七、使用索引
1、自动创建
当我们为⼀张表加主键约束(Primarykey),外键约束(ForeignKey),唯一约束(Unique) 时, MySQL会为对应的的列自动创建⼀个索引
如果表不指定任何约束时,MySQL会自动为每⼀列生成⼀个索引并用ROW_ID 进行标识
2、手动创建
2.1主键索引
sql
#⽅式⼀,创建表时创建主键
create table t_test_pk (
id bigint primary key auto_increment,
name varchar(20)
);
# ⽅式⼆,创建表时单独指定主键列
create table t_test_pk1 (
id bigint auto_increment,
name varchar(20),
primary key (id)
);
# ⽅式三,修改表中的列为主键索引
create table t_test_pk2 (
id bigint,
name varchar(20)
);
alter table t_test_pk2 add primary key (id) ;
alter table t_test_pk2 modify id bigint auto_increment;2.1.1.查看表的结构:
表的结构
sql
desc table_Name;这个语法是简单的表的结构
查看完整的表的结构:
sql
show keys from table_name;
show index from table_name;

2.1.2 注意主键唯一性
sql
alter table table_name add primary key (主键名);MySQL 中一张表只能有且仅有一个主键(包括单列主键、复合主键)
2.1.3正确更换主键
sql
-- 步骤1:删除原有主键(name列的主键)
alter table test_pk drop primary key;
-- 步骤2:给id添加新主键(可选:若需自增,先修改列属性)
alter table test_pk modify id bigint auto_increment; -- 可选自增
alter table test_pk add primary key (id); -- 新增id为主键2.1.4 特殊的复合主键
原有主键是「复合主键」(如 primary key (name, age)),执行 add primary key (id) 同样报错;若想将主键改为「id + 其他列」的复合主键,仍需先删旧主键,再新增复合主键:
sql
-- 删除原有复合主键
alter table test_pk drop primary key;
-- 新增id+name的复合主键
alter table test_pk add primary key (id, name);2.1.5 自增主键的删除
sql
-- 先取消自增(假设原主键列是 id)
alter table table1 modify id bigint; -- 去掉 auto_increment
-- 再删除主键
alter table table1 drop primary key;注意:如果原有主键列带有 AUTO_INCREMENT(自增)属性,删除主键前需先取消自增,否则会报错:
2.2唯一索引
sql
# ⽅式⼀,创建表时创建唯⼀键
create table t_test_uk (
id bigint primary key auto_increment,
name varchar(20) unique
);
# ⽅式⼆,创建表时单独指定唯⼀列
create table t_test_uk1 (
id bigint primary key auto_increment,
name varchar(20),
unique (name)
);
