FPGA教程系列-Vivado实现低延时除法器与generate用法
其实就是用乘法器代替除法器,在matlab中编写一个1/x的查找表,然后通过值来查找对应的结果,y*1/x就相当于y/x了。
Matlab生成coe
将coe文件存在ROM中,当作查找表。
verilog
clc; clear; close all;
% --- 参数设置 ---
DEPTH = 8192; % 数据深度
WIDTH_VAL = 16383; % 分子 (2^14 - 1),决定了输出的最大值
FILENAME = 'dat_opt.coe';
% --- 计算逻辑 ---
x = 1:DEPTH; % 注意:x 不能包含 0,否则会出现 Inf
y = round(WIDTH_VAL ./ x);
% --- 检查数据范围 (防止溢出) ---
% 如果目标是写 FPGA,确保数据不超过位宽限制,这里做个简单截断保护
y(y > WIDTH_VAL) = WIDTH_VAL;
% --- 写文件 (向量化优化版) ---
fid = fopen(FILENAME, 'w');
% 写头信息
fprintf(fid, 'memory_initialization_radix=10;\n');
fprintf(fid, 'memory_initialization_vector=\n');
% 技巧:先打印前 N-1 个带逗号的数据,再打印最后一个带分号的数据
% fprintf 可以直接接受数组,按列优先顺序打印,非常快
fprintf(fid, '%d,\n', y(1:end-1));
fprintf(fid, '%d;', y(end));
fclose(fid);
% --- 绘图验证 ---
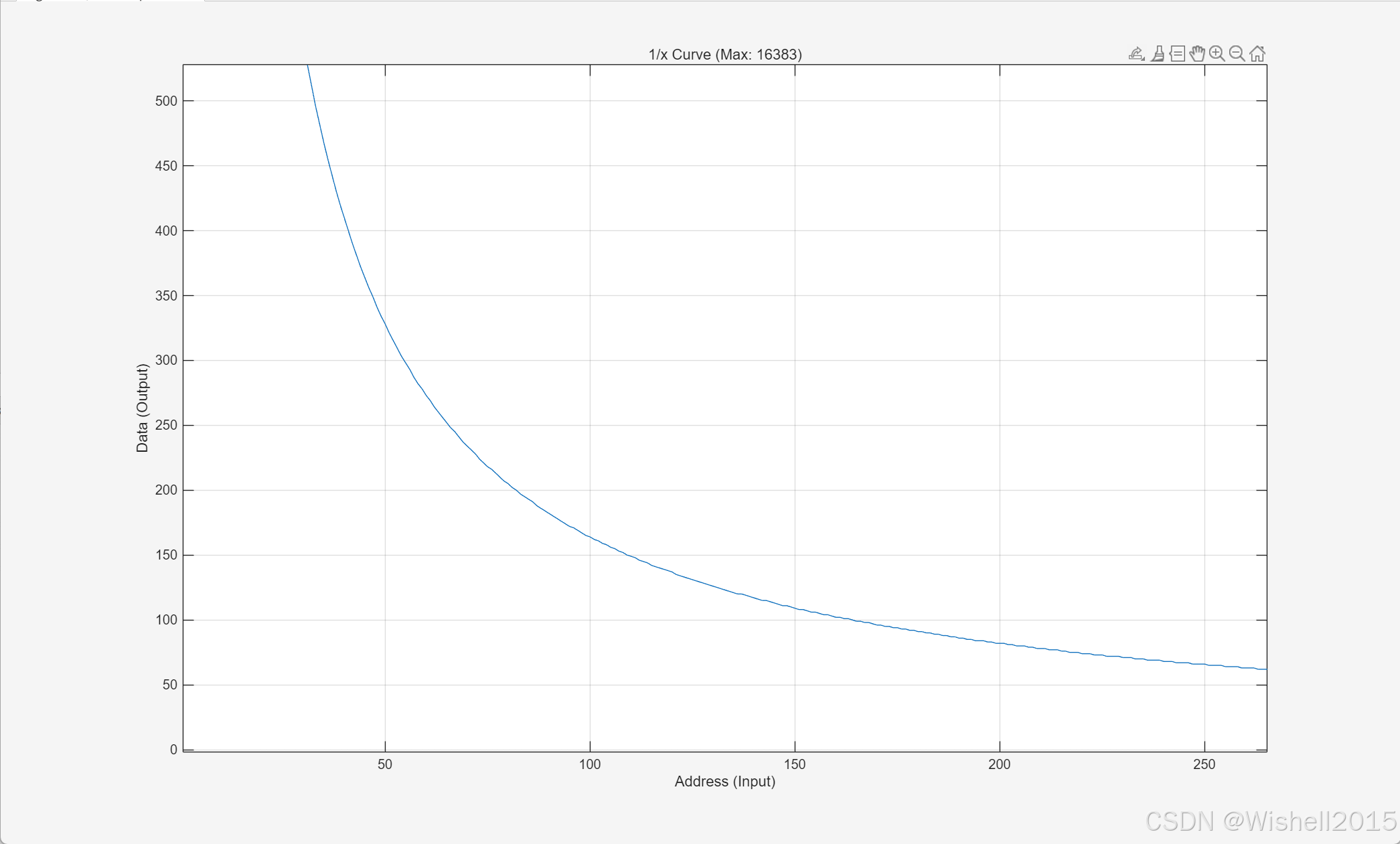
