引言
C++11(曾被称为 C++0x)是 C++ 编程语言的一次里程碑式的更新。它不仅仅是一次简单的功能增加,更是将 C++ 带入现代编程语言行列的关键一步。它引入了大量的新特性,旨在使 C++ 更易于使用、更高效、更安全。如果你还在使用旧版本的 C++,那么 C++11 将为你打开一扇新世界的大门。
本文将从理论到使用代码进行验证的方式来全面讲解c++11中的常见知识:
1、auto关键字:
在 C++11 之前,我们必须显式地写出每一个变量的类型。auto 关键字让编译器在编译期根据初始化表达式自动推导变量类型。
下面将用代码来为大家演示这个关键字的用法:
cpp
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int>vc;
vc.push_back(1);
vc.push_back(2);
vc.push_back(3);
vc.push_back(4);
vc.push_back(5);
auto e = vc[0];
cout << e << endl;
}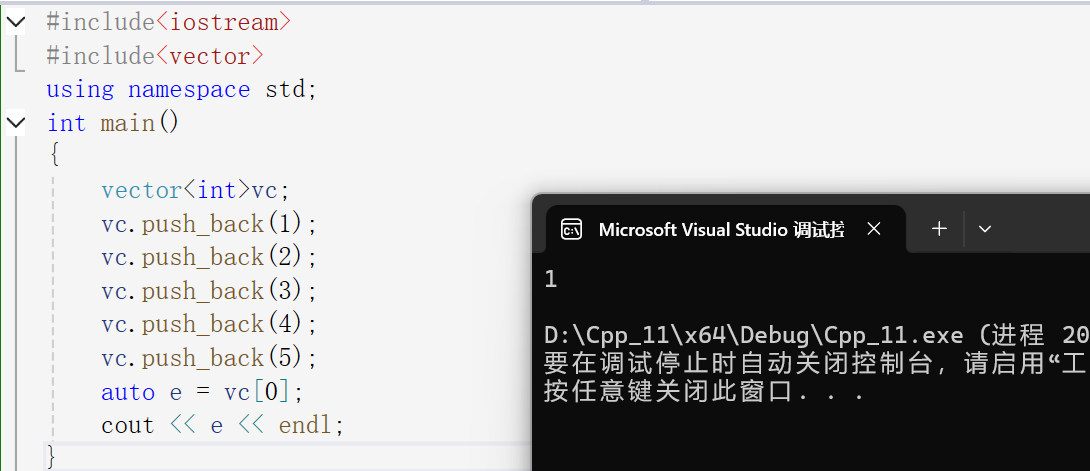
这个代码较为简单,是为了让大家更好地理解auto关键字的作用,在这里,auto会自动退出这个e是int类型的值,所以这里的打印结果与我们所推测的一致,这间接地证明了auto的"自动性"。
auto会忽略顶层const,需要显式添加数组类型推导为指针,需要特别注意
在模板编程中特别有用,能显著简化代码
再来个验证示例:
cpp
#include<iostream>
#include <vector>
#include <map>
#include <string>
using namespace std;
int main()
{
// 基本类型推导
auto i = 42; // int
auto d = 3.14; // double
auto s = "hello"; // const char*
// 复杂类型推导
std::vector<map<string, int>> complex_data;
auto it = complex_data.begin(); // 推导出迭代器类型
cout<< i << endl << d << endl << s << endl;
