Meeting Summarizer Using Natural Language Processing
文章目录
- [Meeting Summarizer Using Natural Language Processing](#Meeting Summarizer Using Natural Language Processing)
-
- abstract摘要
- introduction引言
- [proposed system一些提出了的系统](#proposed system一些提出了的系统)
- [TECHNOLOGIES USED一些技术](#TECHNOLOGIES USED一些技术)
- conclusion结论
- [FUTURE SCOPE未来展望](#FUTURE SCOPE未来展望)
abstract摘要
本文主要介绍了几个常见的会议摘要生成技术。记住几个关键词:
term frequency-inverse document frequency (TF-IDF) ,
PageRank algorithm,
Topic Modeling
Glove embedding
introduction引言
两种摘要生成方式:extractive and abstractive。
extractive是基于原文提取;do not generate new text, but rather extract and compile the most important information from the original document
具体方法有singular value decomposition (SVD)奇异值分解:根据文档中词语或短语的频率和共现情况来识别文档中最重要的词语或短语。
还有keyword extraction、sentence extraction等等
abstractive是用自己的话对文本进行凝练摘要use language semantics and natural language generation (NLG) techniques to generate new text and summaries based on the content of the original document比如说用knowledge base、semantic representations
然后介绍了两种技术(详见III. TECHNOLOGIES USED)
TextRank
基于图的提取式摘要技术
TextRank通过创建文档中词语的图,将频繁共同出现的词语之间用边连接,然后根据这些词语在图中的中心性来确定最重要的词语。
TF-IDF词频-逆文档频率TF-IDF是一种统计度量方法,它根据词语在单个文档中的频率以及在文档集合中的稀有程度来反映词语在文档中的重要性。
proposed system一些提出了的系统
以 Microsoft Teams 为例
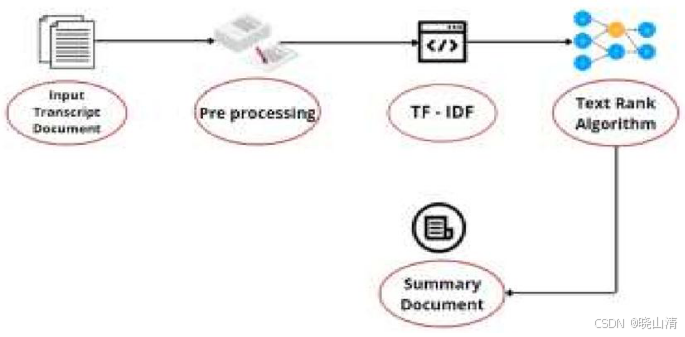
- 在预处理阶段,文本经过标准化处理,并消除停用词。
- 使用TF-IDF(词频-逆文档频率)构建文档术语相似度矩阵(将文档术语特征矩阵与其转置矩阵相乘创建相似度矩阵。该矩阵捕获每对句子之间的相似度)
- 然后生成文档的相似度图(基于PageRank),其中句子作为顶点,相似度分数作为权重或得分系数。
PageRank算法被应用于文档相似性图中,该算法根据网络中节点的重要性分配分数。它为每个句子计算分数,以表明它们在整个网络中的相对重要性。最后,根据句子的分数对它们进行排序,并选择排名靠前的句子来形成输出摘要文档。这些句子代表了原始会议记录中最相关且信息丰富的内容部分。
另一个例子
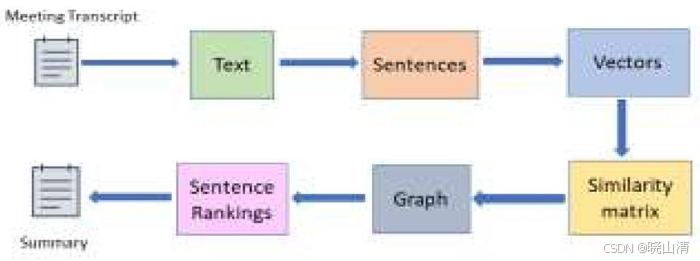
- 该文本使用nltk库进行分词,将其拆分为单个单词。然后移除停用词,并对单词进行词干提取以将其还原为词根形式。
- 提取出的单词通过numpy转换为向量,这些向量代表标准化后的句子。
- 从sklearn模块导入TfidfVectorizer以创建文档的term频率矩阵。通过对该矩阵进行转置,可获得逆文档频率。通过将term频率矩阵与其转置矩阵相乘生成相似度矩阵。
