文章目录
- [1. 概述](#1. 概述)
-
- [1.1. playwright 具有以下特点](#1.1. playwright 具有以下特点)
-
- [1.1.1. 支持所有主流浏览器](#1.1.1. 支持所有主流浏览器)
- [1.1.2. 快速可靠的执行:](#1.1.2. 快速可靠的执行:)
- [1.1.3. 强大的自动化能力](#1.1.3. 强大的自动化能力)
- [2. 安装部署](#2. 安装部署)
-
- [2.1. 本地安装](#2.1. 本地安装)
- [2.2. 离线安装](#2.2. 离线安装)
-
- [2.2.1. 打包 ms-playwright](#2.2.1. 打包 ms-playwright)
- [2.2.2. 打包 site-packages](#2.2.2. 打包 site-packages)
- [3. 命令行工具](#3. 命令行工具)
-
- [3.1. 脚本录制(codegen)](#3.1. 脚本录制(codegen))
-
- [3.1.1. 格式说明](#3.1.1. 格式说明)
- [3.1.2. 示例](#3.1.2. 示例)
- [3.2. 打开网页(open)](#3.2. 打开网页(open))
-
- [3.2.1. 格式说明](#3.2.1. 格式说明)
- [3.2.2. 示例](#3.2.2. 示例)
- [3.3. 截图(screenshot)](#3.3. 截图(screenshot))
-
- [3.3.1. 格式说明](#3.3.1. 格式说明)
- [3.3.2. 示例](#3.3.2. 示例)
- [4. 进阶](#4. 进阶)
-
- [4.1. 浏览器](#4.1. 浏览器)
-
- [4.1.1. 浏览器支持](#4.1.1. 浏览器支持)
- [4.1.2. 浏览器上下文](#4.1.2. 浏览器上下文)
- [4.1.3. 多页面](#4.1.3. 多页面)
- [4.1.4. 断言](#4.1.4. 断言)
- [4.1.5. Robot Framework 库](#4.1.5. Robot Framework 库)
- [4.2. 定位](#4.2. 定位)
-
- [4.2.1. 通过 CSS 或 XPath 定位](#4.2.1. 通过 CSS 或 XPath 定位)
- [4.3. 同步异步](#4.3. 同步异步)
-
- [4.3.1. 用例介绍](#4.3.1. 用例介绍)
- [4.3.2. 同步方式](#4.3.2. 同步方式)
- [4.3.2. 异步方式](#4.3.2. 异步方式)
转发自:
https://blog.csdn.net/u010698107/article/details/121069640
playwright连接已有浏览器操作
https://blog.51cto.com/u_15800928/6952318
playwright长截图&切换标签页&JS注入实战
https://blog.51cto.com/u_15800928/7735545
Playwright基础教程(二)
https://blog.51cto.com/u_15800928/8751226
Playwright基础教程(三)定位操作
https://blog.51cto.com/u_15800928/8751232
