LDA线性判别
PCA主成分分析
t-sne降维
| 对比维度 | SVD(奇异值分解,PCA 核心实现手段) | PCA(主成分分析) | t-SNE(t - 分布随机邻域嵌入) | LDA(线性判别分析) |
|---|---|---|---|---|
| 核心思想 | 对数据矩阵做正交分解(A=UΣVᵀ),取前 k 个奇异值对应的 V 矩阵列向量,本质是 PCA 的数学实现核心(避免协方差矩阵计算的数值不稳定) | 寻找数据的线性投影方向(主成分),最大化投影后数据的方差,保留全局关键信息,剔除冗余 | 基于高维空间中样本的 pairwise 距离,通过 KL 散度最小化,在低维空间中保留局部邻域关系 | 寻找线性投影方向,最大化类间距离、最小化类内距离,提升分类任务的可分性 |
| 算法类型 | 线性降维、无监督学习 | 线性降维、无监督学习 | 非线性降维、无监督学习(流形学习) | 线性降维、有监督学习(依赖类别标签) |
| 是否需要标签 | 否(无监督,仅依赖数据本身) | 否(无监督,仅依赖数据本身) | 否(无监督,仅依赖数据本身) | 是(必须输入类别标签,用于计算类间 / 类内散度矩阵) |
| 降维目标 | 与 PCA 一致:保留数据全局方差,去除特征冗余(数学层面更稳定) | 保留数据全局方差,去除特征冗余,简化数据结构 | 保留数据局部邻域结构,优化低维空间的可视化效果 | 提升数据的类间可分性,为后续分类模型提供更优的特征表示 |
| 输出维度 | 自定义 k(k≤min (样本数 n, 特征数 p)),常用 k=2/3(可视化)或根据奇异值贡献率确定 | 自定义 k(k≤min (n,p)),常用 "累计方差贡献率≥85%" 确定 k,或 k=2/3(可视化) | 几乎仅用于 2/3 维(可视化场景),k>3 无实际意义 | k≤类别数 c-1(数学约束:类间散度矩阵秩≤c-1),常用 k=2/3(可视化)或 k=c-1(建模) |
| 计算复杂度 | 标准 SVD:O (n²p)(n 为样本数,p 为特征数);截断 SVD(PCA 常用):O (nkp)(k 为输出维度),效率高于协方差矩阵 PCA | 基于协方差矩阵:O (p³);基于 SVD 实现:O (nkp),大规模数据下推荐用 SVD 版本 | O (n²)(n 为样本数),样本数 > 1 万时速度显著变慢 | O (p³ + p²c)(c 为类别数),样本数影响小,主要依赖特征数 p 和类别数 c |
| 对新数据转换 | 支持:通过 PCA 训练得到的 V 矩阵(奇异向量),直接对新数据做线性投影(新数据 ×V :, :k) | 支持:通过训练得到的主成分投影矩阵,直接对新数据做线性转换(新数据 - 均值 × 投影矩阵) | 不支持:无固定投影矩阵,新数据需重新加入全部数据一起训练,无法增量更新 | 支持:通过训练得到的判别投影矩阵,直接对新数据做线性转换 |
| 对数据缩放敏感性 | 高:方差大的特征会主导奇异值,需先标准化(StandardScaler)或归一化 | 高:方差大的特征会主导主成分,必须先标准化(StandardScaler) | 低:对特征尺度不敏感,无需强制标准化(但异常值仍会影响距离计算) | 高:方差大的特征会主导投影方向,需先标准化(StandardScaler) |
| 参数敏感性 | 低:仅需指定输出维度 k,或通过奇异值贡献率自动选择,无其他关键参数 | 低:仅需指定输出维度 k 或累计方差贡献率,无其他敏感参数 | 高:核心参数perplexity(推荐 5-50)影响邻域大小,过小易过拟合、过大模糊局部结构;学习率也需调优 |
低:几乎无敏感参数,仅需指定输出维度 k(≤c-1),无需复杂调参 |
| 可解释性 | 中 - 高:投影方向(V 矩阵列向量)是原始特征的线性组合,可通过特征权重分析主成分的物理含义(与 PCA 一致) | 高:主成分是原始特征的线性组合,可通过 "特征贡献度" 解释每个主成分的含义(如第一主成分 = 0.8× 身高 + 0.7× 体重) | 极低:非线性映射无明确物理意义,低维坐标仅用于可视化,无法关联原始特征 | 中 - 高:投影方向与类别相关,可解释为 "最能区分不同类别的特征组合"(如 LDA 投影后,同类样本聚集) |
| 优点 | 1. 数值稳定性优于直接计算协方差矩阵的 PCA;2. 可处理稀疏 / 高维数据;3. 兼顾降维和去噪;4. 计算效率高 | 1. 线性变换稳定、计算快;2. 可解释性强;3. 支持增量学习和新数据转换;4. 兼具去噪功能 | 1. 非线性数据可视化效果极佳(远超 PCA/LDA);2. 能捕捉数据局部聚类结构;3. 对特征尺度不敏感 | 1. 为分类任务量身定制,降维后分类效果更优;2. 计算快、参数简单;3. 可解释性较强;4. 支持新数据转换 |
| 缺点 | 1. 仅能处理线性关系;2. 对异常值敏感;3. 无法捕捉非线性结构 | 1. 仅能处理线性关系,非线性数据效果差;2. 对异常值敏感;3. 全局方差最大化可能忽略重要局部结构 | 1. 计算复杂度 O (n²),不支持大数据(n>1 万需采样);2. 不支持新数据转换;3. 可解释性差;4. 训练时间长 | 1. 仅适用于分类任务,无法用于无监督场景;2. 仅能处理线性关系;3. 输出维度受类别数限制(k≤c-1);4. 对类别不平衡敏感 |
