物理架构与竞态
物理内存布局 (SRAM)
html
STM32MP157 内部有一块 SRAM,它被映射到了两个地址空间:
MPU (Microprocessor Unit,微处理器) A7 (Linux): 虚拟地址 -> 物理地址 0x10040000
MCU (Microcontroller Unit,微控制器) M4 (RTOS): 物理地址 0x10040000三级竞态
html
核间竞态 (Inter-Core): A7 和 M4 同时写这块 SRAM。
会导致数据损坏(Tearing)。
VirtIO 环形缓冲区 (软件解法) 或 HSEM (硬件解法)。
本地中断竞态 (Local Interrupt): A7 正在向 SRAM 填数据,突然 IPCC 接收中断来了。
会导致死锁或数据不一致。
Spinlock (自旋锁) + 关中断。
本地多进程竞态 (Local Process): 两个 Linux APP 同时通过驱动发消息。
会导致逻辑混乱。
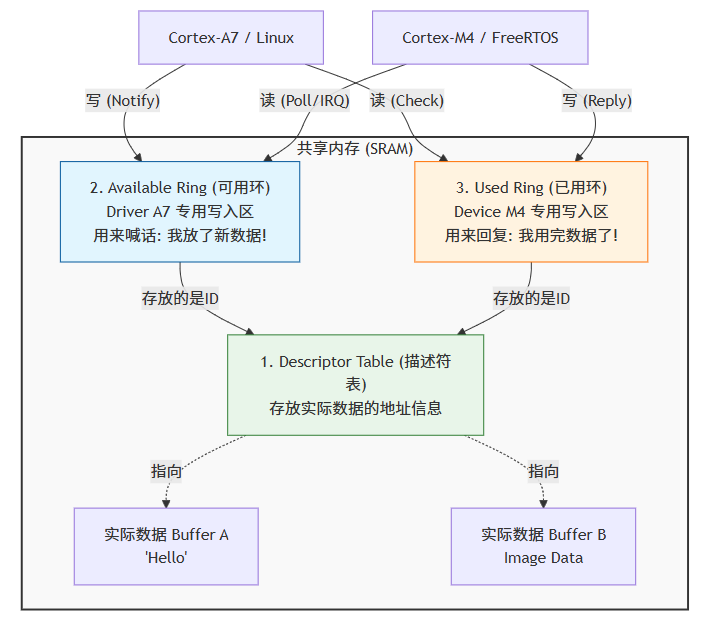
Mutex (信号量)。核心数据结构 ------ VirtIO Ring (解决核间竞态)
为了避免 A7 和 M4 竞态,VirtIO 采用了单向流设计:
html
vring (Virtual Ring): 由三部分组成:
Descriptor Table (描述符表): 存放实际数据的地址和长度。
Available Ring (可用环): 发送方(Driver)只写这一部分,告诉接收方"我有数据给你"。
Used Ring (已用环): 接收方(Device)只写这一部分,告诉发送方"我处理完了"。VirtIO 的设计使得 A7 只修改 Available Ring 的索引,M4 只修改 Used Ring 的索引。读写分离,从算法上消除了核间竞态。
Linux 驱动层的并发 (解决本地竞态)
Linux 内核模块(.ko)的保护
html
A.发送数据时:处于"进程上下文" (Process Context)
Linux 应用层程序(APP)调用了 write(fd, buf, len)。
此时,CPU 从用户态切换到内核态,开始执行驱动里的 my_ipcc_write 函数。
某个具体的进程执行(PID=100 的 demo_app),内核知道这个进程的所有信息(task_struct)。
休眠目的:
调用了 copy_from_user。
用户传进来的内存地址可能是虚拟地址。
如果这块内存当时不在物理 RAM 里(被交换到了硬盘 swap 区),就会触发 "缺页异常 (Page Fault)"。
由于CPU 需要去硬盘读数据,这非常慢。
为了不浪费 CPU,内核会把当前进程"置为睡眠状态 (Sleep)",把 CPU 让给别的进程用,等数据读好了再唤醒它。
由于休眠,所以用 Mutex(互斥体)。如果拿不到锁,当前进程就去休眠,不占用 CPU 资源。
B.接收数据时:处于"中断上下文" (Interrupt Context)
M4 核心向 A7 发了一个信号,硬件触发了 IPCC 中断。
A7 的 CPU 立即停止手头的一切工作(无论当时在运行哪个进程),强行跳转到 my_ipcc_rx_handler 执行。
CPU 响应硬件的紧急呼叫。
此时内核代表的是"硬件",没有对应的 task_struct(就是借用了被打断进程的壳,但无权限使用)。
为什么严禁休眠:
Linux 调度器只能调度"进程"。中断处理程序不属于任何进程。
如果你在中断里休眠(调用了会导致休眠的函数,或者使用了 Mutex),调度器就把这个"不知名"的执行流挂起。
调度器再也找不到它了,因为它没有进程 ID。
导致系统崩溃(Kernel Panic),或者整个 CPU 核心死锁。
因为不能休眠,所以用 Spinlock(自旋锁)。
如果拿不到锁,CPU 就在那里"原地空转(Spin)"死等。因为中断必须极快结束,稍微等几微秒是可以接受的,但绝不能休眠。
1.发送数据 (进程上下文)互斥体
当APP 调用 write() 发送数据时,你处于进程上下文,可能会休眠,也可能会被其他进程抢占。
c
struct ipcc_client_dev {
struct mutex tx_lock; // 互斥体:用于进程间互斥
spinlock_t rx_lock; // 自旋锁:用于中断保护
void __iomem *shm_base; // 共享内存基地址
};
// 发送函数:APP调用 write 时触发
ssize_t my_ipcc_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
struct ipcc_client_dev *dev = filp->private_data;
