导语
Redis 是一个高性能的内存键值数据库,常用于缓存、分布式锁、会话存储以及排行榜等高并发场景,凭借极快的读写速度和丰富的数据结构(如字符串、哈希、列表、集合、有序集合等)在互联网业务中被广泛采用。随着业务规模的扩大,单节点 Redis 很难同时兼顾性能与可靠性,这就催生了对数据冗余与高可用的需求。为了解决单点故障、提升读吞吐能力并支持数据迁移,Redis 提供了主从复制(Replication)机制:通过将主节点的数据异步复制到一个或多个从节点,实现读写分离和多副本容灾。本文将系统地剖析 Redis 主从复制的工作原理,并梳理其在各个版本中的演进过程。
作者:腾讯云NoSQL团队-李鸿瑞
1 主从复制简介
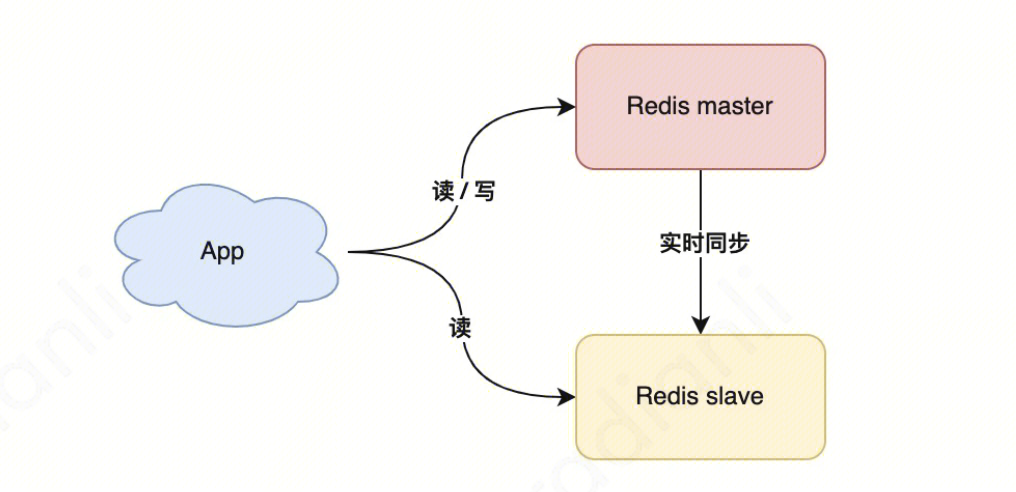
图 1 、 Redis主从复制示意图
Redis 主从复制(Replication)是一种核心的数据冗余和高可用机制。简单来说,就是可以给一个主节点连上几个副本,每个副本与主节点拥有的数据完全一致。主从复制主要用于解决以下问题:
数据冗余与容灾
通过将主节点(Master)的数据异步复制到多个从节点(Replica or Slave),避免单点故障导致的数据丢失。即使主节点宕机,从节点仍可提供数据备份,保障业务连续性。
读写分离,提高读并发能力
主节点负责处理写操作(如 SET、DEL),从节点负责处理读操作(如 GET)。通过将读请求分摊到多个从节点,显著提升系统的读性能和吞吐量。
数据迁移
Redis主从复制机制实现了节点间的数据同步,且在数据同步期间主节点可以正常处理请求,是一个很好的实例间数据热迁移的方式。
2 全量同步
主从复制对于高可用的意义是显著的,但是,当陌生的从节点申请挂从时,主节点首先要考虑的是如何把自己的数据完整地、并且尽可能快速地发送给从节点。并且在全量同步期间,主节点还必须同时处理新的读写请求,在这期间发生的数据变动也必须传递到从节点。如此看来,实现高可用的道路上注定困难重重,接下来,让我们来探究一下 Redis 是如何巧妙地化解难题,实现主从节点间全量同步的。
2 .1 全量同步的实现
为了将自己当前的数据完整地发给从节点,主节点首先会生成一个 RDB 文件,它是主节点当下的数据快照,存储了主节点在该时刻的所有数据。为了避免 RDB 的生成影响主进程的性能,主节点会执行 BGSAVE,fork 出一个子进程来负责 RDB 快照的生成。待 RDB 快照生成后,主节点将其发送给从节点,从节点接收后清空本地数据并加载 RDB。
此外,正如前文提到的,主节点上述过程期间的数据变更也必须传递到从节点。为了实现这点,主节点会将 RDB 生成、接收、加载期间的写命令都暂存到自己给副本客户端准备的输出缓冲区中,待从节点加载完 RDB 后发送给从节点。如此一来,从节点便拥有了与主节点一模一样的数据,并且同步期间主节点能照常处理请求。
全量同步的流程如下图所示:
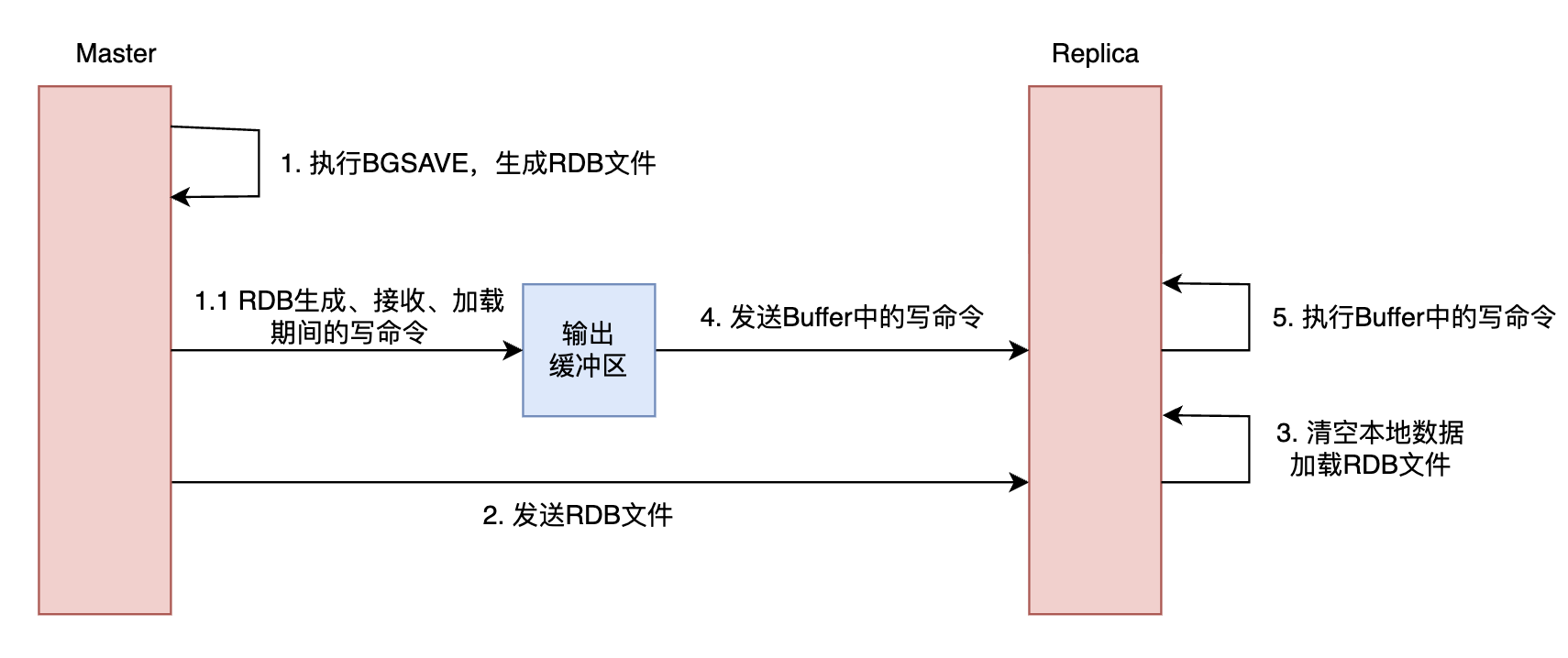
