TL;DR
- 场景:在 Elasticsearch 7.3 中用查询 DSL 做全文检索,而不是靠 Kibana 点选和简单关键字搜索。
- 结论:区分 match、match_phrase、query_string、multi_match 的匹配边界和分词语义,是中文搜索是否"搜得到"的关键。
- 产出:一套可直接复制的 DSL 示例与排错思路,覆盖中文分词、逻辑查询、多字段匹配和常见"查不到数据"的问题定位。

版本矩阵
| Elasticsearch 版本 | 已验证说明 |
|---|---|
| 7.3 | 是全文示例基于 7.3 官方 DSL 文档与实际集群验证,语法与截图一一对应。 |
| 7.4--7.17 | 部分查询 DSL 语法整体兼容,match、match_phrase、query_string、multi_match 用法基本一致,个别参数以官方文档为准。 |
官方地址
shell
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/query-dsl.htmlElasticsearch提供了基于JSON的完整查询DSL(Domain Specific Language 特定域语言)来定义查询,将查询 DSL 视为查询AST(抽象语法树),它由两种子句组成:
- 叶子查询句 叶子查询子句 在特定域中寻找特定的值,如 match、term、range 查询
- 复合查询子句 复合查询子句包装其他叶子查询或复合查询,并用于以逻辑方式组合多个查询(例如 bool或dis_max查询),或更改其行为(如 constant_score 查询) 我们在使用Elasticsearch的时候,避免不使用DSL语句去查询,就像使用关系型数据库的时候要学会使用SQL一样。
查询所有
示例
shell
# 查询所有数据
POST /wzkicu-index/_search
{
"query":{
"match_all": {}
}
}- query 代表查询的对象
- match_all 代表查询所有
执行后,结果如下: 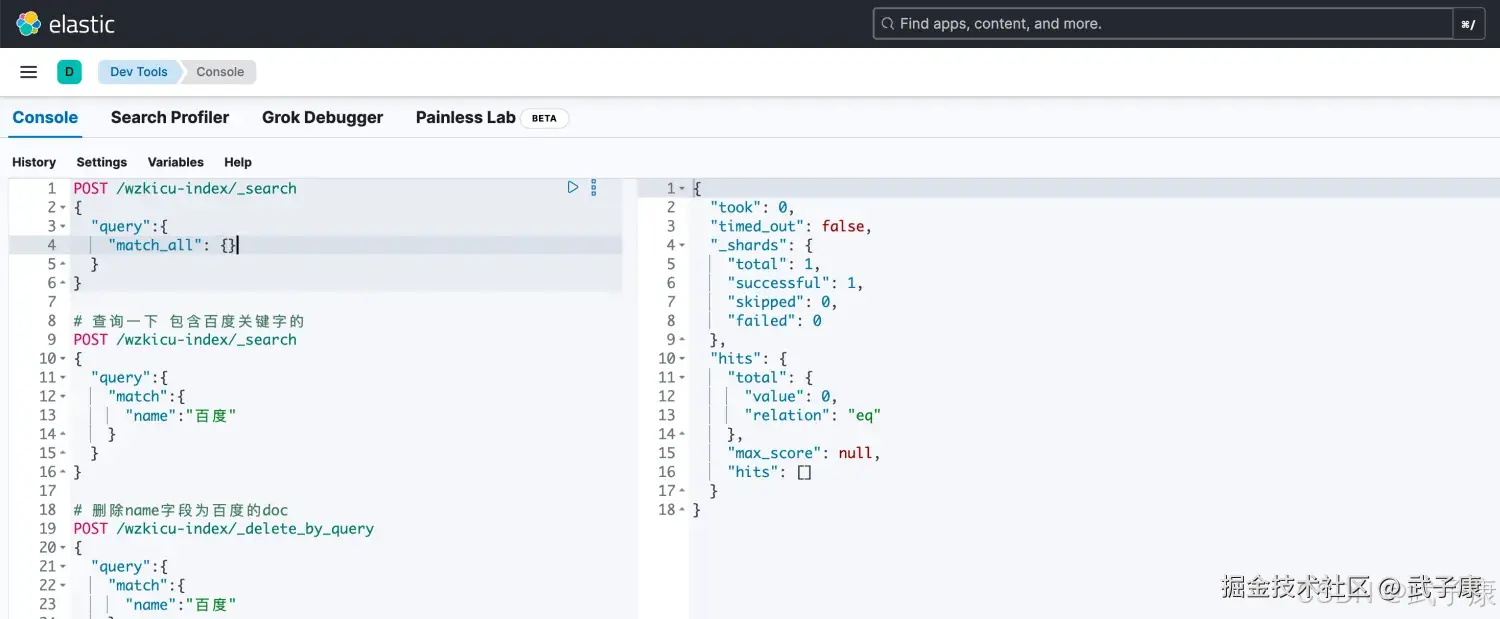 结果中:
结果中:
- took 查询花费时间,单位是毫秒
- time_out 是否超时
- _shards 分片信息
- hits 搜索结果总览对象
- total 搜索到的总数
- max_score 所有结果中文档得分的最高分
- _index 索引库
- _type 文档类型
- _id 文档id
- _score 文档得分
- _source 文档的数据源
全文检索(full-text query)
全文搜索能够搜索已分析的文本字段,如电子邮件正文、商品描述,使用索引期间应用于字段的同一分词处理查询字符串,全文搜索的分类很多,有如下的这么几种。
匹配搜索(match query)
