摘要:本文介绍了一个基于深度学习的游戏评论情感分析系统。该系统利用自然语言处理技术对TapTap平台的游戏评论进行情感倾向分析(满意/不满意)。文章详细阐述了从数据预处理、特征工程到机器学习(逻辑回归、随机森林等)与深度学习(LSTM、CNN)模型构建的完整流程,并展示了基于Flask框架开发的Web应用系统,实现了用户登录、实时情感预测及数据可视化分析等功能。实验结果表明,该系统能够有效识别玩家情感,为游戏运营提供决策支持。
关键词:情感分析;深度学习;机器学习;自然语言处理;Flask;Web开发;游戏评论;LSTM;CNN
系统演示视频详情见:https://www.bilibili.com/video/BV1yrSmBeEWr/
1. 项目背景与意义
随着游戏产业的蓬勃发展,玩家评论成为了衡量游戏质量、用户体验和市场反馈的重要指标。海量的玩家评论中蕴含着丰富的情感信息,对于游戏开发者优化产品、运营团队制定策略以及潜在玩家进行消费决策都具有极高的参考价值。
本项目旨在构建一个基于深度学习的游戏评论情感分析系统,利用自然语言处理(NLP)技术,对TapTap平台上的游戏评论进行自动化的情感倾向分析(满意/不满意)。系统集成了多种机器学习和深度学习模型,并提供了一个直观的Web界面,方便用户进行实时预测和数据分析。
2. 系统架构概览
本系统采用 B/S (Browser/Server) 架构,前后端分离设计。
- 前端 :使用 Bootstrap 5 框架构建响应式用户界面,提供简洁美观的交互体验。利用 ECharts 进行数据可视化展示。
- 后端 :基于 Flask 轻量级Web框架,负责处理HTTP请求、路由分发和业务逻辑。
- 数据层 :使用 SQLite 数据库存储用户信息和预测历史记录,通过 SQLAlchemy ORM进行操作。
- 算法层 :集成 Scikit-learn (机器学习)和 TensorFlow/Keras(深度学习)框架,提供多种情感分析模型。
3. 算法建模流程
算法建模部分在 Jupyter Notebook (游戏评论情感分析算法建模.ipynb) 中完成,主要包含以下步骤:
3.1 数据探索与预处理
- 数据来源 :TapTap游戏评论数据集 (taptap_review_ready.csv),包含评论文本 (
review) 和情感标签 (sentiment)。 - 数据清洗:去除重复评论和空评论,确保数据质量。
- 文本预处理 :
- 清洗:去除非中文字符、特殊符号和多余空格。
- 分词 :使用 jieba 分词库对中文文本进行切分。
- 去停用词:过滤掉无意义的常用词(如"的"、"了"、"是"等)以及游戏特定高频词(如"游戏"、"玩家"),以减少噪声。
python
# 定义文本清洗函数
def clean_text(text):
"""清洗文本数据"""
# 去除特殊字符,保留中文、英文、数字
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s]', '', str(text))
# 去除多余空格
text = re.sub(r'\s+', ' ', text)
# 去除首尾空格
text = text.strip()
return text
# 定义中文分词函数
def tokenize_chinese(text):
"""中文分词"""
# 使用jieba进行分词
words = jieba.lcut(text)
# 过滤长度小于2的词和停用词
words = [word for word in words if len(word) >= 2 and word not in stopwords]
return ' '.join(words)
# 加载停用词
stopwords = set([
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去',
'你', '会', '着', '没有', '看', '好', '自己', '这', '那', '里', '来', '他', '时候', '可以', '下', '对', '能', '还',
'多', '个', '什么', '这个', '怎么', '现在', '知道', '只是', '但是', '如果', '因为', '所以', '虽然', '然后', '或者',
'游戏', '这款', '这个游戏', '玩家', '感觉', '觉得', '真的', '还是', '就是', '比较', '非常', '特别', '挺', '太'
])
print("开始文本预处理...")