| 适用场景 | 1. PCA 的高效实现(大规模高维数据降维);2. 稀疏数据降维(如文本 TF-IDF 矩阵);3. 数据去噪;4. 建模前预处理 | 1. 通用降维(分类 / 回归任务预处理);2. 高维数据去噪;3. 数据可视化(线性数据);4. 特征冗余剔除 | 1. 高维非线性数据可视化(如单细胞数据、图像特征、文本嵌入);2. 聚类结果展示;3. 探索性数据分析(EDA) | 1. 分类任务的特征预处理(如文本分类、图像识别、生物特征分类);2. 带标签数据的可视化;3. 类别可分性优化 |
| 核心需求 | 优先选择算法 | 排除算法 | 关键理由 |
|---|---|---|---|
| 无标签数据、通用降维 / 预处理 | PCA(或 SVD 实现) | LDA、t-SNE | PCA 无监督、计算快、可解释,适合建模前的特征预处理(如 XGBoost/LightGBM 输入) |
| 分类任务、带标签数据降维 | LDA | t-SNE | LDA 利用标签信息优化类间可分性,降维后分类模型效果更优 |
| 高维非线性数据可视化 | t-SNE(小数据)/UMAP(大数据) | PCA、LDA | PCA/LDA 线性变换无法捕捉非线性结构,可视化效果差;t-SNE 局部结构展示清晰 |
| 大规模数据(n>10 万) | PCA(SVD 实现)/LDA | t-SNE | t-SNE O (n²) 复杂度无法处理大数据,PCA/LDA 计算效率呈线性增长 |
| 需保留原始特征含义 / 可解释性 | PCA/LDA | t-SNE | t-SNE 非线性映射无物理意义,PCA/LDA 可关联原始特征 |
| 处理异常值较多的数据 | t-SNE | PCA、LDA、SVD | PCA/LDA 对异常值敏感(方差易被异常值主导),t-SNE 相对稳健 |
python
# 先运行之前预处理好的代码
import pandas as pd
import pandas as pd #用于数据处理和分析,可处理表格数据。
import numpy as np #用于数值计算,提供了高效的数组操作。
import matplotlib.pyplot as plt #用于绘制各种类型的图表
import seaborn as sns #基于matplotlib的高级绘图库,能绘制更美观的统计图形。
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('D:\python60-days-challenge-master\heart.csv') #读取数据
from sklearn.model_selection import train_test_split
X = data.drop(['target'], axis=1) # 特征,axis=1表示按列删除
y = data['target'] # 标签
# 按照8:2划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
# --- 1. 默认参数的随机森林 ---
# 评估基准模型,这里确实不需要验证集
print("--- 1. 默认参数随机森林 (训练集 -> 测试集) ---")
import time # 这里介绍一个新的库,time库,主要用于时间相关的操作,因为调参需要很长时间,记录下会帮助后人知道大概的时长
start_time = time.time() # 记录开始时间
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train) # 在训练集上训练
rf_pred = rf_model.predict(X_test) # 在测试集上预测
end_time = time.time() # 记录结束时间
print(f"训练与预测耗时: {end_time - start_time:.4f} 秒")
print("\n默认随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred))
print("默认随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred))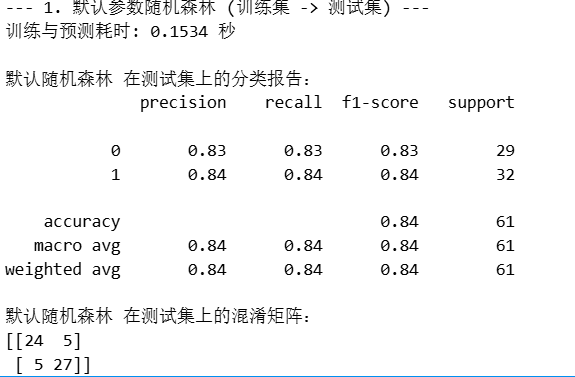
python
# 确保这些库已导入,你的原始代码中可能已经包含了部分
import time
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler # 特征缩放
from sklearn.decomposition import PCA # 主成分分析
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # 线性判别分析
# UMAP 需要单独安装: pip install umap-learn
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
