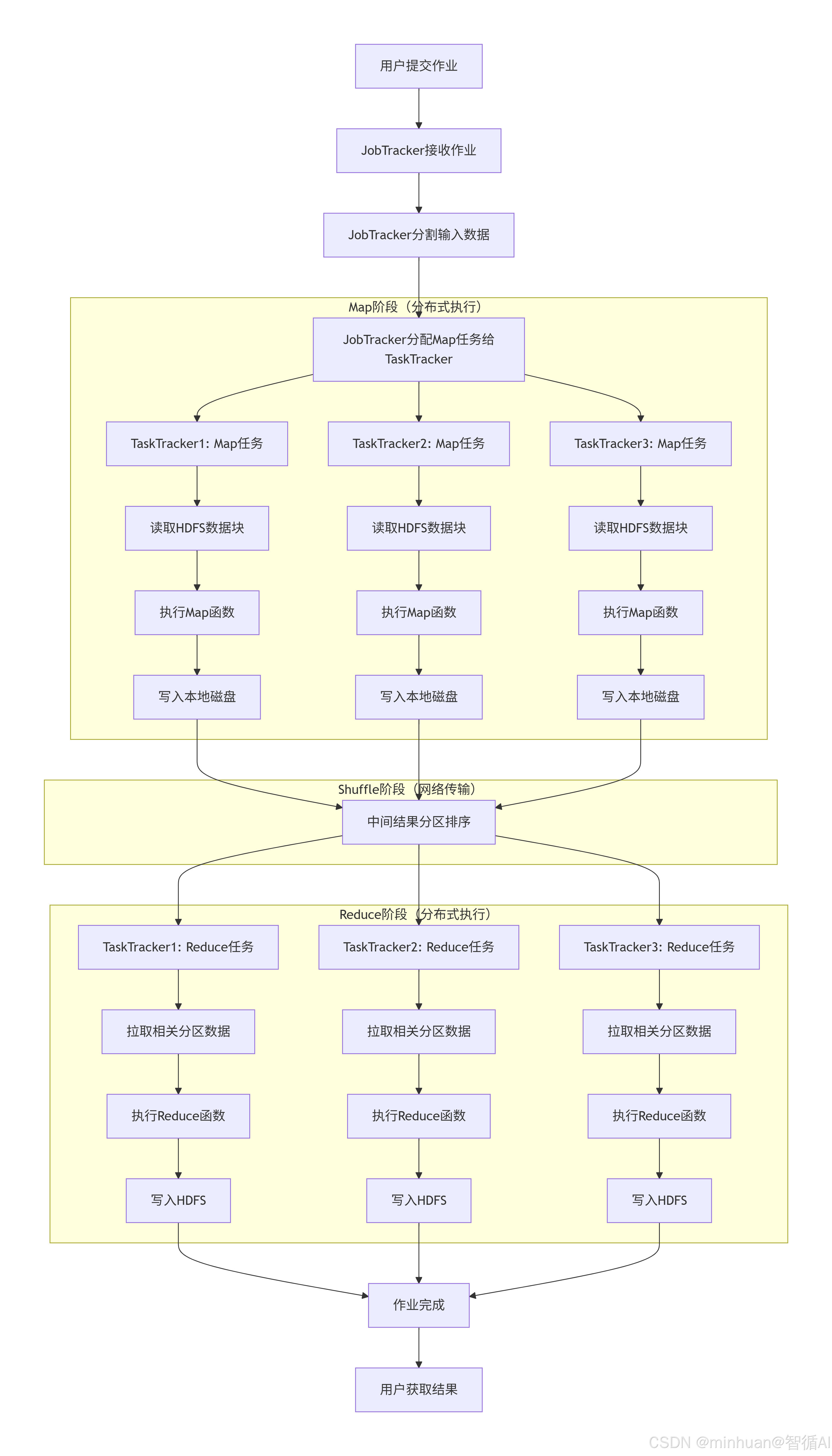
3. Hadoop MapReduce流程图
Hadoop MapReduce的流程包括:
- InputFormat读取数据并分片,
- Map任务处理,
- Shuffle(包括分区、排序、合并),
- Reduce任务处理,最后输出。
4. 优势与局限性
4.1 优势:
- 容错性:自动处理节点故障,任务重新调度
- 扩展性:支持数千节点集群
- 处理能力:专为PB级数据设计
- 生态丰富:集成HDFS、YARN、Hive等
- 成本低:可运行在廉价硬件上
4.2 局限性:
- 实时性差:批处理模式,延迟高(分钟到小时)
- 磁盘IO密集:中间结果写入磁盘,速度慢
- 编程复杂:需要实现Map、Reduce类
- 内存限制:不适合迭代计算(如机器学习)
- 资源管理:YARN配置复杂
5. 简单示例
本示例实现一个基于传统的Hadoop MapReduce风格的词频统计,注重以下这些重要的特性:
- 基于Hadoop框架的,通常运行在HDFS(分布式文件系统)上,可以处理大规模数据集。
- Map和Reduce阶段是分开的,中间有Shuffle阶段,将Map输出的键值对按照键进行分组,然后发送给Reduce任务。
- 具有良好的容错性,通过将中间结果写入磁盘来防止节点失败。
- 但是,Hadoop MapReduce的每一步都需要读写磁盘,因此速度相对较慢。
python
"""
中文词频统计MapReduce实现
理论基础:词频统计是MapReduce的经典案例
特点:使用专业分词工具,避免整句输出
"""
import re
from collections import defaultdict
import jieba # 专业中文分词库
import jieba.posseg as pseg # 带词性标注的分词
class ChineseWordCountMapReduce:
"""
中文词频统计MapReduce实现类
理论基础:分而治之的并行处理模式
"""
def __init__(self, use_professional_tokenizer=True):
"""
初始化MapReduce处理器
参数:
use_professional_tokenizer: 是否使用专业分词器
理论:专业分词器能更好处理中文歧义和未登录词
"""
self.use_professional_tokenizer = use_professional_tokenizer
# 初始化专业分词器配置
if use_professional_tokenizer:
self._init_jieba()
def _init_jieba(self):
"""初始化jieba分词器"""
# 理论:中文分词需要处理多种情况
# 1. 加载用户词典(处理领域专有词汇)
# 2. 调整分词模式(平衡精度与速度)
# 示例:添加自定义词典
custom_words = [
"自然语言处理", # 专业术语
"人工智能", # 专业术语
"深度学习", # 专业术语
"大语言模型", # 专业术语
"机器学习" # 专业术语
]
for word in custom_words:
jieba.add_word(word, freq=1000) # 设置较高频率,确保切分
# 设置停用词(高频但信息量低的词)
self.stop_words = set([
"的", "了", "在", "是", "我", "有", "和", "就",
"不", "人", "都", "一", "一个", "上", "也", "很",
"到", "说", "要", "去", "你", "会", "着", "没有",
"看", "好", "自己", "这"
])
def map_function(self, line):
"""
Map函数:将文本行转换为(词, 1)键值对
理论:
输入:一行文本
处理:分词、过滤、转换
输出:中间键值对列表
"""
# 清理文本:去除标点、数字、英文等
cleaned_text = self._clean_chinese_text(line)
if not cleaned_text:
return [] # 空文本直接返回
# 根据配置选择分词方式
if self.use_professional_tokenizer:
words = self._professional_tokenize(cleaned_text)
else:
words = self._simple_tokenize(cleaned_text)
# 过滤停用词(如果使用专业分词器)
if self.use_professional_tokenizer:
words = [w for w in words if w not in self.stop_words]
# 生成Map输出:每个词计数为1
# 理论:输出为(词, 1)形式,便于后续Reduce汇总
return [(word, 1) for word in words if word.strip()]
def _clean_chinese_text(self, text):
"""
清理中文文本
理论:
中文文本预处理包括:
1. 去除非中文字符(保留必要标点)
2. 统一全半角字符
3. 处理空白字符
"""
# 仅保留中文和空格
# Unicode范围参考:https://unicode-table.com/cn/blocks/
chinese_pattern = re.compile(
r'[^\u4e00-\u9fff\s]'
# r'[^\u4e00-\u9fff\u3000-\u303f\uff00-\uffef\s]' # 包含中文标点
)
cleaned = chinese_pattern.sub(' ', text)
# 合并多个空格
cleaned = re.sub(r'\s+', ' ', cleaned)
return cleaned.strip()
def _simple_tokenize(self, text):
"""
简单分词:按字符分割
理论:
优点:简单快速,不会出错
缺点:丢失词语语义,统计粒度粗
适用场景:字频统计、初步分析
"""
# 按字符分割,过滤空白
return [char for char in text if char.strip() and char != ' ']
def _professional_tokenize(self, text):
"""
专业分词:使用jieba分词
理论:
优点:保留语义信息,统计更准确
缺点:需要词典支持,可能产生歧义
适用场景:词频统计、语义分析
"""
# 使用精确模式分词(适合文本分析)
words = jieba.lcut(text, cut_all=False)
# 可选:过滤词性(只保留名词、动词等实词)
# words_with_tag = pseg.cut(text)
# words = [word for word, flag in words_with_tag
# if flag.startswith(('n', 'v', 'a'))]
return words
def shuffle_function(self, map_results):
"""
Shuffle函数:按键分组
理论:
输入:所有Map任务的输出
处理:按key分组,相同key的value放入列表
输出:分组后的字典 {key: [values]}
"""
shuffle_dict = defaultdict(list)
for word, count in map_results:
shuffle_dict[word].append(count)
return shuffle_dict
def reduce_function(self, shuffle_dict):
"""
Reduce函数:汇总统计
理论:
输入:分组后的中间结果
处理:对每个key的所有value求和
输出:最终的词频统计结果
"""
reduce_results = []
for word, counts in shuffle_dict.items():
total_count = sum(counts)
reduce_results.append((word, total_count))
# 按频次降序排序
# 理论:排序是大数据分析的常见需求
return sorted(reduce_results, key=lambda x: x[1], reverse=True)