return 0;
}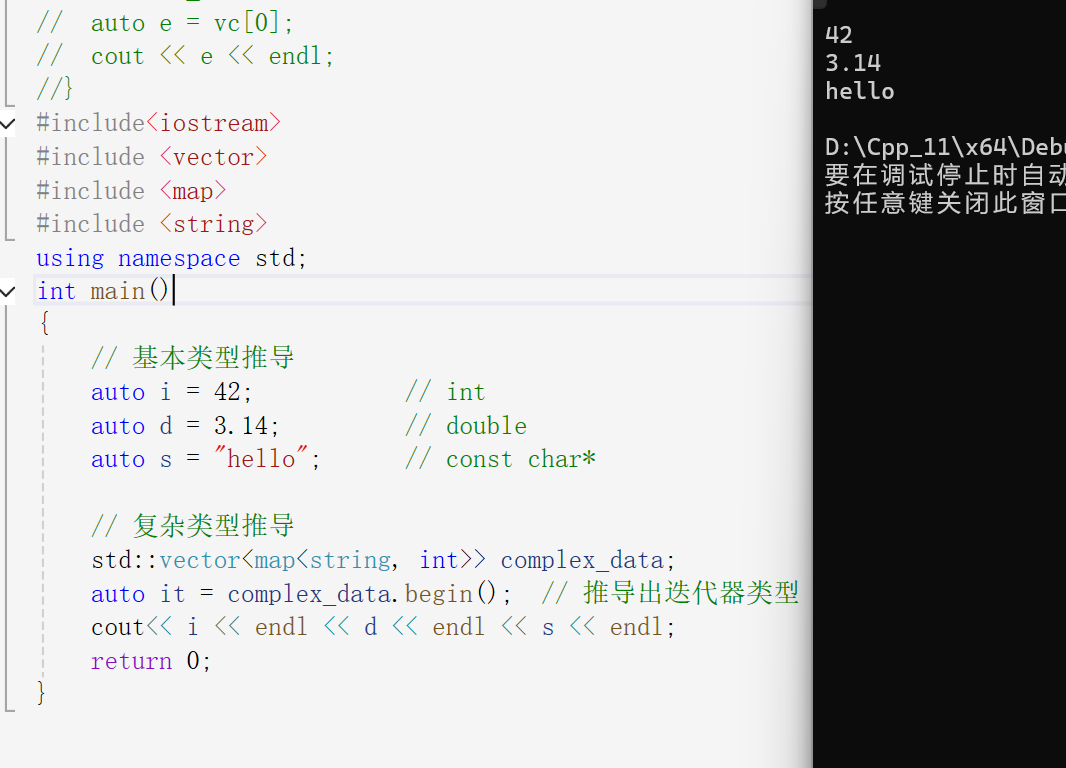
上面的例子再次向我们证明了auto的具有自动推导的性质。
下面的代码我把头文件全放在最前面了就不再写头文件了。
2、范围for:
为什么要用范围循环?
传统 for 循环需要处理索引或迭代器,范围 for 循环让遍历容器变得简单直观。
cpp
int main()
{
vector<int> scores = { 85, 92, 78, 96, 88 };
// 传统 for 循环
cout << "传统 for 循环: ";
for (int i = 0; i < scores.size(); i++) {
cout << scores[i] << " ";
}
cout << endl;
// 范围 for 循环(值拷贝)
cout << "范围 for 循环(值): ";
for (auto score : scores) {
cout << score << " ";
}
cout << endl;
// 范围 for 循环(引用,可修改)
cout << "范围 for 循环(引用): ";
for (auto& score : scores) {
score += 1; // 修改原数据
cout << score << " ";
}
cout << endl;
// 验证修改是否生效
cout << "修改后的数据: ";
for (auto score : scores) {
cout << score << " ";
}
cout << endl;
return 0;
}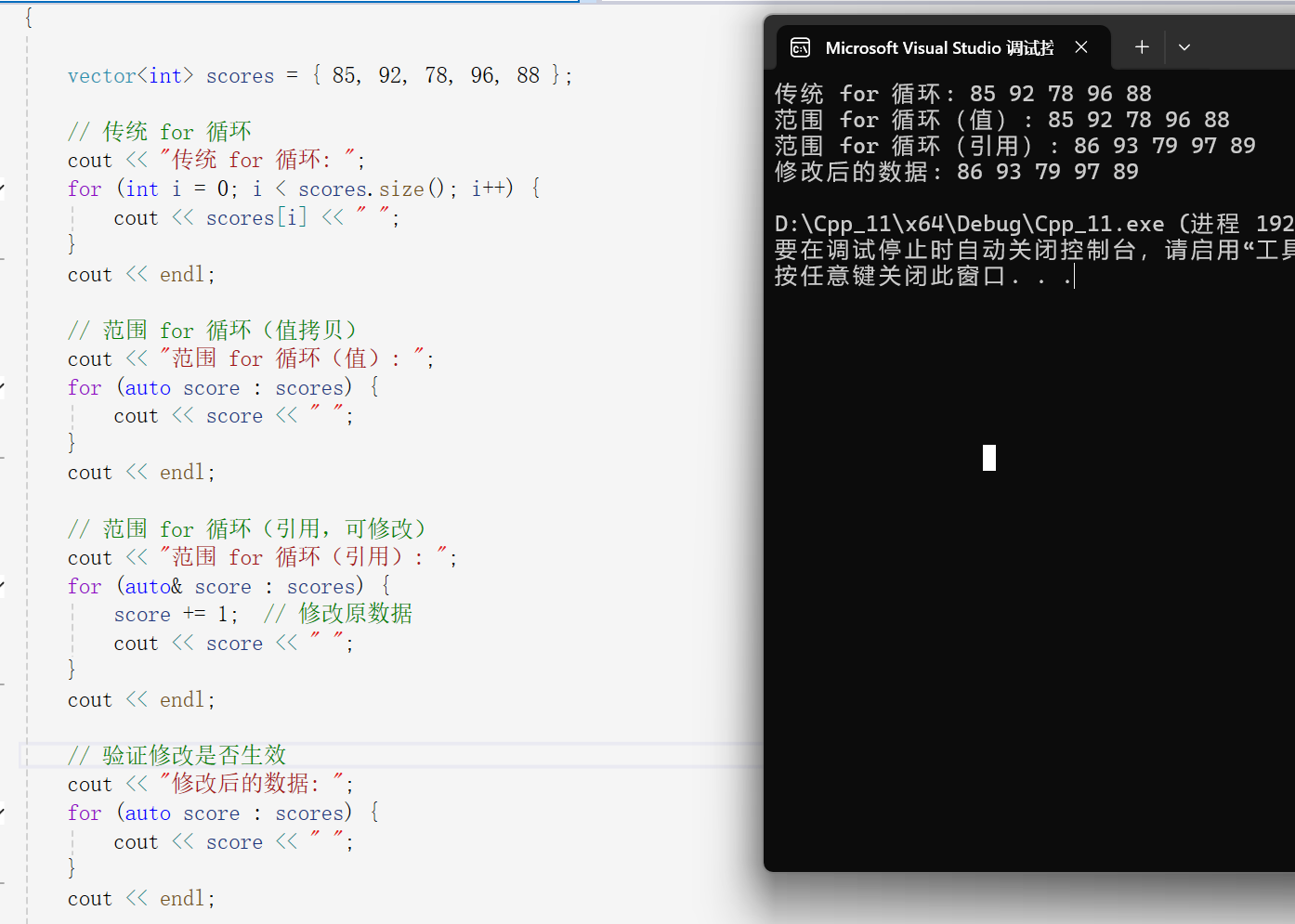
其实说白了,使用范围for的好处就是比传统的for循环会方便很多。
3、 lambda 表达式:
laxmbda函数语法:
[捕获列表] (参数列表) -> 返回类型 { 函数体 }b捕获列表
捕获列表:该列表总是出现在lambda函数的开始位置,编译器根据 来判断下面的代码是否为lambda函数,捕获列表能捕获上下文中的变量提供lambda函数使用。
参数列表:与普通函数的参数列表一致,如果不需要参数传递,也可以同()一起省略。
