很长时间没有更新博客了。
在大模型Agent领域,Plan ReAct架构凭借"规划-行动-观察"的循环机制,成为解决复杂多意图任务的主流方案。但在实际落地中,传统Plan ReAct Agent普遍面临拓展性瓶颈------新增技能需修改核心代码、技能间耦合度高、难以适配多样化项目场景。Anthropic推出的Claude Skills,以"模块化封装、渐进式披露、文件系统驱动"为核心设计,为Agent的可拓展性升级提供了关键思路。
本文将从Claude Skills的核心原理拆解入手,结合传统Plan ReAct的改造需求,系统讲解如何构建"技能可插拔、任务可适配、拓展无侵入"的智能Agent系统,涵盖架构设计、分步实现、进阶优化全流程,并深入剖析各环节的技术要点与实践逻辑。
一、Claude Skills核心原理与Plan ReAct改造必要性
要实现两者的深度融合,需先明确Claude Skills的核心设计逻辑,以及传统Plan ReAct架构的核心痛点,为后续改造提供方向锚点。
1.1 Claude Skills核心原理
什么是Skills?
Skills是一种模块化的能力,用于扩展 Claude 的功能。每个 Skill 都打包了元数据、指令和可选资源(如脚本或模板),当与用户的请求相关时,Claude 会自动使用它们。
简单来说,Skills 是可重用的、基于文件系统的资源,它为 Claude 提供了领域特定的专业知识、工作流程、上下文和最佳实践,从而将通用代理转变为特定领域的专家。
Claude Skills并非简单的"工具插件",而是一套基于文件系统的"领域能力模块化封装与动态调度方案"。其核心目标是将通用Agent转化为特定领域专家,同时解决大模型上下文窗口有限的核心问题,关键原理可概括为4个核心维度:
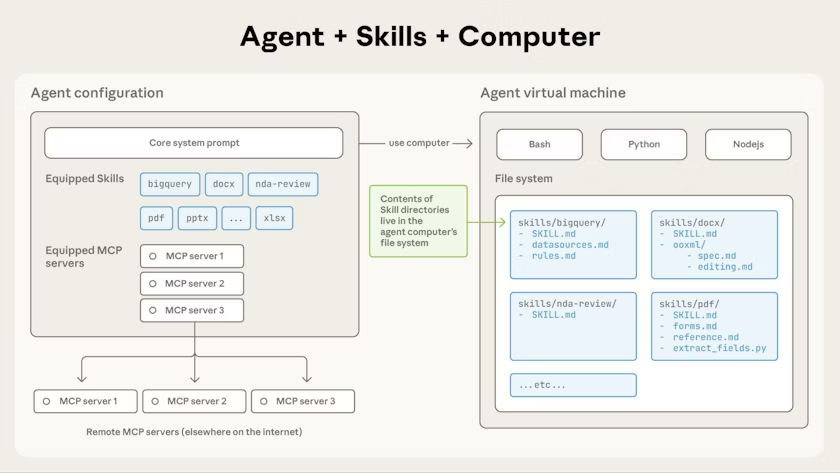
【Claude Skills 架构图-图片来源于官网】
- 模块化能力封装:每个Skill以独立目录形式存在,包含标准化的元数据、指令文档和资源脚本,将领域专业知识(如PDF处理流程、Excel分析规范)与核心Agent系统完全解耦。无需修改Agent核心逻辑,仅通过增减Skill即可适配不同场景。
- 渐进式披露机制:这是Claude Skills解决上下文冗余的核心创新。Skill内容被划分为三级加载层级,仅在需要时才纳入上下文:Level 1(元数据)启动时常驻,Level 2(核心指令)触发时加载,Level 3(资源脚本)按需调用,最大限度降低Token消耗。
- 文件系统驱动架构:Skills依托Claude的虚拟机环境运行,以目录形式存在于文件系统中。Agent通过Bash命令实现Skill的导航、读取与执行,使得大量参考文档、脚本等资源可离线存储,仅在需要时才接入上下文。
- 声明式技能发现:每个Skill通过标准化元数据描述功能与触发条件,Agent通过LLM的语义理解自动匹配任务与技能,替代传统的硬编码路由或关键词匹配,大幅提升技能发现的灵活性与准确性。
简单来说,Claude Skills的核心价值在于"让Agent具备按需装配能力"------核心系统保持稳定,通过挂载不同的Skill模块,即可快速切换为金融分析、文档处理、知识库查询等不同领域的专家Agent。
1.1.1 Claude Skills核心结构与工作流程
一个标准的Claude Skill目录必须包含顶层SKILL.md文件(含YAML元数据前言),可选脚本、参考文档等资源文件,其三级加载流程如下:
skills的结构示例:

- Level 1:元数据加载(启动时):SKILL.md前言中的元数据(名称、描述、触发条件)被加载到系统提示,每个Skill仅消耗约100 Token,确保大量Skill共存时无明显上下文压力。核心作用是让Agent知道"有哪些技能可用"以及"何时该用"。
- Level 2:指令加载(触发时):当用户任务与元数据描述匹配时,Agent通过Bash命令读取SKILL.md主体内容(含领域工作流程、操作规范),该部分通常低于5k Token,仅在触发后才进入上下文,提供具体任务执行指导。
- Level 3:资源加载(按需时):Skill目录中的脚本(如数据验证脚本)、参考文档(如API手册)等资源,仅在Level 2指令中被引用时才会被访问。脚本执行时仅返回输出结果,代码本身不进入上下文,实现无限容量资源扩展。
1.2 传统Plan ReAct Agent的核心痛点
传统Plan ReAct架构虽能解决复杂任务拆解问题,但原生设计未考虑规模化拓展需求,存在3个核心痛点,与Claude Skills的设计优势形成精准互补:
- 技能硬编码耦合:工具/技能直接嵌入核心规划逻辑,新增或修改技能需改动Agent的规划模块、执行引擎,违反"开闭原则",交付团队无法自主拓展。
- 上下文冗余严重:所有技能的指令、规则均常驻上下文,随着技能数量增加,上下文Token消耗呈线性增长,易触及模型窗口上限,影响任务拆解准确性。
- 技能发现效率低:依赖人工配置的关键词或意图分类器匹配技能,新增技能后需重新训练分类模型,无法适应快速变化的业务场景需求。
将Claude Skills的"模块化、渐进式加载、文件系统驱动"思想融入Plan ReAct架构,可精准解决上述痛点,实现Agent系统的规模化拓展与产品化落地。