图 2 、全量同步流程 示意 图
从全量同步的过程中,我们不难发现 RDB 文件以及输出缓冲区的处理是整个过程中的重点,我们紧接着来讨论一下 Redis 处理 RDB 文件以及输出缓冲区的一些细节。
2.2 RDB的生成与传输
- RDB的无盘传输
在 Redis 主从复制的全量同步过程中,传统方式是先将 RDB 文件写入磁盘,然后再从磁盘读取并通过网络发送给从节点,经过了两次磁盘I/O。这种方式虽然简单,但会带来额外的磁盘 I/O 开销,并且在磁盘性能较差或数据集较大时,可能成为复制的瓶颈。
为了解决这一问题,Redis 从 2.8.18 版本开始引入了无盘传输。在无盘传输模式下,主节点在执行 BGSAVE 生成 RDB 数据时,不再将数据写入磁盘文件,而是直接通过 socket 将 RDB 数据流发送给从节点,从而省去了磁盘写入和读取的开销。
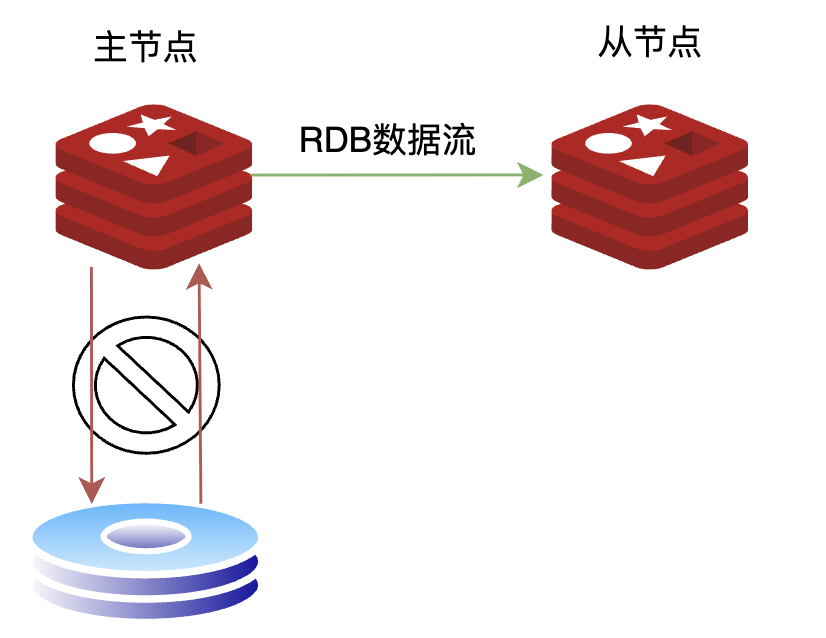
图 3 、无盘复制示意图
- RDB复用
如果同时有多个从节点与主节点进行全量同步,主节点需要为每个从节点都生成一份RDB吗?答案是只需要一份就好了。Redis实现了RDB的复用机制。如果当前有BGSAVE正在进行并且有其他从节点正在等待当前BGSAVE结束,则可以复用这次BGSAVE生成的RDB,从而减少BGSAVE的次数。其大致流程如下:
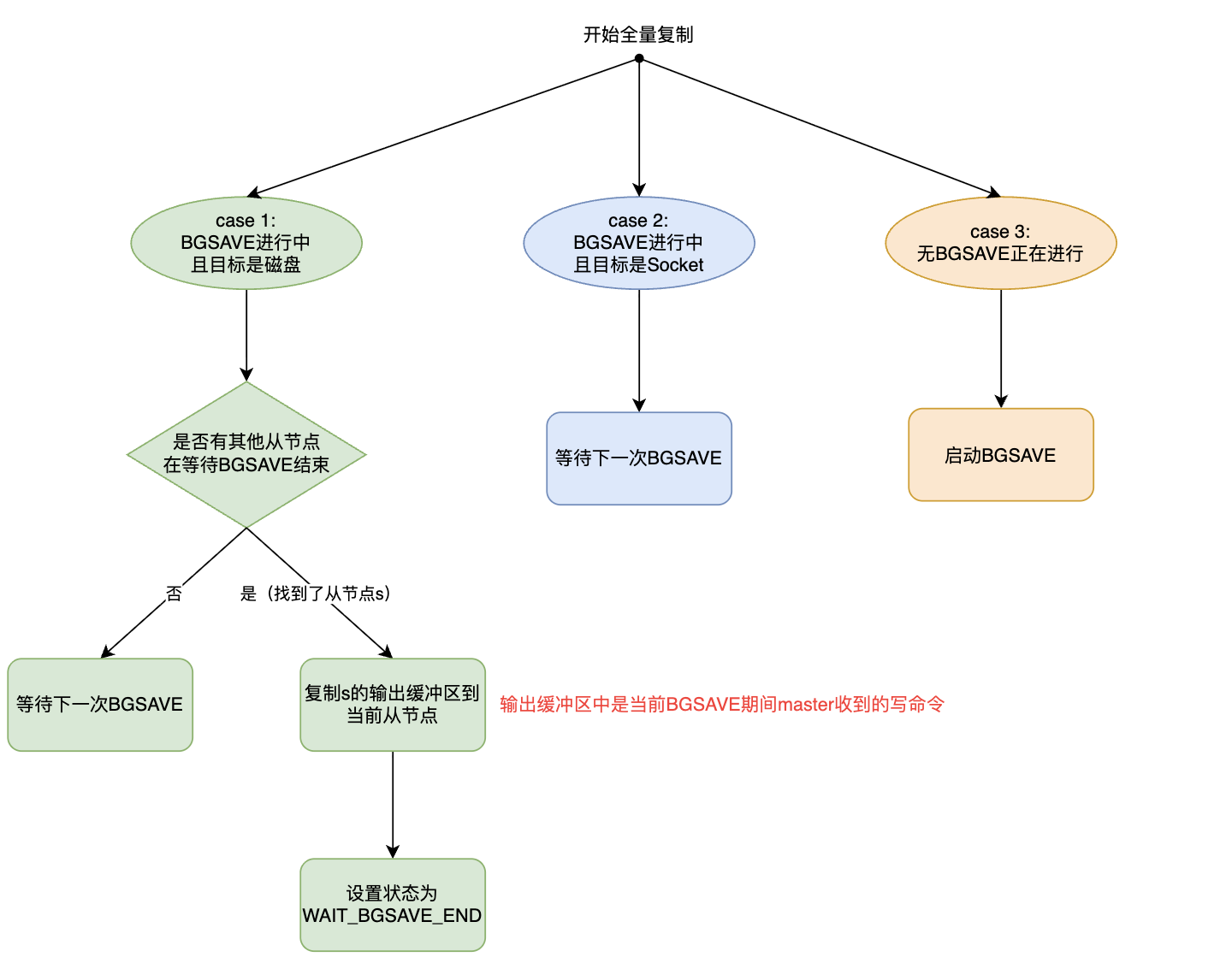
图 4 、RDB复用流程
值得注意一点的是,如果使用了给另一个从节点s准备的RDB,那么为了对齐数据,还需要将s的输出缓冲区中的写命令也copy过来。
2.3 写命令暂存与数据对齐
在全量同步过程中,从节点的数据实际上有两个来源:主节点发来的RDB快照以及输出缓冲区中的写命令。Redis需要保证:
- 数据对齐 :输出缓冲区中的第一条命令正好是RDB快照后的第一条命令。
- 加载顺序正确 :先加载RDB快照,然后再加载输出缓冲区中的写命令。
Redis是如何保证上述两个条件的呢?让我们深入源码进行分析。
Redis的主从复制实现有一套完善的状态机设计,与本小节相关的是如下4个状态:
#define SLAVE_STATE_WAIT_BGSAVE_START 6 /* 需要生成新的RDB快照 */
#define SLAVE_STATE_WAIT_BGSAVE_END 7 /* 等待RDB快照创建完成 */
#define SLAVE_STATE_SEND_BULK 8 /* 正在发送RDB快照到从节点 */
#define SLAVE_STATE_ONLINE 9 /* RDB传输完成 */ 当主节点接收到写命令时,会调用 replicationFeedSlaves 函数,向每个从节点对应的客户端输出缓冲区也写入一份同样的数据:
void replicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) {
// ...