返回值类型:用追踪返回类型形式声明函数的返回值类型,没有返回值时可省略。
函数体:在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
[] - 不捕获任何变量
[=] - 按值捕获所有变量
[&] - 按引用捕获所有变量
[a, &b] - 按值捕获a,按引用捕获b
首先,先来一个最简单,无参的lambda表达式:
cpp
int main()
{
[]()
{
cout << "你好,我是lambda表达式" << endl;
}();
}
上面的代码就是一个最简单的lambda表达式,省略了返回值和参数。这个代码只会打印花括号里面的内容。
接着往下看:
cpp
int main() {
auto test_lambda = []()
{
cout << "我正在测试lambda" << endl;
};
test_lambda();
test_lambda();
}
上面的代码说明了一个需要注意的问题:lambda表达式是可以重复调用的,首先我们使用auto帮助我们进行了保存,然后在保存了之后进行重复调用。
再来个案例:
cppint main() { int a = 5, b = 10; //按值捕获 auto test_lambda1 = [a, b]() { return a + b; // 使用捕获时的值 }; //按引用捕获 auto test_lambda2 = [&a, &b]() { a = 10; return a + b; }; cout << "按值捕获结果" << test_lambda1() << endl; cout << "按引用捕获结果" << test_lambda2() << endl; cout << "修改之后的a:" << a << endl;//a被修改为10 }

4、override与final关键字:
cpp
class Base
{
public:
virtual void show(int x)
{
cout << "Base: " << x<<endl;
}
};
class Derived : public Base
{
public:
// 想重写但写错了 - 参数类型不对
virtual void show(double x)// 这是新函数,不是重写!