# 你的 X_train, X_test, y_train, y_test 应该已经根据你的代码准备好了
# 我们假设你的随机森林模型参数与基准模型一致,以便比较降维效果
# rf_params = {'random_state': 42} # 如果你的基准模型有其他参数,也在这里定义
# 为了直接比较,我们使用默认的 RandomForestClassifier 参数,除了 random_state
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np # 确保numpy导入
# 假设 X_train, X_test, y_train, y_test 已经准备好了
print(f"\n--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) ---")
# 步骤 1: 特征缩放
scaler_pca = StandardScaler()
X_train_scaled_pca = scaler_pca.fit_transform(X_train)
X_test_scaled_pca = scaler_pca.transform(X_test) # 使用在训练集上fit的scaler
# 步骤 2: PCA降维
# 选择降到10维,或者你可以根据解释方差来选择,例如:
pca_expl = PCA(random_state=42)
pca_expl.fit(X_train_scaled_pca)
cumsum_variance = np.cumsum(pca_expl.explained_variance_ratio_)
n_components_to_keep_95_var = np.argmax(cumsum_variance >= 0.95) + 1
print(f"为了保留95%的方差,需要的主成分数量: {n_components_to_keep_95_var}")--- 2. PCA 降维 + 随机森林 (不使用 Pipeline) --- 为了保留95%的方差,需要的主成分数量: 12
python
# 我们测试下降低到10维的效果
n_components_pca = 10
pca_manual = PCA(n_components=n_components_pca, random_state=42)
X_train_pca = pca_manual.fit_transform(X_train_scaled_pca)
X_test_pca = pca_manual.transform(X_test_scaled_pca) # 使用在训练集上fit的pca
print(f"PCA降维后,训练集形状: {X_train_pca.shape}, 测试集形状: {X_test_pca.shape}")
start_time_pca_manual = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_pca = RandomForestClassifier(random_state=42)
rf_model_pca.fit(X_train_pca, y_train)
# 步骤 4: 在测试集上预测
rf_pred_pca_manual = rf_model_pca.predict(X_test_pca)
end_time_pca_manual = time.time()
print(f"手动PCA降维后,训练与预测耗时: {end_time_pca_manual - start_time_pca_manual:.4f} 秒")
print("\n手动 PCA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_pca_manual))
print("手动 PCA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_pca_manual))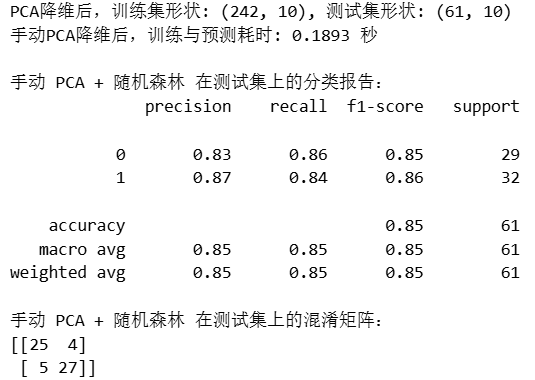
python
from sklearn.manifold import TSNE
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
import matplotlib.pyplot as plt # 用于可选的可视化
import seaborn as sns # 用于可选的可视化
# 假设 X_train, X_test, y_train, y_test 已经准备好了
# 并且你的 X_train, X_test 是DataFrame或Numpy Array
print(f"\n--- 3. t-SNE 降维 + 随机森林 ---")
print(" 标准 t-SNE 主要用于可视化,直接用于分类器输入可能效果不佳。")
# 步骤 1: 特征缩放
scaler_tsne = StandardScaler()
X_train_scaled_tsne = scaler_tsne.fit_transform(X_train)
X_test_scaled_tsne = scaler_tsne.transform(X_test) # 使用在训练集上fit的scaler