def run_mapreduce(self, data_lines):
"""
运行完整的MapReduce流程
理论:
模拟MapReduce的完整执行流程:
1. Map阶段:并行处理(这里简化为顺序)
2. Shuffle阶段:分组聚合
3. Reduce阶段:汇总输出
"""
print("开始MapReduce中文词频统计...")
print(f"使用分词器:{'专业分词器(jieba)' if self.use_professional_tokenizer else '简单字符分割'}")
print(f"处理文本行数:{len(data_lines)}")
# 阶段1:Map(在实际分布式系统中是并行的)
print("\n=== Map阶段 ===")
map_results = []
for i, line in enumerate(data_lines):
line_results = self.map_function(line)
map_results.extend(line_results)
if (i + 1) % 10 == 0: # 每10行输出一次进度
print(f" 已处理 {i + 1}/{len(data_lines)} 行,生成 {len(line_results)} 个中间结果")
print(f"Map阶段完成,共生成 {len(map_results)} 个中间键值对")
# 阶段2:Shuffle
print("\n=== Shuffle阶段 ===")
shuffle_dict = self.shuffle_function(map_results)
print(f"Shuffle完成,生成 {len(shuffle_dict)} 个不同的词")
# 阶段3:Reduce
print("\n=== Reduce阶段 ===")
final_results = self.reduce_function(shuffle_dict)
print(f"Reduce完成,输出 {len(final_results)} 个最终结果")
return final_results
def analyze_results(self, results, top_n=20):
"""
分析统计结果
理论:
词频分析可以提供:
1. 高频词:反映文本主题
2. 词频分布:齐普夫定律验证
3. 词汇多样性:词汇丰富度指标
"""
print("\n=== 结果分析 ===")
# 1. 输出Top N高频词
print(f"\nTop {top_n} 高频词:")
for i, (word, count) in enumerate(results[:top_n], 1):
print(f" {i:2d}. {word:8s} : {count:4d}")
# 2. 计算基本统计信息
total_words = sum(count for _, count in results)
unique_words = len(results)
print(f"\n统计摘要:")
print(f" 总词数: {total_words}")
print(f" 唯一词数: {unique_words}")
print(f" 词频平均值: {total_words/unique_words:.2f}")
# 3. 验证齐普夫定律(Zipf's Law)
# 理论:在自然语言中,词的频率与其排名成反比
if len(results) >= 10:
print(f"\n齐普夫定律验证(前10个词):")
for rank, (word, freq) in enumerate(results[:10], 1):
expected_ratio = results[0][1] / rank # 第一名频率/排名
actual_ratio = freq
print(f" 第{rank}名 '{word}': 实际频率={freq}, 预期≈{expected_ratio:.1f}")
# 测试示例
if __name__ == "__main__":
# 中文示例语料(更丰富的文本)
chinese_corpus = [
"自然语言处理是人工智能领域的重要分支,它研究计算机与人类语言之间的交互。",
"深度学习技术在自然语言处理中取得了显著进展,特别是大语言模型的出现。",
"中文自然语言处理面临独特挑战,包括分词、词性标注和语义理解等问题。",
"大语言模型需要海量数据进行训练,这些数据通常来自互联网和各种文本资源。",
"机器学习算法能够从数据中自动学习规律,而不需要显式的编程指令。",
"人工智能正在改变许多行业,包括医疗、金融、教育和娱乐等领域。",
"神经网络模拟人脑中神经元的连接方式,通过多层结构学习复杂特征。",
"预训练模型如BERT和GPT在多个自然语言处理任务上表现出色。",
"注意力机制让模型能够关注输入中的重要部分,提高处理长文本的能力。",
"Transformer架构已经成为自然语言处理的主流模型框架。",
"词向量将词语映射到高维空间,使得语义相似的词在空间中距离相近。",
"中文分词是中文信息处理的基础任务,准确性直接影响后续分析结果。",
"数据挖掘技术可以从大量数据中发现有价值的信息和模式。",
"云计算为大规模数据处理和模型训练提供了强大的计算资源。",
"边缘计算将计算任务推向数据源附近,减少延迟和带宽消耗。"
]
print("=" * 70)
print("中文词频统计MapReduce示例")
print("=" * 70)
# 测试1:使用专业分词器
print("\n测试1:使用专业分词器(jieba)")
print("-" * 50)
processor_pro = ChineseWordCountMapReduce(use_professional_tokenizer=True)
results_pro = processor_pro.run_mapreduce(chinese_corpus)
processor_pro.analyze_results(results_pro, top_n=15)
# 测试2:使用简单分词器(对比)
print("\n" + "=" * 70)
print("\n测试2:使用简单字符分割")
print("-" * 50)
processor_simple = ChineseWordCountMapReduce(use_professional_tokenizer=False)
results_simple = processor_simple.run_mapreduce(chinese_corpus)
processor_simple.analyze_results(results_simple, top_n=15)
# 对比分析
print("\n" + "=" * 70)
print("分词方法对比分析")
print("=" * 70)
# 提取两种方法的前10个高频词
top_pro = {word for word, _ in results_pro[:10]}
top_simple = {word for word, _ in results_simple[:10]}
print(f"\n专业分词器Top 10词汇: {', '.join(top_pro)}")
print(f"字符分割Top 10词汇: {', '.join(top_simple)}")
# 计算重合度
overlap = top_pro.intersection(top_simple)
print(f"\n重合词汇({len(overlap)}个): {', '.join(overlap) if overlap else '无'}")输出结果:
=====================================================================
中文词频统计MapReduce示例
=====================================================================
测试1:使用专业分词器(jieba)
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Loading model cost 0.449 seconds.
Prefix dict has been built successfully.
开始MapReduce中文词频统计...