{
cout << "Derived: " << x << endl;
}
};
int main()
{
Derived obj;
Base* ptr = &obj;
ptr->show(10); // 输出 "Base: x is 10",而不是期望的 "Derived: 10"
}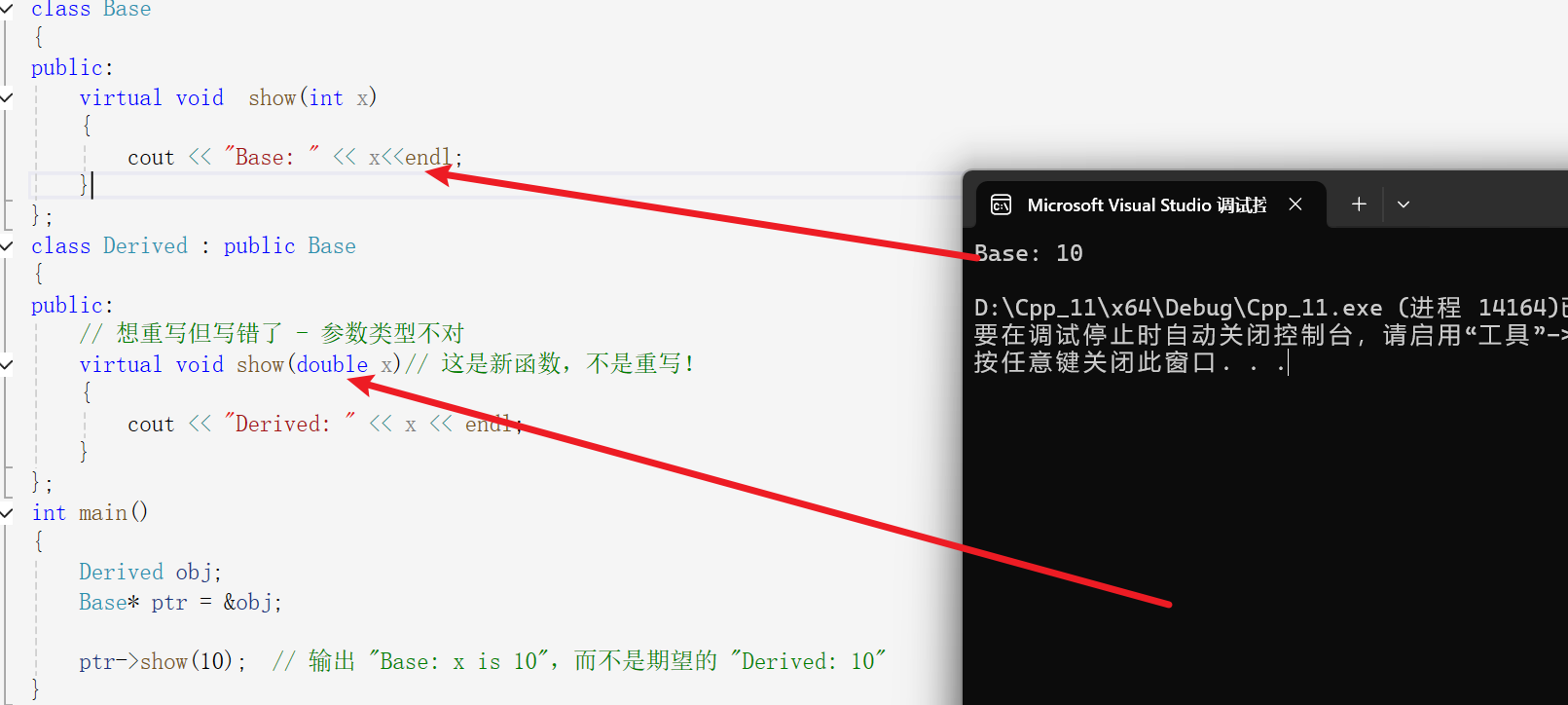
下面的箭头所指向那里并没有对父类的成员函数进行重写,而是相当于定义了一个新函数所以这里并没有形成多态,所以这里调用的依然是父类的show函数,所以会输出Base:10。
而为了避免发生类似于这种情况,c++11引入了一个新的关键字override:
cpp
class Base
{
public:
virtual void show(int x)
{
cout << "Base: " << x<<endl;
}
};
class Derived : public Base
{
public:
virtual void show(int x)override
{
cout << "Derived: " << x << endl;
}
//// 想重写但写错了 - 参数类型不对
//virtual void show(double x)override// 这是新函数,不是重写!