1.3 为什么不直接用MCP
| 对比维度 | Claude Skills(技能模块) | MCP(工具调用) |
|---|---|---|
| 设计定位 | 领域能力模块化封装,支持Agent按需装配 | 特定功能工具的直接调用,聚焦单一操作执行 |
| 核心目标 | 提升Agent可拓展性,降低上下文冗余,支持团队协作拓展 | 弥补大模型原生能力不足,完成具体操作(如文件读写、API调用) |
| 与Agent耦合度 | 低耦合,通过标准化元数据与核心系统解耦,支持热插拔 | 高耦合,工具调用逻辑常嵌入核心规划模块,修改需改动核心代码 |
| 拓展方式 | 按规范封装技能包上传注册,无需修改核心逻辑 | 硬编码新增工具调用接口,需适配规划模块的参数格式 |
| 上下文效率 | 渐进式加载(三级),仅按需加载内容,Token消耗可控 | 工具描述常常驻上下文,数量增加时Token消耗线性增长 |
| 执行逻辑 | 脚本化流程,包含完整的前置校验、执行规范、结果处理 | 单次操作调用,需依赖LLM生成连续调用逻辑,确定性较弱 |
| 适用场景 | 复杂领域任务(如PDF全流程处理、Excel数据分析),需团队共享复用能力 | 简单单一操作(如获取当前时间、调用特定API接口),无需复杂流程约束 |
通过上述对比可见,Skills与MCP并非替代关系,而是互补关系:MCP提供基础操作能力,Skills则通过模块化封装将MCP工具整合为完整工作流,提升Agent的可拓展性与执行确定性。基于此,两者的深度融合成为改造Plan ReAct Agent的关键方向。
二、核心架构设计:融合Claude Skills的四层拓展架构
基于上述分析,我们设计"四层架构"的可拓展Plan ReAct Agent系统,从上至下依次为:任务交互层、核心控制层、技能管理层、执行引擎层。核心创新是将"技能管理层"独立为核心枢纽,融入Claude Skills的标准化设计与渐进式加载逻辑,实现技能与规划、执行逻辑的完全解耦。
2.1 架构整体概览与核心交互流程
各层职责清晰、松耦合,核心目标是实现"技能可插拔、规划与技能解耦、资源按需加载",具体职责与交互流程如下:
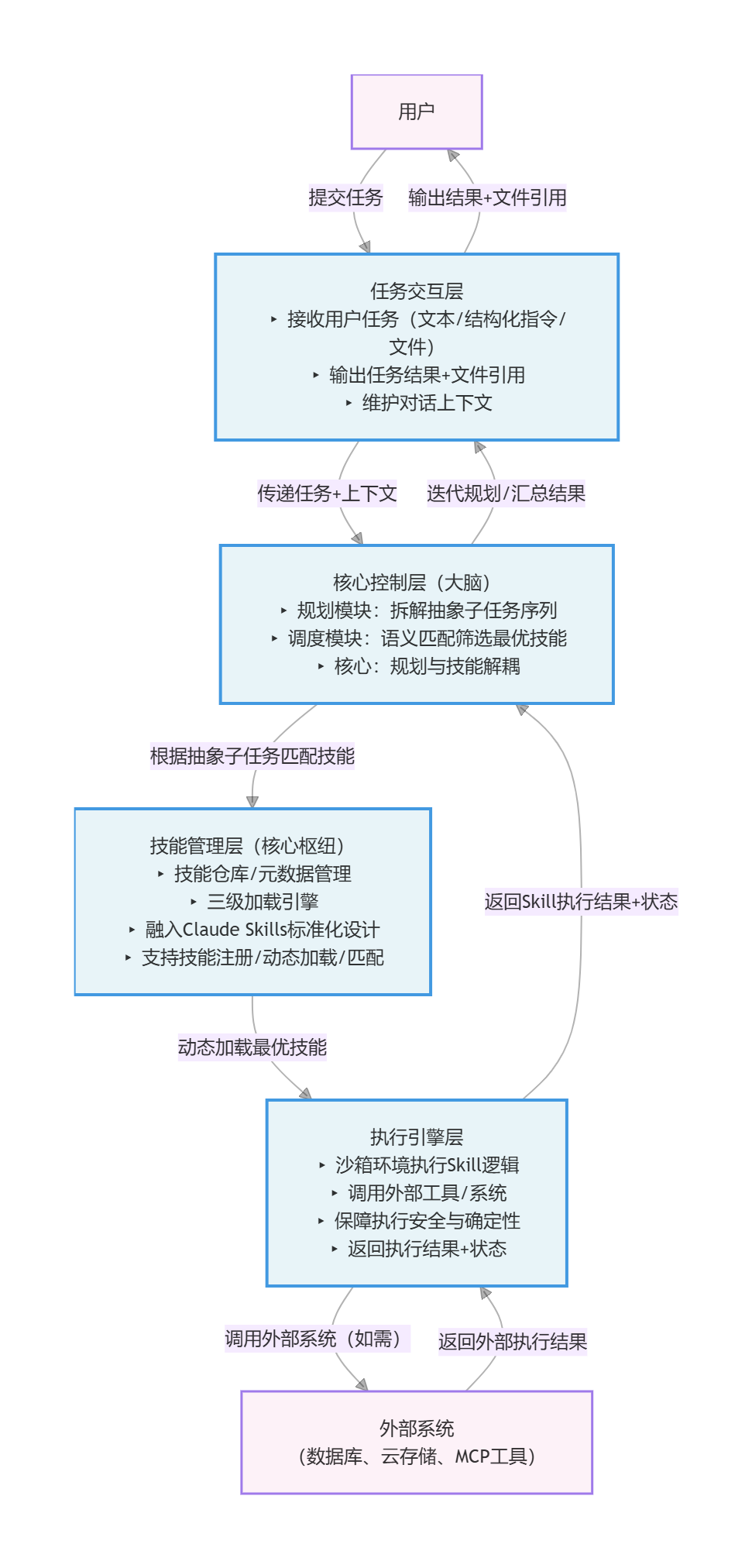
- 任务交互层:负责接收用户任务(文本描述、结构化指令、输入文件),输出任务结果与文件引用(如生成的Excel报告ID),同时维护对话上下文(用户历史、执行记录)。核心作用是实现用户与Agent的标准化交互。
- 核心控制层:Agent的"大脑",包含规划模块与调度模块。规划模块将复杂任务拆解为"与技能无关的抽象子任务序列";调度模块基于子任务需求,通过语义匹配从技能管理层筛选最优技能,实现规划与技能的解耦。
- 技能管理层:系统可拓展性的核心载体,融入Claude Skills的标准化设计,实现技能的注册、存储、动态加载与匹配。包含技能仓库、元数据管理、三级加载引擎三大核心组件。
- 执行引擎层:基于沙箱环境,负责执行Skill的具体逻辑(脚本运行、外部工具调用),与外部系统(数据库、云存储、MCP工具)交互,返回执行结果与状态,保障执行安全与确定性。
核心交互流程:用户任务 → 核心控制层(抽象规划拆解)→ 技能管理层(匹配Skill+动态加载)→ 执行引擎层(沙箱内执行)→ 核心控制层(观察结果+迭代规划)→ 任务交互层(输出结果)。
2.2 关键模块设计:技能管理层
技能管理层是融合Claude Skills思想的核心,其设计直接决定系统的拓展性与上下文效率,需严格遵循"标准化、渐进式、可共享"原则,核心组件设计如下:
2.2.1 标准化Skill抽象模型
参考Claude Skills的目录规范,定义标准化的Skill抽象模型,确保所有Skill遵循统一规范,实现"即插即用"。每个Skill包含3个核心部分,对应Claude Skills的三级加载层级:
python
class SkillModel:
def __init__(self, metadata: dict, instruction: str, resources: dict, executor: callable):
self.metadata = metadata # 格式:{"name": "processing-pdfs", "description": "处理PDF文件的文本提取、总结与格式转换", "input_schema": {...}, "priority": 1}
self.instruction = instruction # 来自SKILL.md主体,含工作流程、操作规范
self.resources = resources # 格式:{"scripts": {"extract_text.py": "path/to/script"}, "references": {"api_doc.md": "path/to/doc"}}
self.executor = executor # 接收标准化参数,调用资源脚本执行,返回结果说明:Skill的核心逻辑封装在executor中,新增Skill时只需按规范实现该模型,通过注册接口接入系统即可,无需修改核心控制层代码;元数据的description字段需明确技能功能与触发条件,为LLM语义匹配提供依据。