使用分词器:专业分词器(jieba)
处理文本行数:15
=== Map阶段 ===
已处理 10/15 行,生成 7 个中间结果
Map阶段完成,共生成 177 个中间键值对
=== Shuffle阶段 ===
Shuffle完成,生成 140 个不同的词
=== Reduce阶段 ===
Reduce完成,输出 140 个最终结果
=== 结果分析 ===
Top 15 高频词:
自然语言处理 : 5
中 : 5
数据 : 4
模型 : 4
训练 : 3
任务 : 3
计算 : 3
人工智能 : 2
领域 : 2
重要 : 2
技术 : 2
大语言模型 : 2
中文 : 2
包括 : 2
分词 : 2
统计摘要:
总词数: 177
唯一词数: 140
词频平均值: 1.26
齐普夫定律验证(前10个词):
第1名 '自然语言处理': 实际频率=5, 预期≈5.0
第2名 '中': 实际频率=5, 预期≈2.5
第3名 '数据': 实际频率=4, 预期≈1.7
第4名 '模型': 实际频率=4, 预期≈1.2
第5名 '训练': 实际频率=3, 预期≈1.0
第6名 '任务': 实际频率=3, 预期≈0.8
第7名 '计算': 实际频率=3, 预期≈0.7
第8名 '人工智能': 实际频率=2, 预期≈0.6
第9名 '领域': 实际频率=2, 预期≈0.6
第10名 '重要': 实际频率=2, 预期≈0.5
==================================================================
测试2:使用简单字符分割
开始MapReduce中文词频统计...
使用分词器:简单字符分割
处理文本行数:15
=== Map阶段 ===
已处理 10/15 行,生成 19 个中间结果
Map阶段完成,共生成 419 个中间键值对
=== Shuffle阶段 ===
Shuffle完成,生成 209 个不同的词
=== Reduce阶段 ===
Reduce完成,输出 209 个最终结果
=== 结果分析 ===
Top 15 高频词:
的 : 12
语 : 11
理 : 9
中 : 9
模 : 9
言 : 8
处 : 8
自 : 7
和 : 7
数 : 7
据 : 7
算 : 6
型 : 6
词 : 6
然 : 5
统计摘要:
总词数: 419
唯一词数: 209
词频平均值: 2.00
齐普夫定律验证(前10个词):
第1名 '的': 实际频率=12, 预期≈12.0
第2名 '语': 实际频率=11, 预期≈6.0
第3名 '理': 实际频率=9, 预期≈4.0
第4名 '中': 实际频率=9, 预期≈3.0
第5名 '模': 实际频率=9, 预期≈2.4
第6名 '言': 实际频率=8, 预期≈2.0
第7名 '处': 实际频率=8, 预期≈1.7
第8名 '自': 实际频率=7, 预期≈1.5
第9名 '和': 实际频率=7, 预期≈1.3
第10名 '数': 实际频率=7, 预期≈1.2
=====================================================================
分词方法对比分析
=====================================================================
专业分词器Top 10词汇: 中, 人工智能, 任务, 自然语言处理, 领域, 计算, 训练, 模型, 重要, 数据
字符分割Top 10词汇: 中, 理, 模, 的, 自, 言, 数, 处, 和, 语
重合词汇(1个): 中
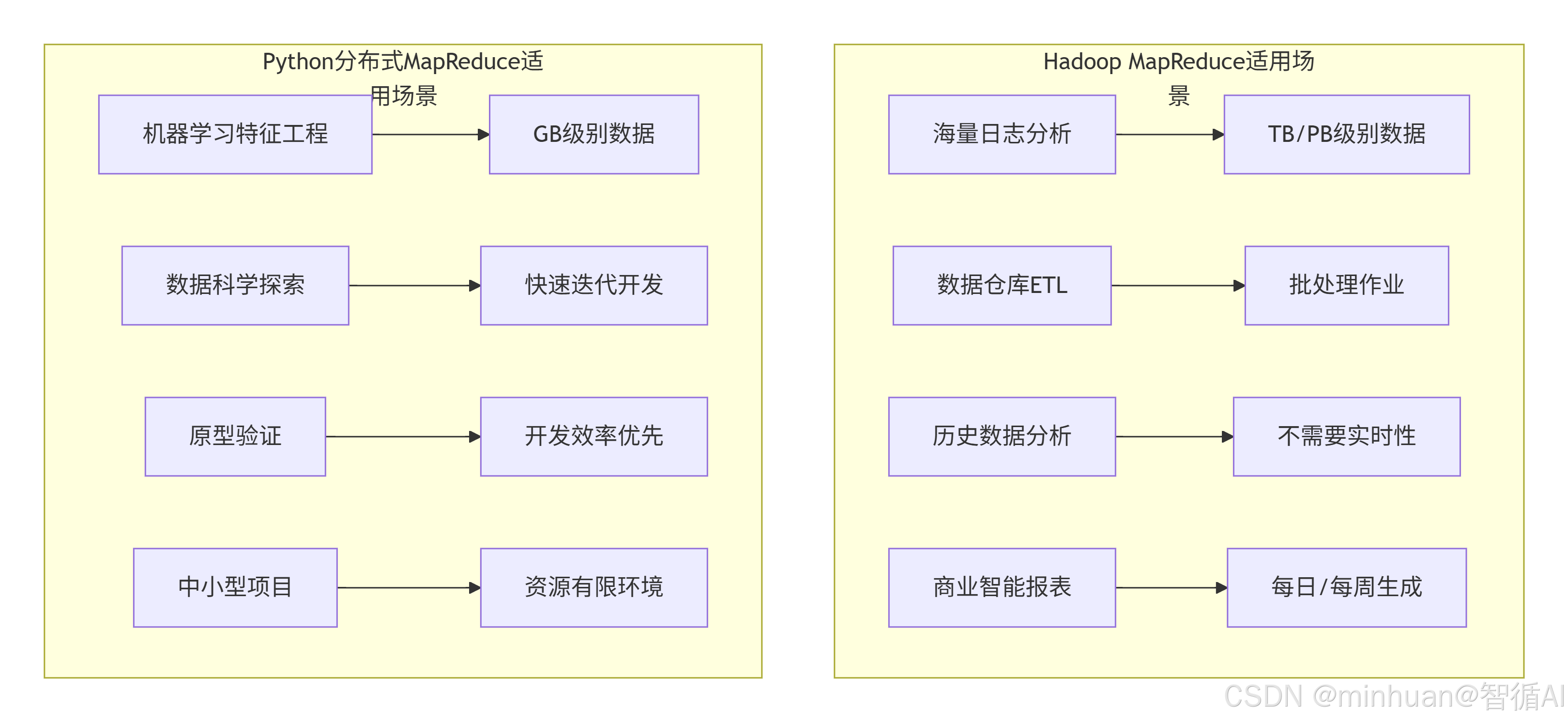
三、分布式 MapReduce
1. 核心架构
Python分布式MapReduce是一个轻量级并行计算框架,通常基于多进程或多线程,适合中等规模数据处理。
分布式MapReduce架构:
- 主进程(Master) - 控制流程,分配任务
- 工作进程池(Worker Pool) - 执行Map/Reduce函数
- 共享内存或队列 - 进程间通信
- 文件系统或内存 - 数据存储
2. 主要特点
- 轻量级:不需要复杂的集群部署
- 内存计算:中间结果在内存中,速度快
- 灵活性高:可以方便地集成Python生态工具
- 开发简单:Python代码,学习曲线低
- 适合中小数据:GB级别数据量
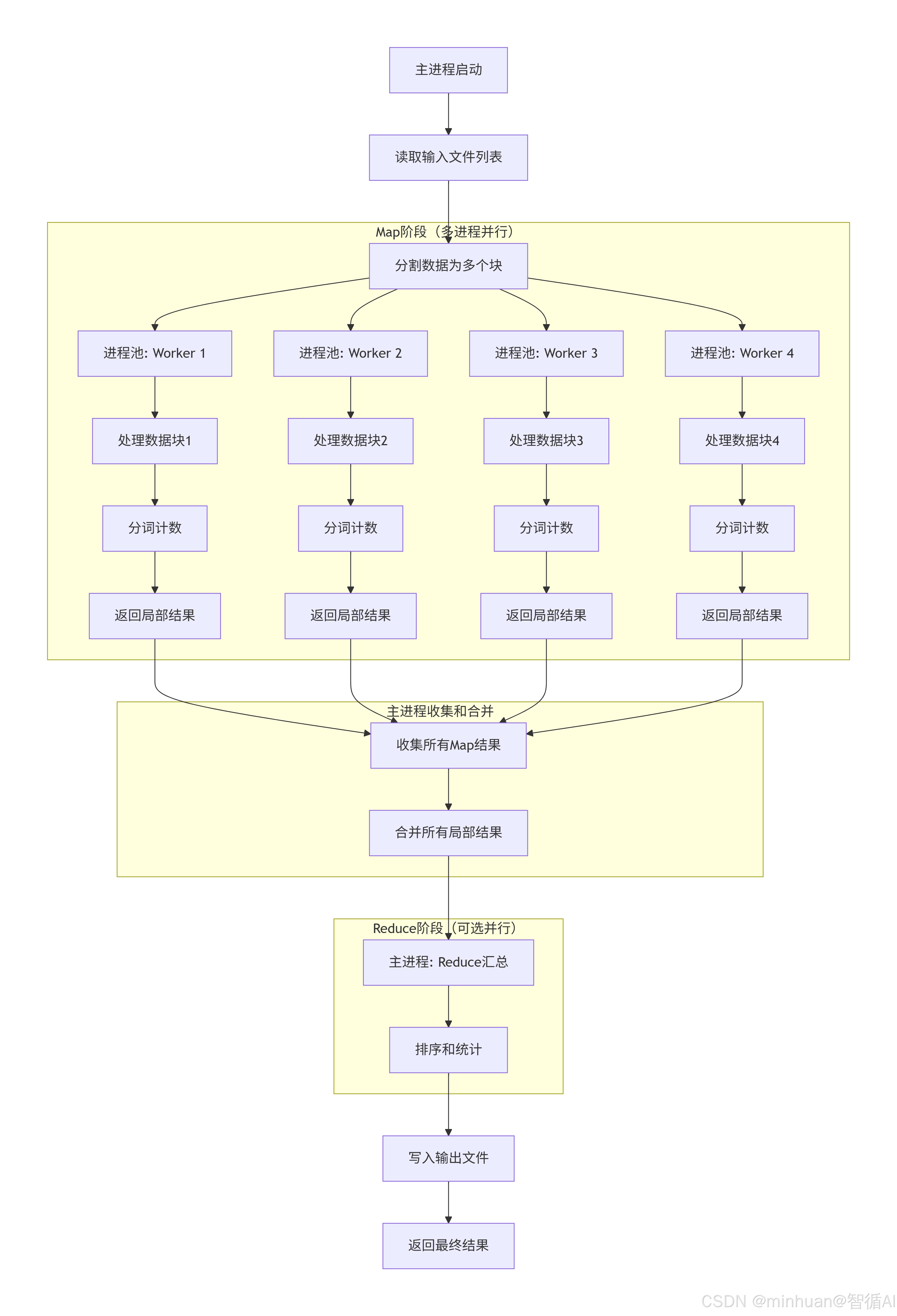
3. 分布式MapReduce流程图
分布式MapReduce(多进程)流程图:读取所有数据,分割成块,分配给多个Map进程并行处理,然后收集Map结果,在Reduce进程中合并统计
核心阶段
1. Split:任务拆分
将原始大任务拆解为若干语义独立、长度适配模型上下文窗口 的子任务。
- 拆分原则:保证子任务语义完整(如按段落拆分文档、按问题类型拆分多问任务),子任务长度≤模型最大上下文窗口的 80%(预留推理空间)。
- 拆分维度:按文本长度、按语义主题、按任务类型(如分类任务拆分为单样本分类)。
2. Map:子任务推理
对每个拆分后的子任务,调用本地大模型独立推理,生成子结果。
- 核心要求:子任务输入格式统一,模型输出结构化(便于后续聚合)。
- 并行策略:多线程 / 多进程调用本地模型,最大化利用硬件资源。
3. Combine(可选):局部聚合
对同类型 / 同主题的 Map 子结果先做局部整合,减少 Reduce 阶段的处理压力(如先合并同一章节的总结,再合并全书总结)。
4. Reduce:最终聚合
将所有 Map(或 Combine)输出的子结果,通过大模型 / 规则引擎整合为最终结果,还原对原始大任务的响应。
4. 优势与局限性
4.1 优势
- 开发效率:Python语法简单,开发快速
- 内存计算:中间结果在内存,速度快
- 集成方便:可轻松使用Numpy、Pandas等库
- 部署简单:单机多核即可运行
- 实时性较好:适合中小数据快速处理
4.2 局限性
- 扩展性有限:受单机资源限制
- 容错性差:进程崩溃整个作业失败
- 内存限制:大数据可能导致内存溢出
- 不适合PB级:设计目标不是海量数据
- 缺乏生态:没有Hadoop那样的完整生态
5. 详细示例
这段代码使用Python的多进程模拟分布式计算,适用于单机多核环境,也可以根据需要扩展到多机。
- 没有显式的Shuffle阶段,而是在Reduce阶段之前,将各个Map进程的结果在内存中合并(通过主进程)。
- 由于是在内存中操作,所以速度较快,但是处理的数据量受限于内存大小。
- 没有Hadoop那样的容错机制,如果某个进程失败,整个任务就会失败。
python
"""
分布式MapReduce实现
理论基础:主从架构,任务调度,结果聚合
"""
import multiprocessing
from multiprocessing import Manager, Pool
import os
from typing import List, Tuple, Dict
import json
import time
import jieba # 专业中文分词库
import re
from collections import defaultdict
class ChineseWordCountMapReduce:
"""
中文词频统计MapReduce实现类
理论基础:分而治之的并行处理模式
"""
def __init__(self, use_professional_tokenizer=True):
"""
初始化MapReduce处理器
参数:
use_professional_tokenizer: 是否使用专业分词器
理论:专业分词器能更好处理中文歧义和未登录词
"""
self.use_professional_tokenizer = use_professional_tokenizer
# 初始化专业分词器配置
if use_professional_tokenizer:
self._init_jieba()
def _init_jieba(self):
"""初始化jieba分词器"""
# 理论:中文分词需要处理多种情况
# 1. 加载用户词典(处理领域专有词汇)
# 2. 调整分词模式(平衡精度与速度)
# 示例:添加自定义词典
custom_words = [
"自然语言处理", # 专业术语
"人工智能", # 专业术语
"深度学习", # 专业术语
"大语言模型", # 专业术语
"机器学习" # 专业术语
]
for word in custom_words:
jieba.add_word(word, freq=1000) # 设置较高频率,确保切分
# 设置停用词(高频但信息量低的词)
self.stop_words = set([
"的", "了", "在", "是", "我", "有", "和", "就",