figure('Name', '1/x Lookup Table');
plot(y);
grid on;
title(['1/x Curve (Max: ', num2str(WIDTH_VAL), ')']);
xlabel('Address (Input)');
ylabel('Data (Output)');结果放大看,是一个1/x的函数。
Vivado中IP核的设置
这些IP核在前面都讲过,就不再赘述了,不懂的可以翻一翻。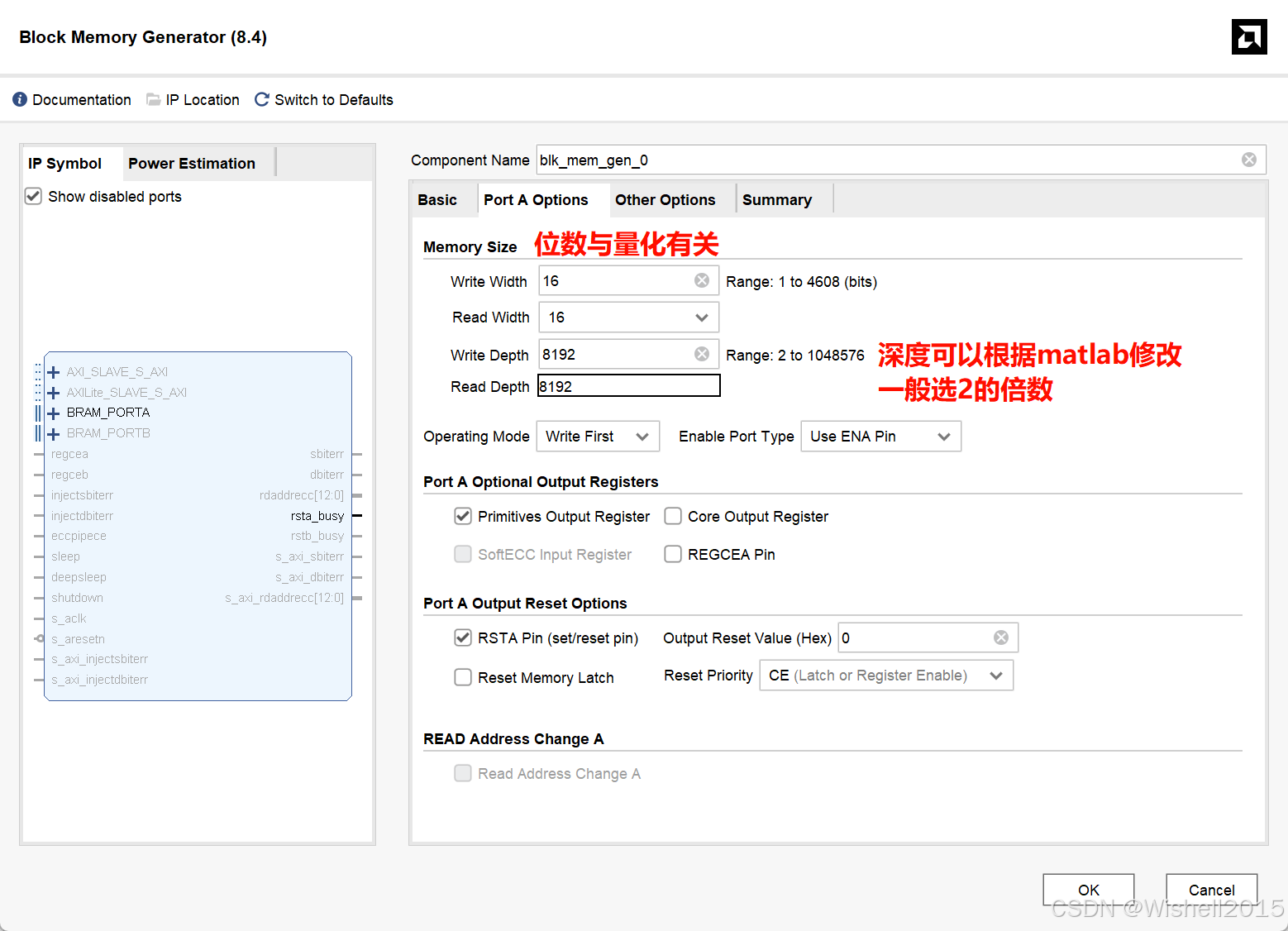
导入coe文件
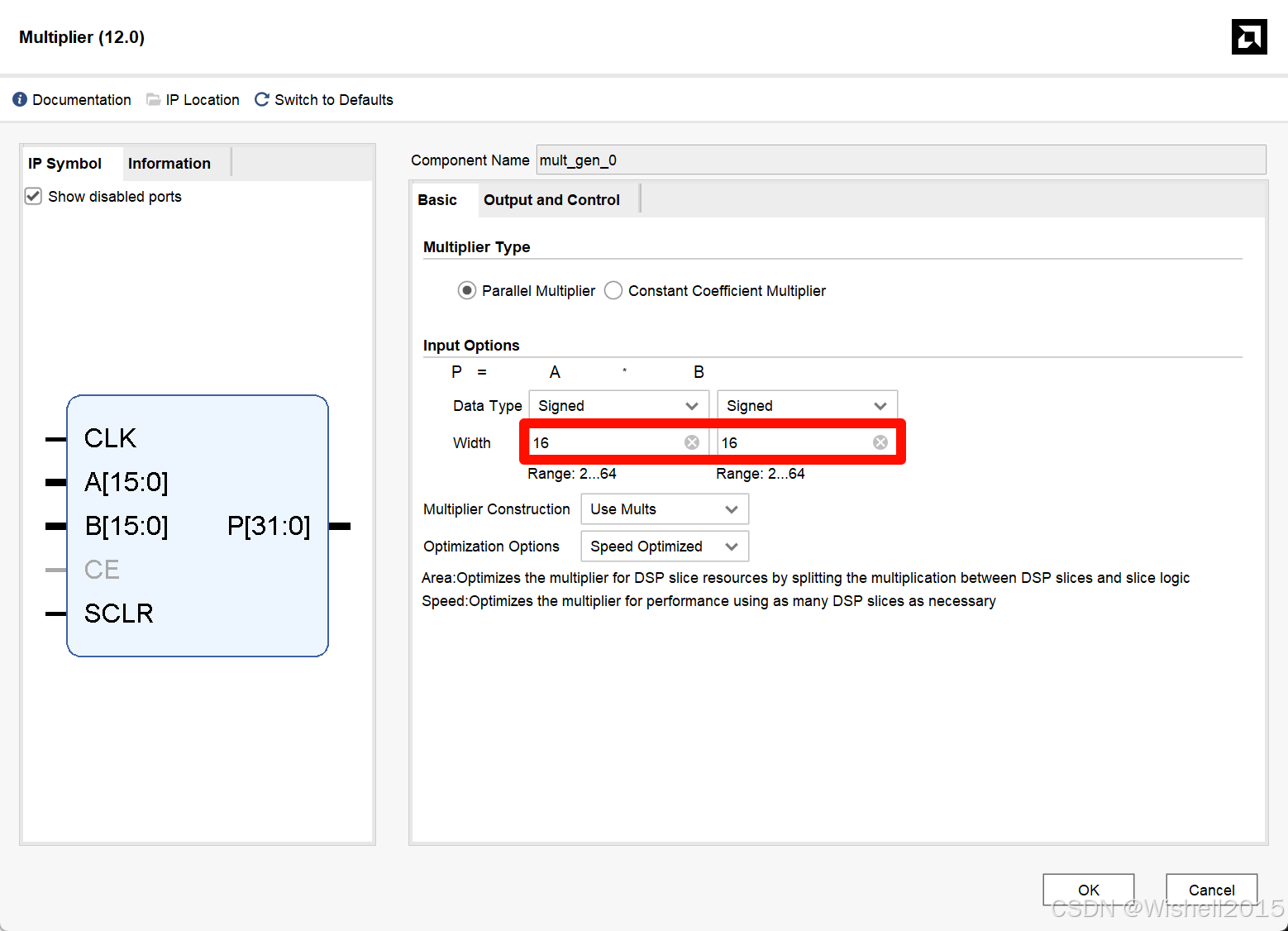
设置乘法器
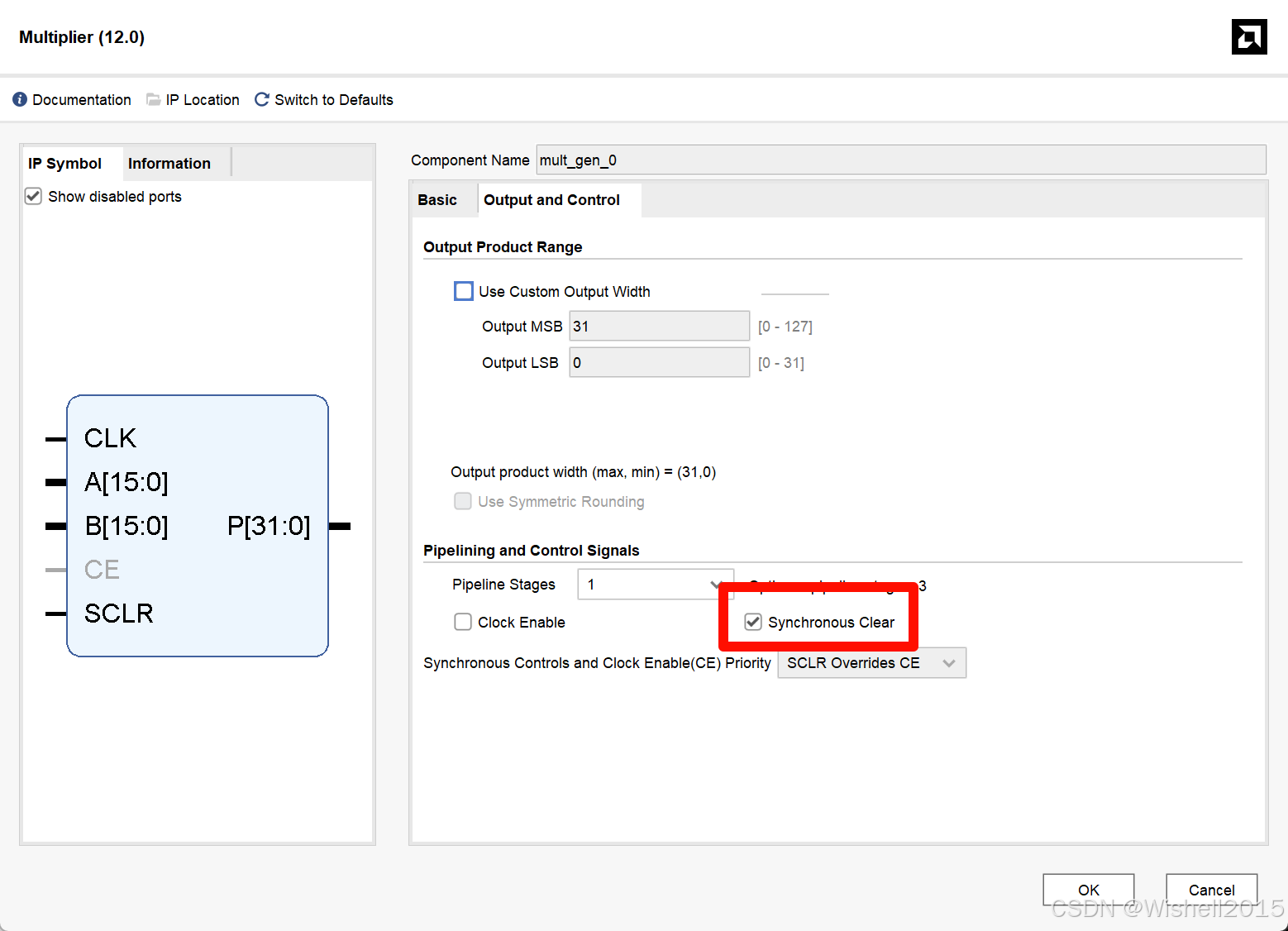
Top文件
几个点:
1、第一个乘法器用来y与1/x相乘,也就是用来模拟除法器,输出o_P,可以用来查看延时。
2、generate简单用法,生成三个乘法器,分别将除法器的结果乘以1、2、3然后相加输出结果,其实就相当于将除法器的结果乘以6.还涉及到一些截断等,想了解的可以自行百度一下。
verilog
module lowdelay_div(
input i_clk,
input i_rst,
input signed [15:0] i_y,
input signed [15:0] i_x,
output signed [15:0] o_P,
output signed [33:0] o_generate
);
//==========================================================
// 参数设置
