近年来,随着大语言模型(LLM)能力的不断提升,如何将这些模型高效部署到边缘设备 (如国产瑞芯微 RK3588 芯片)成为开发者关注的重点。本文将手把手带你完成 DeepSeek-R1-Distill-Qwen-1.5B 模型在 RK3588 上的转换、部署与推理全流程。
关键词:RK3588、RKLLM、Qwen、DeepSeek、边缘 AI、大模型推理、国产芯片、Rockchip
📦 项目背景
本 Demo 基于 RKLLM Toolkit 工具链,展示了如何将 Hugging Face 上开源的轻量级推理模型 DeepSeek-R1-Distill-Qwen-1.5B 转换为 RK3588 可运行的 .rkllm 格式,并通过 C++ 推理程序在开发板上实现本地化部署。

该模型仅 1.5B 参数,但经过 DeepSeek-R1 强化蒸馏,在数学、代码和逻辑推理任务上表现优异,非常适合资源受限的边缘场景。
🔧 环境要求
确保你的主机环境满足以下依赖:
text
rkllm-toolkit == 1.2.x
rkllm-runtime == 1.2.x
Python >= 3.8💡 提示:建议使用 Ubuntu 20.04/22.04(X86) + Conda 虚拟环境进行模型转换。
🔄 第一步:模型转换(Host 端,X86)
1. 准备量化校准数据
RKLLM 支持 INT8/W8A8 量化以提升推理速度。我们需要先生成校准数据 data_quant.json:
bash
cd export
python generate_data_quant.py -m /path/to/DeepSeek-R1-Distill-Qwen-1.5B该脚本会加载原始 FP16 模型,生成一批典型输入用于后续量化。
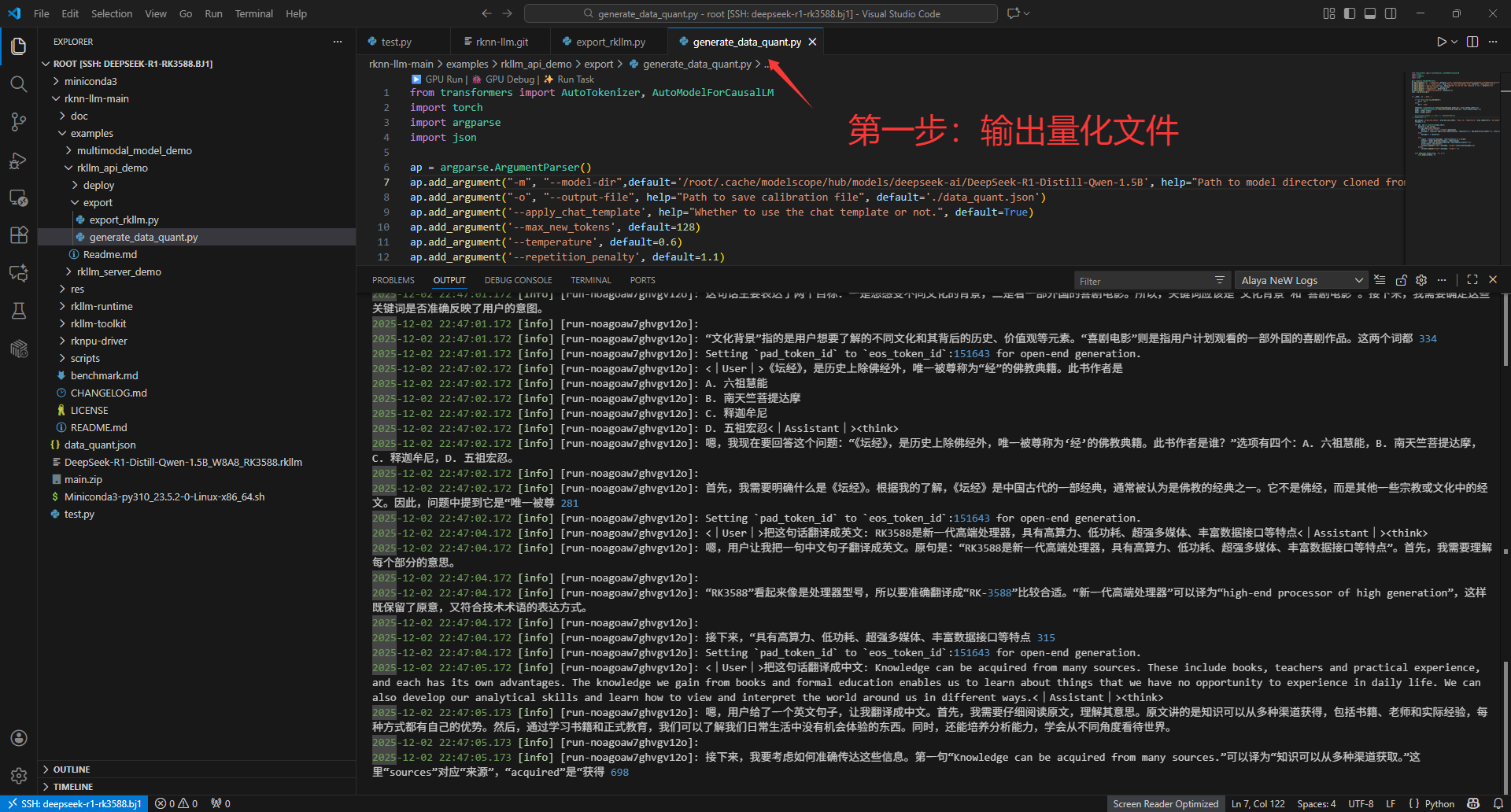
2. 导出 RKLLM 模型
执行导出脚本,生成可在 RK3588 上运行的 .rkllm 文件:
模型下载:
bash
pip install modelscope
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5Brkllm模型导出:(这一步在X86+cuda电脑上实现,非arm)
bash
python generate_data_quant.py -m /path/to/DeepSeek-R1-Distill-Qwen-1.5B
python export_rkllm.py✅ TMI :以前也可以直接从 RKLLM 模型仓库(提取码:
rkllm)下载已转换好的DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm模型文件,跳过上述步骤。But, rknn-llm 1.2.3版本的Deepseek-R1只能自己转,官方没有提供!