listRewind(slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
if (!canFeedReplicaReplBuffer(slave)) continue; // 关键检查点
/* Feed slaves that are waiting for the initial SYNC (so these commands
* are queued in the output buffer until the initial SYNC completes),
* or are already in sync with the master. */
/* Add the multi bulk length. */
addReplyArrayLen(slave,argc);
/* Finally any additional argument that was not stored inside the
* static buffer if any (from j to argc). */
for (j = 0; j < argc; j++)
addReplyBulk(slave,argv[j]);
}
}
int canFeedReplicaReplBuffer(client *replica) {
/* Don't feed replicas that only want the RDB. */
if (replica->flags & CLIENT_REPL_RDBONLY) return 0;
/* Don't feed replicas that are still waiting for BGSAVE to start. */
if (replica->replstate == SLAVE_STATE_WAIT_BGSAVE_START) return 0;
return 1;
}从canFeedReplicaReplBuffer函数的实现中可以看到,只要从节点状态不是 SLAVE_STATE_WAIT_BGSAVE_START,写命令就会通过 addReply 系列函数添加到从节点对应的客户端输出缓冲区中。这意味着在以下状态下,命令都会被缓冲:
- SLAVE_STATE_WAIT_BGSAVE_END(等待RDB生成完成)
- SLAVE_STATE_SEND_BULK(发送RDB中)
- SLAVE_STATE_ONLINE(在线状态)
这保证了在主节点开始为某个从节点生成 RDB 快照之前,新的写命令不会进入其对应的客户端输出缓冲区中;主节点一旦开始生成RDB,之后的写命令便会进入输出缓冲区。并且Redis的事件处理是单线程模型,执行命令必然在从节点状态变化的前或者后,而不会在状态变化期间并发执行。所以严格的状态控制确保了输出缓冲区中的第一条命令正好是RDB快照后的第一条命令。
那数据的加载顺序是如何保证的呢?这依赖于主节点对发送顺序的控制。在RDB快照的生成,传输和加载阶段,主节点的增量写命令都只会缓存在主从连接的输出缓冲区里,不会往socket中写入;一直等到从节点加载完RDB后,发送 REPLCONF ACK 命令通知主节点,主节点才会开始把输出缓冲区中的增量命令真正写入socket。我们来看看Redis的具体实现。
void replconfCommand(client *c) {
...
else if (!strcasecmp(c->argv[j]->ptr,"ack")) {
/* REPLCONF ACK is used by slave to inform the master the amount
* of replication stream that it processed so far. */
long long offset;
if (!(c->flags & CLIENT_SLAVE)) return;
if ((getLongLongFromObject(c->argv[j+1], &offset) != C_OK))
return;
if (offset > c->repl_ack_off)
c->repl_ack_off = offset;
c->repl_ack_time = server.unixtime;
...
// 关键:收到ACK后,真正将从节点上线
if (c->repl_put_online_on_ack && c->replstate == SLAVE_STATE_ONLINE)
putSlaveOnline(c); // 这里会安装写处理器
return;
}
...
}
void putSlaveOnline(client *slave) {