# ⽅式三,修改表中的列为唯⼀索引
create table t_test_uk2 (
id bigint primary key auto_increment,
name varchar(20)
);
alter table t_test_uk2 add unique (name) ;当你给列添加 UNIQUE 约束时,MySQL 会自动为该列生成对应的唯一索引 (索引类型为 UNIQUE),二者是「约束规则 + 索引结构」的一体关系,无需额外操作
2.3普通索引
1.指定索引列
sql
# ⽅式⼀,创建表时指定索引列
create table t_test_index (
id bigint primary key auto_increment,
name varchar(20) unique
sno varchar(10),
index(sno)
);
2.修改表中的列为普通索引
sql
# ⽅式⼆,修改表中的列为普通索引
create table t_test_index1 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
alter table t_test_index1 add index (sno) ;3.单独创建索引并指定索引名

sql
# ⽅式三,单独创建索引并指定索引名
create table t_test_index2 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
create index index_name on t_test_index2(sno);总结:
sql
# ⽅式⼀,创建表时指定索引列
create table t_test_index (
id bigint primary key auto_increment,
name varchar(20) unique
sno varchar(10),
index(sno)
);
# ⽅式⼆,修改表中的列为普通索引
create table t_test_index1 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
alter table t_test_index1 add index (sno) ;
# ⽅式三,单独创建索引并指定索引名
create table t_test_index2 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
create index index_name on t_test_index2(sno);3、创建复合索引
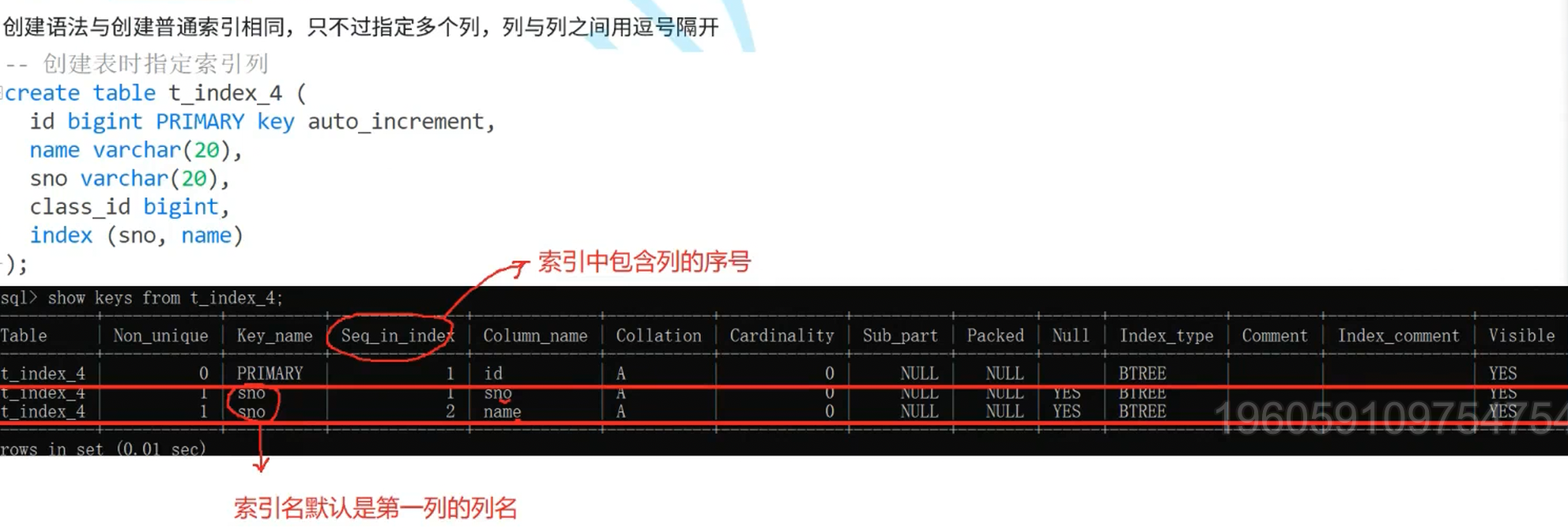
创建语法与创建普通索引相同,只不过指定多个列,列与列之间用逗号隔开,默认索引名是第一列的列名
sql
# ⽅式⼀,创建表时指定索引列
create table t_test_index4 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint,
index (sno, class_id)
);
# ⽅式⼆,修改表中的列为复合索引
create table t_test_index5 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint
);
alter table t_test_index5 add index (sno, class_id);
# ⽅式三,单独创建索引并指定索引名
create table t_test_index6 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint
);