Playwright基础教程(四)事件操作①高亮&元素匹配器&鼠标悬停
https://blog.51cto.com/u_15800928/8751239
Playwright基础教程(五)事件操作②悬停&输入&清除精讲
https://blog.51cto.com/u_15800928/8751242
Playwright基础教程(六)事件操作③单击&双击&计数&过滤&截图&JS注入
https://blog.51cto.com/u_15800928/8751231
Playwright基础教程(七)Keyboard键盘
https://blog.51cto.com/u_15800928/8751234
Playwright基础教程(八)鼠标操作
https://blog.51cto.com/u_15800928/8751245
Playwright基础教程(九)-悬浮元素定位&自定义ID定位&组合定位&断言
https://blog.51cto.com/u_15800928/8751246
Playwright基础教程(十)元素拖拽&元素坐标&获取网页源码&元素内文本
https://blog.51cto.com/u_15800928/8751247
1. 概述
playwright 是由微软开发的 Web UI 自动化测试工具, 支持 Node.js、Python、C# 和 Java 语言。
1.1. playwright 具有以下特点
1.1.1. 支持所有主流浏览器
- 支持所有主流浏览器:
基于 Chromium 内核的 Google Chrome 和 Microsoft Edge 浏览器),WebKit 内核的 Apple Safari 和 Mozilla Firefox 浏览器,不支持 IE11。 - 跨平台:
Windows、Linux 和 macOS - 可用于模拟移动端 WEB 应用的测试,不支持在真机上测试。
- 支持无头模式(默认)和有头模式
1.1.2. 快速可靠的执行:
- 自动等待元素
- playwright 基于 Websocket 协议,可以接受浏览器(服务端)的信号。selenium 采用的是 HTTP 协议,只能客户端发起请求。
- 浏览器上下文并行:单个浏览器实例下创建多个浏览器上下文,每个浏览器上下文可以处理多个页面。
- 有弹性的元素选择:可以使用文本、可访问标签选择元素。
1.1.3. 强大的自动化能力
- playwright 是一个进程外自动化驱动程序,它不受页面内JavaScript执行范围的限制,可以自动化控制多个页面。
- 强大的网络控制:playwright 引入了上下文范围的网络拦截来存根和模拟网络请求。
- 现代 web 特性:支持 Shadow DOM 选择,元素位置定位,页面提示处理,Web Worker 等 Web API。
- 覆盖所有场景:支持文件下载、上传、OOPIF(out-of-process iframes),输入、点击,暗黑模式等。
2. 安装部署
2.1. 本地安装
playwright 有 Node.js、Python、C# 和 Java 语言版本,本文介绍 Python 版本的playwright 使用方法。
playwright 的 Python 版本仓库地址:https://github.com/microsoft/playwright-python