//==========================================================
parameter BRAM_LATENCY = 2;
//==========================================================
// 信号定义
//==========================================================
wire [15:0] rom_dout_tdata;
wire [12:0] rom_addr;
reg signed [15:0] i_y_dly [0:BRAM_LATENCY-1];
wire signed [31:0] mult_result;
wire signed [15:0] div_result_16bit;
integer k;
//==========================================================
// 1. 数据对齐逻辑
//==========================================================
always @(posedge i_clk) begin
if (i_rst) begin
for (k=0; k<BRAM_LATENCY; k=k+1) begin
i_y_dly[k] <= 16'd0;
end
end else begin
i_y_dly[0] <= i_y;
for (k=1; k<BRAM_LATENCY; k=k+1) begin
i_y_dly[k] <= i_y_dly[k-1];
end
end
end
//==========================================================
// 2. BMG (Block RAM) 实例化
//==========================================================
assign rom_addr = (i_x > 16'd0) ? (i_x[12:0] - 1'b1) : 13'd0;
blk_mem_gen_0 blk_mem_gen_0u (
.clka(i_clk),
.rsta(i_rst),
.addra(rom_addr),
.douta(rom_dout_tdata),
.rsta_busy()
);
//==========================================================
// 3. 第一级乘法器 (计算 y * 1/x)
//==========================================================
mult_gen_0 mult_gen_u(
.CLK(i_clk),
.A(i_y_dly[BRAM_LATENCY-1]),
.B(rom_dout_tdata),
.SCLR(i_rst),
.P(mult_result) // 32位结果,格式为 Q17.14 (假设)
);
assign div_result_16bit = mult_result[29:14];
assign o_P = div_result_16bit; // 输出第一级结果
//==========================================================
// 4. 后级乘法器组 (generate 生成)
//==========================================================