// 【步骤1】获取互斥锁 (解决:进程竞态)
// 为什么要用 mutex?因为 copy_from_user 可能会休眠(导致缺页异常),
// 只有 mutex 允许休眠,spinlock 不允许。
if (mutex_lock_interruptible(&dev->tx_lock)) {
return -ERESTARTSYS;
}
// 【步骤2】拷贝数据到内核缓冲区
// 此时其他进程想发数据会被堵塞在 mutex_lock
copy_from_user(local_buffer, buf, count);
// 【步骤3】写入共享内存 & 触发 IPCC
// 这里如果涉及到底层寄存器操作,且必须极快,可能需要关中断
// 但通常 OpenAMP 内部处理了,这里假设我们在操作裸机共享内存
writel(data, dev->shm_base + OFFSET);
// 触发 IPCC 硬件门铃
stm32_ipcc_set_channel(ipcc_handle, CHANNEL_ID);
// 【步骤4】释放互斥锁
mutex_unlock(&dev->tx_lock);
return count;
}2.接收数据 (中断上下文)自旋锁
当 M4 回复消息时,A7 会触发中断。此时严禁休眠。
c
// 中断服务程序 (ISR):当 IPCC 硬件中断触发时执行
static irqreturn_t my_ipcc_rx_handler(int irq, void *data)
{
struct ipcc_client_dev *dev = (struct ipcc_client_dev *)data;
unsigned long flags;
// 【步骤1】获取自旋锁并关中断 (解决:中断竞态)
// 为什么用 spin_lock_irqsave?
// 1. 我们在中断里,绝不能休眠,所以不能用 mutex。
// 2. irqsave 会保存当前中断状态并禁止本地中断,防止嵌套中断打断我们。
spin_lock_irqsave(&dev->rx_lock, flags);
// --- 临界区开始 (Critical Section) ---
// 必须快进快出!不要在这里做耗时操作(如打印大量日志、延时)
// 从共享内存读取 M4 发来的状态/数据
uint32_t status = readl(dev->shm_base + STATUS_OFFSET);
// 如果数据量大,通常只把数据拷贝到环形缓冲区,然后唤醒等待队列
// 让下半部(Bottom Half)去慢慢处理
// --- 临界区结束 ---
// 【步骤2】释放自旋锁并恢复中断
spin_unlock_irqrestore(&dev->rx_lock, flags);
return IRQ_HANDLED;
}轻量级并发:原子操作
原子操作的作用: 它是CPU指令级别的保证,保证代码执行一气呵成,中间绝对插不进任何东西。
A. 整型原子操作 (操作 atomic_t 结构体)
不能直接对 atomic_t 里的 int counter 赋值,必须用专用函数。
| 操作 | 函数/宏 | 解释 |
|---|---|---|
| 定义 | atomic_t v = ATOMIC_INIT(1); |
定义 v 并初始化为 1 |
| 写 | atomic_set(&v, 5); |
把 v 设为 5 |
| 读 | val = atomic_read(&v); |
读取 v 的值 |
| 加减 | atomic_add(2, &v); |
v = v + 2 |
| 自增减 | atomic_inc(&v); |
v = v + 1 |
| 测试 | atomic_dec_and_test(&v); |
先减1,如果结果为0返回真。常用于引用计数。 |
B. 位原子操作 (操作 unsigned long)
用于控制硬件寄存器的标志位
| 操作 | 函数 | 解释 |
|---|---|---|
| 置位 | set_bit(nr, &addr); |
把第 nr 位 置1 |
| 清零 | clear_bit(nr, &addr); |
把第 nr 位 置0 |
| 翻转 | change_bit(nr, &addr); |
0变1,1变0 |
| 测试 | test_bit(nr, &addr); |
查看第 nr 位是 0 还是 1 |
| 测试并设置 | test_and_set_bit(...); |
原子级操作:读出旧值,写入1。用于实现"抢锁"。 |
实现一次只能打开一次的驱动
c
static atomic_t test_atomic = ATOMIC_INIT(1); // 初始为1
static int led_chrdev_open(...) {