官方文档地址:https://playwright.dev/python/docs/intro
playwright 安装简单,pip 安装时会自动下载浏览器驱动:
bash
pip install playwright
playwright install # 安装支持的浏览器:cr, chromium, ff, firefox, wk 和 webkit
playwright install chromium # 安装指定的chromium浏览器安装时会自动下载浏览器依赖,windows 系统在%USERPROFILE%\AppData\Local\ms-playwright 路径下。
2.2. 离线安装
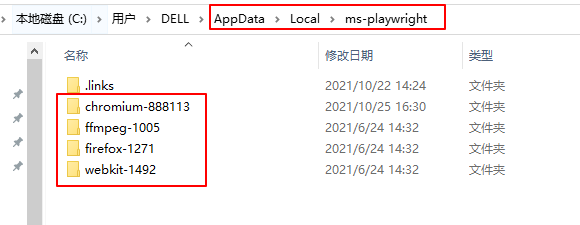
2.2.1. 打包 ms-playwright
将 %USERPROFILE%\AppData\Local\ms-playwright 路径下的文件打包,并再新环境中重建。
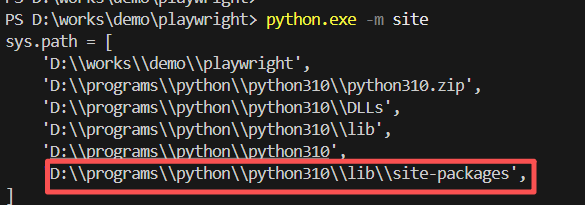
2.2.2. 打包 site-packages
使用 python.exe -m site 找到所以依赖文件打包,并再新环境中解压。
3. 命令行工具
3.1. 脚本录制(codegen)
3.1.1. 格式说明
在命令行窗口使用如下语法格式进行脚本录制:
bash
npx playwright codegen [options] [url]options参数:
-o, --output :保存生成脚本
--target :生成的脚本语言,可以设置javascript, test, python, python-async和csharp,默认为python。
-b, --browser :要使用的浏览器,可以选择cr, chromium, ff, firefox, wk和webkit,默认chromium。
--channel :chromium版本,比如chrome, chrome-beta, msedge-dev等,
--color-scheme :模拟器的颜色主题,可选择light 或者 dark样式。
--device :模拟的设备,比如iPhone 11。
--save-storage :保存上下文状态,用于保存cookies 和localStorage,可用它来实现重用。例如playwright codegen --save-storage=auth.json
--load-storage :加载--save-storage 保存的数据,重用认证数据。
--proxy-server :指定代理服务器
--timezone : 指定时区
--geolocation :指定地理位置坐标
--lang :指定语言/地区,比如中国大陆:zh-CN
--timeout :超时时间,定位毫秒,默认10000ms
--user-agent :用户代理
--viewport-size :浏览器窗口大小
-h, --help :查看帮助信息
3.1.2. 示例
模拟 iPhone 12 Pro 设备打开百度,使用 Chromium 驱动,生成的脚本语言设置为 python,保存名称为 test_playwright.py:
bash