wire [31:0] mult_out [1:3];
generate
genvar m;
for (m=1; m<=3; m=m+1) begin: mult_loop
mult_gen_0 mult_gen_gen_u(
.CLK(i_clk),
.A(div_result_16bit), //输入必须是截位后的16位数据,不能是32位的 mult_result
.B(m[15:0]), // 将 genvar 转换为 16位信号输入
.SCLR(i_rst),
.P(mult_out[m]) // 输出 32位
);
end
endgenerate
//==========================================================
// 5. 输出求和
//==========================================================
// 注意符号位扩展,这里简单相加
assign o_generate = mult_out[1] + mult_out[2] + mult_out[3];
endmodule可以看到,一共用了4个乘法器。
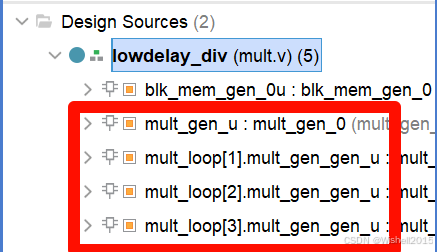
Testbench
编写Testbench进行仿真:
verilog
`timescale 1ns / 1ps
module lowdelay_div_tb;
reg i_clk;
reg i_rst;
reg signed [15:0] i_y;
reg signed [15:0] i_x;
wire signed [15:0] o_P;
wire signed [33:0] o_generate;