# 步骤 2: t-SNE 降维
# 我们将降维到与PCA相同的维度(例如10维)或者一个适合分类的较低维度。
# t-SNE通常用于2D/3D可视化,但也可以降到更高维度。
# 然而,降到与PCA一样的维度(比如10维)对于t-SNE来说可能不是其优势所在,
# 并且计算成本会显著增加,因为高维t-SNE的优化更困难。
# 为了与PCA的 n_components=10 对比,我们这里也尝试降到10维。
# 但请注意,这可能非常耗时,且效果不一定好。
# 通常如果用t-SNE做分类的预处理(不常见),可能会选择非常低的维度(如2或3)。
# n_components_tsne = 10 # 与PCA的例子保持一致,但计算量会很大
n_components_tsne = 2 # 更典型的t-SNE用于分类的维度,如果想快速看到结果
# 如果你想严格对比PCA的10维,可以将这里改为10,但会很慢
# 对训练集进行 fit_transform
tsne_model_train = TSNE(n_components=n_components_tsne,
perplexity=30, # 常用的困惑度值
n_iter=1000, # 足够的迭代次数
init='pca', # 使用PCA初始化,通常更稳定
learning_rate='auto', # 自动学习率 (sklearn >= 1.2)
random_state=42, # 保证结果可复现
n_jobs=-1) # 使用所有CPU核心
print("正在对训练集进行 t-SNE fit_transform...")
start_tsne_fit_train = time.time()
X_train_tsne = tsne_model_train.fit_transform(X_train_scaled_tsne)
end_tsne_fit_train = time.time()
print(f"训练集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_train - start_tsne_fit_train:.2f} 秒")
# 对测试集进行 fit_transform
# 再次强调:这是独立于训练集的变换
tsne_model_test = TSNE(n_components=n_components_tsne,
perplexity=30,
n_iter=1000,
init='pca',
learning_rate='auto',
random_state=42, # 保持参数一致,但数据不同,结果也不同
n_jobs=-1)
print("正在对测试集进行 t-SNE fit_transform...")
start_tsne_fit_test = time.time()
X_test_tsne = tsne_model_test.fit_transform(X_test_scaled_tsne) # 注意这里是 X_test_scaled_tsne
end_tsne_fit_test = time.time()
print(f"测试集 t-SNE fit_transform 完成,耗时: {end_tsne_fit_test - start_tsne_fit_test:.2f} 秒")
print(f"t-SNE降维后,训练集形状: {X_train_tsne.shape}, 测试集形状: {X_test_tsne.shape}")
start_time_tsne_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_tsne = RandomForestClassifier(random_state=42)
rf_model_tsne.fit(X_train_tsne, y_train)
# 步骤 4: 在测试集上预测
rf_pred_tsne_manual = rf_model_tsne.predict(X_test_tsne)
end_time_tsne_rf = time.time()
print(f"t-SNE降维数据上,随机森林训练与预测耗时: {end_time_tsne_rf - start_time_tsne_rf:.4f} 秒")
total_tsne_time = (end_tsne_fit_train - start_tsne_fit_train) + \
(end_tsne_fit_test - start_tsne_fit_test) + \
(end_time_tsne_rf - start_time_tsne_rf)
print(f"t-SNE 总耗时 (包括两次fit_transform和RF): {total_tsne_time:.2f} 秒")
print("\n手动 t-SNE + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_tsne_manual))
print("手动 t-SNE + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_tsne_manual))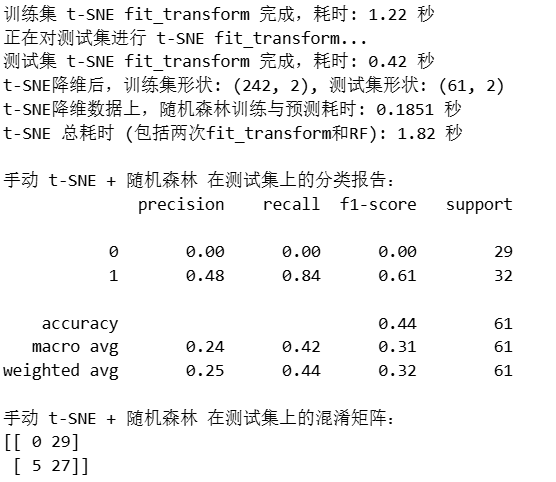
python
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
import time
import numpy as np