create index index_name on t_test_index6 (sno, class_id);4、查看索引
方式1:
sql
# ⽅式⼀:show keys from 表名
show keys from t_test_index6;方式2:
sql
# ⽅式⼀:show index from 表名
show index from t_test_index6;方式三:
sql
# ⽅式⼆
show index from t_test_index6;
# ⽅式三,简要信息:desc 表名;
desc t_test_index6;5、删除索引
5.1.1、删除前必做:先查索引名(避免删错)
删除索引需要指定「索引名」(主键索引无需名,其他索引必须),先执行以下语句查看表的所有索引及名称:
sql
-- 查看表的索引信息(关键看 Key_name 列:索引名)
SHOW INDEX FROM 表名;示例(查看 t_test_uk 表的索引):
sql
SHOW INDEX FROM t_test_uk;字段解读:
Key_name:索引名(主键索引固定为PRIMARY,唯一 / 普通索引为自定义 / 默认名,如name、uk_name);Non_unique:0= 唯一索引,1= 普通索引。
5.1.2、分类型删除索引
类型 1:删除主键索引(PRIMARY KEY)
主键索引是特殊索引,删除有专属语法,且一张表仅一个主键索引,无需指定索引名。
基础语法
sql
ALTER TABLE 表名 DROP PRIMARY KEY;普通场景示例(无自增列)
sql
-- 先创建带主键的表(贴合你之前的结构)
CREATE TABLE t_test_pk (
id bigint PRIMARY KEY,
name varchar(20) UNIQUE
);
-- 删除主键索引(id列的主键)
ALTER TABLE t_test_pk DROP PRIMARY KEY;特殊场景:主键列带自增(AUTO_INCREMENT)
若主键列有 auto_increment 属性,直接删除会报错,需先取消自增,再删主键:
sql
-- 步骤1:创建带自增主键的表
CREATE TABLE t_test_pk_auto (
id bigint PRIMARY KEY AUTO_INCREMENT,
name varchar(20)
);
-- 步骤2:先取消id列的自增属性
ALTER TABLE t_test_pk_auto MODIFY id bigint; -- 去掉 AUTO_INCREMENT
-- 步骤3:删除主键索引
ALTER TABLE t_test_pk_auto DROP PRIMARY KEY;类型 2:删除唯一索引 / 普通索引 / 复合索引(通用语法)
唯一索引、普通索引、复合索引(包括多列组合的唯一 / 普通索引)共用两套等价语法,核心是指定「索引名」。
语法 1(推荐:ALTER TABLE 方式,通用)
sql
ALTER TABLE 表名 DROP INDEX 索引名;语法 2(简化:DROP INDEX 方式,等价)
sql
DROP INDEX 索引名 ON 表名;示例 1:删除唯一索引(单列)
sql
-- 先创建带唯一索引的表(你之前的示例表)
CREATE TABLE t_test_uk (
id bigint PRIMARY KEY AUTO_INCREMENT,
name varchar(20) UNIQUE -- 唯一索引,默认索引名:name
);
-- 方法1:ALTER TABLE 删除(推荐)
ALTER TABLE t_test_uk DROP INDEX name;
-- 方法2:DROP INDEX 删除(等价)
DROP INDEX name ON t_test_uk;示例 2:删除自定义名称的唯一索引
sql
-- 先创建带自定义索引名的唯一索引