2.2.2 技能仓库与注册机制
设计支持文件系统存储的技能仓库,实现Skill的持久化管理,同时提供标准化的注册接口,支持"热注册"(无需重启Agent即可新增技能),适配交付团队的自主拓展需求:
python
class SkillRepository:
def __init__(self, base_path: str):
self.base_path = base_path # Skill存储根目录:如"/skills/"
self.skills = {}
self._load_existing_skills()
def _load_existing_skills(self):
"""加载根目录下所有符合规范的Skill,自动解析元数据与指令"""
for skill_dir in os.listdir(self.base_path):
skill_path = os.path.join(self.base_path, skill_dir)
if not os.path.isdir(skill_path):
continue
skill_md_path = os.path.join(skill_path, "SKILL.md")
if not os.path.exists(skill_md_path):
continue
metadata, instruction = self._parse_skill_md(skill_md_path)
resources = self._scan_skill_resources(skill_path)
executor = self._init_executor(os.path.join(skill_path, "scripts/main.py"))
skill = SkillModel(metadata, instruction, resources, executor)
self.skills[metadata["name"]] = skill
def register_skill(self, skill_zip: bytes):
"""注册新Skill:接收压缩包,解压至根目录,自动解析加载"""
skill_dir = self._unzip_skill(skill_zip)
self.skills[new_skill.metadata["name"]] = new_skill
return {"status": "success", "skill_name": new_skill.metadata["name"]}
def match_skill(self, task_description: str, llm: object) -> SkillModel:
"""基于LLM语义理解匹配Skill,替代硬编码路由"""
skill_list_prompt = "以下是可用技能列表,请根据用户任务选择最匹配的技能:\n"
for skill_name, skill in self.skills.items():
skill_list_prompt += f"- 技能名称:{skill_name},适用场景:{skill.metadata['description']}\n"
prompt = f"{skill_list_prompt}\n用户任务:{task_description}\n仅返回匹配的技能名称,无需其他内容"
matched_skill_name = llm.generate(prompt).strip()
return self.skills.get(matched_skill_name)该设计的核心优势:一是遵循Claude Skills的文件系统规范,降低Skill开发与集成成本;二是技能匹配依赖LLM语义理解,无需开发专门的意图分类器,交付团队新增Skill后系统可自动识别。
2.2.3 三级动态加载引擎
参考Claude Skills的渐进式披露机制,设计三级动态加载引擎,确保仅将当前任务所需的内容加载至上下文,平衡系统轻量化与任务执行质量:
python
class ProgressiveLoadEngine:
@staticmethod
def load_level1(skill_repo: SkillRepository, system_prompt: str) -> str:
"""加载Level 1:所有Skill的元数据,注入系统提示(启动时执行)"""
level1_prompt = "\n可用技能元数据:\n"
for skill in skill_repo.skills.values():
level1_prompt += f"- 名称:{skill.metadata['name']},描述:{skill.metadata['description']}\n"
return system_prompt + level1_prompt
@staticmethod
def load_level2(skill: SkillModel, context: dict) -> dict:
"""加载Level 2:匹配Skill的核心指令,注入上下文(触发时执行)"""