// atomic_dec_and_test 执行步骤:
// 1. 值减1 (变为0)
// 2. 检查结果是否为0 (是)
// 3. 返回 true
// 整个过程绝对不会被打断
/*
atomic_read(&test_atomic) 直接这样就是错误的,因为这样放在if里面就不是原子的了
if(atomic_read(&test_atomic)) { // 第一步:读,如果是1 (空闲)
atomic_set(&test_atomic, 0); // 第二步:设为0 (占用)
}
*/
if (atomic_dec_and_test(&test_atomic)) {
printk("Open success!\n");
return 0;
} else {
// 如果原本是0,减1变成-1,test失败
// 如果原本是-1,减1变成-2,test失败
// 为了恢复逻辑,我们需要把它加回去 (虽然此时可能已经乱了,但在只有两个竞争者时通常配合 atomic_inc 使用)
atomic_inc(&test_atomic);
return -EBUSY;
}
}
static int led_chrdev_release(...) {
atomic_set(&test_atomic, 1); // 恢复为1
return 0;
}IPCC 中使用原子操作
多核通信项目中,原子操作非常适合做统计和轻量级标志位。
原子操作非常适合做统计和轻量级标志位。
统计接收包的数量
因为在中断里收消息,这是极快的过程,用锁太重了。
c
// 定义全局统计变量
static atomic_t rx_count = ATOMIC_INIT(0);
// 中断服务函数 (ISR)
static irqreturn_t my_ipcc_rx_handler(...) {
// ... 读取数据 ...
// 原子自增,绝对安全,不会因为并发中断导致计数丢失
atomic_inc(&rx_count);
return IRQ_HANDLED;
}
// 在 APP 读取统计时
ssize_t read_count(...) {
int count = atomic_read(&rx_count);
// ... copy_to_user ...
}判断 M4 是否存活
可以用一个原子变量作为心跳计数。
c
// A7 每秒检查一次
if (atomic_read(&m4_heartbeat) == last_value) {
printk("M4 死机了!\n");
}总结说明
| 比较维度 | 原子操作 (Atomic Operations) | 自旋锁 (Spinlock) | 互斥体 (Mutex) |
|---|---|---|---|
| 定义与核心概念 | 最小的不可分割指令序列。 由硬件保证操作在执行过程中绝不会被中断,中间状态对外不可见。 | 一种基于忙等待 (Busy-Wait) 的多线程同步锁机制。 当获取锁失败时,执行单元不会挂起,而是在循环中不断检测锁状态。 | 一种基于调度机制 (Sleep-Wait) 的互斥锁机制。 当获取锁失败时,执行单元会主动放弃 CPU,进入睡眠状态等待唤醒。 |
| 底层实现原理 | 依赖 CPU 指令集架构 (ISA)。 如 ARM 的 LDREX / STREX (独占加载/存储) 和总线锁。 |
依赖原子操作 + 循环判断。 通常使用 "Test-and-Set" 原子指令修改锁标志位。 | 依赖原子操作 + 操作系统调度器。 维护一个等待队列 (Wait Queue),涉及进程状态切换。 |
| 保护粒度 | 极小 仅限单个整型变量或位 (Bit)。 | 小 保护极短的代码片段或临界区。 | 大 保护复杂的代码块、大数据结构或长逻辑。 |
| 竞争时的行为 | 无等待 硬件指令立即执行成功或重试,无"锁"的概念。 | 忙等待 (Spinning) CPU 保持运行状态(空转),占用 100% 算力,直到拿到锁。 | 挂起 (Blocking) 当前进程从运行队列移除,发生上下文切换,CPU 转去执行其他任务。 |
| 上下文限制 | 无限制 可在中断上下文 (ISR) 和进程上下文中使用。 | 无限制 (但在中断中是唯一选择) 可在中断上下文和进程上下文中使用。 | 仅限进程上下文 严禁在中断上下文中使用 (因为中断不能休眠)。 |
| 临界区要求 | 不可休眠 指令级操作,瞬间完成。 | 严禁休眠 持有锁期间绝对不能调用导致调度的函数 (如 kmalloc, copy_from_user)。 |
允许休眠 持有锁期间可以执行 I/O 操作或内存分配。 |
| 适用场景 | 引用计数、状态标志位、统计变量。 | 中断服务程序 (ISR)、多核间共享数据的极短操作。 | 文件读写、用户空间内存拷贝、设备配置等长耗时操作。 |