playwright codegen -o test_playwright.py --target python -b chromium --device="iPhone 12 Pro" https://www.baidu.com/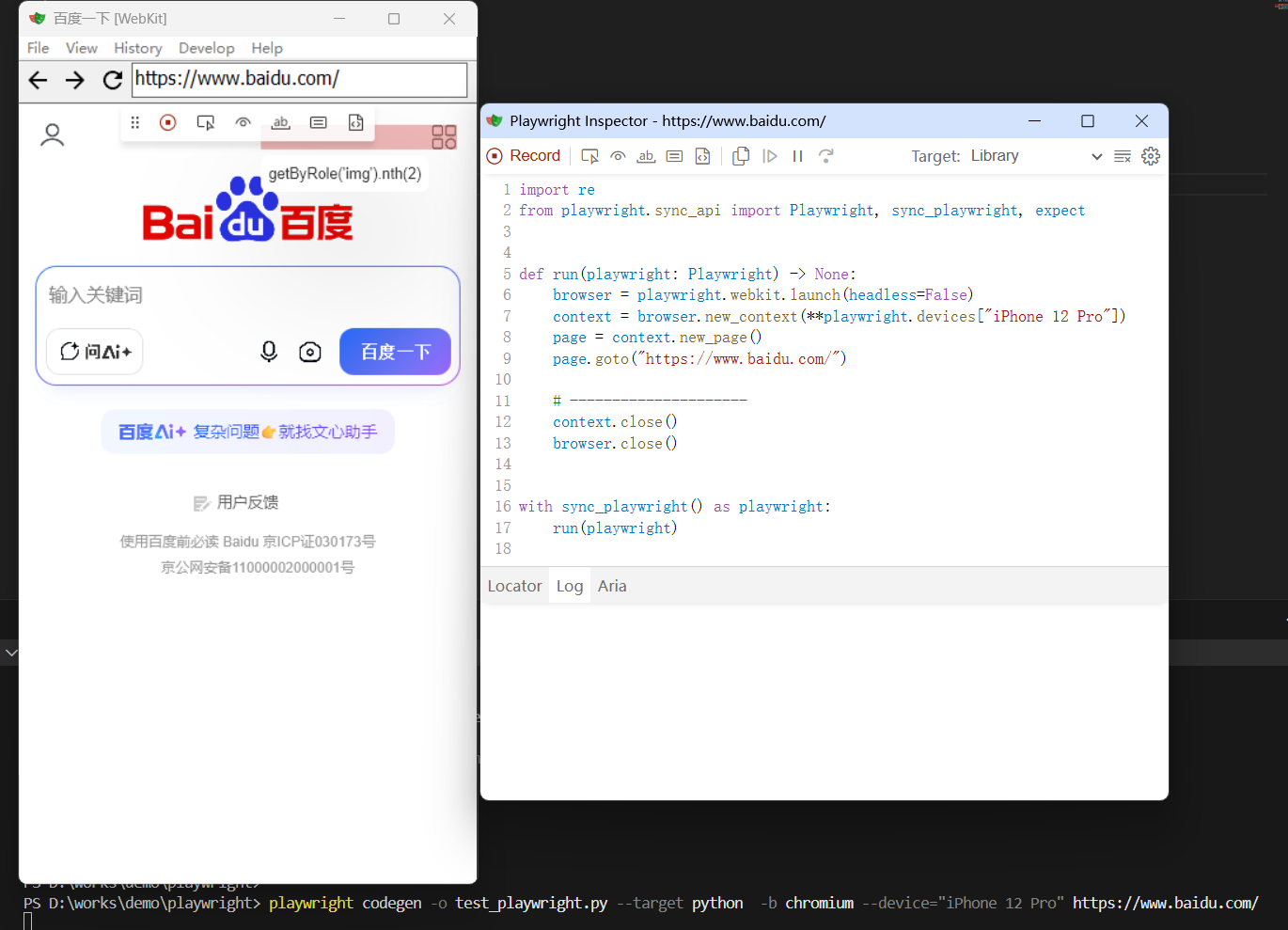
对页面进行的操作会生成对应脚本代码。
3.2. 打开网页(open)
3.2.1. 格式说明
bash
npx playwright open [options] [url]除了没有 -o 和 --target options参数外,playwright open 支持 playwright codegen 的其它参数。
3.2.2. 示例
bash
playwright open https://www.baidu.com/ # 默认使用Chromium打开
playwright wk https://www.baidu.com/ # 使用WebKit打开
playwright open --device="iPhone 12 Pro" https://www.baidu.com/ # 使用iPhone 12 Pro模拟器打开
3.3. 截图(screenshot)
3.3.1. 格式说明
bash
npx playwright screenshot [options] <url> <filename>options 参数和 playwright codegen 的选项类似,可以使用 playwright screenshot --help 命令查看。
3.3.2. 示例
bash
playwright screenshot --device="iPhone 12 Pro" -b wk https://www.baidu.com/ baidu-iphone.png # 截取显示的页面
playwright screenshot --full-page --device="iPhone 12 Pro" -b wk https://www.baidu.com/ baidu-iphone-full-page.png # 截取当前全部页面
4. 进阶
4.1. 浏览器
4.1.1. 浏览器支持
前面提到过,playwright 支持所有主流浏览器,下面介绍4种浏览器的启动方法:
bash
# chrome
browser = p.chromium.launch(channel="chrome", headless=False)
# Microsoft Edge
browser = p.chromium.launch(channel="msedge", headless=False)
# firefox
browser = p.firefox.launch(headless=False)
# webkit
browser = p.webkit.launch(headless=False)4.1.2. 浏览器上下文
在进行 web 自动化控制之前需要对浏览器进行实例化,比如:
bash
browser = p.chromium.launch(channel="chrome", headless=False)browser 是一个 Chromium 实例,创建实例其实是比较耗费资源的。
Playwright 支持在一个 browser 实例下创建多个浏览器上下文(BrowserContext),BrowserContext 的创建速度很快,并且比创建 browser 实例消耗资源更少。对于多页面场景可以使用创建浏览器上下文的方式。