CREATE TABLE t_test_uk1 (
id bigint PRIMARY KEY AUTO_INCREMENT,
name varchar(20),
UNIQUE uk_name (name) -- 自定义索引名:uk_name
);
-- 删除该唯一索引(指定自定义名 uk_name)
ALTER TABLE t_test_uk1 DROP INDEX uk_name;示例 3:删除复合索引(多列组合)
复合索引需「整体删除」,无法单独删除其中某一列,删除时指定复合索引的名称即可:
sql
-- 先创建复合唯一索引
CREATE TABLE t_test_uk2 (
id bigint PRIMARY KEY AUTO_INCREMENT,
name varchar(20),
phone varchar(11),
UNIQUE uk_name_phone (name, phone) -- 复合索引名:uk_name_phone
);
-- 删除复合索引(指定索引名 uk_name_phone)
ALTER TABLE t_test_uk2 DROP INDEX uk_name_phone;5.1.3、验证索引是否删除成功
执行以下语句,若索引名不再出现在 Key_name 列,说明删除成功:
sql
SHOW INDEX FROM 表名;5.1.4、关键注意事项(避坑核心)
- 主键索引删除后风险:主键是表的聚簇索引,删除后表失去聚簇索引,查询性能会显著下降,生产环境删主键后需及时重建;
- 复合索引无法拆分删除 :比如
uk_name_phone (name, phone),不能只删phone列的索引,只能整体删除后,重新创建仅包含name的索引; - 删除前确认依赖 :确保删除的索引无高频查询依赖(比如基于该索引的
WHERE/JOIN查询),否则会导致查询性能暴跌; - 大表删除索引的锁表风险:删除大表(百万级 +)的索引时,MySQL 会加表级锁,阻塞读写,建议在低峰期操作;
- 权限要求 :删除索引需要表的
ALTER权限(主键索引还需DROP权限); - 不可逆操作:索引删除后无法恢复,需重新创建(数据不会丢失,仅索引结构删除)。
5.2.1.查看表的结构:
表的结构
sql
desc table_Name;这个语法是简单的表的结构
查看完整的表的结构:
sql
show keys from table_name;
show index from table_name;5.2.2 注意主键唯一性
sql
alter table table_name add primary key (主键名);MySQL 中一张表只能有且仅有一个主键(包括单列主键、复合主键)
5.2.3正确更换主键
sql
-- 步骤1:删除原有主键(name列的主键)
alter table test_pk drop primary key;
-- 步骤2:给id添加新主键(可选:若需自增,先修改列属性)
alter table test_pk modify id bigint auto_increment; -- 可选自增
alter table test_pk add primary key (id); -- 新增id为主键5.2.4 特殊的复合主键
原有主键是「复合主键」(如 primary key (name, age)),执行 add primary key (id) 同样报错;若想将主键改为「id + 其他列」的复合主键,仍需先删旧主键,再新增复合主键:
sql
-- 删除原有复合主键
alter table test_pk drop primary key;
-- 新增id+name的复合主键
alter table test_pk add primary key (id, name);5.2.5 自增主键的删除
sql
-- 先取消自增(假设原主键列是 id)