"不", "人", "都", "一", "一个", "上", "也", "很",
"到", "说", "要", "去", "你", "会", "着", "没有",
"看", "好", "自己", "这"
])
def map_function(self, line):
"""
Map函数:将文本行转换为(词, 1)键值对
理论:
输入:一行文本
处理:分词、过滤、转换
输出:中间键值对列表
"""
# 清理文本:去除标点、数字、英文等
cleaned_text = self._clean_chinese_text(line)
if not cleaned_text:
return [] # 空文本直接返回
# 根据配置选择分词方式
if self.use_professional_tokenizer:
words = self._professional_tokenize(cleaned_text)
else:
words = self._simple_tokenize(cleaned_text)
# 过滤停用词(如果使用专业分词器)
if self.use_professional_tokenizer:
words = [w for w in words if w not in self.stop_words]
# 生成Map输出:每个词计数为1
# 理论:输出为(词, 1)形式,便于后续Reduce汇总
return [(word, 1) for word in words if word.strip()]
def _clean_chinese_text(self, text):
"""
清理中文文本
理论:
中文文本预处理包括:
1. 去除非中文字符(保留必要标点)
2. 统一全半角字符
3. 处理空白字符
"""
# 仅保留中文和空格
# Unicode范围参考:https://unicode-table.com/cn/blocks/
chinese_pattern = re.compile(
r'[^\u4e00-\u9fff\s]'
# r'[^\u4e00-\u9fff\u3000-\u303f\uff00-\uffef\s]' # 包含中文标点
)
cleaned = chinese_pattern.sub(' ', text)
# 合并多个空格
cleaned = re.sub(r'\s+', ' ', cleaned)
return cleaned.strip()
def _simple_tokenize(self, text):
"""
简单分词:按字符分割
理论:
优点:简单快速,不会出错
缺点:丢失词语语义,统计粒度粗
适用场景:字频统计、初步分析
"""
# 按字符分割,过滤空白
return [char for char in text if char.strip() and char != ' ']
def _professional_tokenize(self, text):
"""
专业分词:使用jieba分词
理论:
优点:保留语义信息,统计更准确
缺点:需要词典支持,可能产生歧义
适用场景:词频统计、语义分析
"""
# 使用精确模式分词(适合文本分析)
words = jieba.lcut(text, cut_all=False)
# 可选:过滤词性(只保留名词、动词等实词)
# words_with_tag = pseg.cut(text)
# words = [word for word, flag in words_with_tag
# if flag.startswith(('n', 'v', 'a'))]
return words
def shuffle_function(self, map_results):
"""
Shuffle函数:按键分组
理论:
输入:所有Map任务的输出
处理:按key分组,相同key的value放入列表
输出:分组后的字典 {key: [values]}
"""
shuffle_dict = defaultdict(list)
for word, count in map_results:
shuffle_dict[word].append(count)
return shuffle_dict
def reduce_function(self, shuffle_dict):
"""
Reduce函数:汇总统计
理论:
输入:分组后的中间结果
处理:对每个key的所有value求和
输出:最终的词频统计结果
"""
reduce_results = []
for word, counts in shuffle_dict.items():
total_count = sum(counts)
reduce_results.append((word, total_count))
# 按频次降序排序
# 理论:排序是大数据分析的常见需求
return sorted(reduce_results, key=lambda x: x[1], reverse=True)
def run_mapreduce(self, data_lines):
"""
运行完整的MapReduce流程
理论:
模拟MapReduce的完整执行流程:
1. Map阶段:并行处理(这里简化为顺序)
2. Shuffle阶段:分组聚合
3. Reduce阶段:汇总输出
"""
print("开始MapReduce中文词频统计...")
print(f"使用分词器:{'专业分词器(jieba)' if self.use_professional_tokenizer else '简单字符分割'}")
print(f"处理文本行数:{len(data_lines)}")
# 阶段1:Map(在实际分布式系统中是并行的)
print("\n=== Map阶段 ===")
map_results = []
for i, line in enumerate(data_lines):
line_results = self.map_function(line)
map_results.extend(line_results)
if (i + 1) % 10 == 0: # 每10行输出一次进度
print(f" 已处理 {i + 1}/{len(data_lines)} 行,生成 {len(line_results)} 个中间结果")
print(f"Map阶段完成,共生成 {len(map_results)} 个中间键值对")
# 阶段2:Shuffle
print("\n=== Shuffle阶段 ===")
shuffle_dict = self.shuffle_function(map_results)
print(f"Shuffle完成,生成 {len(shuffle_dict)} 个不同的词")
# 阶段3:Reduce
print("\n=== Reduce阶段 ===")
final_results = self.reduce_function(shuffle_dict)
print(f"Reduce完成,输出 {len(final_results)} 个最终结果")
return final_results
def analyze_results(self, results, top_n=20):
"""
分析统计结果
理论:
词频分析可以提供:
1. 高频词:反映文本主题
2. 词频分布:齐普夫定律验证
3. 词汇多样性:词汇丰富度指标
"""
print("\n=== 结果分析 ===")
# 1. 输出Top N高频词
print(f"\nTop {top_n} 高频词:")
for i, (word, count) in enumerate(results[:top_n], 1):
print(f" {i:2d}. {word:8s} : {count:4d}")
# 2. 计算基本统计信息
total_words = sum(count for _, count in results)
unique_words = len(results)
print(f"\n统计摘要:")
print(f" 总词数: {total_words}")
print(f" 唯一词数: {unique_words}")
print(f" 词频平均值: {total_words/unique_words:.2f}")
# 3. 验证齐普夫定律(Zipf's Law)
# 理论:在自然语言中,词的频率与其排名成反比
if len(results) >= 10:
print(f"\n齐普夫定律验证(前10个词):")
for rank, (word, freq) in enumerate(results[:10], 1):
expected_ratio = results[0][1] / rank # 第一名频率/排名
actual_ratio = freq