# 清洗文本
df['cleaned_review'] = df['review'].apply(clean_text)
# 中文分词
df['tokenized_review'] = df['cleaned_review'].apply(tokenize_chinese)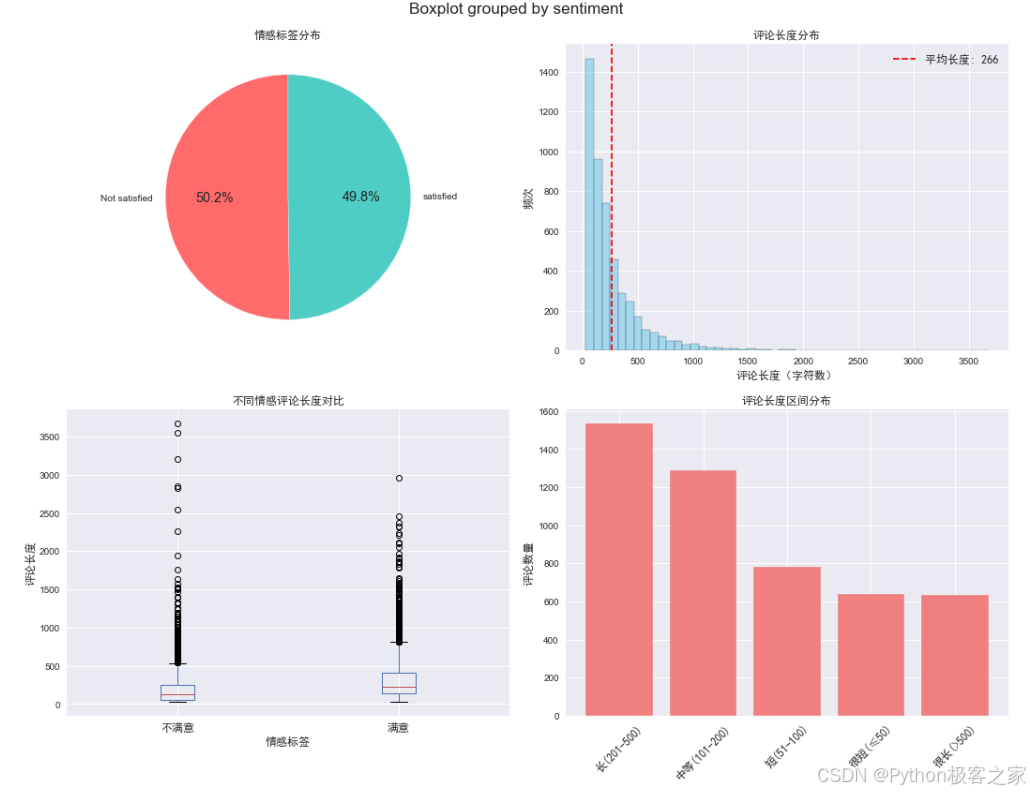

3.2 特征工程
- 机器学习特征 :使用 TF-IDF (Term Frequency-Inverse Document Frequency) 将文本转换为向量,提取关键词特征。
- 深度学习特征 :使用 Tokenizer 将文本转换为整数序列,并使用
pad_sequences将序列填充/截断为固定长度(例如200),以便输入神经网络。
python
# 准备数据
X = df['tokenized_review']
y = df['sentiment']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
print(f"训练集大小: {len(X_train)}")
print(f"测试集大小: {len(X_test)}")
print(f"训练集正负样本比例: {y_train.value_counts(normalize=True)}")
# TF-IDF特征提取
tfidf_vectorizer = TfidfVectorizer(
max_features=5000, # 最大特征数
ngram_range=(1, 2), # 使用1-gram和2-gram
min_df=2, # 最小文档频率
max_df=0.95 # 最大文档频率
)
# 拟合并转换训练数据
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print(f"\nTF-IDF特征矩阵形状: {X_train_tfidf.shape}")
print(f"特征词汇表大小: {len(tfidf_vectorizer.vocabulary_)}")
# 保存TF-IDF向量化器
joblib.dump(tfidf_vectorizer, 'tfidf_vectorizer.pkl')
print("TF-IDF向量化器已保存")3.3 模型构建与训练
本项目对比了多种模型的性能:
3.3.1 机器学习模型 (Machine Learning)
- 逻辑回归 (Logistic Regression):作为基准模型,训练速度快,可解释性强。
- 随机森林 (Random Forest):基于决策树的集成方法,具有较好的抗过拟合能力。
- 朴素贝叶斯 (Multinomial Naive Bayes):适用于文本分类的经典算法。
- XGBoost:高效的梯度提升决策树算法,通常能获得更好的性能。
python
# 1. 逻辑回归
print("=" * 50)
print("训练逻辑回归模型")
lr_model = LogisticRegression(random_state=42, max_iter=1000)
lr_model, lr_acc, lr_auc = evaluate_model(lr_model, X_train_tfidf, X_test_tfidf, y_train, y_test, "逻辑回归")
model_results['逻辑回归'] = {'model': lr_model, 'accuracy': lr_acc, 'auc': lr_auc}