//{
// cout << "Derived: " << x << endl;
//}
};
int main()
{
Derived obj;
Base* ptr = &obj;
ptr->show(10); // 输出 "Base: x is 10",而不是期望的 "Derived: 10"
}

所以override的作用就很轻松地总结出来了:
告诉编译器"我要开始重写虚函数了"
如果签名不匹配,编译器会报错。
防止拼写错误和参数错误。
换句话说这个override就像是我们的小助手一样,它会一直检查我们写的代码,如果出错了它会直接报错,没有出错才能通过编译!
final关键字:
1、用来表示该类不能被继承,如果继承,编译器会报错
2、这个类可以被继承,但它是继承类的终点,也就是说最后到这里了,不能继续有别的类去继承它了,下面将用代码来给大家展示一下这两个特性:
cpp
// 这个类不能被继承
class FinalClass final {
public:
void show() {
cout << "FinalClass" << endl;
}
};
// class Child : public FinalClass { }; // 错误!不能继承final类
class NormalClass {
public:
virtual void func() {
cout << "NormalClass"<<endl;
}
};
// 这个类可以被继承,但它是继承链的终点
class LastClass final : public NormalClass {
public:
void func() override {
cout << "LastClass"<<endl;
}
};
// class Further : public LastClass { }; // 错误!LastClass是final的
int main() {
FinalClass f;
f.show();
LastClass l;
l.func();
return 0;
}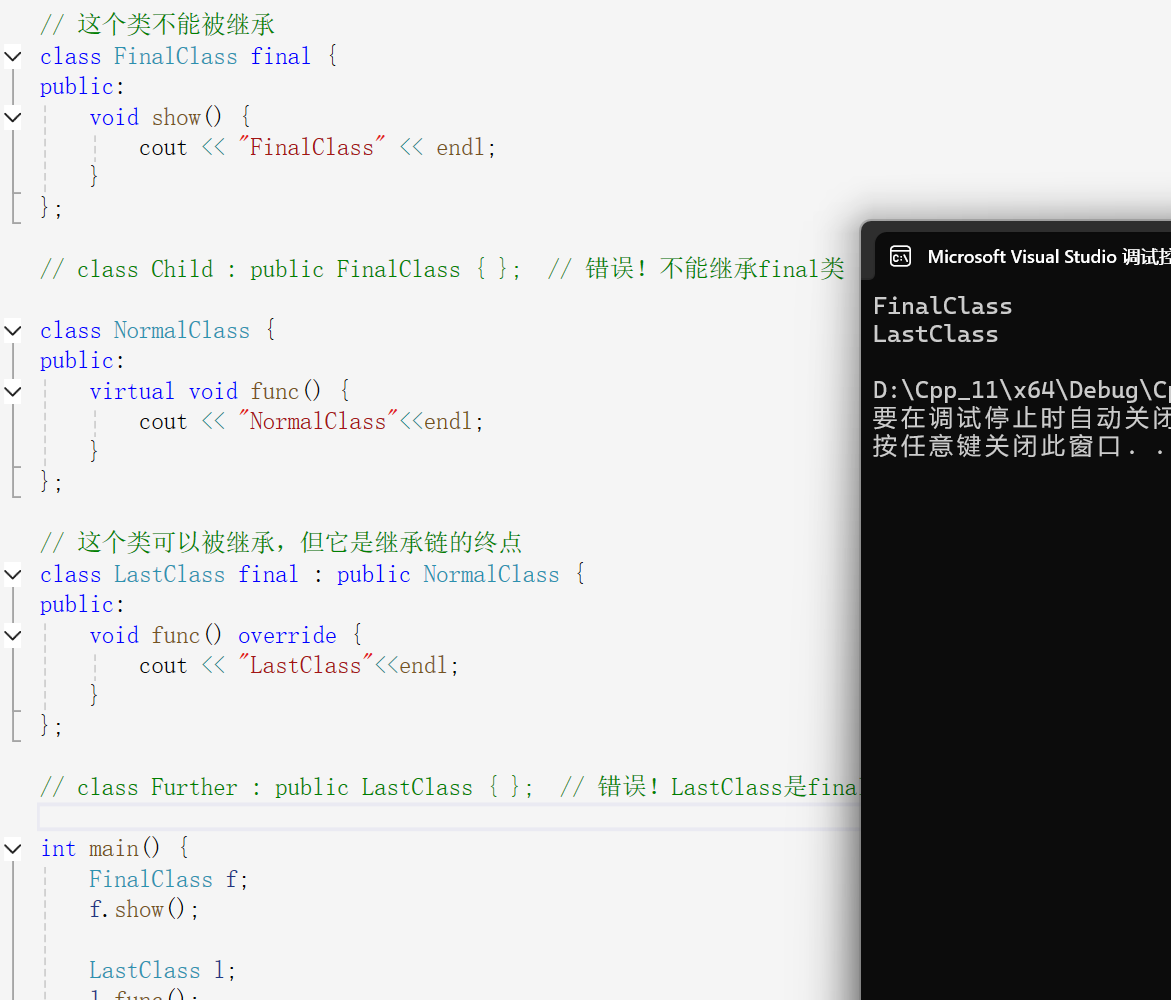
这就充分证明了在类名后面加