print(f" 第{rank}名 '{word}': 实际频率={freq}, 预期≈{expected_ratio:.1f}")
class DistributedMapReduce:
"""
分布式MapReduce框架
理论基础:
1. 主节点(Master):负责任务调度和结果收集
2. 工作节点(Worker):执行具体的Map/Reduce任务
3. 数据分片(Data Split):将输入数据划分为多个块
4. 任务调度(Task Scheduling):动态分配任务给空闲Worker
"""
def __init__(self, num_workers: int = 4):
"""
初始化分布式MapReduce框架
参数:
num_workers: 工作进程数
理论:根据CPU核心数和任务特性确定最优worker数
"""
self.num_workers = num_workers
self.worker_pool = None
# 初始化分词器(所有worker共享)
self._init_tokenizer()
def _init_tokenizer(self):
"""初始化分词器(在实际分布式系统中,每个节点都需要)"""
import jieba
# 添加领域词汇
domain_words = [
"MapReduce", "分布式计算", "并行处理", "数据分片",
"任务调度", "容错机制", "负载均衡", "数据局部性"
]
for word in domain_words:
jieba.add_word(word, freq=1000)
def split_data(self, data: List[str], num_splits: int = None) -> List[List[str]]:
"""
数据分片函数
理论:
数据分片原则:
1. 大小均衡:各分片数据量相近
2. 局部性:相关数据尽量在同一分片
3. 可扩展:支持动态增加分片
参数:
data: 输入数据列表
num_splits: 分片数,默认等于worker数
"""
if num_splits is None:
num_splits = self.num_workers
# 计算每个分片的大小
chunk_size = len(data) // num_splits
if len(data) % num_splits != 0:
chunk_size += 1
# 创建分片
splits = []
for i in range(0, len(data), chunk_size):
splits.append(data[i:i + chunk_size])
print(f"数据分片完成:{len(data)}条数据 → {len(splits)}个分片")
return splits
def map_worker(self, chunk: List[str]) -> List[Tuple[str, int]]:
"""
Map工作进程函数
理论:
Map Worker职责:
1. 读取分配给它的数据分片
2. 应用Map函数处理每条记录
3. 输出中间键值对
4. 可能进行本地聚合(Combiner优化)
"""
import jieba
# 获取进程ID(用于调试)
pid = os.getpid()
print(f"Map Worker {pid}: 开始处理 {len(chunk)} 条记录")
map_results = []
# 处理数据块中的每一行
for i, line in enumerate(chunk):
# 清理文本
cleaned = self._clean_text(line)
if not cleaned:
continue
# 使用jieba分词
words = jieba.lcut(cleaned)
# 过滤停用词和短词
filtered_words = [
w for w in words
if len(w) > 1 and w.strip() # 过滤单字和空白
]
# 生成中间结果
for word in filtered_words:
map_results.append((word, 1))
# 进度显示
if (i + 1) % 100 == 0:
print(f" Worker {pid}: 已处理 {i + 1}/{len(chunk)} 行")
print(f"Map Worker {pid}: 处理完成,生成 {len(map_results)} 个中间结果")
return map_results
def shuffle_phase(self, all_map_results: List[List[Tuple[str, int]]]) -> Dict[str, List[int]]:
"""
Shuffle阶段:中间结果分组
理论:
Shuffle过程:
1. 分区(Partition):确定每个中间结果由哪个Reduce处理
2. 排序(Sort):按key排序,便于分组
3. 传输(Transfer):将数据发送到对应的Reduce节点
优化策略:
- 哈希分区:均匀分布key
- 本地聚合:Map端先进行部分聚合
- 数据压缩:减少网络传输
"""
print(f"\n开始Shuffle阶段,处理 {len(all_map_results)} 个Map输出")
# 合并所有Map结果
combined_results = []
for map_result in all_map_results:
combined_results.extend(map_result)
print(f"总中间结果数: {len(combined_results)}")
# 分组:相同key的value放入列表
# 理论:使用哈希表实现高效分组
shuffle_dict = {}
for key, value in combined_results:
if key not in shuffle_dict:
shuffle_dict[key] = []
shuffle_dict[key].append(value)
print(f"分组完成,生成 {len(shuffle_dict)} 个不同的key")
return shuffle_dict
def reduce_worker(self, key_values: Tuple[str, List[int]]) -> Tuple[str, int]:
"""
Reduce工作进程函数
理论:
Reduce Worker职责:
1. 接收分配给它的键值分组
2. 对每个key的所有value进行归约操作
3. 输出最终结果
参数:
key_values: (key, values_list)元组
"""
key, values = key_values
pid = os.getpid()
# 计算总和
total = sum(values)
# 可选:复杂Reduce操作
# 例如:计算平均值、最大值、最小值等
# avg = total / len(values) if values else 0
return (key, total)
def _clean_text(self, text: str) -> str:
"""清理文本"""
import re
# 保留中文、英文字母、数字和基本标点
cleaned = re.sub(r'[^\u4e00-\u9fff\w\s.,!?;:,。!?;:"\'、-]', '', text)
# 合并多个空格
cleaned = re.sub(r'\s+', ' ', cleaned)
return cleaned.strip()
def run_distributed(self, input_data: List[str], output_file: str = None):
"""
运行分布式MapReduce作业
理论:
完整的分布式执行流程:
1. 作业初始化:配置参数,准备环境
2. 数据分片:将输入数据划分为多个分片
3. Map阶段:并行执行Map任务
4. Shuffle阶段:中间结果分组和传输
5. Reduce阶段:并行执行Reduce任务
6. 输出阶段:收集和保存结果
"""
print("=" * 70)
print("分布式MapReduce作业启动")
print(f"工作进程数: {self.num_workers}")
print(f"输入数据量: {len(input_data)} 条")
print("=" * 70)
start_time = time.time()
try:
# 阶段1:数据分片
print("\n[阶段1] 数据分片...")
data_splits = self.split_data(input_data)
# 阶段2:Map阶段(并行)
print("\n[阶段2] Map阶段(并行执行)...")