# 2. 随机森林
print("=" * 50)
print("训练随机森林模型")
rf_model = RandomForestClassifier(n_estimators=100, random_state=42, n_jobs=-1)
rf_model, rf_acc, rf_auc = evaluate_model(rf_model, X_train_tfidf, X_test_tfidf, y_train, y_test, "随机森林")
model_results['随机森林'] = {'model': rf_model, 'accuracy': rf_acc, 'auc': rf_auc}
# 3. 朴素贝叶斯
print("=" * 50)
print("训练朴素贝叶斯模型")
nb_model = MultinomialNB()
nb_model, nb_acc, nb_auc = evaluate_model(nb_model, X_train_tfidf, X_test_tfidf, y_train, y_test, "朴素贝叶斯")
model_results['朴素贝叶斯'] = {'model': nb_model, 'accuracy': nb_acc, 'auc': nb_auc}
# 4. XGBoost
print("=" * 50)
print("训练XGBoost模型")
xgb_model = xgb.XGBClassifier(random_state=42, eval_metric='logloss')
xgb_model, xgb_acc, xgb_auc = evaluate_model(xgb_model, X_train_tfidf, X_test_tfidf, y_train, y_test, "XGBoost")
model_results['XGBoost'] = {'model': xgb_model, 'accuracy': xgb_acc, 'auc': xgb_auc}3.3.2 深度学习模型 (Deep Learning)
- LSTM (Long Short-Term Memory) :一种特殊的循环神经网络(RNN),能够捕捉长距离的语义依赖,适合处理序列数据。
- 网络结构:Embedding层 -> LSTM层 -> Dense层 (Sigmoid激活)。
- CNN (Convolutional Neural Network) :一维卷积神经网络,能够提取文本的局部特征(如短语模式)。
- 网络结构:Embedding层 -> Conv1D层 -> GlobalMaxPooling1D层 -> Dense层。
python
# 1. LSTM模型
print("构建LSTM模型")
lstm_model = Sequential([
Embedding(max_features, 128, input_length=max_length),
LSTM(64, dropout=0.5, recurrent_dropout=0.5),
Dense(32, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
lstm_model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
print(lstm_model.summary())
# 训练LSTM模型
print("训练LSTM模型...")