final,表示这个类是"最终版本"其他类不能从这个类继承如果尝试继承,编译器会报错,其次
LastClass继承了NormalClass,但自己是final这意味着继承到LastClass就结束了,不能再从LastClass派生出新的类
总结:final用法:
直接在类名后面加上final这个关键字,这样就可以禁止其他类来继承这个类。
它有如下优点:
1、防止误用。
2、编译器检查,会更安全。
5、NULL与nullptr:
- NULL的问题
在C++11之前,我们使用NULL表示空指针,但NULL实际上有很多问题:
来看这段代码:
cpp
#include <iostream>
using namespace std;
void func(int x) {
cout << "调用整型版本: " << x << endl;
}
void func(char* ptr) {
if (ptr == nullptr) {
cout << "调用指针版本: 空指针" << endl;
} else {
cout << "调用指针版本: " << ptr << endl;
}
}
int main() {
func(0); // 明确调用整型版本
func(NULL); // 问题:调用哪个版本?
return 0;
}NULL在c++中通常定义为0,这导致函数重载时可以出现歧义,编译器不知道应该调用整型版本还是指针版本。
基于上面这个问题,c++引出了一个新的关键字用来表示空指针:nullptr
cpp
#include <iostream>
using namespace std;
void func(int x) {
cout << "调用整型版本: " << x << endl;
}
void func(char* ptr) {
if (ptr == nullptr) {
cout << "调用指针版本: 空指针" << endl;
} else {
cout << "调用指针版本: " << ptr << endl;
}
}
int main() {
func(0); // 调用整型版本
func(nullptr); // 明确调用指针版本
// 现在没有歧义了!
