文章目录
前言
跟踪PG向量库embedding存储,即需要分析: kb --recreate-vs 命令,重新创建向量库以及文本内容加强embedding存储。
前提
1.Langchain-Chatchat一、本地开发环境部署
2.已安装Pg向量库
kb_settings.yaml文件配置
yaml
# 默认使用的知识库
DEFAULT_KNOWLEDGE_BASE: samples
# 默认向量库/全文检索引擎类型
# 可选值:['faiss', 'milvus', 'zilliz', 'pg', 'es', 'relyt', 'chromadb']
DEFAULT_VS_TYPE: pg
kbs_config:
faiss: {}
......
pg:
connection_uri: postgresql://postgres:postgres@127.0.0.1:5432/postgres
relyt:
connection_uri: postgresql+psycopg2://postgres:postgres@127.0.0.1:5432/postgres
PyCharm 配置debug调试参数:kb --recreate-vs
一、创建向量库并加强embedding存储文本流程图
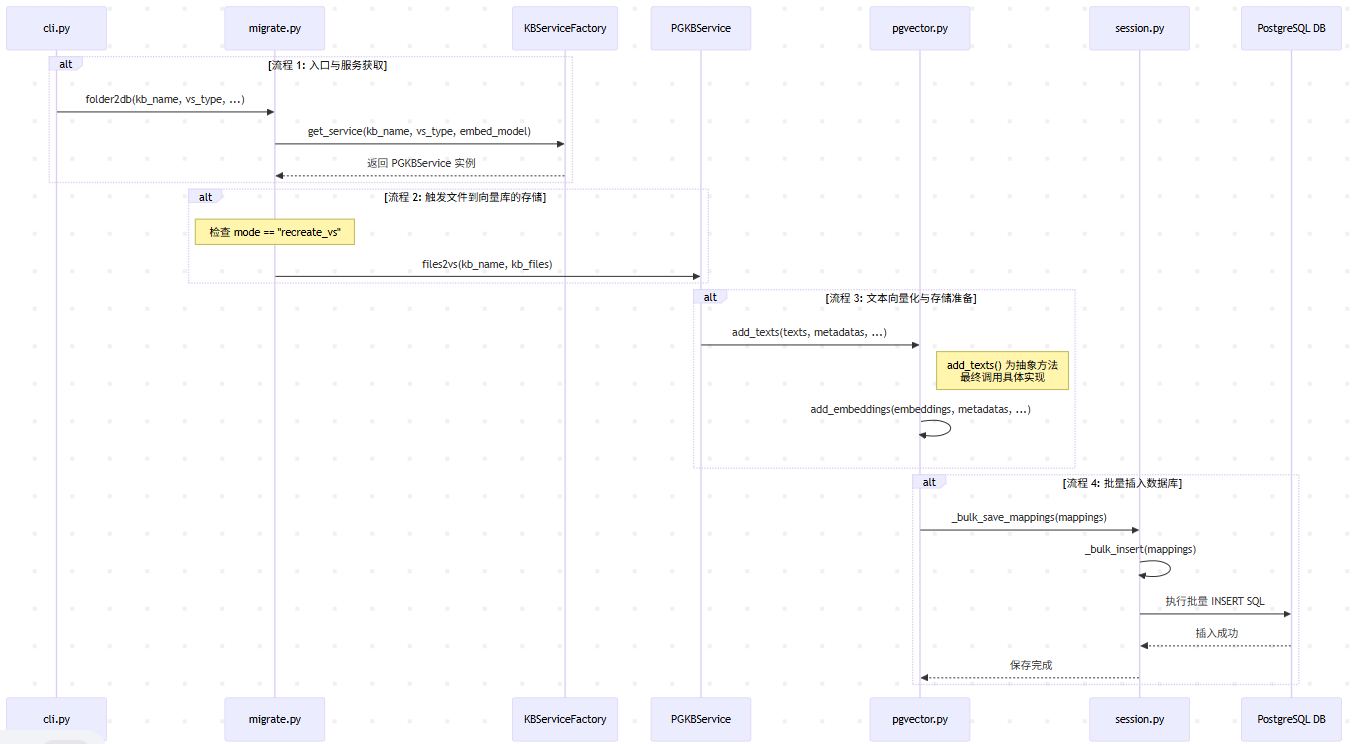
二、流程核心部分说明
文本内容加强(embeddings)存储
pg_kb_service.py#def _load_pg_vector(self):
代码如下(片断):
python
class PGKBService(KBService):
engine: Engine = sqlalchemy.create_engine(
Settings.kb_settings.kbs_config.get("pg").get("connection_uri"), pool_size=10
)
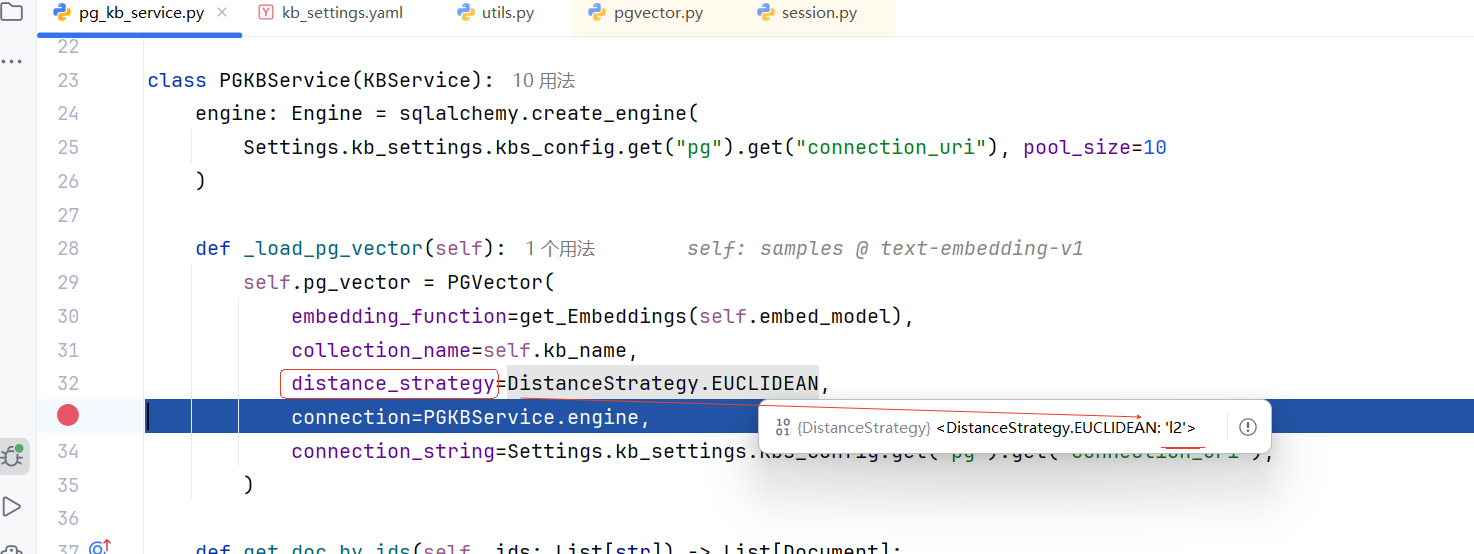
def _load_pg_vector(self):
self.pg_vector = PGVector(
embedding_function=get_Embeddings(self.embed_model),
collection_name=self.kb_name,
distance_strategy=DistanceStrategy.EUCLIDEAN, #DistanceStrategy.EUCLIDEAN = "l2" 点积
connection=PGKBService.engine,
connection_string=Settings.kb_settings.kbs_config.get("pg").get("connection_uri"),
)
python
class PGVector(VectorStore):
def __init__(
self,
connection_string: str,
embedding_function: Embeddings,
embedding_length: Optional[int] = None,
collection_name: str = _LANGCHAIN_DEFAULT_COLLECTION_NAME,
collection_metadata: Optional[dict] = None,
distance_strategy: DistanceStrategy = DEFAULT_DISTANCE_STRATEGY,
pre_delete_collection: bool = False,
logger: Optional[logging.Logger] = None,
relevance_score_fn: Optional[Callable[[float], float]] = None,
*,
connection: Optional[sqlalchemy.engine.Connection] = None,
engine_args: Optional[dict[str, Any]] = None,
use_jsonb: bool = False,
create_extension: bool = True,
) -> None:
"""Initialize the PGVector store."""
