在复杂的数据生态中,数据血缘被视为理解数据流向的"地图"。然而,大多数企业的数据血缘图谱是残缺的:DBA 能看到表与表的关系,应用开发能看到服务与服务的调用,但介于两者之间的核心逻辑**"SQL 查询"** ,却往往隐藏在代码深处,成为血缘链路中的"黑盒"。本文将探讨如何利用 Web 原生架构(集成 SQL 管理与 API 发布),通过"SQL 即服务"的模式,自动解析并串联起从底层物理表到上层 API 接口的完整依赖关系,实现数据血缘的"自动驾驶"。

1. 困局:断裂的血缘链条
"改了一个字段,结果整个 BI 系统崩了。"
这是数据团队最不愿听到的事故,却是最常发生的悲剧。
造成这种"蝴蝶效应"的根源,在于企业数据血缘链路的结构性断裂。在传统的 IT 架构中,数据流转被割裂在两个平行的世界里:
-
数据库: 这里有表、视图和存储过程。DBA 使用专业的数据库工具管理它们,清晰地知道表之间的外键依赖。
-
应用层: 这里有 Java/Go 代码和 API 接口。开发人员使用 IDE 和 APM 工具,清晰地知道微服务之间的调用链。
断裂点在哪里? 就在SQL。
在传统模式下,SQL 语句是以"字符串"的形式硬编码在后端代码(如 MyBatis XML, Java String)里的。
-
数据库不知道这段 SQL 属于哪个 API。
-
API 网关也不知道这个接口底层查了哪张表。
这导致了一个巨大的治理黑盒:当 DBA 想要修改表结构时,他无法评估会影响上层哪些业务;当业务方发现数据错误时,很难快速定位是底层哪段 SQL 逻辑出了问题。企业花费巨资购买的元数据管理工具,往往只能扫描到表级血缘,却无法穿透代码层,打通这"最后一公里"。
2. 破局:Web 架构的"上帝视角"
要修复这条断裂的链条,靠"事后代码扫描"是非常困难且不准确的。最高效的解法是架构融合。
如果有一个平台,既是 DBA 管理数据库的控制台 ,又是开发人员发布 API 的生产车间,那么血缘问题将迎刃而解。
这就是 Web 原生数据库管理 + 低代码 API 平台 的核心价值。它通过将"SQL 编写"和"API 发布"两个动作在同一个 Web 平台 上完成,实现了血缘的内生性。
在这种架构下,血缘不再是"事后分析"出来的,而是"生产过程"的副产品。
3. 核心机制:全链路追踪是如何"自动驾驶"的?
让我们剖析一下,在这个统一的 Web 平台上,一条完整的端到端血缘是如何自动生成的。
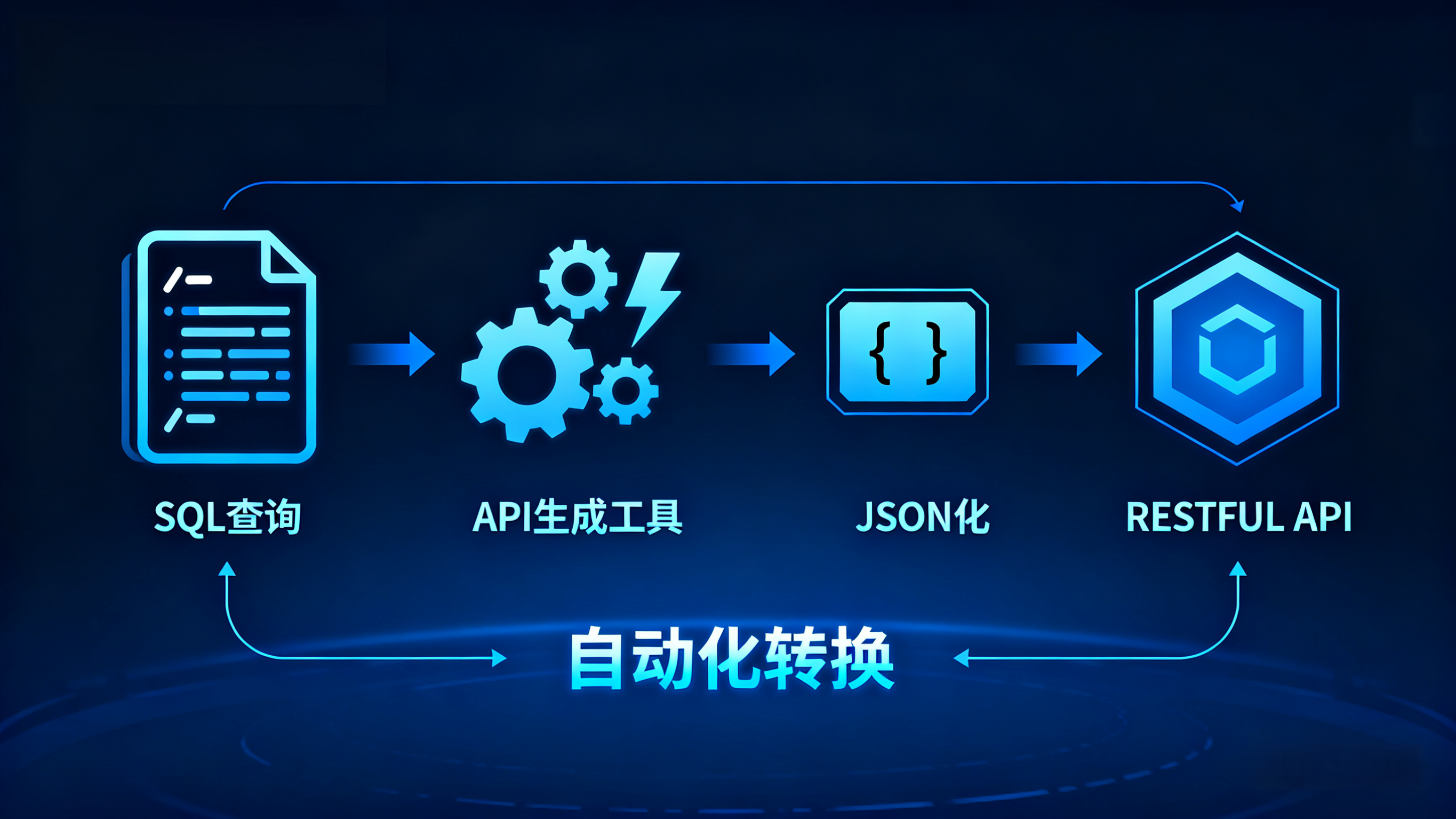
3.1 环节一:SQL 解析与对象识别
当开发人员在 Web 平台的 SQL 编辑器中编写查询语句(例如用于发布一个新 API)时,平台内置的 SQL 解析引擎会实时工作。
它不只是把 SQL 当作文本,而是将其解析为抽象语法树。
-
输入:
SELECT u.name, o.amount FROM users u JOIN orders o ON u.id = o.uid WHERE o.status = 1 -
识别: 平台自动提取出依赖对象:
Table: users,Table: orders,Column: name,Column: amount。 -
记录: 这些依赖关系被立即写入元数据仓库,而不是等代码提交后再去扫描。
3.2 环节二:逻辑对象的资产化