// 实例化 DUT
lowdelay_div lowdelay_div_u(
.i_clk (i_clk),
.i_rst (i_rst),
.i_y (i_y),
.i_x (i_x),
.o_P (o_P),
.o_generate (o_generate)
);
// 时钟生成 (100MHz)
initial begin
i_clk = 0;
forever #5 i_clk = ~i_clk;
end
// 激励生成
initial begin
// 初始化
i_rst = 1;
i_y = 0;
i_x = 1; // 避免 x=0
// 复位释放同步
repeat(10) @(posedge i_clk);
i_rst = 0;
// 测试用例 1: 10000 / 100 = 100
@(posedge i_clk);
i_y <= 16'd10000;
i_x <= 16'd100;
// 保持一段时间,观察流水线输出
// 即使输入变了,流水线也会按顺序输出结果
repeat(10) @(posedge i_clk);
// 测试用例 2: 10000 / 200 = 50
@(posedge i_clk);
i_y <= 16'd10000;
i_x <= 16'd200;
repeat(10) @(posedge i_clk);
// 测试用例 3: 10000 / 50 = 200
@(posedge i_clk);
i_y <= 16'd10000;
i_x <= 16'd50;
repeat(20) @(posedge i_clk);
$stop;
end
endmodule仿真结果:
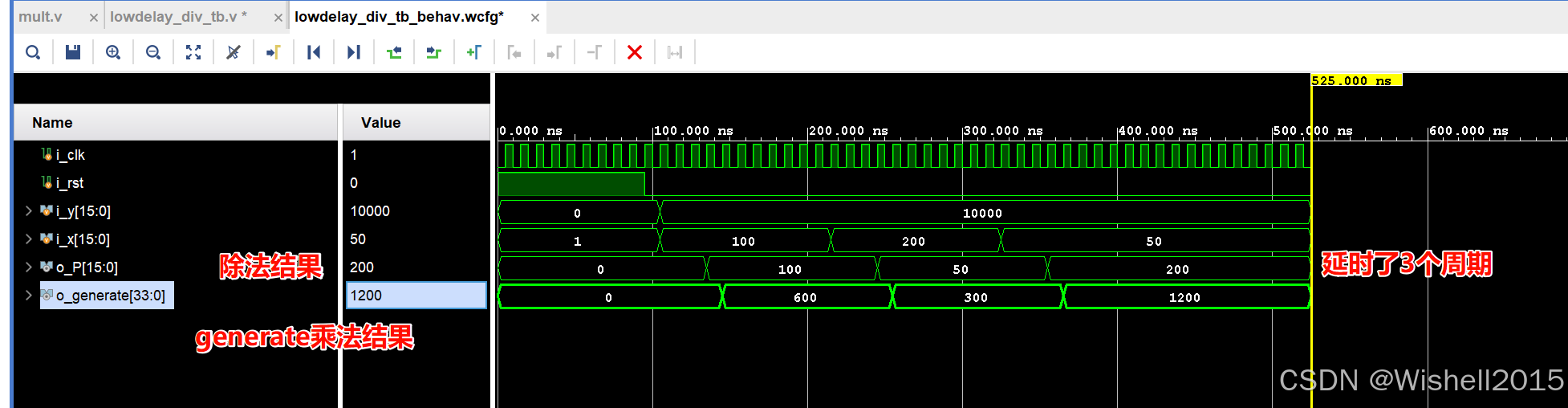
结果与预期相符,延时相对来说较低。