slave->replstate = SLAVE_STATE_ONLINE;
...
// 关键:安装sendReplyToClient作为写处理器
if (connSetWriteHandler(slave->conn, sendReplyToClient) == C_ERR) {
serverLog(LL_WARNING,
"Unable to register writable event for replica bulk transfer: %s",
strerror(errno));
freeClient(slave);
return;
}
...
serverLog(LL_NOTICE,"Synchronization with replica %s succeeded",
replicationGetSlaveName(slave));
}`
`可以看到,在从节点加载完RDB后,会通知到主节点,主节点接到通知后给该从节点的连接安装写处理器sendReplayToClient,之后输出缓冲区中的写命令就可以发送给从节点了。
总之,数据对齐依赖于严格的状态机控制,而加载顺序依赖于在正确的时间点安装写处理器。本小节分析的核心流程可总结为以下时序图:
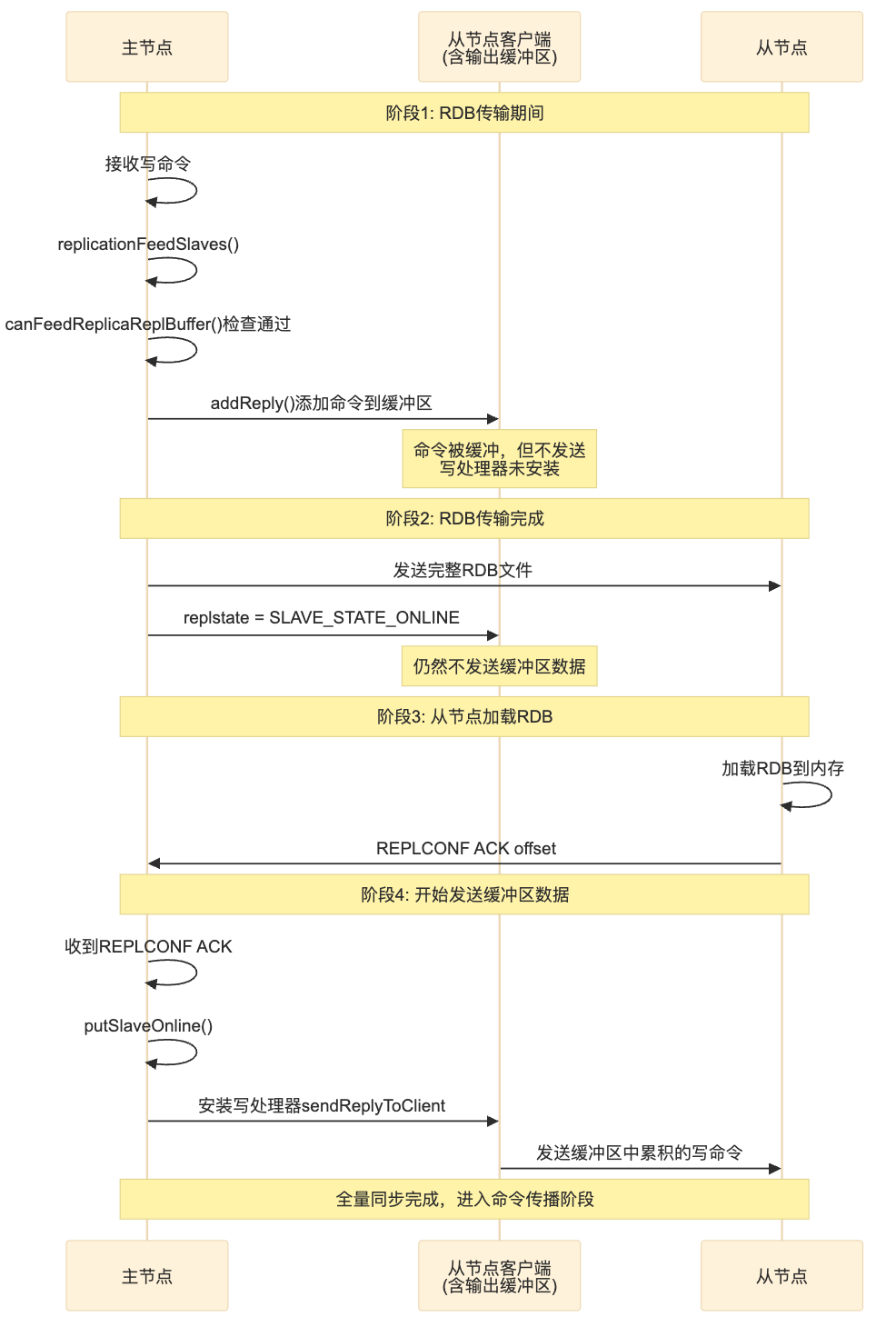
图 5 、数据对齐与加载顺序控制相关过程时序图
2 . 4 主从同步状态机
前面已经多次提到过Redis通过状态机来实现对主从复制流程的控制。图6是Redis主从复制状态机的示意图。由于主从复制同时涉及到主节点和从节点两个角色,因此主节点和从节点各有一套状态机。后面会讲到Redis的增量同步,它可以大大加快主从同步的速度。
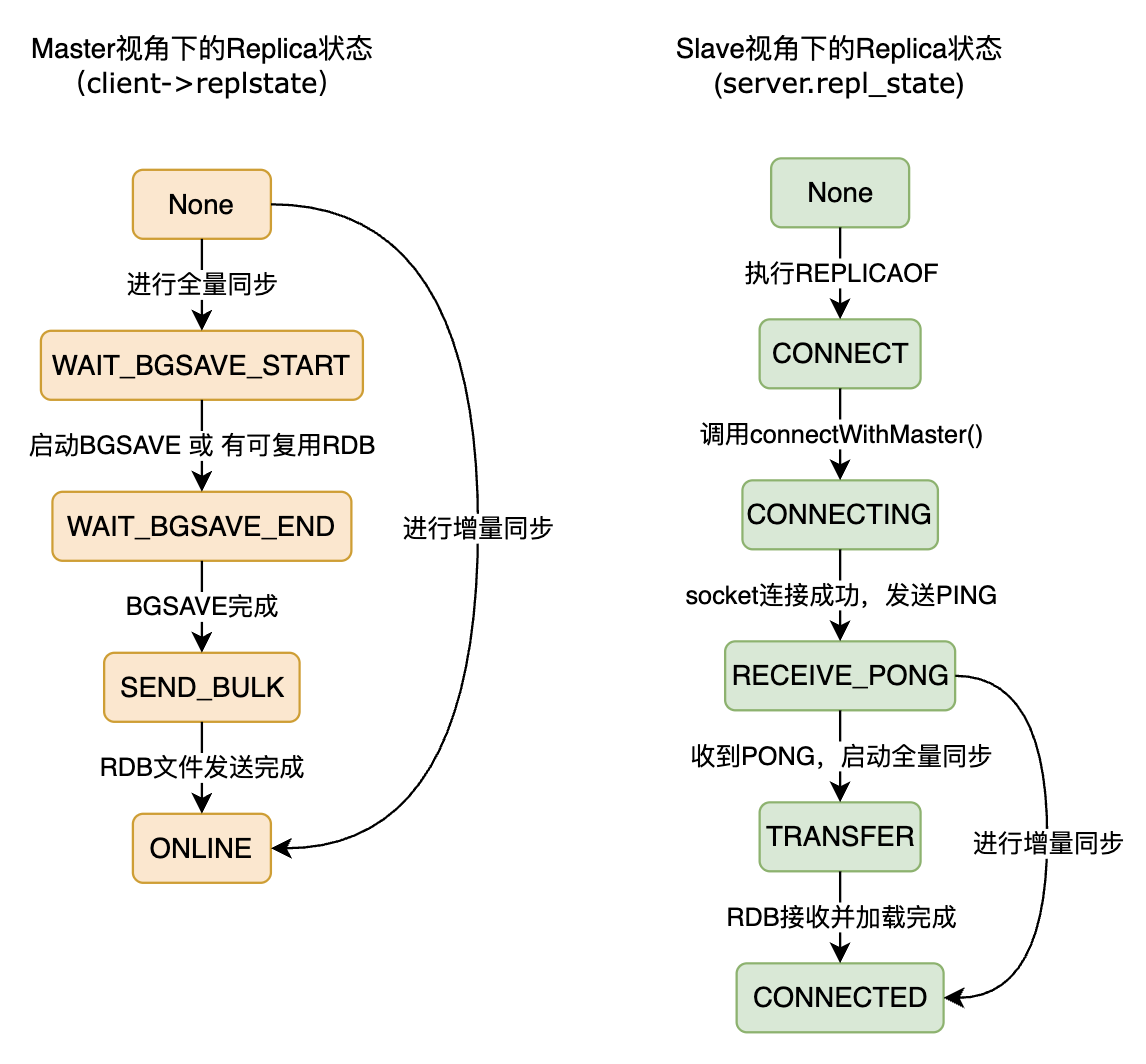
图 6 、Redis主从复制状态机
3 命令传播
3.1 命令传播的实现
全量同步结束后,主从节点就进入了相对稳定的命令传播阶段。如果说全量同步期间主从节点间传递的数据是一波"汹涌的洪流",那全量同步结束后,传递的数据则是一条"平缓的小溪"。命令传播的方式非常简单------主节点每收到一条写命令,就将该命令发送给每个从节点。
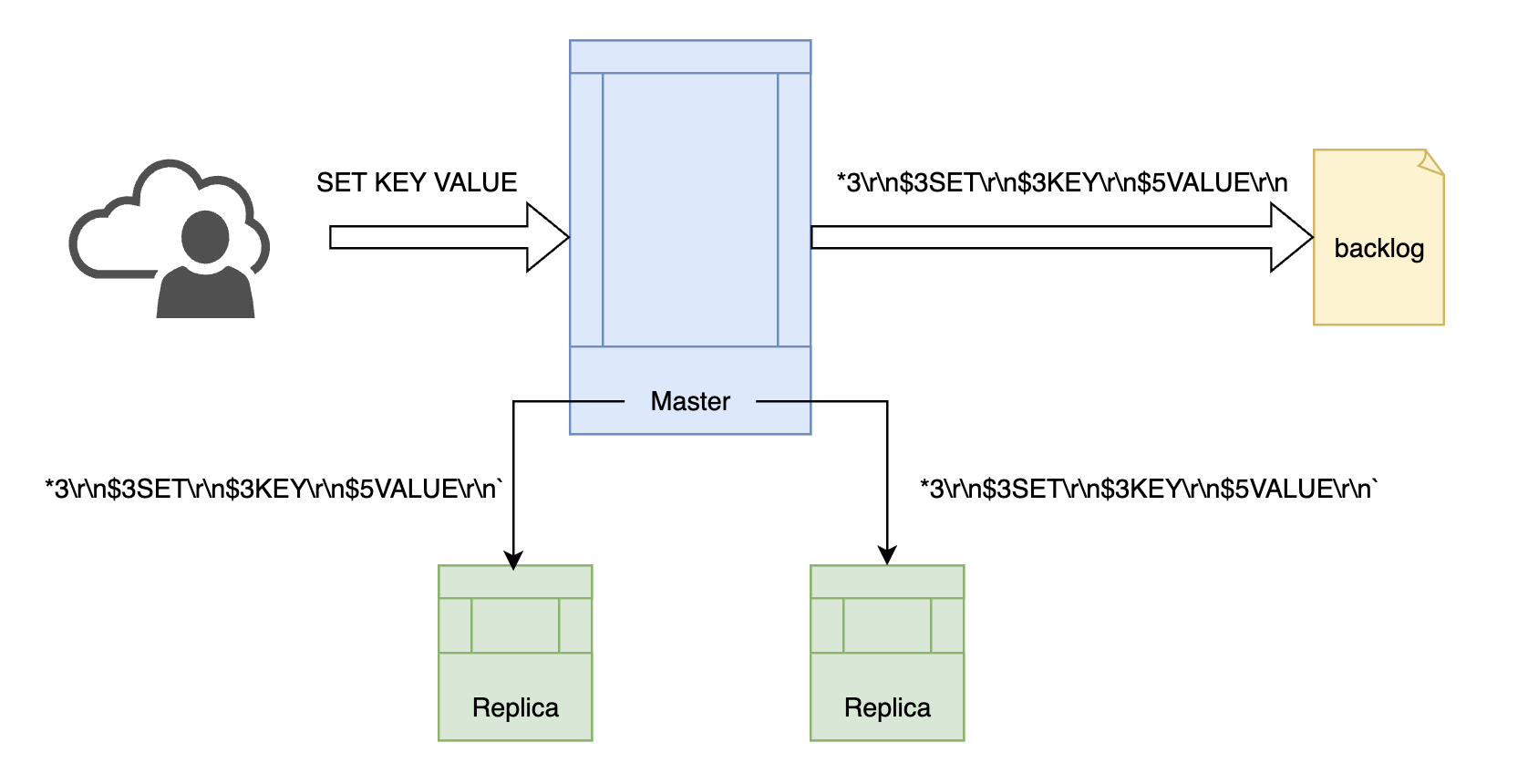
图7、命令传播
除了将命令发给从节点外,主节点还会将命令发送一份到复制积压缓冲区中(上图中的backlog,后文会细讲),用于增量同步。
这里稍加深入,介绍一下Redis命令的编码格式。Redis命令的编码使用Redis serialization protocol (RESP)格式。一条命令如果有argc个参数,第i个参数的长度为leni, 那么转换为RESP格式为*<argc>\r\n\
例如命令SET KEY VALUE转换为RESP格式为*3\r\n3SET\\r\\n3KEY\r\n$5VALUE\r\n。
主节点发送给从节点和复制积压缓冲区的命令都为RESP格式。
3.2 数据一致性
世界上每一个数据冗余机制都会面临数据一致性问题,Redis主从复制也不例外。
出于性能方面的考虑,Redis的命令传播是异步的。当主节点执行完命令,在客户端获得返回值"OK"时,命令可能还没传到从节点,这就产生了主从节点数据不一致的问题。如果此时用户向从节点发送读命令,那么得到的返回结果就是(nil)。用户明明刚写了一个key,却读不到这个key。
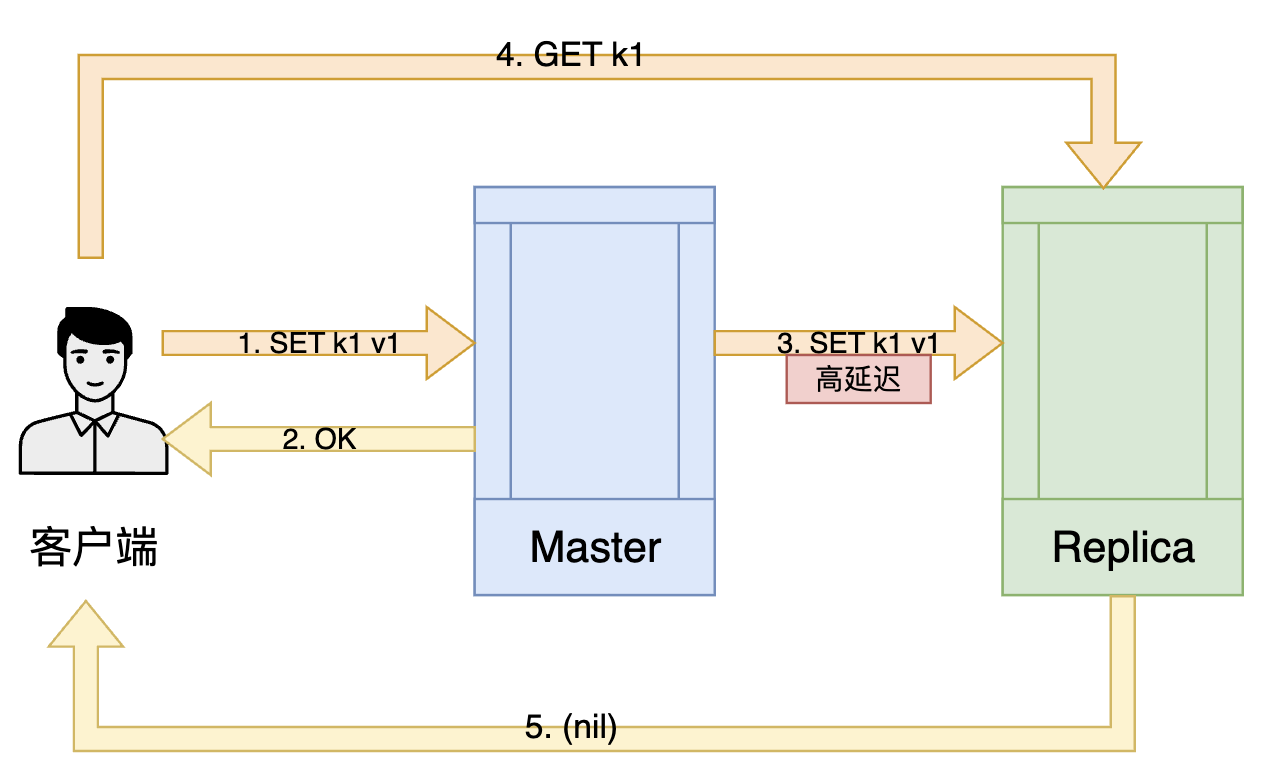
图8、主从连接高延迟导致主从数据不一致
To be honest,Redis并不是一个擅长处理数据不一致问题的数据库,这可能是追求高性能而不得不作出的妥协。但Redis依旧为了数据一致性做出了一些努力,主要是min-replicas-to-write配置和WAIT命令。
- min-replicas-to-write
min-replicas功能保证数据一致性的方式是去验证主从节点间网络连接状态是否良好。如果主从之间网络连接延迟较高,那么出现数据不一致现象的概率也越高,此时主节点会拒绝写入。更具体一点,在写操作前,Redis主节点会检查当前有多少个网络连接状态良好的从节点,只有这些从节点的数量不少于min-replicas-to-write时才会允许主节点执行写命令。
网络连接的流畅度由lag值来衡量,lag是主节点距离上一次接收到从节点心跳的时间间隔。例如使用以下配置,主节点在接收到写命令之后,会确保自己至少拥有3个lag值小于1s的从节点才会进行写操作,否则该命令将会被拒绝。
min-replicas-to-write 3
min-replicas-max-lag 1- WAIT命令