alter table table1 modify id bigint; -- 去掉 auto_increment
-- 再删除主键
alter table table1 drop primary key;注意:如果原有主键列带有 AUTO_INCREMENT(自增)属性,删除主键前需先取消自增,否则会报错
6.其他索引
sql
# 语法alter table 表名 drop index 索引名;
# ⽰例,删除t_test_index6表中名为index_name的索引
alter table t_test_index6 drop index index_name;
# 查看结果
show keys from t_test_index6;7、创建索引的注意事项
- 索引应该创建在高频查询的列上
- 索引需要占用额外的存储空间
- 对表进行插入、更新和删除操作时,同时也会修索引,可能会影响性能
- 创建过多或不合理的索引会导致性能下降,需要谨慎选择和规划索引
8.执行计划查看explain
核心作用:分析查询的执行逻辑
MySQL 在执行一条 SQL 语句时,会先制定一个「执行计划」(比如:用什么方式访问表?是否使用索引?扫描多少行数据?)。EXPLAIN 语句的作用就是把这个计划**「可视化」**地展示出来,让你能看到:
- 查询是否会全表扫描(效率低)还是用了索引(效率高);
- 估计需要扫描多少行数据(行数越少越好);
- 表的访问顺序(如果是多表关联查询)等。

-
type (访问类型) : 这是判断查询性能最关键的字段。它显示了 MySQL 决定如何查找表中的行。
-
性能从差到好排序 :
ALL<index<range<ref<eq_ref<const/system<NULL -
常见类型详解:
-
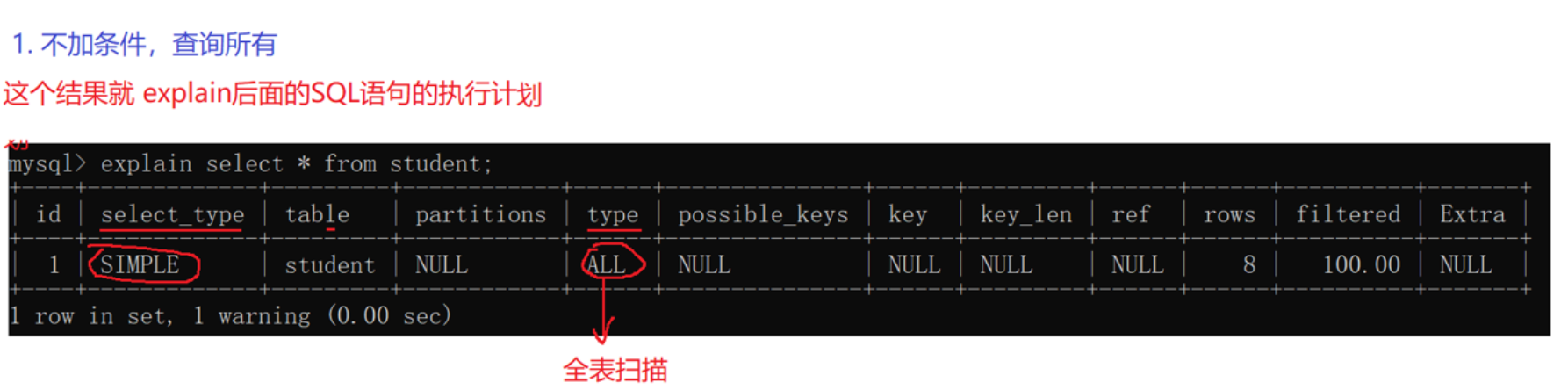
ALL: 全表扫描。性能最差,需要遍历整张表。例1就是这种情况。
-
index: 全索引扫描。遍历整个索引树,通常比ALL快,因为索引文件通常比数据文件小。
-
range : 索引范围扫描。使用索引查找一个范围内的值(如
BETWEEN,>,<)。 -
ref: 使用非唯一索引进行等值查找。可能返回多条匹配记录。
-
eq_ref : 使用唯一索引 (通常是主键或唯一约束)进行关联查询时,对于前表的每一行,后表只有一行匹配。常见于
JOIN ... ON ...操作。 -
const/system : 通过主键或唯一索引进行等值查询 ,最多返回一行。
system是const的特例(表只有一行)。性能最优。例2和例3的主查询部分就是const。 -
NULL: 不访问表或索引就能得到结果,例如从索引列中选取最小值。
-
-
-
possible_keys : 查询可能使用 的索引。如果为
NULL,表示没有找到可用的索引。 -
key : 查询实际使用 的索引。如果为
NULL,表示没有使用索引。 -
rows : MySQL 预估需要扫描的行数。这个值越小越好。
-
Extra: 包含执行计划的额外重要信息。
-
Using index: 表示查询使用了"覆盖索引",即所需数据直接从索引中获取,无需回表查询数据行。性能很好。例3的子查询部分就出现了这个提示。
-
Using where: 表示服务器在存储引擎检索行后进行过滤。
-
Using temporary : 表示需要创建临时表来处理查询,通常发生在排序 (
ORDER BY) 和分组 (GROUP BY) 时,会影响性能。 -
Using filesort: 表示无法利用索引完成排序,需要额外的排序步骤,会影响性能。
-
8.1不加条件,查询所有
 8.2使用主键查询
8.2使用主键查询

8.3子查询中使用索引


8.4使用普通索引

8.5使用复合索引

这个是回表查询还是覆盖查询呢?