python
import asyncio
from playwright.async_api import async_playwright
async def testcase1():
print('testcase1 start')
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto("https://www.baidu.com/")
print(await page.title())
await page.fill("input[name=\"wd\"]", "test")
await page.click("text=百度一下")
await page.click("#page >> text=2")
context = await browser.new_context()
page2 = await context.new_page()
await page2.goto("https://www.sogou.com/")
print(await page2.title())
await page2.fill("input[name=\"query\"]", "test")
await page2.click("text=搜狗搜索")
await page2.click("#sogou_page_2")
print(await page.title())
print('testcase1 done')
asyncio.run(testcase1())4.1.3. 多页面
一个浏览器上下文可以有多个页面,也就是多个窗口。
python
async def testcase2():
print('testcase2 start')
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context()
page1 = await context.new_page()
await page1.goto("https://www.sogou.com/")
print(await page1.title())
await page1.fill("input[name=\"query\"]", "test")
await page1.click("text=搜狗搜索")
await page1.click("#sogou_page_2")
page2 = await context.new_page()
await page2.goto("https://www.baidu.com/")
print(await page2.title())
print('testcase2 done')4.1.4. 断言
Python 中可以使用 assert 进行断言:
python
assert page.title() == "百度一下,你就知道"除了使用 assert 断言以外,还可以使用功能更加强大的断言方法 Hamcrest ,具有丰富的断言匹配器。
安装 PyHamcrest:
bash
pip install PyHamcrest
python
from hamcrest import *