map_start = time.time()
with Pool(processes=self.num_workers) as pool:
map_results = pool.map(self.map_worker, data_splits)
map_time = time.time() - map_start
print(f"Map阶段完成,耗时: {map_time:.2f}秒")
# 阶段3:Shuffle阶段
print("\n[阶段3] Shuffle阶段...")
shuffle_start = time.time()
shuffle_dict = self.shuffle_phase(map_results)
shuffle_time = time.time() - shuffle_start
# 将分组数据转换为列表,便于并行处理
reduce_inputs = list(shuffle_dict.items())
print(f"Shuffle阶段完成,耗时: {shuffle_time:.2f}秒")
print(f"生成 {len(reduce_inputs)} 个Reduce任务")
# 阶段4:Reduce阶段(并行)
print("\n[阶段4] Reduce阶段(并行执行)...")
reduce_start = time.time()
with Pool(processes=self.num_workers) as pool:
reduce_results = pool.map(self.reduce_worker, reduce_inputs)
reduce_time = time.time() - reduce_start
print(f"Reduce阶段完成,耗时: {reduce_time:.2f}秒")
# 阶段5:结果处理
print("\n[阶段5] 结果处理...")
# 按频次排序
final_results = sorted(reduce_results, key=lambda x: x[1], reverse=True)
# 计算统计信息
total_words = sum(count for _, count in final_results)
unique_words = len(final_results)
total_time = time.time() - start_time
# 输出统计信息
print("\n" + "=" * 70)
print("作业执行统计")
print("=" * 70)
print(f"总执行时间: {total_time:.2f}秒")
print(f"Map阶段时间: {map_time:.2f}秒 ({map_time/total_time*100:.1f}%)")
print(f"Shuffle阶段时间: {shuffle_time:.2f}秒 ({shuffle_time/total_time*100:.1f}%)")
print(f"Reduce阶段时间: {reduce_time:.2f}秒 ({reduce_time/total_time*100:.1f}%)")
print(f"总词数: {total_words}")
print(f"唯一词数: {unique_words}")
print(f"平均词频: {total_words/unique_words:.2f}")
# 输出Top 20结果
print(f"\nTop 20 高频词:")
for i, (word, count) in enumerate(final_results[:20], 1):
percentage = count / total_words * 100
print(f" {i:2d}. {word:10s} : {count:6d} ({percentage:.2f}%)")
# 保存结果到文件
if output_file:
self._save_results(final_results, output_file)
return final_results
except Exception as e:
print(f"作业执行失败: {e}")
import traceback
traceback.print_exc()
raise
def _save_results(self, results: List[Tuple[str, int]], output_file: str):
"""保存结果到文件"""
# 转换为字典格式
result_dict = {
"metadata": {
"timestamp": time.strftime("%Y-%m-%d %H:%M:%S"),
"total_words": sum(count for _, count in results),
"unique_words": len(results)
},
"word_frequencies": dict(results[:1000]) # 只保存前1000个
}
# 保存为JSON
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(result_dict, f, ensure_ascii=False, indent=2)
print(f"\n结果已保存到: {output_file}")
# 生成测试数据
def generate_test_data(num_lines: int = 1000) -> List[str]:
"""
生成中文测试数据
理论:
测试数据应该:
1. 覆盖不同长度的文本
2. 包含领域特定词汇
3. 有一定的重复模式
4. 模拟真实数据分布
"""
base_sentences = [
"自然语言处理是人工智能的重要分支",
"深度学习模型需要大量数据进行训练",
"大语言模型在多个任务上表现出色",
"中文分词是中文信息处理的基础",
"Transformer架构已成为主流模型",
"注意力机制提高了模型性能",
"预训练模型减少了数据需求",
"分布式计算加速了模型训练",
"MapReduce框架处理大规模数据",
"云计算提供弹性计算资源"
]
import random
test_data = []
for i in range(num_lines):
# 组合多个句子
num_sentences = random.randint(1, 3)
selected = random.sample(base_sentences, num_sentences)
# 添加一些随机词汇
random_words = ["技术", "发展", "应用", "研究", "算法", "系统", "网络", "数据"]
extra = random.sample(random_words, random.randint(0, 2))
# 构建文本行
line = ",".join(selected + extra) + "。"
test_data.append(line)
return test_data
# 运行分布式MapReduce
if __name__ == "__main__":
print("分布式MapReduce中文词频统计示例")
print("=" * 70)
# 生成测试数据
print("生成测试数据...")
test_data = generate_test_data(500) # 500行文本
print(f"生成 {len(test_data)} 行测试数据")
# 示例:显示部分数据
print("\n示例数据(前5行):")
for i, line in enumerate(test_data[:5]):
print(f" {i+1}. {line}")
# 创建分布式MapReduce处理器
# 理论:根据CPU核心数设置worker数
import multiprocessing
cpu_count = multiprocessing.cpu_count()
num_workers = min(cpu_count, 8) # 最多使用8个worker
print(f"\nCPU核心数: {cpu_count}")
print(f"设置工作进程数: {num_workers}")
dmr = DistributedMapReduce(num_workers=num_workers)
# 运行分布式作业
results = dmr.run_distributed(
input_data=test_data,
output_file="distributed_word_count.json"
)
# 性能对比:单进程 vs 多进程
print("\n" + "=" * 70)
print("性能对比分析")
print("=" * 70)
# 单进程执行(对比基准)
print("\n单进程执行测试...")