context["system_prompt"] += f"\n当前使用技能:{skill.metadata['name']}\n技能执行规范:{skill.instruction}"
return context
@staticmethod
def load_level3(skill: SkillModel, resource_name: str, context: dict) -> dict:
"""加载Level 3:按需加载资源/脚本,仅返回结果(需要时执行)"""
resource_path = skill.resources.get(resource_name)
if not resource_path:
raise ValueError(f"资源{resource_name}不存在")
if resource_name.endswith((".md", ".txt")):
with open(resource_path, "r", encoding="utf-8") as f:
resource_content = f.read()
context["temp_resource"] = resource_content
elif resource_name.endswith(".py"):
result = subprocess.run(["python", resource_path], capture_output=True, text=True)
context["temp_resource_result"] = result.stdout if result.returncode == 0 else result.stderr
return context2.3 核心控制层:规划与调度的协同设计
核心控制层需实现"抽象规划-技能匹配-动态加载-执行监控"的闭环,关键是让规划模块生成"与技能无关的抽象子任务",再由调度模块完成技能匹配与加载,实现规划与技能的完全解耦。
2.3.1 规划模块:生成抽象子任务序列
传统Plan ReAct的规划模块直接生成包含具体工具调用的步骤,耦合度高。优化后的规划模块仅生成"抽象子任务",描述"需要做什么",不指定"用什么技能做":
python
class Planner:
def __init__(self, llm: object):
self.llm = llm
def generate_abstract_plan(self, task_description: str, context: dict) -> list:
"""生成抽象子任务序列,格式标准化,不包含具体技能信息"""
prompt = f"""请将用户任务拆解为可执行的抽象子任务序列,每个子任务仅描述目标,不指定工具/技能。
用户任务:{task_description}
输出格式要求:JSON数组,包含step(步骤)、sub_task(子任务描述)、input_requirement(所需输入)
示例输出:
[
{"step": 1, "sub_task": "读取指定PDF文件的文本内容", "input_requirement": "需要PDF文件的绝对路径"},
{"step": 2, "sub_task": "对提取的文本进行总结", "input_requirement": "需要PDF提取的文本内容"}
]"""
plan = self.llm.generate(prompt)
return json.loads(plan)2.3.2 调度模块:技能匹配与执行协调
调度模块是连接规划与执行的核心枢纽,负责将抽象子任务匹配到具体Skill,触发动态加载,生成标准化输入参数,同时处理执行异常:
python
class Scheduler:
def __init__(self, skill_repo: SkillRepository, load_engine: ProgressiveLoadEngine, executor_engine: object):
self.skill_repo = skill_repo
self.load_engine = load_engine
self.executor_engine = executor_engine # 封装沙箱执行逻辑
def schedule_execution(self, plan: list, context: dict, llm: object) -> list:
"""按规划调度技能执行,返回各步骤执行结果"""
execution_results = []
for step in plan:
sub_task = step["sub_task"]
matched_skill = self.skill_repo.match_skill(sub_task, llm)
if not matched_skill:
execution_results.append({"step": step["step"], "status": "failed", "reason": "无匹配技能"})
continue
context = self.load_engine.load_level2(matched_skill, context)
input_params = self._generate_standard_params(step, matched_skill, context, llm)