这个时候,如果想要转这个模型,就需要x86版本的带英伟达显卡的电脑。找了好久都没找到,甚至用虚拟机也没法实现(没法调用显卡)。这个时候非常感谢AladdinEdu AI学习实践工作坊,他们的工作人员(非常nice的兄弟!)给我提供了他们的云平台。
常言道,工欲善其事必先利其器!在他们的平台上,我很快转换成功我需要的DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm 的模型。
🖥️ 第二步:C++ 推理部署(板端)
进入 deploy 目录,我们提供了完整的 Linux/Android 推理示例。
1. 编译可执行程序
bash
cd deploy
./build-linux.sh # Linux aarch64 平台
# 或
./build-android.sh # Android 平台(需配置交叉编译工具链)编译成功后,会在 deploy/install/demo_Linux_aarch64/ 目录下生成:
llm_demo:推理主程序lib/:RKLLM 运行时动态库
2. 推送文件到 RK3588 开发板
bash
# 推送可执行程序
adb push install/demo_Linux_aarch64 /data
# 推送模型文件
adb push DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm /data/demo_Linux_aarch64/
# 推送固定频率脚本(提升性能稳定性)
adb push ../../../scripts/fix_freq_rk3588.sh /data/demo_Linux_aarch64/3. 在板端运行推理
bash
adb shell
cd /data/demo_Linux_aarch64
export LD_LIBRARY_PATH=./lib
sh fix_freq_rk3588.sh # 锁定 CPU/NPU 频率
export RKLLM_LOG_LEVEL=1 # 启用日志(可选)
# 启动推理(参数:模型路径、max_new_tokens=2048、max_ctx_len=4096)
./llm_demo DeepSeek-R1-Distill-Qwen-1.5B_W8A8_RK3588.rkllm 2048 4096启动成功后,你会看到:
rkllm init start
rkllm init success
**********************可输入以下问题对应序号获取回答/或自定义输入********************
[0] 鸡兔同笼问题...
[1] 小朋友排队问题...