self.connection_string = connection_string
self.embedding_function = embedding_function
self._embedding_length = embedding_length
self.collection_name = collection_name
self.collection_metadata = collection_metadata
self._distance_strategy = distance_strategy #DistanceStrategy.EUCLIDEAN = "l2" 点积
self.pre_delete_collection = pre_delete_collection
self.logger = logger or logging.getLogger(__name__)
self.override_relevance_score_fn = relevance_score_fn
self.engine_args = engine_args or {}
self._bind = connection if connection else self._create_engine()
self.use_jsonb = use_jsonb
self.create_extension = create_extension
.....说明:PG向量库类等默认向量相似度为最大内积:(点积)衡量相似性 L2
如图:
三、存储PG向量库表
1.distance_strategy=DistanceStrategy.EUCLIDEAN
默认配置参数:DistanceStrategy.EUCLIDEAN = "l2" ,最大内积(点积),_embedding值范围为:(负穷大,正无穷大)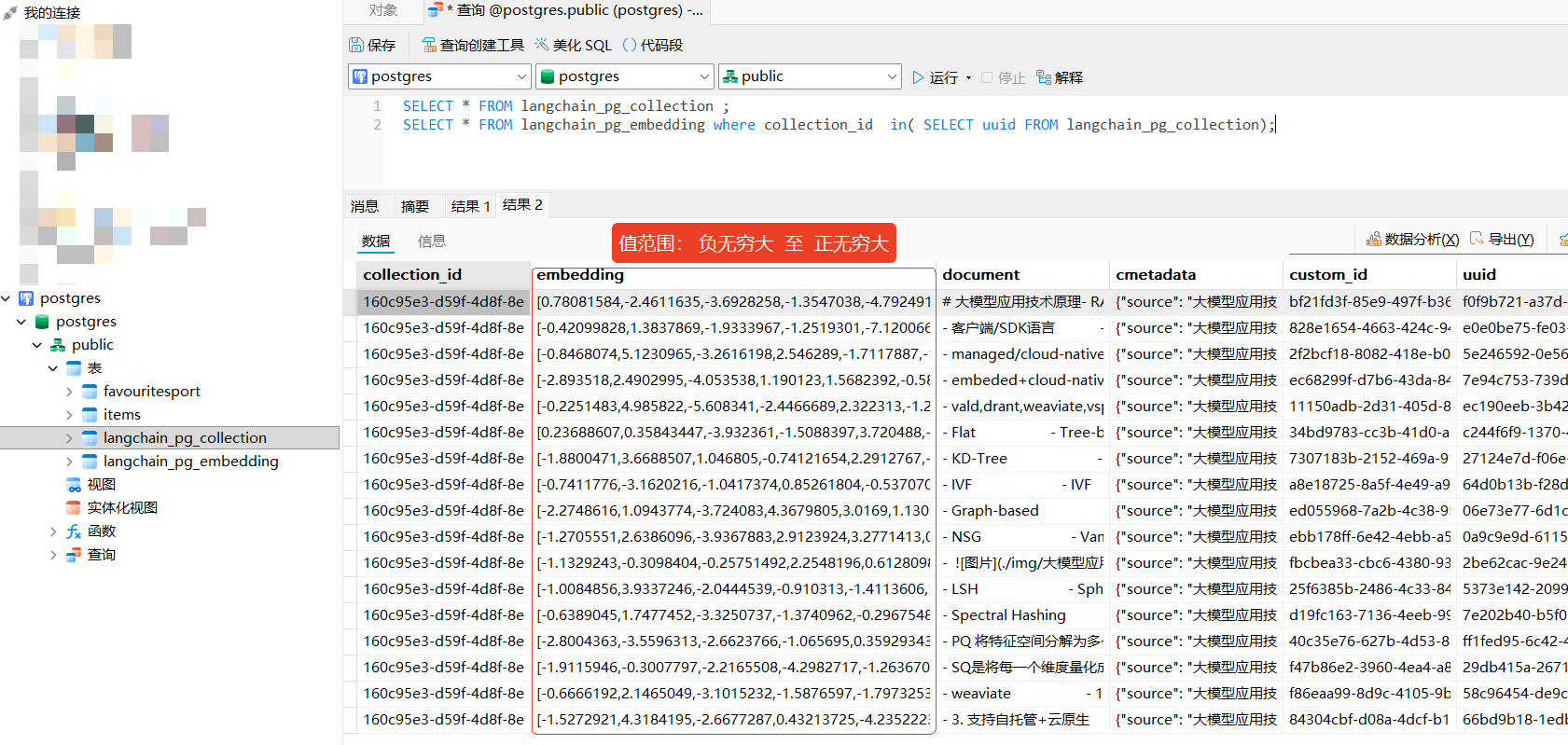
2.distance_strategy=DistanceStrategy.COSINE
修改配置参数:DistanceStrategy.EUCLIDEAN = "cosine" ,余弦相似度, 如图: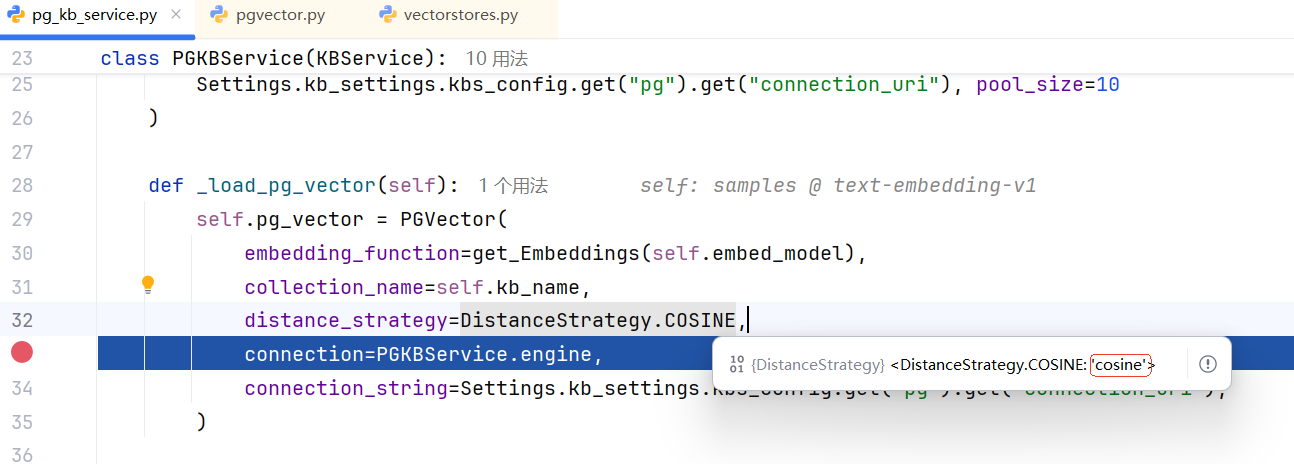
_embedding加强存储,值范围为:(-1,1)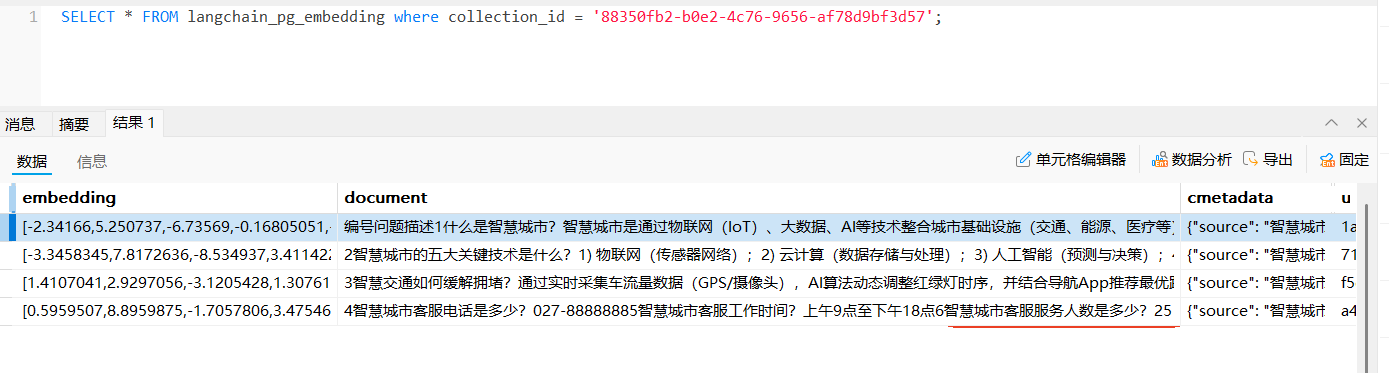
存在的问题: 修改PG库distance_strategy参数后并未改变 文档内容_embedding值范围,不清楚是否是 Pg库问题还是其它问题,等待分析。
3.策略配置参数distance_strategy
文本内容加强embedding(向量化)存储值由数据库创建向量索引策略方式确定,目前LangChain VectorStores支持向量索引策略计算方法有三种,策略如下:
- 欧氏距离:欧氏距离(L2范数)计算向量差异。
- 最大内积:(点积)衡量相似性,适用于高维向量场景,如:PG向量库embedding默认 L2。
- 余弦相似度:COSINE 归一化向量后计算夹角余弦值 。