如果说min-replicas-to-write是内核自动去尽可能维护数据一致性,那么WAIT命令就是由用户去强行保证数据一致性。
WAIT命令的使用方式为
WAIT <num_replicas> <milliseconds_timeout>WAIT命令会持续阻塞redis-client,直到确认有至少num_replicas个从节点与主节点完全同步,或达到指定的超时时间 milliseconds_timeout 时返回。
WAIT命令的使用示例如下,在一次性向主节点写入1000000个key后,为了确保主从一致,先运行一次WAIT 2 10000,结果返回2。说明两个从节点都已经同步完成,接下来就可以放心地向两个从节点发送读请求啦。
127.0.0.1:7000> info replication
# Replication
role:master
connected_slaves:2
...
127.0.0.1:7000> EVAL "for i = 1, 1000000 do redis.call('SET', 'k'..i, 'v'..i) end" 0
(nil)
127.0.0.1:7000> WAIT 2 10000
(integer) 2
127.0.0.1:7000> 4 Redis 主从复制 演进史
自2009年Redis诞生,到今天Redis已更新迭代到8.x版本,Redis主从复制在持续不断地优化演进。无数思维活跃的开源贡献者们向社区奉献他们的智慧,让Redis主从复制更快、更稳、更省内存。接下来让我们来细细欣赏历史上Redis主从复制机制的几次重要升级。
4 . 1 Redis 2.8: 增量同步(PSYNC)
我们先来考虑这么一个场景:Redis从节点因网络原因断开了与主节点的连接,但网络很快就恢复了,从节点在短暂断连后重新连上了主节点。在过去的十几秒内,主节点已经接受了一些写命令并更新了数据。为了与主节点再次同步数据,从节点只好向主节点申请全量同步,收RDB,加载RDB,balabala。但事实上,在断连的短暂时间内,从节点只有很少部分数据与主节点不一致,大多数数据都是一样的。此时进行全量同步显然是一个费时费力的操作,有没有一个办法,能让主节点只把从节点缺失的那部分数据发过去就完事儿了呢?
增量同步能做到。它诞生于Redis 2.8版本,生来就是短暂断连场景的王者
在介绍增量同步的具体实现前,我们先来讲一下主节点如何判断是否能进行增量同步。判断的依据来源于replica发送的PSYNC命令中的两个参数:replid 和offset。
(PSYNC命令的基本格式为PSYNC <replid> <offset>)
- replid ,即replication id,是数据集的标记。id一致说明是同一数据集。每个master有唯一的replid,replica则会继承所属master的replid,标识自己是从哪一个master中同步数据。
- offset ,即偏移量,用于标识数据同步到了哪一步。offset是源自复制积压缓冲区(replication backlog)的概念,一个偏移量就对应了写命令的一个字节。写命令在复制积压缓冲区中的存储格式为前面介绍过的RESP。
在介绍了上述两个参数的概念后,我们可以简单分析出增量同步的条件:
- master的replid与psync命令中的replid一致。
- pysnc命令中的offset在复制积压缓冲区的范围内。
增量同步实现的核心数据结构是复制积压缓冲区。它是Redis 主节点维护的一个固定大小的环形数组,用于存储最近一段时间内发送给从节点的写命令数据流。其基本数据结构如下:
long long master_repl_offset; /* 全局复制偏移量*/
char *repl_backlog; /* 复制积压缓冲区(用于部分同步) */
long long repl_backlog_size; /* 积压缓冲区的环形缓冲区大小 */
long long repl_backlog_histlen; /* 积压缓冲区中实际数据的长度 */
long long repl_backlog_idx; /* 积压缓冲区环形缓冲区的当前偏移量 */
long long repl_backlog_off; /* 积压缓冲区中的最小偏移量 */
time_t repl_backlog_time_limit; /* 无从节点时积压缓冲区被释放的时间限制 */当主节点接收写命令并调用replicationFeedSlaves时,除了将写命令传播给从节点,还会将写命令存一份到复制积压缓冲区中,调用的函数为feedReplicationBacklog。
/* Add data to the replication backlog.