*************************************************************************
user: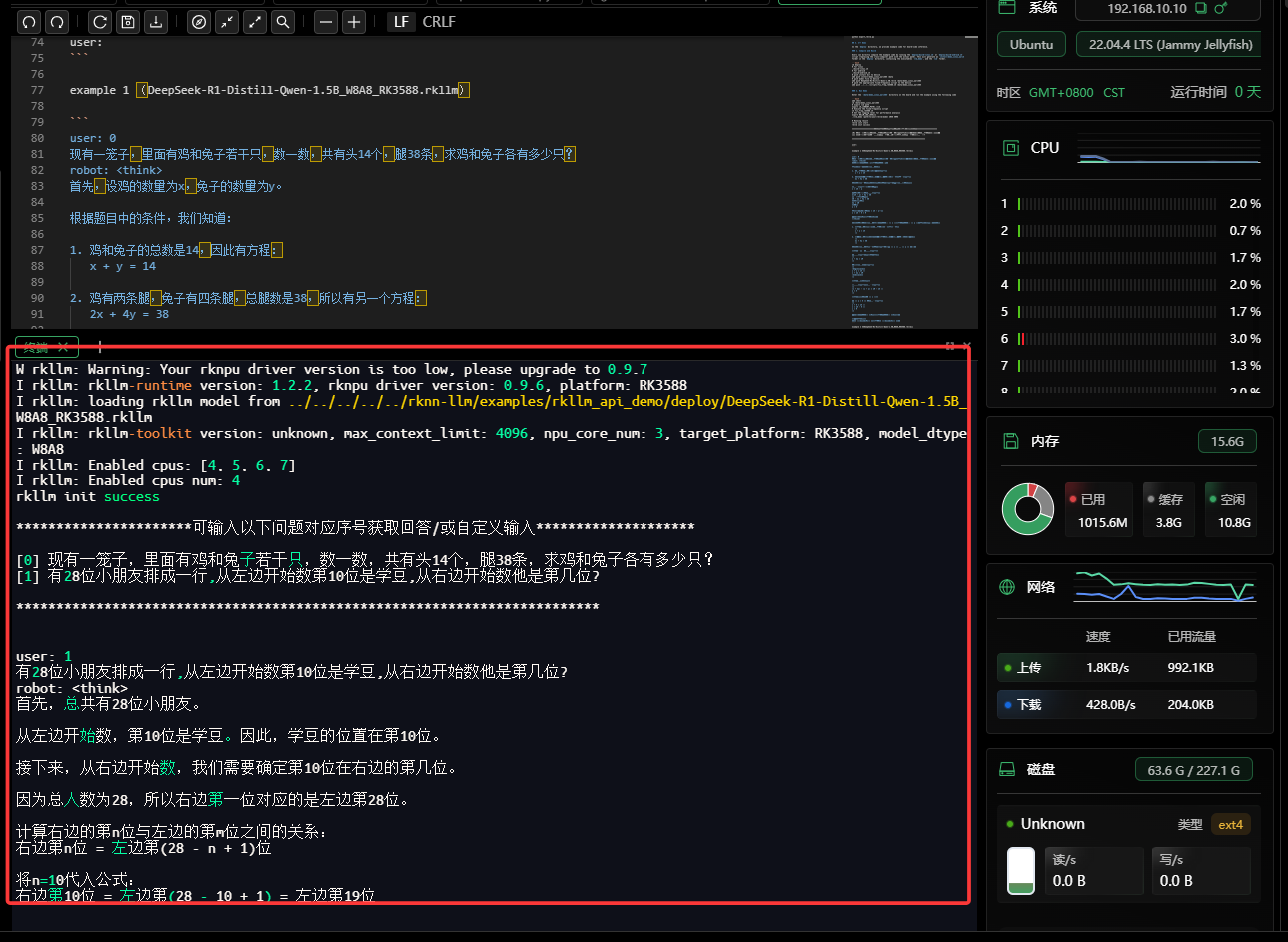
🧠 推理效果展示
示例 1:数学推理(鸡兔同笼)
user: 0
现有一笼子,里面有鸡和兔子若干只,数一数,共有头14个,腿38条,求鸡和兔子各有多少只?模型输出(节选):
设鸡为 ( x ),兔为 ( y ),列方程: \\begin{cases} x + y = 14 \\ 2x + 4y = 38 \\end{cases} 解得:鸡有 9 只 ,兔子有 5 只。
最终答案:鸡有 (\boxed{9}) 只,兔子有 (\boxed{5}) 只。
✅ 模型不仅给出答案,还完整展示分步推理过程,符合 DeepSeek 系列"强推理"特性。
示例 2:逻辑题(位置计算)
user: 1
有28位小朋友排成一行,从左边开始数第10位是学豆,从右边开始数他是第几位?模型输出:
总人数 28,左边第 10 位 → 右边位置 = ( 28 - 10 + 1 = 19 )
最终答案:(\boxed{19})
🌟 总结与展望
通过 RKLLM 工具链,我们成功将 1.5B 级别的高性能推理模型部署到 RK3588 边缘设备,实现在无网络、低功耗环境下运行复杂语言任务。这为国产芯片在 AIoT、教育、工业等场景的应用打开了新可能。
未来方向:
- 支持多模态模型(如 Qwen-VL)
- 集成 FastAPI 构建本地 REST 服务
- 优化 W4A16 量化策略进一步提速