Streams 能为大家提供一种简单的方式,在数据摄入阶段对日志进行整理、解析和管理。以往大家可能需要在每个端点都配置日志解析和路由,而有了 Streams,大家只需将所有日志发送到单个流中,后续的日志分区、解析、留存以及数据质量保障等工作,都可以交给 Streams 来处理。这种方式能有效降低操作复杂度、节省时间,让大家更轻松地将日志转化为可落地的有效洞察。
本文将涵盖如下的几个方面的内容:
- 借助 AI 技术,将非结构化日志解析为结构化字段
- 把单一的日志流划分为具有实际意义的不同分组
- 无需人工搜索,就能检测重要事件并触发告警
- 应用日志留存策略,只保留大家实际需要的日志数据
- 监控数据质量,快速发现并解决日志摄入过程中出现的问题
通过观看下面的内容,大家就能清楚看到,Streams 是如何帮助 SRE(站点可靠性工程)团队和 DevOps(开发运维)团队减少重复繁琐的工作、提升系统可靠性,以及让大家更有信心地将原始日志转化为有价值的洞察的。
更多阅读:将 Streams 引入 Observability:调查的第一站
- 解析日志 (Parsing Logs)
简介 (Intro)
日志中包含着丰富的洞察,但只有将它们转化为结构化数据时才真正有用。传统方法需要手动编写 Grok 模式,这既耗时又容易出错。由 Search AI 驱动的 Streams 通过建议模式、提供有意义的字段名,将团队从手动劳动中解放出来,使这一过程更快、更容易。
在此演示中,我们将使用 Streams 和 AI 生成 Grok 模式,提取订单类型和数量等有用字段,然后将结果可视化。目标是展示将原始文本转化为有意义的洞察是多么简单。
 www.bilibili.com/video/BV1bZ...使用 AI 解析日志: www.bilibili.com/video/BV1bZ...
www.bilibili.com/video/BV1bZ...使用 AI 解析日志: www.bilibili.com/video/BV1bZ...
回顾 (Recap)
日志处理的挑战一直在于如何将混乱的文本转化为可信赖、可大规模使用的结构化数据。在此演示中,我们从非结构化日志开始,最终获得了干净、可查询的字段。
通过在摄入时借助 AI 辅助解析日志,我们看到了将一致的数据输入仪表板、警报和工作流是多么容易。这减少了平均解决时间(MTTR),提高了可靠性,并将日志从仅仅是过去的记录转变为用于监控和故障排查的主动工具。
- 分区流 (Partitioning Streams)
将所有日志发送到日志流
在端点管理解析和路由是复杂且脆弱的。对日志源的每次更改都意味着重新配置代理或管道,这使得扩展变得困难并拖慢了团队的进度。
Streams 改变了这种模式。您可以将所有日志发送到单个入口点,而不是在边缘进行预分类和解析。分区和解析在摄入时进行,使得分离服务、清理日志和添加结构变得简单,而无需触及端点。在此演示中,我们将从一个流中的所有日志开始,为 Spark 创建一个分区,然后让 AI 建议并为 Hadoop 创建一个分区。
提示 (Tips)
 对日志流进行分区: www.bilibili.com/video/BV18Z...
对日志流进行分区: www.bilibili.com/video/BV18Z...
r
`(?<body_text>[\s\S]*)`AI写代码回顾 (Recap)
基于端点的配置所面临的挑战是它会增加复杂性并减慢操作速度。在此演示中,我们看到了 Streams 如何在摄入时处理分区:Hadoop 和 Spark 的日志被自动分离,无需任何端点更改。
通过集中化解析和分区,Streams 使日志保持组织化和结构化变得容易。您只需将所有内容发送到日志流,剩下的由 Streams 完成。结果是更简单的操作、更快的故障排查以及跨所有系统的一致可见性。
- 重要事件 (Significant Events)
如何找到可能重要的事件?