result = self.executor_engine.execute(
skill_executor=matched_skill.executor,
input_params=input_params,
skill_resources=matched_skill.resources
)
execution_results.append({"step": step["step"], "status": "success", "result": result})
context["execution_history"].append(execution_results[-1])
return execution_results
def _generate_standard_params(self, step: dict, skill: SkillModel, context: dict, llm: object) -> dict:
"""基于子任务需求与Skill输入规范,生成标准化参数"""
prompt = f"""请根据子任务需求和技能输入规范,生成符合要求的输入参数。
子任务:{step['sub_task']}
技能输入规范:{skill.metadata['input_schema']}
对话上下文:{context['user_history'] + context['execution_history']}
输出格式:严格遵循input_schema的JSON格式,仅返回JSON,无需其他内容"""
return json.loads(llm.generate(prompt))三、分步实现:从Skill封装到Agent系统落地
基于上述架构,我们通过"Skill封装→系统搭建→任务验证"三步完成Agent落地,全程体现"可拓展性"核心优势,适配交付团队的自主拓展需求。
3.1 第一步:按规范封装Skill(以PDF处理为例)
遵循Claude Skills的目录规范,封装PDF处理Skill,包含元数据、核心指令、资源脚本三部分,实现"即插即用"。
3.1.1 Skill目录结构
text
processing-pdfs/ # Skill名称(小写字母+连字符)
├── SKILL.md # 必选:元数据+核心指令
├── scripts/ # 可选:可执行脚本
│ ├── main.py # 主执行脚本(文本提取、总结)
│ └── validate_path.py # 辅助脚本(路径验证)
└── references/ # 可选:参考文档
└── pdf_tool_api.md # PDF处理工具API手册3.1.2 核心文件实现
1. SKILL.md(元数据+核心指令):
markdown
# SKILL.md
---
name: processing-pdfs
description: 处理PDF文件的文本提取、内容总结与格式转换,支持单页/多页PDF,需传入文件绝对路径
input_schema:
file_path: str,PDF文件的绝对路径(必填)
operation: str,可选值:extract_text/summarize/convert(必填)
page_range: list,可选,页码范围,如[1,3]表示1-3页,默认全页
output_schema:
status: str,success/failed
result: str,操作结果(文本内容/总结文本/转换后文件ID)
reason: str,失败时的错误原因
---
## 执行规范
1. 操作前必须调用scripts/validate_path.py验证file_path的有效性,无效则直接返回错误
2. 执行extract_text操作时,需按page_range提取对应页码的文本,保留原始段落结构
3. 执行summarize操作时,需先提取文本,再按"核心观点+关键信息"的结构生成总结(不超过500字)
4. 执行convert操作时,转换为txt格式,输出至/output目录,返回文件ID(通过Files API获取)
5. 所有操作结果需严格遵循output_schema格式返回2. 主执行脚本(scripts/main.py):
python
import pdfplumber
import os
from validate_path import validate_file_path
def extract_text(file_path, page_range=None):
"""提取PDF文本"""
text = ""
with pdfplumber.open(file_path) as pdf:
pages = pdf.pages if not page_range else pdf.pages[page_range[0]-1:page_range[1]]
for page in pages:
text += page.extract_text() + "\n"
return text.strip()
def summarize_text(text):
"""总结文本(实际落地可调用LLM,此处简化为示例)"""
return f"核心总结:{text[:200]}..."