* This function also increments the global replication offset stored at
* server.master_repl_offset, because there is no case where we want to feed
* the backlog without incrementing the offset. */
void feedReplicationBacklog(void *ptr, size_t len) {
unsigned char *p = ptr;
server.master_repl_offset += len;
/* This is a circular buffer, so write as much data we can at every
* iteration and rewind the "idx" index if we reach the limit. */
while(len) {
size_t thislen = server.repl_backlog_size - server.repl_backlog_idx;
if (thislen > len) thislen = len;
memcpy(server.repl_backlog+server.repl_backlog_idx,p,thislen);
server.repl_backlog_idx += thislen;
if (server.repl_backlog_idx == server.repl_backlog_size)
server.repl_backlog_idx = 0;
len -= thislen;
p += thislen;
server.repl_backlog_histlen += thislen;
}
if (server.repl_backlog_histlen > server.repl_backlog_size)
server.repl_backlog_histlen = server.repl_backlog_size;
/* Set the offset of the first byte we have in the backlog. */
server.repl_backlog_off = server.master_repl_offset -
server.repl_backlog_histlen + 1;
}feedReplicationBacklog(void *ptr, size_t len)将ptr处的长度为len的字节copy到server.repl_backlog中,并更新相关偏移量。
当replica断连一段时间重连后,只需要master向replica发送repl_backlog中落后部分的写命令即可,避免了全量同步的较大开销。例如在图8中,用一个圆圈表示复制积压缓冲区,左边的master只需要将红色部分的字节发送给从节点即可;而右边master的复制积压缓冲区已经写满了一圈并且覆盖到了未同步的数据,因此只能遗憾地进行全量同步。
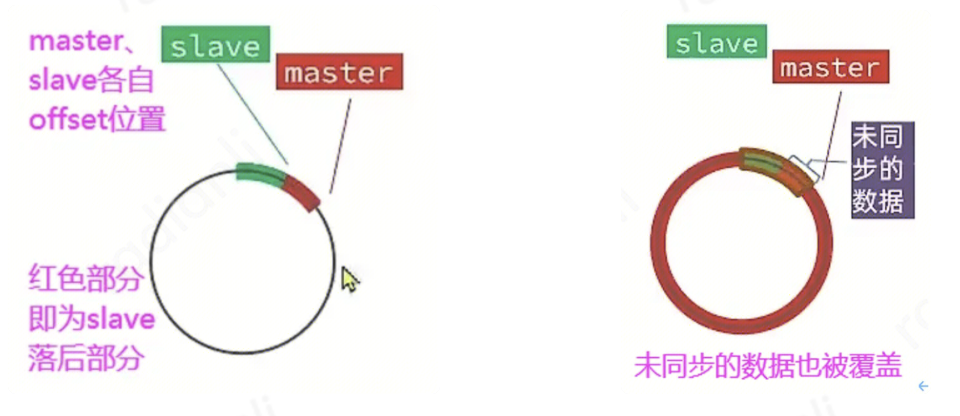
图 9 、复制积压缓冲区示意图 3
增量同步的流程也非常简单,如下图所示:

图 1 0 、增量同步流程示意图
4 . 2 Redis 4.0: PSYNC2
Redis 复制在PSYNC2前有以下两点问题:
首先是**从节点重启导致不必要的全量同步。**上一章节谈到过,增量同步依赖replid和offset,目前信息仅存于内存。从节点重启后,内存中的replid和offset就丢失了,从而无法执行增量同步,被迫进行全量同步,造成资源浪费。
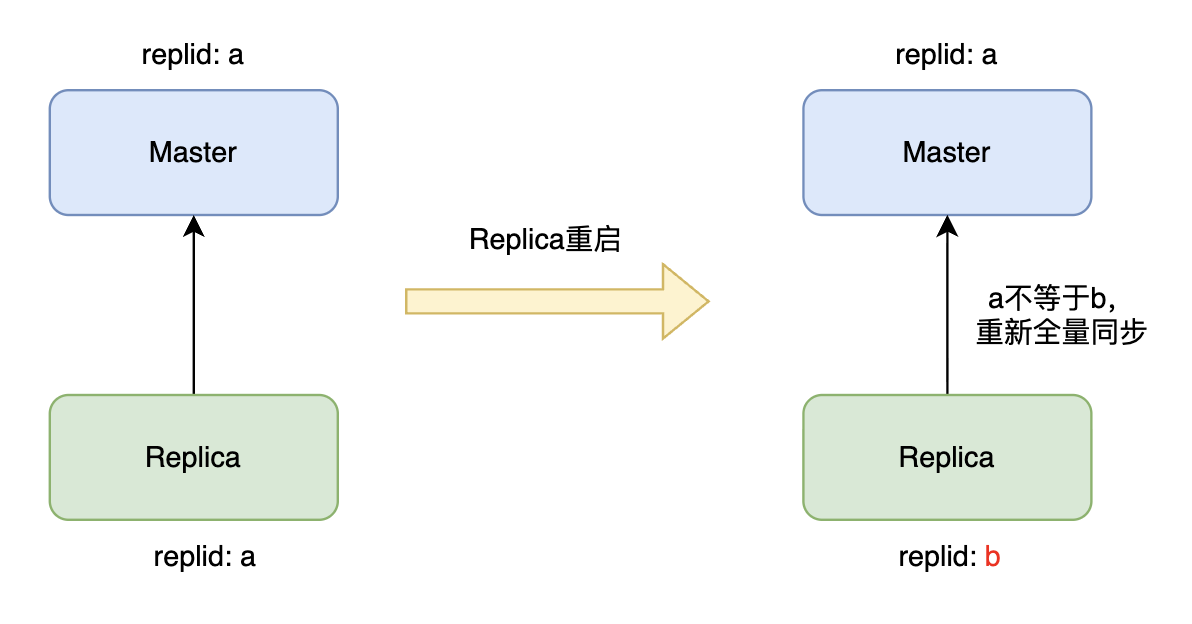
图1 1 、从节点重启丢失replid
如上图所示,从节点重启后,replid a丢失,生成了一个新的replid b,与主节点不一致,从而只能全量同步,尽管与主节点只有少部分数据不一致。
然后是主从切换导致不必要的全量同步(一主多从场景)。假如主节点意外宕机,其中一个复制偏移量最大的从节点被提升为新的主节点,并生成一个新的replid,导致剩余从节点与新主节点的replid不一致,必须全量同步。具体情况如图11所示。
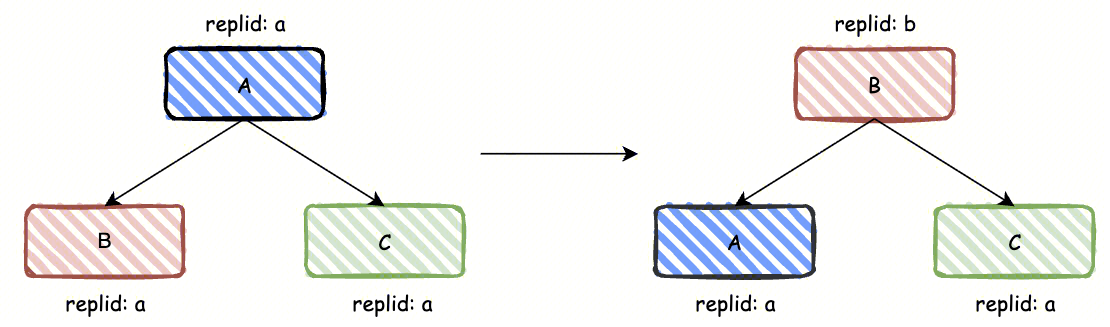
图1 2 、主从切换后,从节点不认识新主 4
为解决上述问题,Redis 4.0设计了PSYNC2。
- 从节点重启后的增量同步
要解决从节点重启后丢失replid和offset的问题,只需要将主节点ID和复制偏移量持久化到 RDB 文件中,重启后便可恢复这些信息。没错,就是这么简单直接。
- 主从切换后的增量同步
主从切换后不能增量同步的原因在于,提主的从节点变成主节点后就"忘了旧主",因此解决办法就是让从节点提主后依旧"认旧主"。PSYNC2设计下,提主后的新主节点会记录自己原先的主节点 I D (master_replid2) ,并保留一段复制积压缓冲区 ( 配套 s e c o n d _ r e p l i d _ o f f s e t ) 。从节点找新主节点做数据同步时,若其原主节点ID与新主节点的 master_replid2 匹配,且偏移量在新主节点的复制积压缓冲区范围内,则可直接执行增量同步。