- 对相似度图应用PageRank算法,根据句子的重要性为其分配排名。
- 最后,根据排名提供排名最高的句子作为输出。输出摘要中的句子数量根据输入中预处理后的句子数量来确定:如果输入句子超过30句,则输出包含总输入句子的20%;否则包含30%。
TECHNOLOGIES USED一些技术
-
TEXTRANK Algorithm
TextRank 是一种基于图的排序算法,其灵感来源于谷歌的 PageRank 算法。它可以用于识别文本中相关性最高的句子并提取关键词。
该算法会创建一个图,其中顶点表示文档中的每个短语,边则根据内容重叠度将句子连接起来。这可以通过计算两个句子共有的单词数量来实现。然后将这些句子输入 PageRank 算法,该算法根据句子网络确定每个句子的重要性。选择最重要的句子来生成文本摘要。TextRank 还可以通过创建单词网络来从文本中提取关键词,该网络能够识别相互关联的单词。如果两个单词在文本中频繁地相邻出现,它们之间就会建立一条链接,且如果这两个单词一起出现的频率更高,该链接的权重也会更大。将 PageRank 算法应用于生成的网络以确定每个单词的重要性。选择重要性最高的三分之一单词,并通过将文本中紧密邻近的相关术语分组来创建关键词表。TextRank 架构涉及创建文本的图、将 PageRank 算法应用于该图,并使用得出的分数对文本中的短语或单词进行排序。然后选择最重要的短语或单词,用于所需的任务,如摘要生成或关键词提取。
-
Term Frequency -- Inverse Document Frequency (TF-IDF)
词频矩阵(TF):用于表示文档集合中每个文档与每个词之间的关系。矩阵的行代表文档,列代表词,矩阵中的元素表示词在文档中出现的频率(即词频,TF)。其核心思想是反映词在文档中的局部重要性。
逆文档频率(IDF):用于衡量一个词在整个文档集合中的全局重要性。如果一个词在很多文档中都出现,那么它的IDF值就较低,表示这个词对区分文档的贡献较小;反之,如果一个词只在少数文档中出现,那么它的IDF值就较高,表示这个词对区分文档的贡献较大。IDF的核心思想是抑制常见词的权重,提升稀有词的权重。
I D F ( t ) = l o g ( N d f t ) IDF(t)=log( \frac N{df_t} ) IDF(t)=log(dftN)
- GLOVE Embedding
GloVe(Global Vectors for Word Representation)是一种用于生成词嵌入的无监督学习算法。词嵌入是词语的密集向量表示,每个词语都被映射到一个高维向量中。这些向量能够捕捉词语之间的语义和句法关系,从而更好地理解词语的含义。GloVe算法基于这样的思想:词语的含义可以从大量文本语料库中词语的共现统计信息中推断出来。它分析词语共现矩阵,该矩阵统计词语在给定上下文窗口中共同出现的频率。通过对该矩阵进行分解,GloVe学习到能够最佳捕捉词语共现统计模式的嵌入。生成的词嵌入编码了词语之间的语义关系。相似的词语在嵌入空间中由距离较近的向量表示,而不相似的词语则由距离较远的向量表示。这些嵌入可以作为各种自然语言处理(NLP)任务中的特征使用,例如情感分析、命名实体识别、机器翻译和文本分类。由于GloVe嵌入在捕捉语义信息方面的有效性以及其处理词汇表外词语的能力,它们广受欢迎。GloVe嵌入已被广泛应用于研究和工业应用中,以提升NLP模型的性能。
conclusion结论
虽然抽取式摘要可以作为快速理解会议记录内容的有用工具,但它并不总是生成最简洁的摘要,因为它可能会包含来自原始文档的无关或冗余信息。另一方面,抽象式摘要涉及生成新的句子来捕捉原始文档的主要要点,可能在生成简洁摘要方面更有效。然而,抽象式摘要通常比抽取式摘要更难实现,因为它要求系统理解文本的含义并生成新的句子。
FUTURE SCOPE未来展望
对信息提取、知识管理和决策过程的优化
- 可能的进步包括通过整合音频、视频和文本实现多模态摘要,
- 增强说话人识别与追踪以提供个性化摘要。
- 情感分析和实体识别等上下文理解能力的提升,生成更准确的摘要。
- 实时会议摘要、用户自定义功能以及与协作工具的集成,可进一步提高生产力。
- 需要建立稳健的评估指标来衡量摘要质量。
- 多语言支持将扩大其适用范围。