single_start = time.time()
single_processor = ChineseWordCountMapReduce(use_professional_tokenizer=True)
single_results = single_processor.run_mapreduce(test_data[:100]) # 只测试100行
single_time = time.time() - single_start
print(f"单进程处理100行耗时: {single_time:.2f}秒")
# 估算全量数据单进程时间
estimated_single_time = single_time * (len(test_data) / 100)
print(f"估算单进程处理全部{len(test_data)}行耗时: {estimated_single_time:.2f}秒")5.1 重点说明
5.1.1 代码特点
- 模块化设计:将MapReduce的各个阶段(Map、Shuffle、Reduce)封装成独立的函数,便于理解和修改。
- 支持两种分词方式:简单字符分割和专业分词(使用jieba)。
- 分布式模拟:利用多进程模拟分布式计算,每个进程处理一个数据分片。
- 完整流程:包括数据分片、Map、Shuffle、Reduce、结果收集和排序。
- 提供了性能对比,可以比较单进程和多进程处理的耗时。
5.1.2 执行流程
单机MapReduce(ChineseWordCountMapReduce类)
- 初始化:根据参数选择分词器,并初始化jieba分词器(如果需要)。
- Map阶段:逐行读取数据,对每行文本进行清洗和分词,然后输出(词, 1)的键值对。
- Shuffle阶段:将Map输出的键值对按照键(词)进行分组,形成{词: 1, 1, ...}的字典。
- Reduce阶段:对每个键对应的值列表求和,得到每个词的总频次。
- 排序与输出:按词频降序排序,并输出结果。
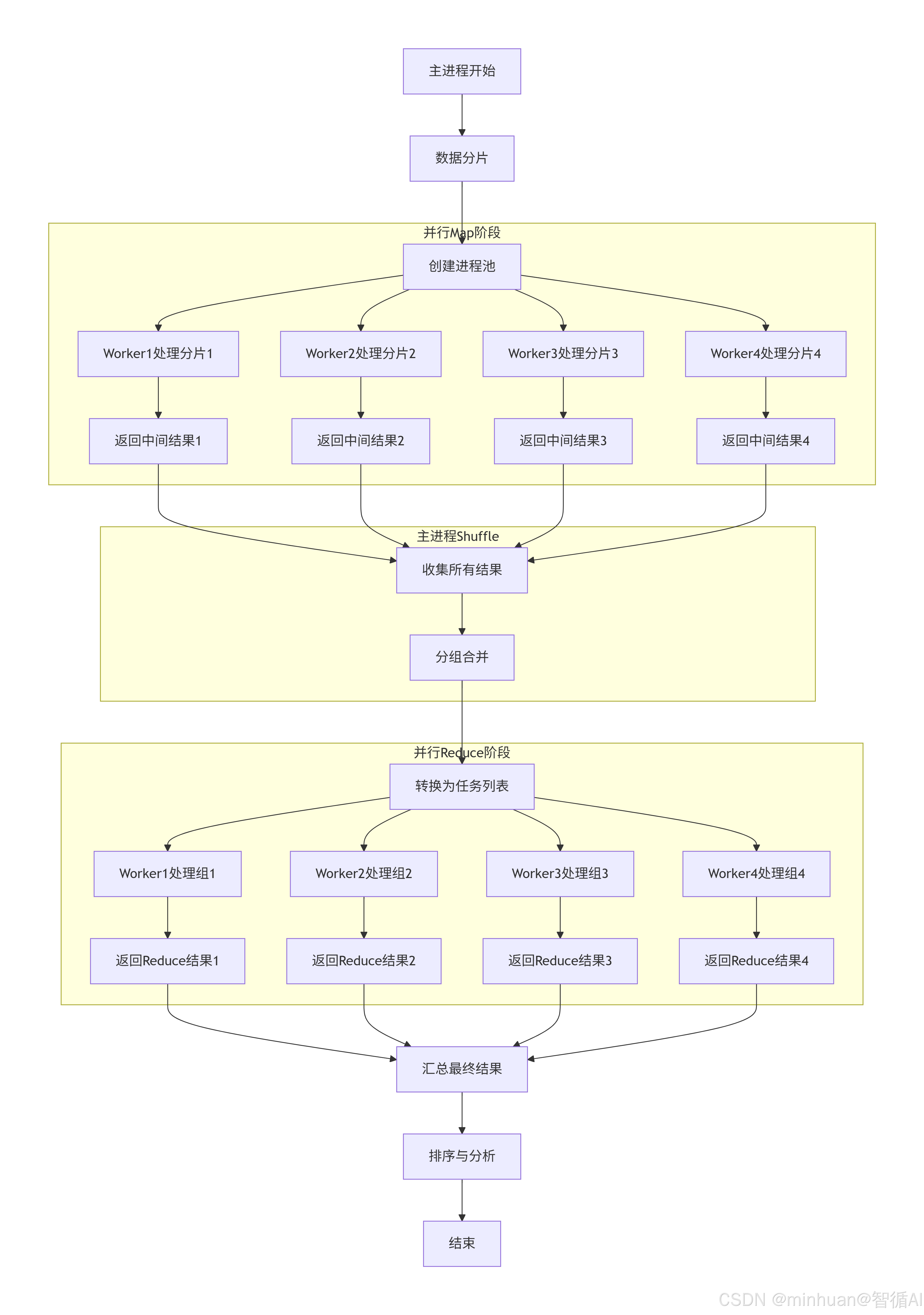
分布式MapReduce(DistributedMapReduce类)
- 初始化:设置工作进程数,初始化分词器。
- 数据分片:将输入数据均匀分成多个分片,分片数默认为工作进程数。
- Map阶段(并行):使用进程池,每个进程处理一个数据分片,执行Map操作,生成中间键值对。
- Shuffle阶段:收集所有Map任务的输出,合并并按键分组。
- Reduce阶段(并行):使用进程池,每个进程处理一组键值(一个键和对应的值列表),执行Reduce操作。
- 结果汇总:收集所有Reduce任务的输出,按词频排序,并输出统计信息。
5.1.3 设计细节
- 分词器的选择:
- 简单分词器:按字符分割,适用于字频统计。
- 专业分词器(jieba):能够识别中文词汇,但需要加载词典和停用词。
- 数据清洗:
- 使用正则表达式去除非中文字符(或保留中文和基本标点)。
- 合并多个空格,去除首尾空格。
- 分布式模拟中的进程通信:
- 使用multiprocessing.Pool来管理进程池,通过map方法分配任务。
- Map阶段:每个进程处理一个数据分片,返回该分片的中间结果。
- Reduce阶段:每个进程处理一个键及其值列表,返回(键, 总和)。
- 性能对比:
- 代码中对比了单进程处理100行数据的时间,并推算了全量数据单进程处理时间。
- 分布式处理使用多进程,可以显著减少处理时间(尤其是数据量大的时候)。
- 结果保存:
- 分布式处理的结果可以保存为JSON文件,包括元数据和词频统计。
- 容错与健壮性:
- 代码中使用了异常处理,确保在出错时能够打印错误信息。
- 分布式模拟中,进程池会自动管理进程的生命周期。
5.2 架构解析
5.2.1 双模式设计实现方式
单机版(ChineseWordCountMapReduce):
- 特点:顺序执行,教学演示
- 适用场景:小数据量,理解原理
- 并行性:模拟并行,实际顺序执行
分布式版(DistributedMapReduce):
- 特点:多进程并行,接近真实分布式
- 适用场景:中等数据量,性能测试
- 并行性:真正的多进程并行
5.2.2 模块化设计
- 数据预处理:_clean_chinese_text(), _clean_text()
- 分词处理:_simple_tokenize(), _professional_tokenize()
- Map阶段:map_function(), map_worker()
- Shuffle阶段:shuffle_function(), shuffle_phase()
- Reduce阶段:reduce_function(), reduce_worker()
- 结果分析:analyze_results(), _save_results()
5.2.3 两种分词策略
策略1:字符级分割(简单但丢失语义)
- 理论依据:中文的每个字符都有独立意义
- 优点:不会出错,处理速度快
- 缺点:丢失词语级别的语义信息
- 示例:"自然语言" → "自", "然", "语", "言"
策略2:词语级分割(复杂但准确)
- 理论依据:中文以词为基本语义单位
- 优点:保留语义信息,统计更准确
- 缺点:需要词典,可能产生歧义
- 示例:"自然语言" → "自然", "语言"
5.2.4 数据分片策略
-
- 分片数默认等于worker数:最大化并行度
-
- 处理余数问题:最后一片可能稍小
-
- 保持数据完整性:每个元素只在一个分片中
- 数据分布示例:
- 100条数据,4个worker → 每个分片25条
- 103条数据,4个worker → 分片大小:26,26,26,25
5.2.5 进程池管理
使用进程池而非线程池的原因
- Python GIL限制:CPU密集型任务用多进程
- 内存隔离:每个进程独立内存,避免竞争
- 容错性:一个进程崩溃不影响其他进程
- 扩展性:可扩展到多机分布式
- pool.map: 阻塞调用,等待所有worker完成
5.2.6 内存中的分组操作
关键细节:
-
- 合并所有Map结果:先收集再处理
-
- 使用字典分组:O(1)时间复杂度查找
-
- 内存消耗:可能较大,适合中等规模数据
优化空间:
-
- 外部排序:数据太大时存磁盘
-
- 哈希分区:提前确定Reduce目标
-
- Combiner:Map端预聚合减少数据量
5.3 输出结果
分布式MapReduce中文词频统计示例
======================================================================
生成测试数据...