# 假设你已经导入了 matplotlib 和 seaborn 用于绘图 (如果需要)
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 如果需要3D绘图
import seaborn as sns
print(f"\n--- 4. LDA 降维 + 随机森林 ---")
# 步骤 1: 特征缩放
scaler_lda = StandardScaler()
X_train_scaled_lda = scaler_lda.fit_transform(X_train)
X_test_scaled_lda = scaler_lda.transform(X_test) # 使用在训练集上fit的scaler
# 步骤 2: LDA 降维
n_features = X_train_scaled_lda.shape[1]
if hasattr(y_train, 'nunique'):
n_classes = y_train.nunique()
elif isinstance(y_train, np.ndarray):
n_classes = len(np.unique(y_train))
else:
n_classes = len(set(y_train))
max_lda_components = min(n_features, n_classes - 1)
# 设置目标降维维度
n_components_lda_target = 10
if max_lda_components < 1:
print(f"LDA 不适用,因为类别数 ({n_classes})太少,无法产生至少1个判别组件。")
X_train_lda = X_train_scaled_lda.copy() # 使用缩放后的原始特征
X_test_lda = X_test_scaled_lda.copy() # 使用缩放后的原始特征
actual_n_components_lda = n_features
print("将使用缩放后的原始特征进行后续操作。")
else:
# 实际使用的组件数不能超过LDA的上限,也不能超过我们的目标(如果目标更小)
actual_n_components_lda = min(n_components_lda_target, max_lda_components)
if actual_n_components_lda < 1: # 这种情况理论上不会发生,因为上面已经检查了 max_lda_components < 1
print(f"计算得到的实际LDA组件数 ({actual_n_components_lda}) 小于1,LDA不适用。")
X_train_lda = X_train_scaled_lda.copy()
X_test_lda = X_test_scaled_lda.copy()
actual_n_components_lda = n_features
print("将使用缩放后的原始特征进行后续操作。")
else:
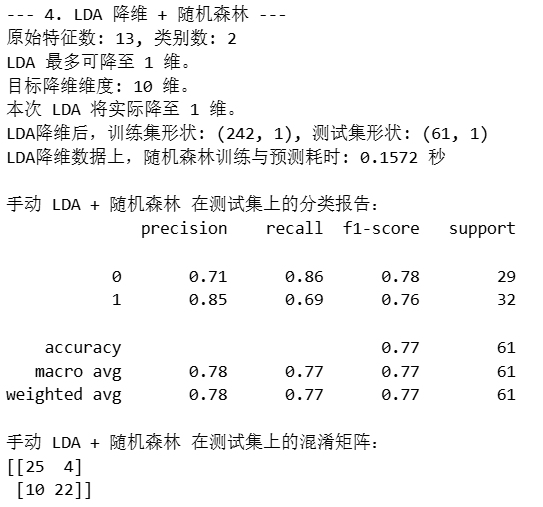
print(f"原始特征数: {n_features}, 类别数: {n_classes}")
print(f"LDA 最多可降至 {max_lda_components} 维。")
print(f"目标降维维度: {n_components_lda_target} 维。")
print(f"本次 LDA 将实际降至 {actual_n_components_lda} 维。")
lda_manual = LinearDiscriminantAnalysis(n_components=actual_n_components_lda, solver='svd')
X_train_lda = lda_manual.fit_transform(X_train_scaled_lda, y_train)
X_test_lda = lda_manual.transform(X_test_scaled_lda)
print(f"LDA降维后,训练集形状: {X_train_lda.shape}, 测试集形状: {X_test_lda.shape}")
start_time_lda_rf = time.time()
# 步骤 3: 训练随机森林分类器
rf_model_lda = RandomForestClassifier(random_state=42)
rf_model_lda.fit(X_train_lda, y_train)
# 步骤 4: 在测试集上预测
rf_pred_lda_manual = rf_model_lda.predict(X_test_lda)
end_time_lda_rf = time.time()
print(f"LDA降维数据上,随机森林训练与预测耗时: {end_time_lda_rf - start_time_lda_rf:.4f} 秒")
print("\n手动 LDA + 随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_lda_manual))
print("手动 LDA + 随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_lda_manual))