def convert_to_txt(text, output_dir="/output"):
"""转换为txt文件,返回文件ID"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
file_name = f"pdf_convert_{os.path.basename(file_path).replace('.pdf', '.txt')}"
file_path = os.path.join(output_dir, file_name)
with open(file_path, "w", encoding="utf-8") as f:
f.write(text)
return {"file_id": f"pdf_{os.urandom(8).hex()}", "file_path": file_path}
def execute(input_params):
"""主执行函数,接收标准化参数,返回结果"""
file_path = input_params["file_path"]
operation = input_params["operation"]
page_range = input_params.get("page_range")
if not validate_file_path(file_path):
return {"status": "failed", "reason": f"文件路径无效:{file_path}"}
try:
if operation == "extract_text":
text = extract_text(file_path, page_range)
return {"status": "success", "result": text}
elif operation == "summarize":
text = extract_text(file_path, page_range)
summary = summarize_text(text)
return {"status": "success", "result": summary}
elif operation == "convert":
text = extract_text(file_path, page_range)
convert_result = convert_to_txt(text)
return {"status": "success", "result": convert_result["file_id"]}
else:
return {"status": "failed", "reason": f"不支持的操作:{operation}"}
except Exception as e:
return {"status": "failed", "reason": str(e)}3.2 第二步:搭建Agent系统,集成Skill
整合各模块,搭建完整Agent系统,实现Skill的自动加载、注册与调度,核心代码如下:
python
from langchain_openai import OpenAI
import json
import os
llm = OpenAI(api_key="your-api-key", model="gpt-4")
skill_repo = SkillRepository(base_path="/skills/")
load_engine = ProgressiveLoadEngine()
executor_engine = SandboxExecutorEngine() # 封装Docker沙箱、文件存储服务
planner = Planner(llm=llm)
scheduler = Scheduler(
skill_repo=skill_repo,
load_engine=load_engine,
executor_engine=executor_engine
)
initial_system_prompt = "你是一个具备多技能的智能Agent,能根据用户任务匹配最优技能并完成执行"
context = {
"system_prompt": load_engine.load_level1(skill_repo, initial_system_prompt),
"user_history": [],
"execution_history": []
}
def agent_run(task_description: str, context: dict) -> dict:
context["user_history"].append(task_description)
plan = planner.generate_abstract_plan(task_description, context)
print(f"生成抽象规划:{json.dumps(plan, indent=2, ensure_ascii=False)}")
execution_results = scheduler.schedule_execution(plan, context, llm)
final_result = {
"task": task_description,
"plan": plan,
"execution_results": execution_results,
"final_status": "success" if all(res["status"] == "success" for res in execution_results) else "failed"
}
return final_result
# 4. 注册新Skill(交付团队自主拓展时使用)
def register_new_skill(skill_zip_path: str):
"""上传Skill压缩包,完成注册"""
with open(skill_zip_path, "rb") as f:
skill_zip = f.read()
return skill_repo.register_skill(skill_zip)3.3 第三步:任务验证,测试系统功能与拓展性
通过两个核心测试场景,验证系统的功能完整性与拓展性:
3.3.1 测试1:复杂PDF任务执行