收集日志很容易,真正的挑战是知道哪些日志行重要,哪些可以忽略。没有帮助,团队需要花费数小时搜索成千上万的条目,希望在噪音中发现信号。这种被动的方法浪费时间,并且通常意味着问题只有在影响用户后才被发现。
带有重要事件功能的 Streams 改变了这一点。AI 会自动识别向流发送数据的系统,突出显示可能指向关键问题的日志行,并使其易于转化为警报。在此演示中,我们将识别 Spark 作为一个系统,生成 AI 驱动的重要事件建议,并从其中一个事件创建警报------所有这些都无需手动挖掘。
 通过 AI 发现重要事件: www.bilibili.com/video/BV1SZ...
通过 AI 发现重要事件: www.bilibili.com/video/BV1SZ...
回顾 (Recap)
日志的挑战一直是在噪音中找到重要的信号。在此演示中,我们使用 AI 识别 Spark 作为一个系统,在其日志中发现重要事件,并仅需几次点击就创建了一个警报。
借助重要事件功能,日志从被动的故障排查转变为主动的智能分析。AI 能够发现您可能错过的模式,在用户注意到问题之前识别问题,并帮助团队设置有意义的警报。结果是更快的检测、更少的人工劳动和更强的运营弹性。
- 数据保留 (Retention)
只保留我们需要的日志
并非所有日志都需要永久保存。存储所有东西会增加成本、产生复杂性,并使合规性管理更加困难。挑战在于保留您需要用于可见性和审计的数据,同时安全地淘汰其余数据。
Streams 使这变得简单。您可以直接对日志流应用清晰的保留策略。在此演示中,我们将确定我们的保留需求并应用新策略,以展示保持合规、控制成本和优化存储是多么容易,而无需牺牲性能。
 应用数据保留策略: www.bilibili.com/video/BV1SZ...
应用数据保留策略: www.bilibili.com/video/BV1SZ...
回顾 (Recap)
日志保留的挑战是在可见性、成本和合规性之间取得平衡。在此演示中,我们对日志流应用了保留策略,并看到了 Streams 如何自动处理其生命周期。
通过在摄入时应用正确的保留设置,您只需在日志有用期间保留它们。团队获得了他们需要的可见性,而无需为不需要的东西支付过高的费用。使用 Elastic,您可以获得不妥协的保留策略,使可观测性数据与业务需求保持一致。
- 数据质量 (Data Quality)
解析日志时是否存在任何问题?