assert_that(page.title(), equal_to("百度一下,你就知道"))4.1.5. Robot Framework 库
如果你使用 robot framework 来管理和编写测试用例,可以使用 robotframework-browser 测试库。
browser 测试库的github地址:https://github.com/MarketSquare/robotframework-browser, 安装方法参考README.md文档。
关键字使用说明文档:https://marketsquare.github.io/robotframework-browser/Browser.html
安装失败:
https://github.com/MarketSquare/robotframework-browser/issues/682
可能是 node 版本太高,可以使用 node v12.9.1版本
4.2. 定位
4.2.1. 通过 CSS 或 XPath 定位
如果使用 CSS 或 XPath 定位器,则可以使用 page.locator() 创建一个定位器,该定位器采用一个选择器来描述如何在页面中查找元素。Playwright 支持 CSS 和 XPath 选择器,如果省略 css= 或 xpath= 前缀,则会自动检测它们。示例代码:
python
page.locator("css=button").click()
page.locator("xpath=//button").click()
# 省略 css= 或 xpath= 前缀
page.locator("button").click()
page.locator("//button").click()示例:
python
import asyncio
import time
from playwright.async_api import async_playwright
async def testcase1():
print('testcase1 start')
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto("https://www.baidu.com/")
print(await page.title())
await page.click("text=百度一下")
# await page.click("#page >> text=2")
# await page.locator('//input[@name="wd"]').fill("搜索")
# await page.locator('//input[@id="chat-input-area"]').fill("搜索")
await page.locator("[class='chat-input-textarea chat-input-scroll-style']").first.fill("搜索")
# 如果控件有多个,与上面等效
# await page.locator("[class='chat-input-textarea chat-input-scroll-style']").nth(0).fill("搜索")
# await browser.close()
await page.wait_for_timeout(3000)