全文查询的标准查询,查询条件比较宽松:
- 需要指定字段名
- 输入文本会进行分词,比如hello world,会拆分成 hello 和 world,然后进行匹配,如果字段内容中包含hello或者world,name就会被查询出来。也就是说match是一个部分匹配的模糊查询。
match queries 接收 text/numerics/dates,对它们进行分词分析,再组织成一个boolean查询,可通过operator指定bool组合操作(or、and、默认是or)。
假设一个案例,目前索引库中,有两部手机,一台电视: 先新增索引库:
shell
# 创建索引
PUT /wzk-property
{
"settings": {},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword"
},
"price": {
"type": "float"
}
}
}
}执行的结果如下图所示: 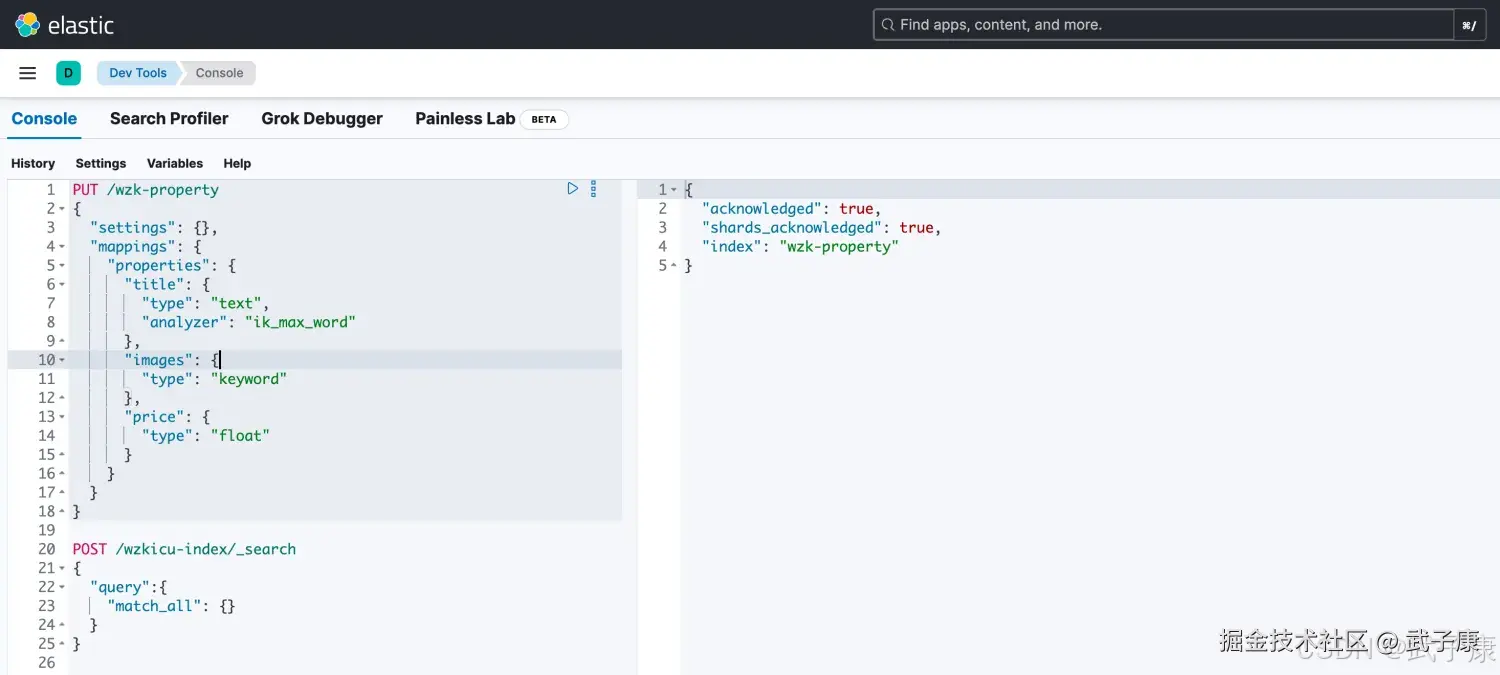 接着我们写入一些数据进去:
接着我们写入一些数据进去:
shell
# 添加数据1
POST /wzk-property/_doc/
{
"title": "小米电视4A",
"images": "https://profile-avatar.csdnimg.cn/755ff10be62f4e7081bc36028fa9eafe_w776341482.jpg!1",