PSYNC2下主从复制 replid的变更流程详见下图。节点B在提主后将A的id记录在replid2中。申请同步时,A、C的replid a与B的replid2 a一致,因此能进行增量同步。同步后A、C的replid变更为新主的b。
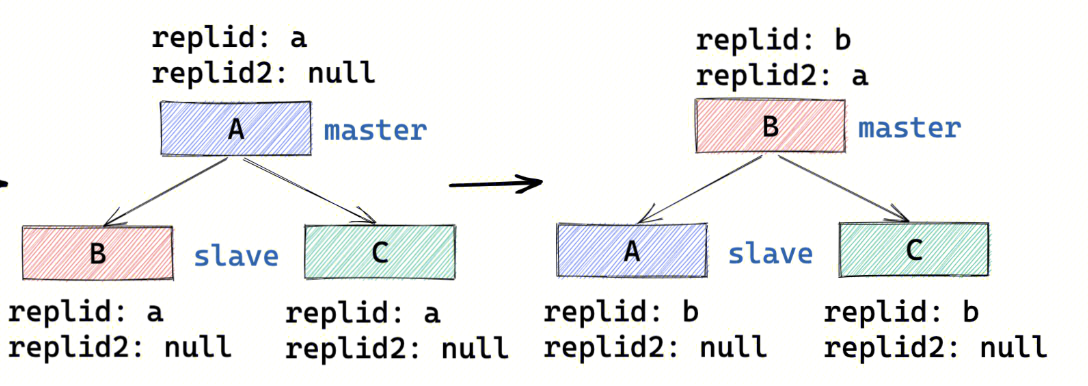
图1 3 、PSYNC2下replid 变更流程 4
4 .3 Redis 6.0: 无盘加载
Redis 6.0支持从节点无盘加载来自主节点的RDB数据,即无需将RDB数据存储到本地就可以将其加载到内存中。
无盘加载通过网络socket一边读取数据,一边加载数据。为避免数据加载异常,需要在加载前使用临时db备份之前内存的数据。
可以发现,从6.0版本开始,Redis主从复制已经支持同时支持了RDB的无盘传输和无盘加载,将RDB相关的操作完全无盘化了。
4 .4 Redis 7.0: 共享(全局)复制缓冲区
原有复制缓冲区设计存在以下两点问题:
多从节点导致主节点内存占用过多
每个从节点在主节点上都有独立的output buffer,全量同步和增量同步时都会将写命令写入所有从节点的output buffer以及repl_backlog。在全量同步阶段,缓冲区数据量大,容易触发 client-output-buffer-limit,导致主节点断开从节点连接,同步失败。不难发现,全量同步时,每个从节点的output buffer与主节点的repl_backlog中有许多相同的数据,这些相同的数据被拷贝了多份,造成了内存的浪费。
output buffer 数据拷贝与释放的阻塞问题
我们在3.1.1小节提到过,为了让多个从节点共享一次 BGSAVE 生成的 RDB,Redis 会将已在同步的从节点 output buffer数据拷贝到新请求全量同步的从节点output buffer 中。当 output buffer 数据量很大时,拷贝操作可能耗时百毫秒甚至秒级,造成阻塞。当 output buffer 触发大小限制被关闭连接时,释放大量数据的过程同样可能耗时较长,对 Redis 性能造成影响。
为解决上述两点问题,Redis 7.0提出了共享复制缓冲区的方案。共享复制缓冲区的核心思想是:主节点在命令传播时,将数据写入一个全局共享的复制缓冲区,所有从节点按各自进度引用其中的不同位置,从而避免为每个从节点维护一份相同数据的 output buffer,repl_backlog也共用这份数据。相关数据结构代码即示意图如下:
/* 共享复制缓冲区数据块 */typedef struct replBufBlock {
int refcount; /* 引用计数:有多少个从节点或backlog在使用 */
long long id; /* 唯一递增的块ID */
long long repl_offset; /* 该块起始的复制偏移量 */
size_t size, used; /* 块大小和已使用大小 */
char buf[]; /* 柔性数组:实际数据缓冲区 */
} replBufBlock; /* 优化后的复制积压缓冲区 */typedef struct replBacklog {
listNode *ref_repl_buf_node; /* 引用的复制缓冲区块节点 */
size_t unindexed_count; /* 距离上次创建索引的块数量 */
rax *blocks_index; /* 块索引(Radix树),用于快速查找 */
long long histlen; /* backlog实际数据长度 */
long long offset; /* backlog第一个字节的复制偏移量 */
} replBacklog;
/* 优化后的客户端输出缓冲区 */typedef struct client {
// ...
listNode *ref_repl_buf_node; /* 引用的复制缓冲区块节点 */
size_t ref_block_pos; /* 在当前块中的读取位置 */
// ...
} client;struct redisServer {
// ...
list *repl_buffer_blocks; /* 共享复制缓冲区数据块链表 */
// ...
}从上面数据结构的定义中可以看到,共享复制缓冲区在redisServer中设置了一个全局的复制缓冲区块列表server.repl_buffer_blocks。更新后的复制积压缓冲区和客户端输出缓冲区不再需要单独分配一片内存空间存储命令字节,只需要维护一个复制缓冲区的块节点引用和在当前块中的读取位置即可。
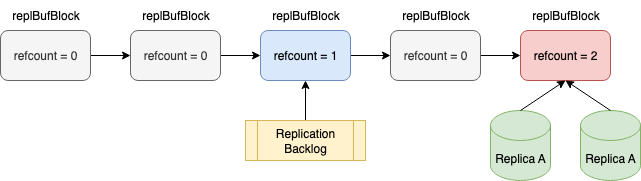
图1 4 、共享复制缓冲区示意图
有了上述结构,就不用再为每个replica维护一个output buffer,内存大小不会再随着replica数量线性增长;此外对master而言,只需要为每个replica维护一个对共享复制缓冲区的引用信息即可,所以之前的数据深拷贝变成了更新引用信息,非常轻量,不再会有阻塞问题。
此外,由于现在我们使用链表管理复制积压区,遍历整个链表来查找对应节点可能会很耗时。因此,Redis 7.0创建了一个 rax 树来索引部分节点(每 64 个节点创建一个索引),以加快查找速度。
4 .5 Redis 8.0: RDB通道