回表查询
这个查询用到了创建的复合索引
复合索引属于**二级索引(非主键索引):**存储的是 "索引字段值 + 主键值"(而不是整行数据)
- 找到对应的主键值;
- 用主键值去主键索引(聚簇索引)中查询整行数据(这个步骤就是 "回表查询")。

场景3:部分覆盖查询
执行计划:Extra: Using where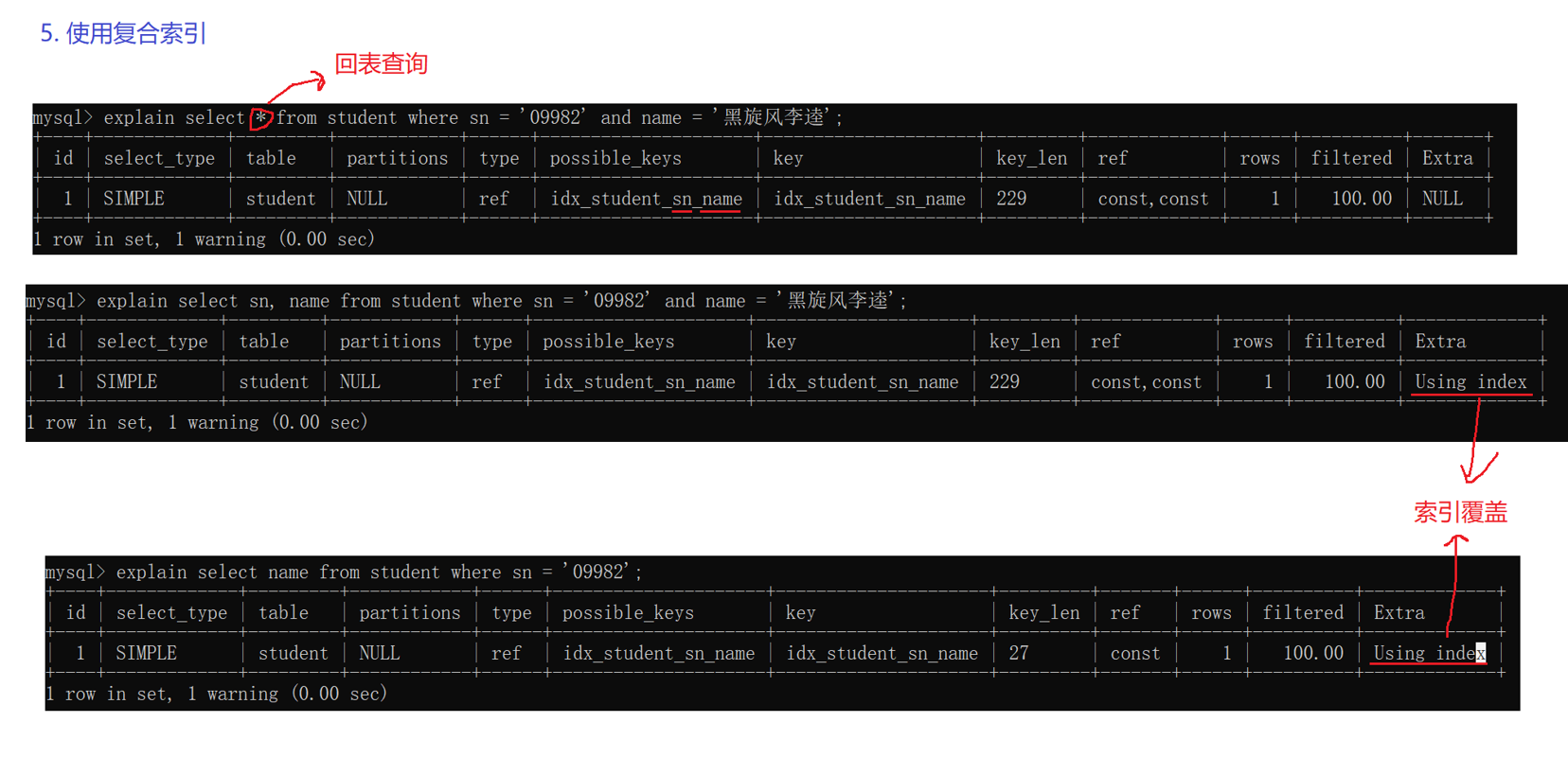
情况一:查的数据不在索引中:
-
⚠️ 部分列在索引中(name, age)
-
⚠️ 但email不在索引中,仍需回表
-
⚠️ 不是完全覆盖查询
情况二:查的数据在索引中:
-
⚠️ 部分列在索引中(name, age)
-
⚠️ 但email在索引中,不需回表
-
⚠️ 是完全覆盖查询

先给大家进行简单讲解后续更新更详细