任务:"读取/skills/test_data/report.pdf文件的1-3页文本,生成总结,并转换为txt格式":
python
task = "读取/skills/test_data/report.pdf文件的1-3页文本,生成总结,并转换为txt格式"
result = agent_run(task, context)
print(f"任务执行结果:{json.dumps(result, indent=2, ensure_ascii=False)}")预期结果:系统生成3步抽象规划,自动匹配processing-pdfs Skill,依次执行"路径验证→文本提取→总结→格式转换",返回包含总结文本与txt文件ID的结果,所有步骤无核心代码修改。
3.3.2 测试2:Skill拓展验证
新增"Excel分析Skill"(按3.1规范封装),通过register_new_skill("excel_analysis.zip")注册后,直接执行任务:"读取/skills/test_data/students.xlsx,统计数学成绩平均值"。
预期结果:系统自动识别新增的excel-analysis Skill,生成对应的抽象规划并执行,无需修改Agent核心逻辑,完美体现"无侵入式拓展"优势。
四、进阶优化
为让系统更贴合生产环境需求,需针对"技能匹配准确性、执行安全性、资源效率、团队协作"四个核心维度进行优化,形成可规模化落地的解决方案。
4.1 技能匹配优化:引入优先级与多候选机制
当多个Skill可匹配同一任务时,通过元数据的priority字段设置优先级(1-5级,数值越高优先级越高),调度模块优先选择高优先级Skill;同时让LLM生成3个候选Skill,当高优先级Skill执行失败时,自动切换至次优Skill,提升任务成功率。
4.2 执行安全优化:强化沙箱隔离与权限管控
参考Claude Skills的安全执行理念,优化执行引擎层:
- 容器化沙箱增强:采用Docker容器为每个任务分配独立沙箱环境,预配置所需依赖,任务结束后立即销毁,避免环境污染与恶意代码影响。
- 命令拦截与审计:拦截LLM生成的Bash命令,禁止网络调用、敏感路径写入等危险操作;记录所有执行日志,支持问题追溯与安全审计。
- 最小权限原则:沙箱容器以最小权限运行,仅允许访问指定的Skill目录与输出目录,限制对底层系统的访问权限。
4.3 资源效率优化:深化缓存与懒加载机制
针对高频使用的Skill(如PDF处理、Excel分析),在技能仓库中增加内存缓存,避免重复加载与解析;对依赖重资源的Skill(如大模型微调技能),实现"资源懒初始化"------仅在首次执行时加载资源,执行完成后释放,降低内存占用。
4.4 团队协作优化:构建Skill管理平台
为支撑交付团队自主拓展,搭建可视化Skill管理平台,提供四大核心功能:
- Skill上传与校验:支持压缩包上传,自动校验目录结构与元数据规范性,不合格则返回具体错误。
- 版本控制:为每个Skill维护版本历史,支持版本回滚,可指定Agent使用特定版本或"latest"版本,避免更新影响现有任务。
- 权限管理:按工作空间划分Skill共享范围,不同团队仅能访问自身工作空间内的Skill,保障敏感技能安全。
- 文档中心:提供Skill开发规范、示例模板、API文档,降低交付团队的Skill开发成本。
4.5 文件交互优化:集成标准化文件服务
参考Claude Files API,集成独立的文件存储服务:
- 输入文件处理:用户上传的输入文件先经过病毒扫描、格式验证,通过后临时挂载至沙箱的/input目录,任务结束后自动清除。
- 输出文件处理:Skill生成的文件自动上传至文件存储服务,返回唯一File ID,用户通过File ID下载文件,避免暴露沙箱内部路径。
五、落地实施的挑战
前文提出的基于Claude Skills思想的Plan ReAct Agent拓展方案,虽能解决传统架构的拓展性与上下文冗余问题,但要从理论设计落地为可产品化的系统,需突破一系列底层技术瓶颈。这些挑战源于Claude Skills架构对执行环境、文件系统、知识管理的特殊要求,同时需适配Plan ReAct的规划-执行闭环,具体可归纳为六大核心技术挑战。
5.1 挑战一:环境隔离与安全执行------沙箱环境构建
Claude Skills的核心基础是隔离且受限的虚拟机环境,所有技能脚本的执行、文件交互均依赖该环境保障安全性与确定性。将这一架构迁移至自研Plan Agent系统,首要突破的是沙箱环境的构建与适配。
5.1.1 核心目标
建立支持文件系统访问、Bash命令执行、代码运行的隔离环境,确保技能脚本(Level 3资源)安全执行,避免恶意代码或错误操作影响底层系统,同时保障执行结果的确定性。
5.1.2 关键技术壁垒
- 环境隔离性不足:自研环境中缺乏类似Claude虚拟机的原生隔离机制,技能脚本直接执行可能导致系统资源竞争、数据泄露或底层环境污染。
- 文件系统映射复杂:需让LLM能通过Bash命令灵活导航、读取技能目录(Level 1元数据、Level 2指令文件),同时确保不同技能的文件路径不冲突,这对文件系统的统一视图构建提出要求。
- 脚本执行安全可控:技能脚本可能包含网络调用、敏感文件操作等风险行为,缺乏对LLM生成的Bash命令的拦截与审计机制,易引发安全隐患。
- 依赖管理繁琐:不同技能脚本可能依赖不同版本的运行环境(如Python包、系统工具), runtime动态安装依赖会导致执行效率低、环境不稳定。
5.1.3 落地实施建议
- 容器化沙箱构建:采用Docker或Kata Containers等容器化技术,为每个Agent请求或会话分配全新的隔离容器。容器预配置技能脚本所需的基础环境与依赖包,请求结束后立即销毁,确保环境隔离与清洁。
- 统一文件系统视图 :容器启动时,将所有启用的技能目录统一挂载至容器内固定路径(如
/skills/{skill-name}/),让LLM可通过标准Bash命令(如cat /skills/pdf-processing/SKILL.md)访问技能文件,模拟Claude的文件系统交互逻辑。 - 命令拦截与安全审计:实现Bash命令拦截器,对LLM生成的命令进行安全校验,限制网络调用、敏感路径写入等危险操作;同时记录所有命令执行日志,支持后续审计与问题追溯。