有了Redis全量同步的精巧设计与Redis各版本的持续演进,全量同步依旧存在以下两个痛点:
- **主节点客户端输出缓冲区压力过大:**在全量同步期间,RDB生成、发送、加载期间传入的所有写命令都暂存到输出缓冲区中。对大实例而言,这一过程耗时往往较长,导致主节点输出缓冲区中累积大量命令,带来很大的内存压力。一旦累积的命令超过了输出缓冲区的限制,主节点将终止该从节点连接,导致复制失败。
- **主节点CPU负载较高:**使用无盘传输时,由于 TLS 连接的限制,子进程需要将 RDB 字节通过管道传输给主进程,再由主进程转发给副本。这个中间转发过程涉及了多次系统调用,带来了额外的CPU开销。
为了解决以上痛点,Redis 8.0 引入了一种全新的复制机制------RDB Channel,其设计示意图如下。
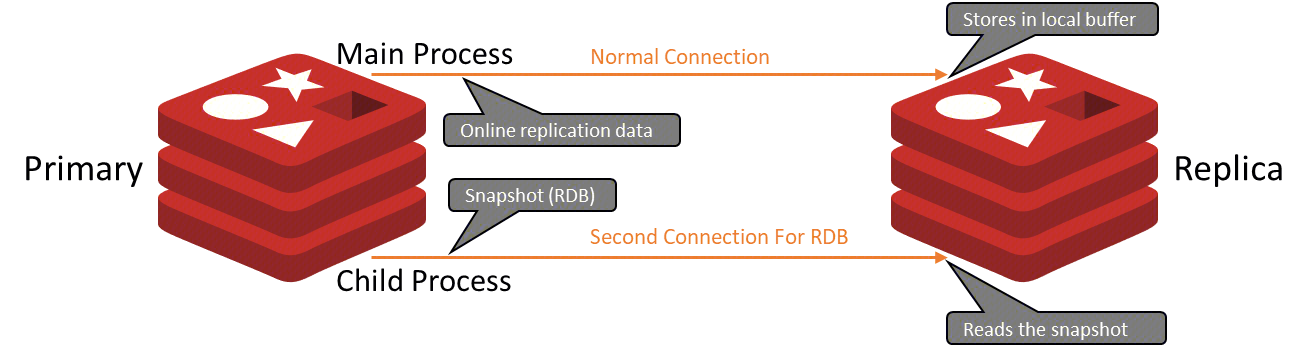
图1 5 、RDB Channel设计示意图 5
在RDB Channel的帮助下,主节点与从节点间建立了两条通道,分别用于传输RDB(RDB Channel)与RDB生成、传输、接收、加载期间的增量命令(Main Channel)。两条通道同时传输数据,增量命令不再暂存到主节点端的输出缓冲区中,而是存入从节点端的内存缓冲区中。
Redis双通道复制的一个巧妙设计在于其复用了PSYNC的逻辑。 具体来说,从节点首先通过RDB通道发送PSYNC ? -1命令向主节点请求RDB数据,主节点随即启动BGSAVE开始生成RDB,在开始生成前通过RDB通道响应+FULLRESYNC <replid> <offset>,将当前的复制ID和偏移量告知从节点。从节点接收并解析这个响应后,会将replid和offset保存下来,作为后续主通道建立的关键参数。接着,从节点利用这些信息通过主通道发送PSYNC <replid> <offset>命令,此时主节点会将其识别为部分重同步请求并响应+CONTINUE。这样一来,主节点会将RDB生成、发送、加载期间新收到的写命令通过主通道发送给从节点。可以看到,主通道的这部分逻辑与部分重同步完全一致,是对现有机制的优雅复用。
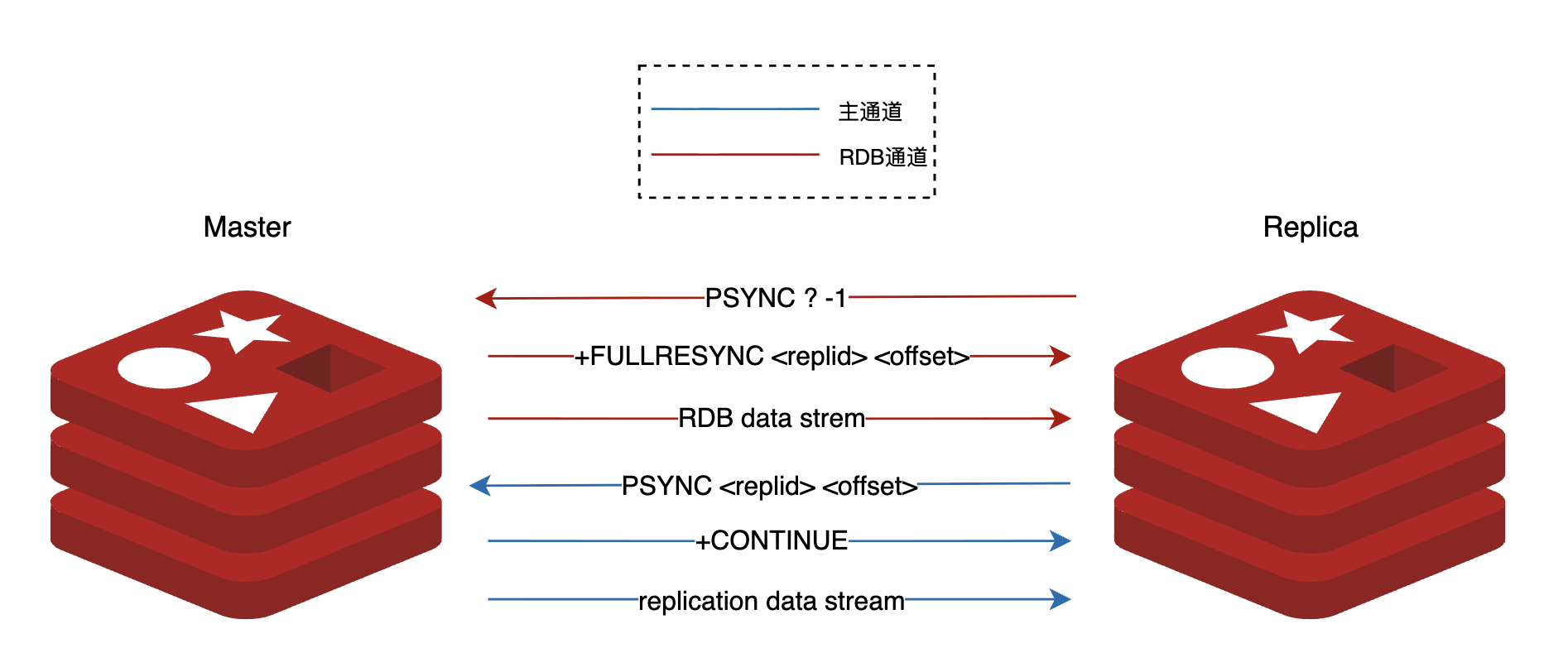
图1 6 、双通道模式下主从节点部分通信信息
RDB Channel replication带来的好处如下:
- 降低主节点输出缓冲区压力。暂存增量命令的任务从主节点转移给了从节点,从而降低了主从同步期间因为输出缓冲区打满导致连接断开的风险。由于从节点在全量同步期间扮演的角色不如主节点重要,因此让从节点担任该任务是更加合适的。
- 降低主节点主进程的 CPU 负载。通过为 RDB 传输开辟一条新的专用连接,子进程可以直接访问该新连接,从而消除了子进程使用主节点"子进程 -> 主进程"管道的需要,降低了主进程的CPU负载。另外一个好处是,即使主线程那边有命令阻塞,也不会影响 rdb channel 继续发送,rdb数据的传输会更加稳定。
- 全量同步速度更快。原来需要先传RDB数据,再传增量命令。现在有了两个通道,这两步可以同时进行,加速了全量同步速度。
在测试中,该特性的贡献者对一个10 GB的数据集进行了完整同步,同时在此期间额外产生了 2684 万次写操作,这些写操作在复制过程中生成了25 GB的变更数据。借助新的复制机制,主节点在复制期间处理写操作的平均速率提高了7.5%。此外,复制所需时间减少了18%,且主节点上的复制缓冲区峰值大小降低了35%。6
5 总结
从本文可以看到,Redis 主从复制机制围绕"如何在不牺牲性能的前提下保证数据高可用与一致性"这一核心目标不断演进:从最初基于 RDB 快照的全量同步,到利用复制积压缓冲区实现的增量同步,构建出一套完整而可靠的数据复制链路。随后,Redis 又在多个版本中持续优化复制细节:4.0 的 PSYNC2 缓解了主从切换和重启场景下的全量同步压力,6.0 的无盘加载进一步在从节点端减轻了磁盘负担,7.0 的共享复制缓冲区则显著优化了多从场景下的内存占用和阻塞问题,8.0 的RDB Channel大大减小了主节点的内存压力,缩短了复制时间。理解这些机制与源码中的关键实现,不仅有助于我们在生产环境中更合理地部署与调优 Redis,也为设计其他分布式系统的复制与高可用方案提供了有价值的工程经验与借鉴。
参考资料
1 Redis replication, Redis replication | Docs
3 《Redis学习笔记------Redis高级篇之分布式缓存》,Redis学习笔记--Redis高级篇之分布式缓存分布式缓存 1.Redis持久化 Redis有两种持久化方案: RDB - 掘金
4 《Redis主从复制演进史与奇思妙想》,Redis主从复制演进史与奇思妙想 | 咕咕
5 Second Channel For RDB, Second Channel For RDB · Issue #11678 · redis/redis · GitHub
6 Redis 8 is now GA, loaded with new features and more than 30 performance improvements, Redis 8 is now GA, loaded with new features and more than 30 performance improvements | Redis