对可观测性数据的信任取决于质量。解析错误、摄入失败或模式不匹配可能导致隐藏重要信号的空白。挑战在于在它们损害仪表板、警报或调查之前迅速发现这些问题。
Streams 通过将数据质量置于首位来解决这个问题。在此演示中,我们将故意引入一个解析错误以产生摄入失败,然后使用"数据质量"选项卡查看 Streams 如何呈现和解释问题。最后,我们将修复错误,以展示问题如何在造成盲点之前得到解决。
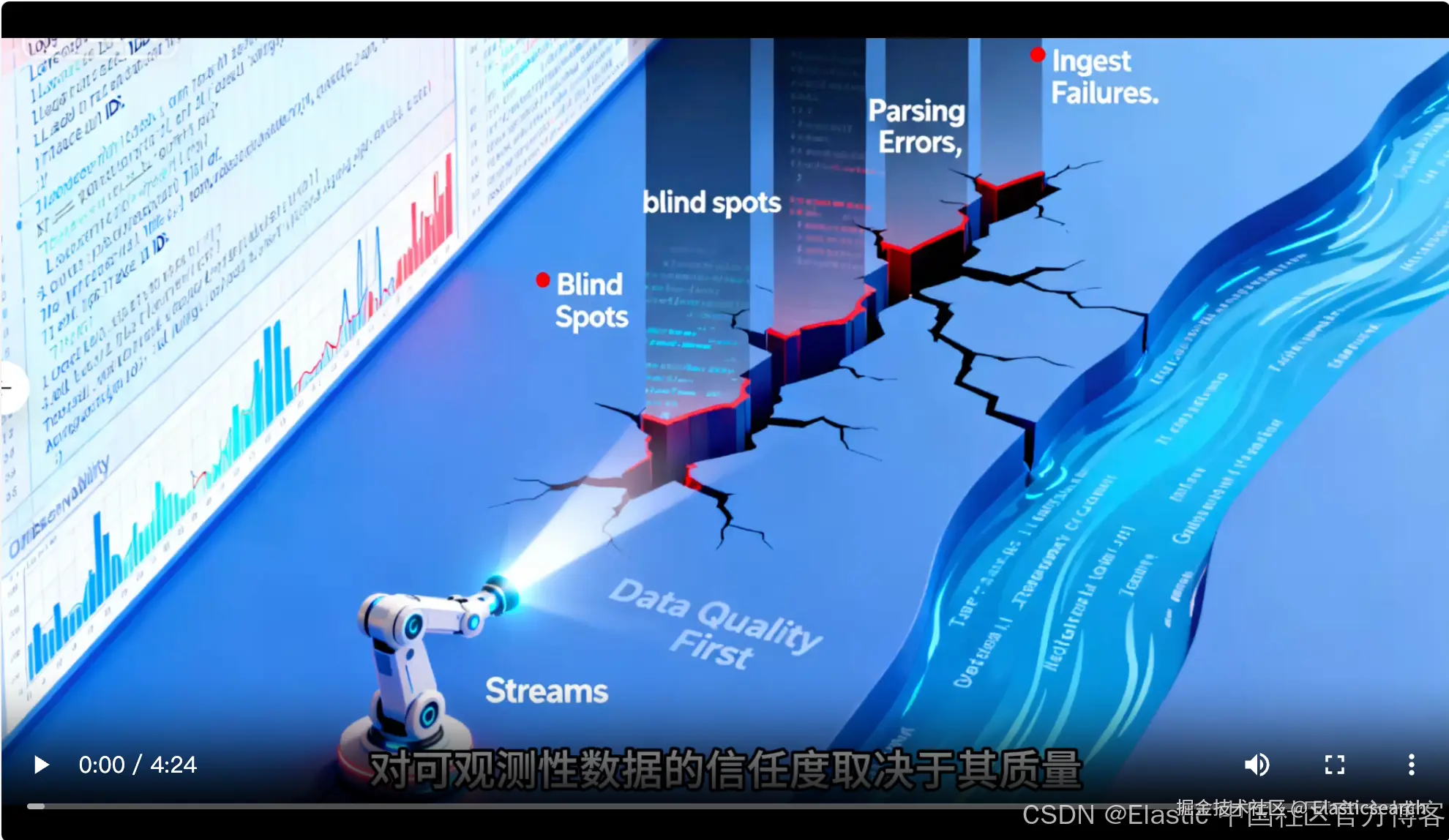 监控数据质量: www.bilibili.com/video/BV1YD...
监控数据质量: www.bilibili.com/video/BV1YD...
回顾 (Recap)
数据质量的挑战在于,摄入错误通常是无声的,直到它们导致数据丢失或误导。在此演示中,我们引入了一个解析错误和格式错误的数据,看到它们立即在"数据质量"中被标记出来,并修复了它们。
通过实时监控数据质量,Streams 确保您可以信任仪表板、警报和调查背后的数据。这使团队有信心,即使在复杂的环境中,他们的可观测性数据也是准确、完整和可靠的。
更多观看
 Streams:Elastic 的新 AI,将日志混乱转化为清晰: www.bilibili.com/video/BV1nU...
Streams:Elastic 的新 AI,将日志混乱转化为清晰: www.bilibili.com/video/BV1nU...
 Streams 是如何工作的 -9.2-demo: www.bilibili.com/video/BV1vu...
Streams 是如何工作的 -9.2-demo: www.bilibili.com/video/BV1vu...
结论 (Conclusion)
在本次研讨会中,我们探讨了 Elastic Observability 中的 Streams 如何从头到尾简化日志处理。我们将非结构化日志解析为有意义的字段,对流进行分区以保持服务井然有序,识别并对重要事件发出警报,应用保留策略,并监控数据质量。每一步都展示了 Streams 如何在摄入时处理解析、组织和治理,而不是在每个端点管理复杂性。
其价值是显而易见的:使用 Streams,您可以将所有日志发送到单个入口点,并信任 Elastic 来组织、丰富和保护您所依赖的数据。这减少了人工劳动,提高了可见性,并确保可观测性数据是准确和可操作的。通过结合速度、上下文和相关性,Elastic Observability 帮助 SRE 和 DevOps 团队充满信心地从原始日志转向可靠的洞察。