- 预配置依赖环境:构建基础镜像时,预先安装所有常用技能依赖包,并要求技能开发者在SKILL.md中明确标注依赖版本;禁止脚本运行时动态安装依赖,确保环境稳定性。
5.2 挑战二:文件I/O与结果处理------跨环境文件流转机制
Claude Skills通过Files API实现隔离环境与外部系统的文件交互(如输入文件上传、输出文件下载),而自研系统需解决"沙箱内文件持久化""外部文件安全接入""文件引用传递"三大核心问题,确保技能执行的文件流转顺畅。
5.2.1 核心目标
实现隔离环境与外部系统的安全文件交互,支持用户输入文件(如待分析的PDF)传入沙箱、技能生成文件(如分析报告)持久化存储与外部获取,同时避免暴露容器内部路径。
5.2.2 关键技术壁垒
- 沙箱内文件持久化困难:容器为临时环境,技能脚本生成的文件(如Excel报告、PDF输出)在容器销毁后会丢失,无法传递给外部用户。
- 文件引用与访问不规范:LLM直接返回容器内文件路径给外部系统,会暴露沙箱内部结构,且路径在容器销毁后失效,无法实现文件下载。
- 输入文件接入安全风险:用户上传的输入文件(如带恶意代码的PDF)直接挂载至沙箱,可能引发病毒感染或恶意攻击。
5.2.3 落地实施建议
- 集成持久化文件存储服务 :搭建类似Claude Files API的文件存储服务(基于S3或内部文件服务)。容器内预设固定输出目录(如
/output/),当技能脚本在该目录生成文件时,触发自动上传机制,将文件同步至持久化存储。 - 采用File ID引用机制:文件上传至持久化存储后,系统生成唯一的File ID返回给LLM,Agent在响应用户时仅携带File ID,外部系统通过调用Files API(传入File ID)获取实际文件内容,避免暴露容器路径。
- 输入文件安全挂载流程 :用户上传的输入文件先经过安全校验(如病毒扫描、格式验证),通过后临时挂载至容器内固定输入目录(如
/input/),技能脚本仅能读取该目录下的文件;请求执行完成后,自动清除临时挂载的输入文件。
5.3 挑战三:SKILL库构建与管理------标准化与可拓展性保障
Claude Skills通过标准化的目录结构、元数据规范实现技能的可发现、可共享,自研系统需构建符合该规范的SKILL库,并实现组织级的技能管理、版本控制与共享机制,确保外部团队(如交付部门)能高效拓展技能。
5.3.1 核心目标
建立标准化的SKILL目录规范,实现技能的快速创建、上传、共享与版本迭代,支持组织内多团队协作拓展,适配不同项目场景的定制化需求。
5.3.2 关键技术壁垒
- 技能结构不规范:不同开发者创建的技能目录结构混乱、元数据(名称、描述)缺失或不清晰,导致LLM无法准确发现与触发技能(Level 1加载机制失效)。
- 技能共享与权限管控缺失:缺乏统一的技能管理接口,外部团队无法便捷上传、共享定制技能;同时未划分技能访问权限,可能导致敏感技能(如内部知识库查询)泄露。
- 版本迭代风险高:技能更新时无版本控制机制,直接覆盖旧版本可能导致依赖该技能的现有任务执行失败,影响生产环境稳定性。
5.3.3 落地实施建议
- 制定严格的技能结构规范 :强制要求每个技能目录顶层必须包含SKILL.md文件,且文件开头需包含YAML元数据(必填name:小写字母+数字+连字符,最大64字符;description:非空,最大1024字符,明确技能功能与触发条件);技能内部文件(如脚本、参考文档)需放置在指定子目录(如
scripts/、reference/),确保结构统一。 - 实现技能管理API接口:提供标准化的技能上传、查询、删除接口,支持用户上传技能压缩包(总大小限制在8MB以内);技能上传后自动校验结构规范性,校验通过后纳入SKILL库。同时支持工作空间级别的技能共享,同一工作空间内的团队成员可共同访问技能。
- 引入技能版本控制机制:为每个技能分配版本ID,支持创建新版本、回滚旧版本;Agent调用技能时,可通过配置指定使用特定版本或"latest"版本;新版本发布前需经过测试验证,避免影响现有任务。
5.4 挑战四:三级加载逻辑实现------上下文效率优化核心
Claude Skills的核心优势是"渐进式披露"的三级加载机制(元数据始终加载、指令触发加载、资源按需加载),该机制直接解决上下文冗余问题。自研系统需精准实现这一逻辑,确保仅将当前任务所需的知识加载至LLM上下文,平衡上下文效率与任务执行质量。
5.4.1 核心目标
实现技能的三级动态加载,确保Level 1元数据轻量常驻、Level 2指令触发后加载、Level 3资源按需访问,最大限度降低上下文Token消耗,同时保障技能执行所需的知识完整。
5.4.2 关键技术壁垒
- 元数据注入效率低:当SKILL库中技能数量较多时,批量读取元数据并注入系统提示会消耗大量启动时间,且可能导致系统提示过长。
- 指令加载时机难把控:无法精准判断用户任务与技能元数据的匹配关系,可能出现技能误触发(加载不必要的指令)或漏触发(未加载所需技能)的情况。
- 资源按需加载逻辑复杂:LLM需通过工具调用访问Level 3资源(如脚本、参考文档),需实现工具与沙箱文件系统的联动,同时确保仅返回资源内容或脚本输出,不加载冗余代码。
5.4.3 落地实施建议
- 轻量级元数据注入机制:实现技能注册表,Agent启动或新对话开始时,仅读取所有启用技能的name与description(每个约100 Token),动态注入系统提示;通过分页或筛选机制,优先加载高频使用技能的元数据,降低启动压力。
- 精准的技能触发匹配逻辑:优化LLM的技能匹配提示,要求LLM基于用户任务与技能description的语义相似度判断是否触发技能;同时引入用户配置的触发词白名单,辅助提升匹配准确性;触发后,通过自定义的Read_File工具读取SKILL.md文件(限制在500行以内,低于5k Token),将指令加载至上下文。
- 资源访问与脚本执行工具封装:实现Read_File(读取Level 3参考文件)与Execute_Code(执行Level 3脚本)两个核心工具,绑定沙箱文件系统:
- ① 读取资源时,仅将文件内容作为工具输出返回给LLM,未访问的资源不消耗Token;
- ② 执行脚本时,仅将脚本输出(如"验证通过""文件格式错误")返回给LLM,脚本代码本身不加载至上下文,提升效率与可靠性。同时强制"一层引用"规则,要求所有Level 3资源直接关联SKILL.md,避免嵌套引用导致的加载混乱。