lstm_history = lstm_model.fit(
X_train_pad, y_train,
batch_size=32,
epochs=5,
validation_split=0.2,
verbose=1
)
# 评估LSTM模型
lstm_pred = (lstm_model.predict(X_test_pad) > 0.5).astype(int).flatten()
lstm_pred_proba = lstm_model.predict(X_test_pad).flatten()
lstm_acc = accuracy_score(y_test, lstm_pred)
lstm_auc = roc_auc_score(y_test, lstm_pred_proba)3.4 模型评估
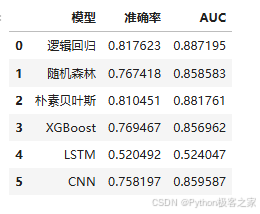
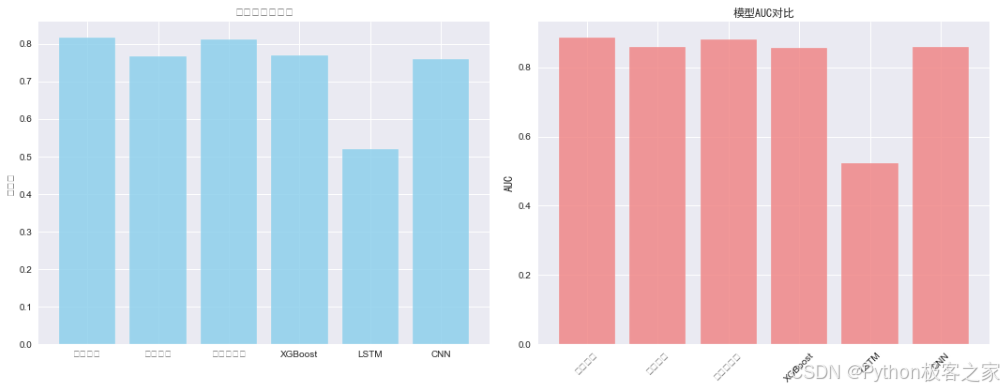
使用 准确率 (Accuracy) 和 AUC (Area Under Curve) 作为主要评估指标。实验结果显示,逻辑回归 在机器学习模型中表现出色,而CNN在深度学习模型中也取得了具有竞争力的结果。最佳模型被保存为文件,用于Web系统部署。
4. Web系统功能详解
Web系统 (app.py) 提供了完整的功能模块:
4.1 系统首页

4.1 用户认证系统
- 注册与登录 :用户可以注册账号并登录系统。密码使用
werkzeug.security进行哈希加密存储,保障安全性。 - 用户会话管理 :使用
Flask-Login管理用户会话,实现登录状态保持和权限控制(如访问预测页面需登录)。
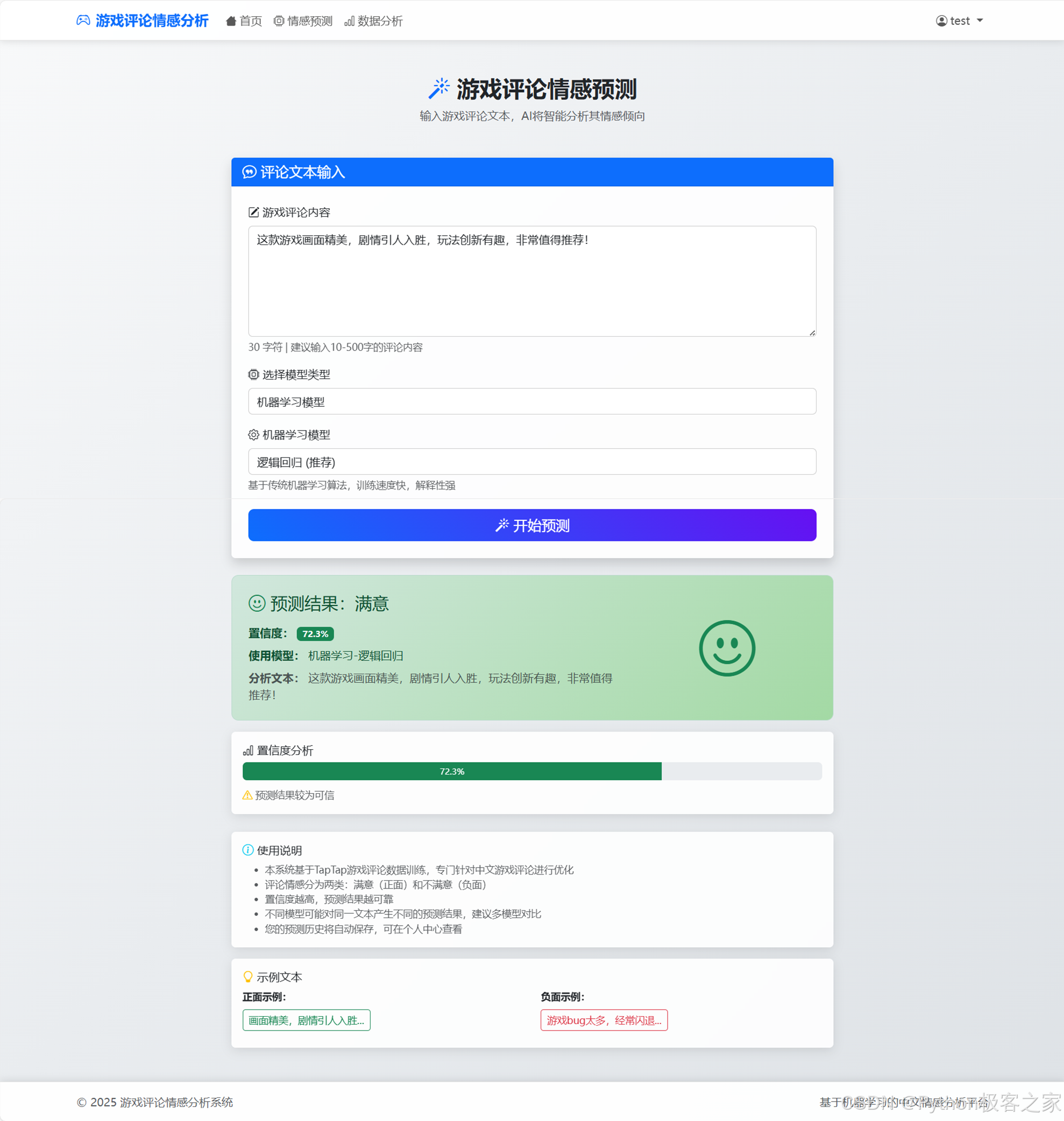
4.2 情感预测模块