print('testcase1 done')
async def main():
task1 = asyncio.create_task(testcase1())
tasks = [task1]
print('before await')
await asyncio.gather(*tasks)
start = time.time()
asyncio.run(main())
end = time.time()
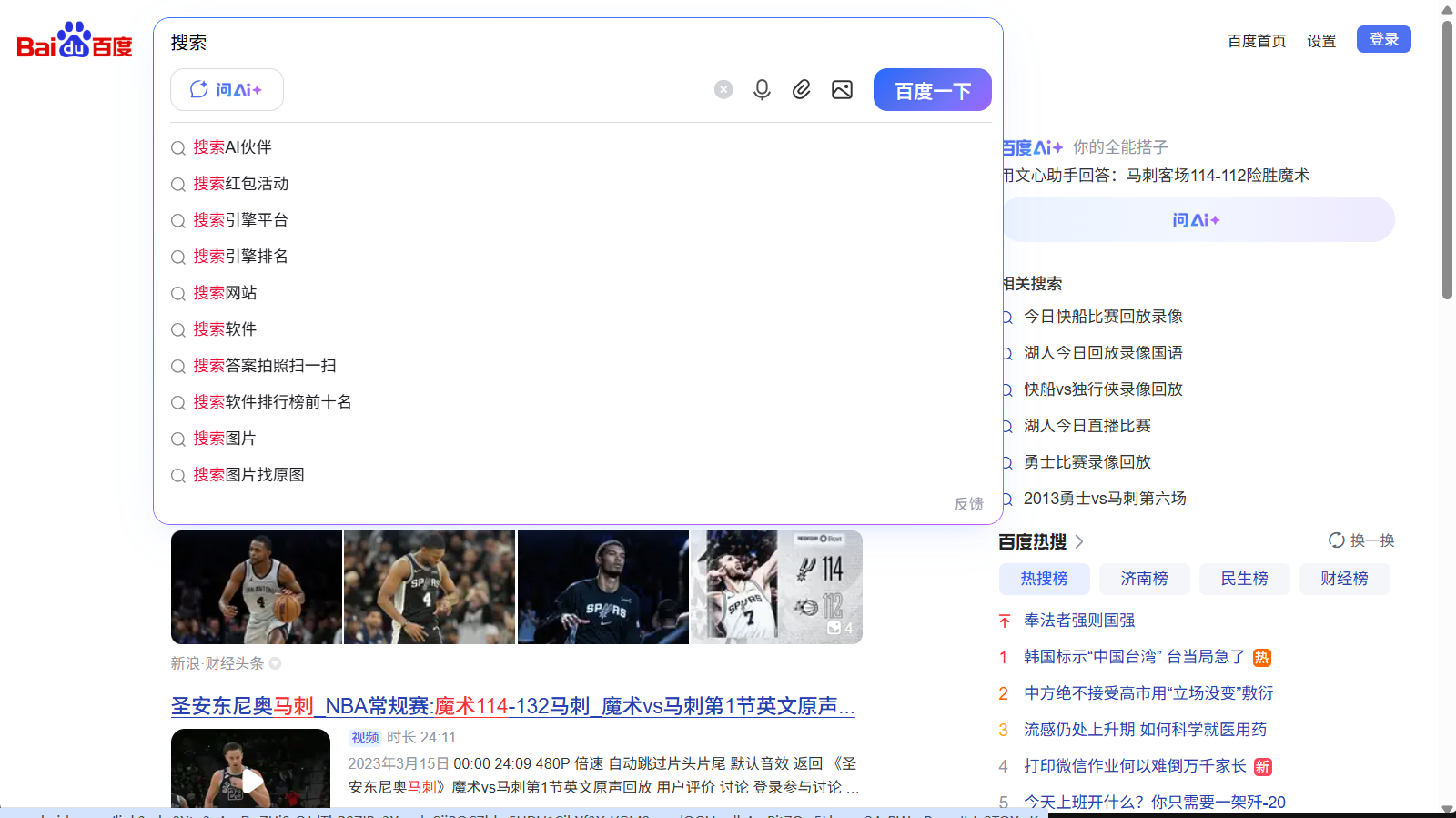
print('Running time: %s Seconds'%(end-start))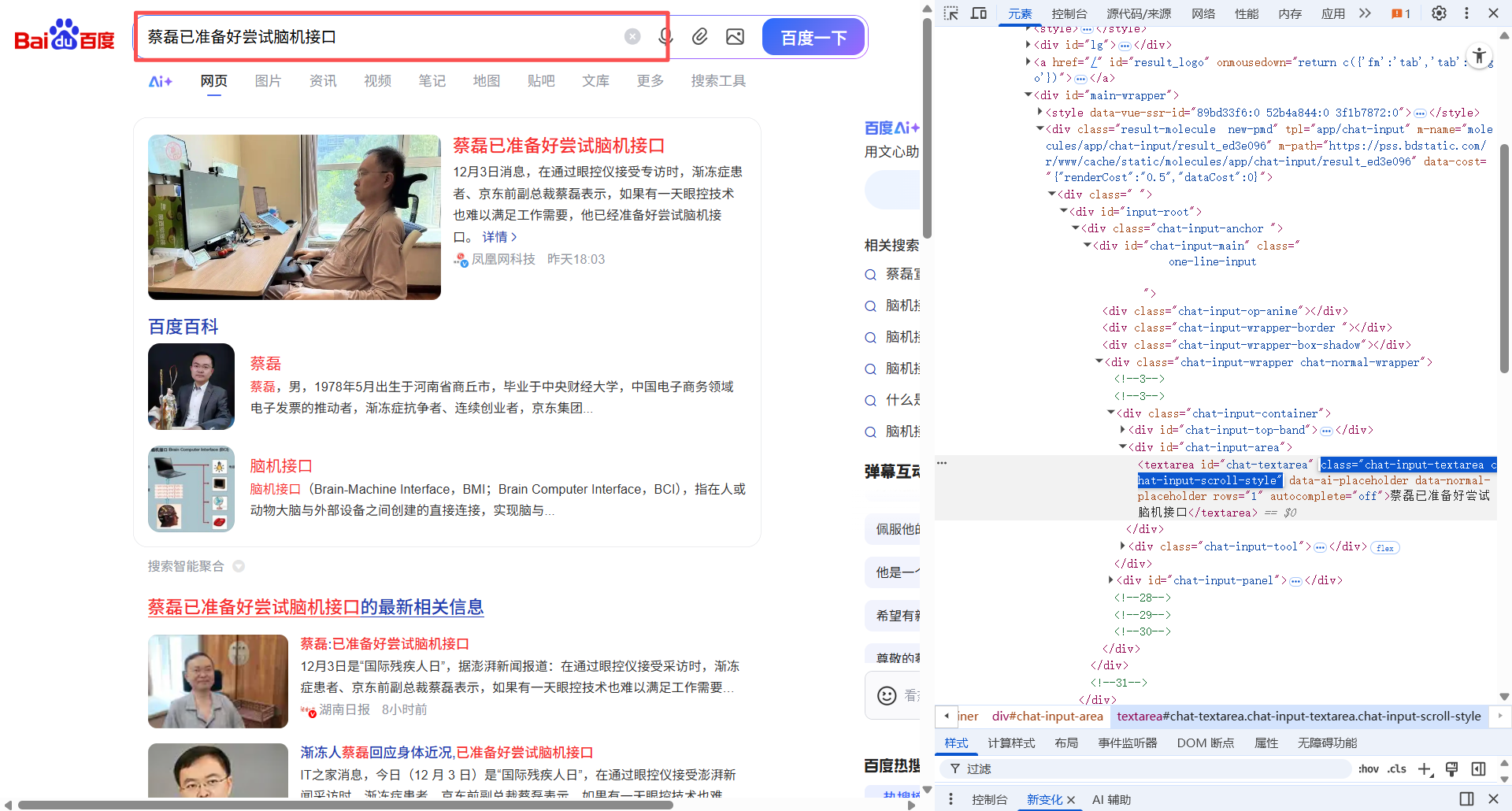
运行之后:"搜索" 二字被填入。
4.3. 同步异步
playwright 支持同步和异步两种 API,使用异步 API 需要导入asyncio 库,它是一个可以用来实现 Python 协程的库,更详细介绍可参考 Python 协程 。
4.3.1. 用例介绍
下面介绍如何使用 python 语言编写简单的 playwright 自动化脚本。一共有2条测试用例:
- 用例1步骤如下:
- chrome浏览器打开百度
- 搜索框输入"test"
- 点击百度一下搜索
- 点击搜索结果的第2页
- 用例2步骤:
- chrome浏览器打开搜狗搜索
- 搜索框输入"test"
- 点击搜狗搜索
- 点击搜索结果的第2页
4.3.2. 同步方式
python
import time
from playwright.sync_api import sync_playwright
def testcase1():
print('testcase1 start')
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.baidu.com/")
print(page.title())
page.fill("input[name=\"wd\"]", "test")
page.click("text=百度一下")
page.click("#page >> text=2")
browser.close()
print('testcase1 done')
def testcase2():
print('testcase2 start')
with sync_playwright() as p:
browser2 = p.chromium.launch(headless=False)
page2 = browser2.new_page()
page2.goto("https://www.sogou.com/")
print(page2.title())
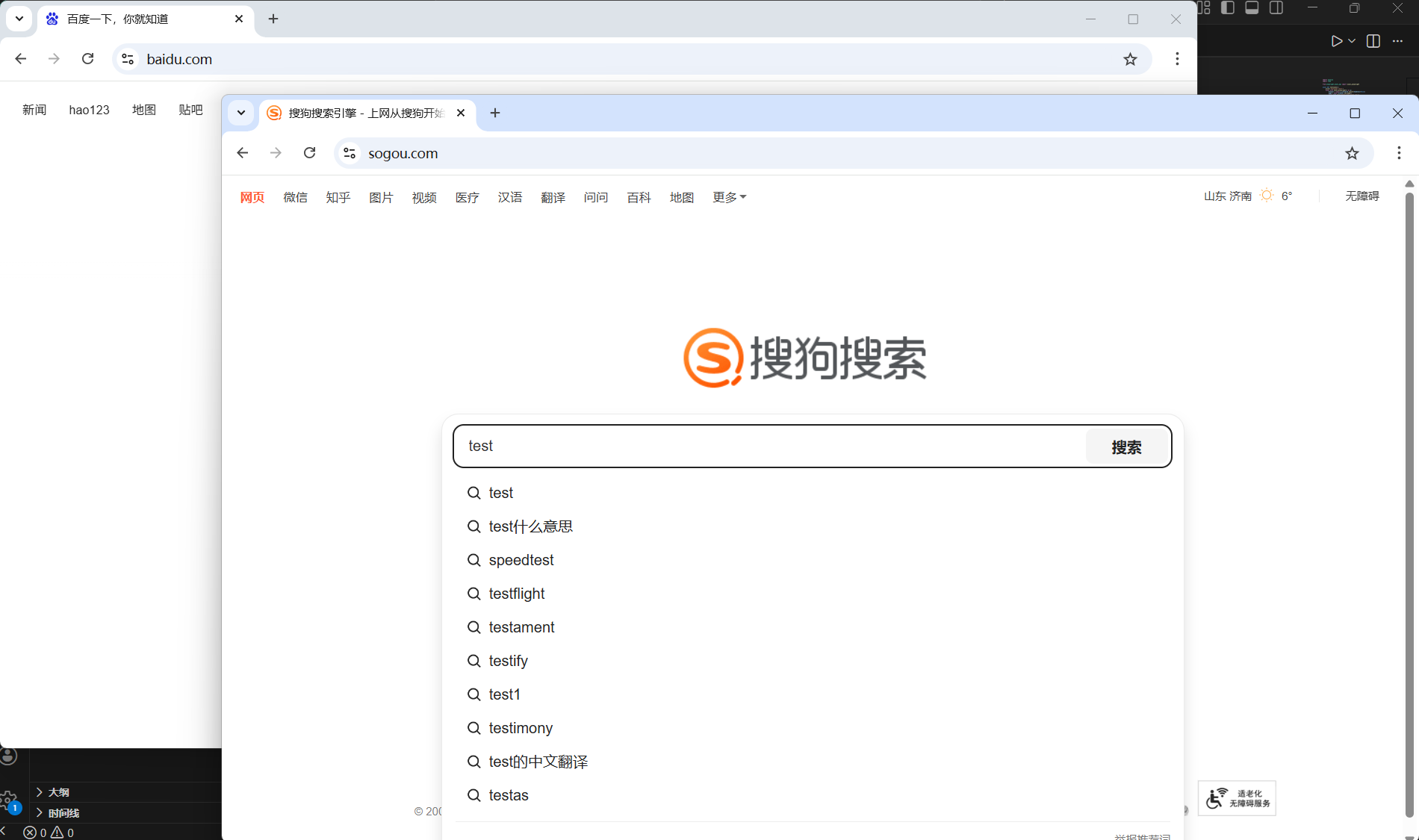
page2.fill("input[name=\"query\"]", "test")
page2.click("text=搜狗搜索")
page2.click("#sogou_page_2")
browser2.close()
print('testcase2 done')
start = time.time()
testcase1()
testcase2()
end = time.time()