return 0;
}在使用了nullptr这个关键字之后,就相当于我们告诉编译器,这是一个空指针,你去调用指针版本的函数就行了,下面来看打印结果:
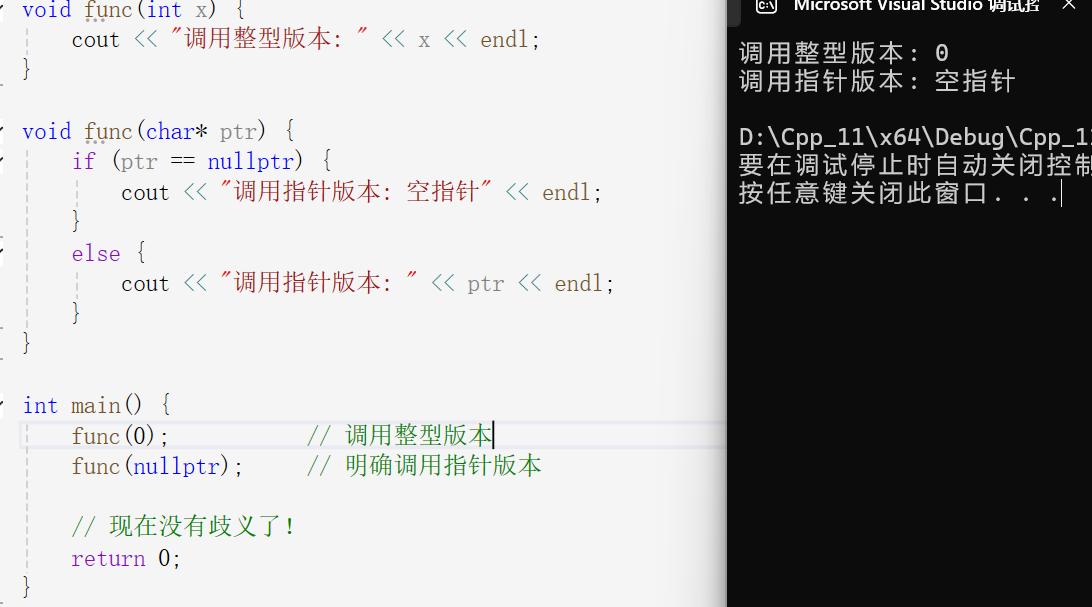
所以在c++11之后,如果想要表示空指针,尽量使用nullptr而不是NULL。
6、左值和右值与左值引用和右值引用:
在c/c++里面有一个及其容易使人混淆的一个概念就是左值与右值,何为左值?何为右值,下面我将详细叙述这一点:
所谓的左值与右值并不是说在方向上的左与右,或者说是表达式的左与右,而需要通俗地将他们理解为左值就是一个具有持久化的变量,而右值通常是一个临时变量。
那么所以:
左值与右值的本质区别不是"位置",而是"生命周期和持久性"。
换言之,所谓的左值就像是我们自己家的筷子( 左值),需要长期使用,那么我们在店外卖的时候可能因为自己家的筷子没有及时刷而使用一次性筷子,那么这个一次性筷子就相当于一个右值,只是临时使用它,使用完就扔了(类似于右值)。此比喻仅仅帮助大家理解!
cpp
int getNumber() {
return 42; // 返回值是右值 - 用完就销毁
}
int main() {
int x = 10; // x是左值 - 持久存在
int y = getNumber(); // getNumber()返回右值 - 临时结果
// 更清晰的例子
string name = "Alice"; // name是左值 - 持久对象
string temp = name + " Smith"; // (name + " Smith")是右值 - 临时字符串
cout << "name: " << name << endl; // name仍然存在
cout << (name + " Smith") << endl; //输出后销毁
return 0;
}左值:
1、有名字的变量或对象。
2、有明确的内存地址
3、可以出现在赋值语句的左边
4、生命周期跨越当前表达式。
右值:
1、临时的,无名的对象。
2、通常没有独立的内存地址。
3、只能出现在赋值语句的右边。
4、生命周期仅限于当前表达式(执行后就销毁了)。
cpp
int main() {
int x = 100;
// 左值引用 - 绑定到左值
int& ref1 = x; // 正确:x是左值
// int& ref2 = 100; // 错误:不能绑定到右值
ref1 = 200; // 通过引用修改x的值
cout << "x = " << x << endl; // 输出200
// const左值引用可以绑定到右值
const int& ref3 = 100; // 正确
const int& ref4 = x; // 也正确
int&& ref5 = x; //这个会报错
return 0;
//总结:
//1、左值引用不能绑定到右值,如果想要绑定必须加const
//2、右值绑定不能绑定到左值
}
右值引用无法绑定到左值,只能绑定右值。左值引用可以绑定左值但是如果想要绑定到右值必须加const。
右值引用的特点:
1、使用&&符号声明
2、只能绑定到右值
3、用于实现语移动语义和完美转发
4、可以延长临时对象的生命周期
5、右值引用变量本身是左值(因为它有名字和地址)
6、使用
std::move()可以将左值转换为右值引用
诸如智能指针这种,我会在后续文章中介绍,本篇博文至此结束,如有错误可在评论区进行指出,本人会及时进行更正!