在传统开发中,SQL 散落在代码里。在 Web 平台中,这段 SQL 被保存为一个"数据服务对象"。
平台为其分配唯一的 ID。这个 ID 成为了连接底层数据和上层应用的关键锚点。
此时,血缘关系建立了第一层:物理表 --> 数据服务对象(SQL)。
3.3 环节三:API 的服务化绑定
开发人员在 Web 界面上将这个"数据服务对象"一键发布为 RESTful API(例如 /api/v1/user_orders)。
平台自动记录下这个绑定关系。
此时,血缘关系建立了第二层:数据服务对象(SQL) --> API 接口。
3.4 环节四:消费端的闭环
当业务系统(如 BI 报表、前端 App)调用这个 API 时,平台通过 API 网关的鉴权机制,识别出调用者身份。
此时,血缘关系完成了最后的闭环:API 接口 --> 消费应用。
至此,一条清晰的、实时的、自动化的全链路血缘图谱诞生了:
Table: orders (物理层)
↓
Logic: OrderQuery SQL (逻辑层)
↓
API: /get_orders (服务层)
↓
App: 财务月报系统 (应用层)
4. 实战价值:从"被动救火"到"主动防御"
拥有了这套"自动驾驶"的血缘图谱,企业的数据治理能力将发生质的飞跃。
4.1 变更影响分析:告别"盲改"
-
场景: DBA 计划对
orders表进行分库分表改造,或者删除一个废弃字段legacy_status。 -
传统模式: DBA 发邮件问全员"谁用了这个字段?",通常没人回,或者回的不准。DBA 只能硬着头皮改,祈祷不出事。
-
Web 架构模式: DBA 在平台点击该字段,查看"血缘影响图"。系统提示:"警告! 该字段被 3 个在线 API 引用,分别是'财务报表'和'物流查询',对应的 SQL 逻辑如下......"。
-
价值: 在故障发生前将其拦截,实现了真正的"主动防御"。
4.2 根因分析:分钟级定责
-
场景: 业务方投诉"客户画像查询接口"数据不准,且响应很慢。
-
传统模式: 后端开发查代码 -> 发现代码逻辑没问题 -> 怀疑数据库 -> 找 DBA -> DBA 抓包分析 SQL。流程漫长。
-
Web 架构模式: 运维人员点击该 API 的血缘图,直接看到其背后的 SQL。发现 SQL 中用了一个全表扫描的
JOIN,且依赖的底层表user_logs昨天刚激增了 1000 万条数据。 -
价值: 视线瞬间穿透应用层直达数据层,快速定位性能瓶颈或逻辑错误。
4.3 资产瘦身:清理"僵尸数据"
-
场景: 数据库空间报警,需要清理无用表。
-
传统模式: 不敢删,怕删错。
-
Web 架构模式: 基于血缘和调用日志,平台列出"过去 90 天未被任何 API 调用的表"。
-
价值: 放心下线无用资产,降低存储和维护成本。
5. 结语
数据血缘不应该是一个需要企业花费数月时间去"梳理"的静态文档,它应该是企业数据基础设施运行时自然产生的动态快照。
通过引入 Web 原生架构,将数据库管理与 API 服务发布整合在同一个平台上,我们消除了"SQL"这个最大的黑盒。这种架构创新,让数据血缘从"手工绘制"时代跨入了"自动驾驶"时代。
z更重要的是,它赋予了企业在复杂的数字化系统中,进行精确变更、快速排障和资产优化的核心能力。