print('Running time: %s Seconds'%(end-start))运行结果
bash
testcase1 start
百度一下,你就知道
testcase1 done
testcase2 start
搜狗搜索引擎 - 上网从搜狗开始
testcase2 done
Running time: 11.476110458374023 Seconds4.3.2. 异步方式
python
import asyncio
import time
from playwright.async_api import async_playwright
async def testcase1():
print('testcase1 start')
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
page = await browser.new_page()
await page.goto("https://www.baidu.com/")
print(await page.title())
await page.fill("input[name=\"wd\"]", "test")
await page.click("text=百度一下")
await page.click("#page >> text=2")
await browser.close()
print('testcase1 done')
async def testcase2():
print('testcase2 start')
async with async_playwright() as p:
browser2 = await p.chromium.launch(headless=False)
page2 = await browser2.new_page()
await page2.goto("https://www.sogou.com/")
print(await page2.title())
await page2.fill("input[name=\"query\"]", "test")
await page2.click("text=搜狗搜索")
await page2.click("#sogou_page_2")
await browser2.close()
print('testcase2 done')
async def main():
task1 = asyncio.create_task(testcase1())
task2 = asyncio.create_task(testcase2())
tasks = [task1,task2]
print('before await')
await asyncio.gather(*tasks)
start = time.time()
asyncio.run(main())
end = time.time()
print('Running time: %s Seconds'%(end-start))运行结果:
bash
before await
testcase1 start
testcase2 start
百度一下,你就知道
搜狗搜索引擎 - 上网从搜狗开始
testcase1 done
testcase2 done
Running time: 6.0248863697052 Seconds