- 多模型支持:用户可以在前端自由选择使用"机器学习模型"(逻辑回归、随机森林等)或"深度学习模型"(LSTM、CNN)进行预测。
- 实时分析:后端实时接收文本,调用加载的预训练模型进行推理,返回情感倾向(满意/不满意)和置信度。
- 历史记录:登录用户的预测记录会自动保存到数据库 (PredictionHistory 表),方便后续查看。
4.3 数据分析模块
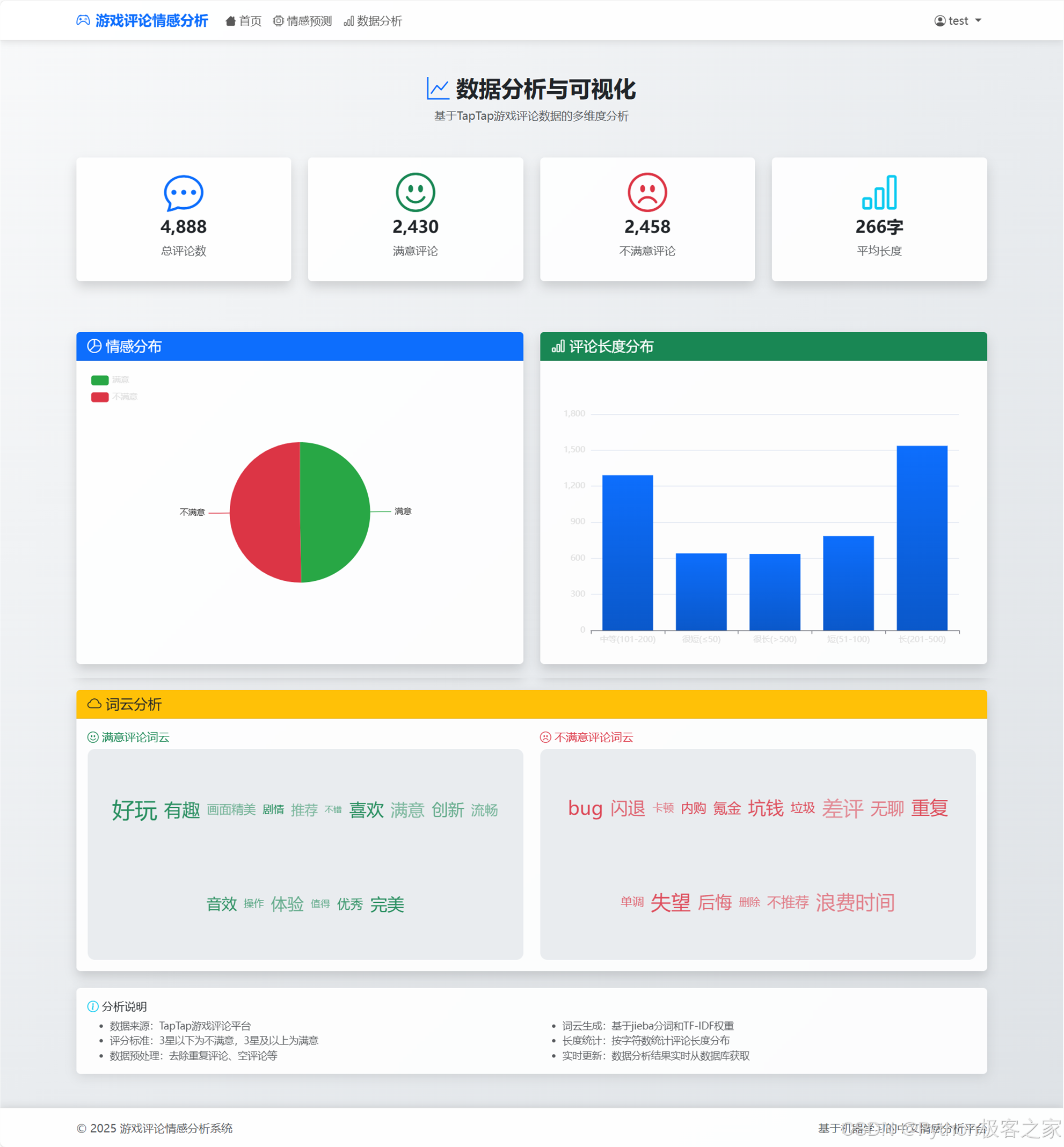
- 可视化看板:提供数据分析页面,展示数据集的统计信息。
- 图表展示:利用 ECharts 展示评论情感分布(饼图)、评论长度分布(直方图)等,帮助用户了解整体舆情。
4.4 个人中心
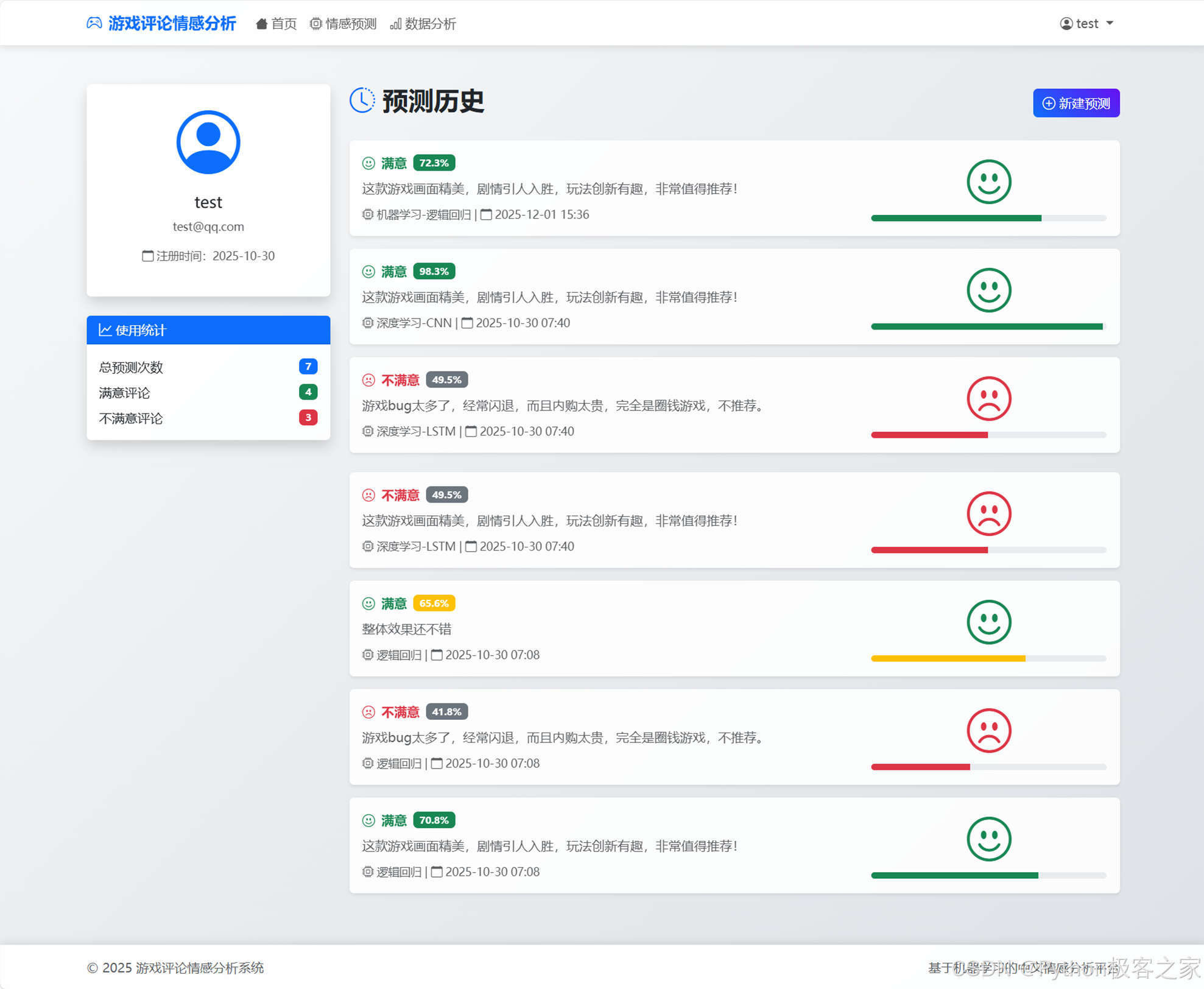
- 历史记录查看:用户可以在个人中心查看自己最近的10条预测记录,包括输入文本、预测结果、置信度和使用的模型。
5. 总结与展望
本项目成功构建了一个端到端的游戏评论情感分析系统,涵盖了从数据处理、算法建模到Web应用开发的完整流程。系统不仅支持多种先进的NLP模型,还提供了友好的用户交互界面。
未来改进方向:
- 模型优化:引入BERT等预训练语言模型,进一步提升情感分类的准确率。
- 细粒度情感分析:从二分类(满意/不满意)扩展到多分类(如评分预测)或方面级情感分析(如针对画面、玩法、剧情分别分析)。
- 实时爬虫集成:增加爬虫模块,支持实时抓取指定游戏的最新评论进行监控。
本文基于本科毕业设计项目整理,旨在分享NLP技术在游戏评论分析领域的应用实践。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取 认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