生成 500 行测试数据
示例数据(前5行):
-
中文分词是中文信息处理的基础。
-
中文分词是中文信息处理的基础,云计算提供弹性计算资源,MapReduce框架处理大规模数据,技术。
-
自然语言处理是人工智能的重要分支,Transformer架构已成为主流模型,技术,网络。
-
云计算提供弹性计算资源,预训练模型减少了数据需求,分布式计算加速了模型训练。
-
预训练模型减少了数据需求,数据,研究。
CPU核心数: 8
设置工作进程数: 8
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Loading model cost 0.433 seconds.
Prefix dict has been built successfully.
======================================================================
分布式MapReduce作业启动
工作进程数: 8
输入数据量: 500 条
======================================================================
阶段1 数据分片...
数据分片完成:500条数据 → 8个分片
阶段2 Map阶段(并行执行)...
Map Worker 15384: 开始处理 63 条记录
Map Worker 14056: 开始处理 63 条记录
Building prefix dict from the default dictionary ...
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Map Worker 4924: 开始处理 63 条记录
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Building prefix dict from the default dictionary ...
Map Worker 12512: 开始处理 63 条记录
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Map Worker 12276: 开始处理 63 条记录
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Building prefix dict from the default dictionary ...
Map Worker 6168: 开始处理 63 条记录
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Building prefix dict from the default dictionary ...
Map Worker 12976: 开始处理 63 条记录
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Map Worker 14440: 开始处理 59 条记录
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\du\AppData\Local\Temp\jieba.cache
Loading model cost 1.009 seconds.
Prefix dict has been built successfully.
Map Worker 15384: 处理完成,生成 747 个中间结果
Loading model cost 1.009 seconds.
Prefix dict has been built successfully.
Map Worker 12276: 处理完成,生成 712 个中间结果
Loading model cost 1.047 seconds.
Prefix dict has been built successfully.
Map Worker 4924: 处理完成,生成 689 个中间结果
Loading model cost 1.101 seconds.
Prefix dict has been built successfully.
Loading model cost 1.131 seconds.
Prefix dict has been built successfully.
Loading model cost 1.057 seconds.
Prefix dict has been built successfully.
Loading model cost 1.073 seconds.
Prefix dict has been built successfully.
Map Worker 12512: 处理完成,生成 706 个中间结果
Loading model cost 1.090 seconds.
Map Worker 14056: 处理完成,生成 641 个中间结果
Prefix dict has been built successfully.
Map Worker 12976: 处理完成,生成 733 个中间结果
Map Worker 14440: 处理完成,生成 638 个中间结果
Map Worker 6168: 处理完成,生成 702 个中间结果
Map阶段完成,耗时: 2.60秒
阶段3 Shuffle阶段...
开始Shuffle阶段,处理 8 个Map输出
总中间结果数: 5568
分组完成,生成 47 个不同的key
Shuffle阶段完成,耗时: 0.00秒
生成 47 个Reduce任务
阶段4 Reduce阶段(并行执行)...
Reduce阶段完成,耗时: 1.00秒
阶段5 结果处理...
======================================================================
作业执行统计
======================================================================
总执行时间: 3.61秒
Map阶段时间: 2.60秒 (72.2%)
Shuffle阶段时间: 0.00秒 (0.1%)
Reduce阶段时间: 1.00秒 (27.8%)
总词数: 5568
唯一词数: 47
平均词频: 118.47
Top 20 高频词:
-
模型 : 611 (10.97%)
-
数据 : 365 (6.56%)
-
训练 : 292 (5.24%)
-
处理 : 205 (3.68%)
-
注意力 : 113 (2.03%)
-
机制 : 113 (2.03%)
-
提高 : 113 (2.03%)
-
性能 : 113 (2.03%)
-
MapReduce : 112 (2.01%)
-
框架 : 112 (2.01%)
-
大规模 : 112 (2.01%)
-
Transformer : 104 (1.87%)
-
架构 : 104 (1.87%)
-
成为 : 104 (1.87%)
-
主流 : 104 (1.87%)
-
语言 : 102 (1.83%)
-
多个 : 102 (1.83%)
-
任务 : 102 (1.83%)
-
表现出色 : 102 (1.83%)
-
计算 : 100 (1.80%)
结果已保存到: distributed_word_count.json
======================================================================
性能对比分析
======================================================================
单进程执行测试...
开始MapReduce中文词频统计...
使用分词器:专业分词器(jieba)
处理文本行数:100
=== Map阶段 ===
已处理 10/100 行,生成 4 个中间结果
已处理 20/100 行,生成 6 个中间结果
已处理 30/100 行,生成 12 个中间结果
已处理 40/100 行,生成 6 个中间结果
已处理 50/100 行,生成 13 个中间结果
已处理 60/100 行,生成 12 个中间结果
已处理 70/100 行,生成 6 个中间结果
已处理 80/100 行,生成 9 个中间结果
已处理 90/100 行,生成 12 个中间结果
已处理 100/100 行,生成 5 个中间结果
Map阶段完成,共生成 1078 个中间键值对
=== Shuffle阶段 ===
Shuffle完成,生成 47 个不同的词
=== Reduce阶段 ===
Reduce完成,输出 47 个最终结果
单进程处理100行耗时: 0.01秒
估算单进程处理全部500行耗时: 0.07秒
四、总结
传统 MapReduce 与大模型 MapReduce 虽同承 "分治 - 并行 - 聚合" 思想,却因目标差异形成显著区别。传统 MapReduce 以 Hadoop 为代表,聚焦结构化数据的集群计算,靠 CPU 与磁盘 IO 支撑,按数据大小分片后,经 Shuffle 环节完成键值对混洗排序,最终输出数值统计结果。
大模型 MapReduce 则适配语义任务,针对超长文本等场景,依托本地 GPU/CPU 运行大模型。其核心是按语义完整性拆分任务,并行调用模型生成子结果,无需 Shuffle 环节,直接通过语义融合完成聚合,输出总结等文本结果。
两者在拆分依据、算力核心、聚合逻辑上截然不同,前者服务数据计算,后者专注语义理解,分别适配不同技术需求。