"price": 4288
}
# 添加数据2
POST /wzk-property/_doc/
{
"title": "小米手机",
"images": "https://profile-avatar.csdnimg.cn/755ff10be62f4e7081bc36028fa9eafe_w776341482.jpg!1",
"price": 2699
}
# 添加数据3
POST /wzk-property/_doc/
{
"title": "华为手机",
"images": "https://profile-avatar.csdnimg.cn/755ff10be62f4e7081bc36028fa9eafe_w776341482.jpg!1",
"price": 5699
}执行结果如下图所示:  我们进行or关系的match搜索,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系:
我们进行or关系的match搜索,会把查询条件进行分词,然后进行查询,多个词条之间是or的关系:
shell
# match 分词匹配
POST /wzk-property/_search
{
"query":{
"match":{
"title":"小米电视4A"
}
}
}执行结果如下图所示: 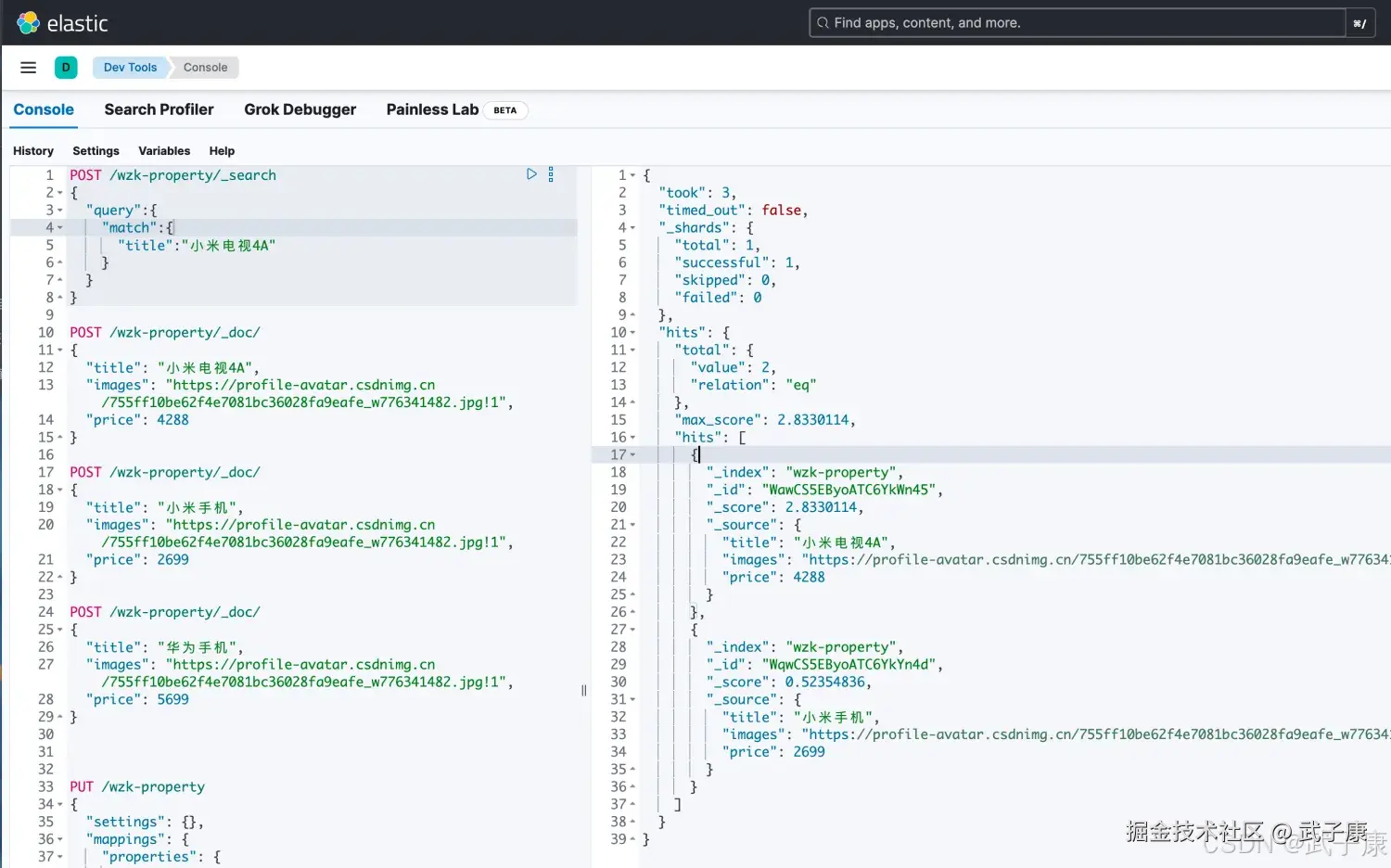 我们可以看到,不仅查到了小米电视、还查询到了小米手机。这不是我们要的结果。此时我们需要使用 and 的方式来进行精确的查找:
我们可以看到,不仅查到了小米电视、还查询到了小米手机。这不是我们要的结果。此时我们需要使用 and 的方式来进行精确的查找:
shell
# match 分词匹配 title字段 同时 分词后的每个词 都要匹配到才可以(and)
POST /wzk-property/_search
{"query":
{
"match": {
"title":
{
"query": "小米电视4A",
"operator": "and"
}
}
}
}执行结果如下,可以看到已经精准匹配到了: 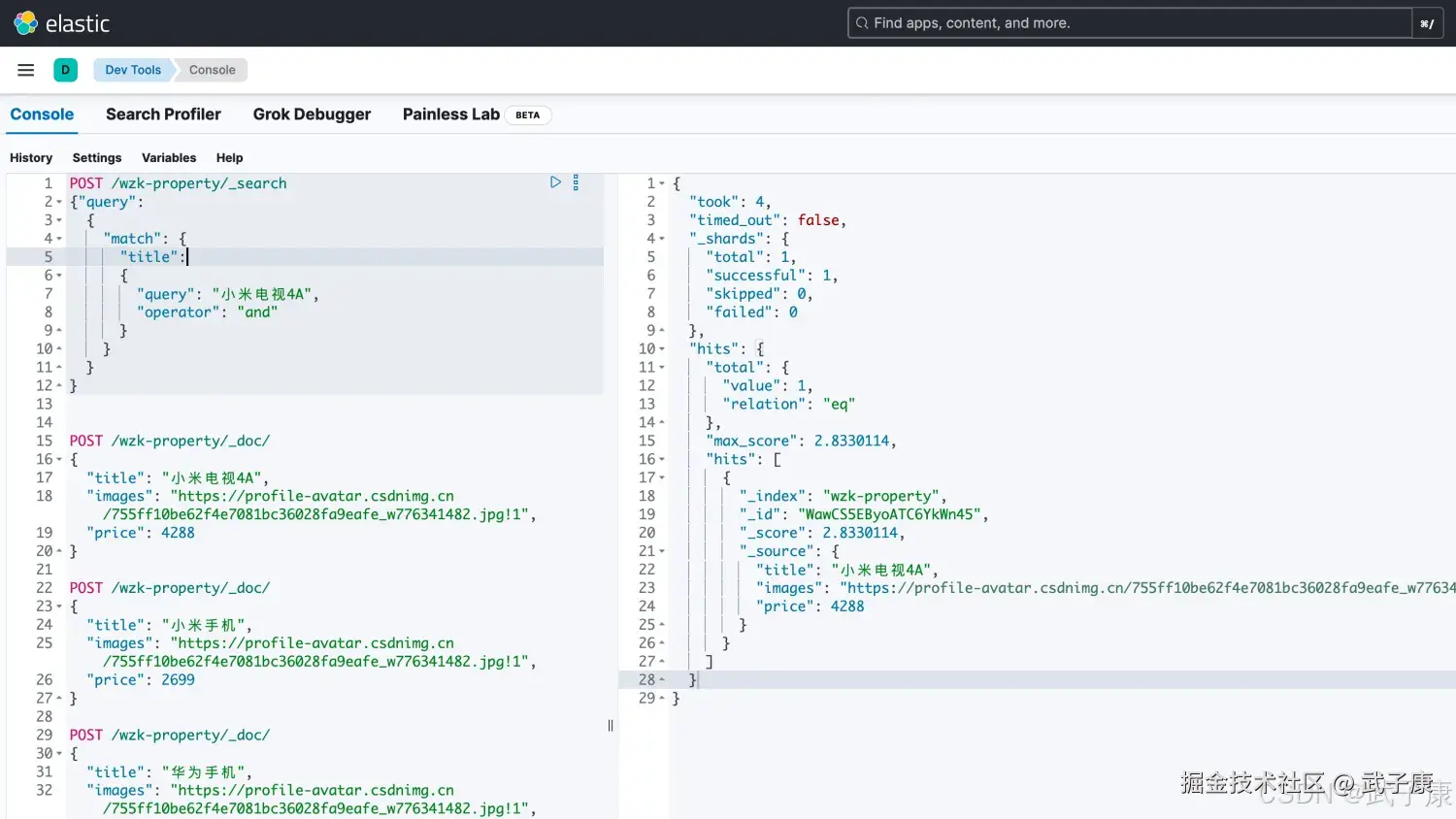
短语搜索(match phrase query)
match_query是分词的,text也是分词的,match_phrase的分词结果必须在text字段中都包含,而且顺序必须相同,而且必须是连续的:
shell
# 分词匹配但考虑顺序
# match是不考虑分词出现的顺序
# match_phrase 将遵循分词的出现顺序才进行匹配
POST /wzk-property/_search
{
"query": {
"match_phrase": {
"title": "小米电视"
}
}
}执行结果如下图所示: 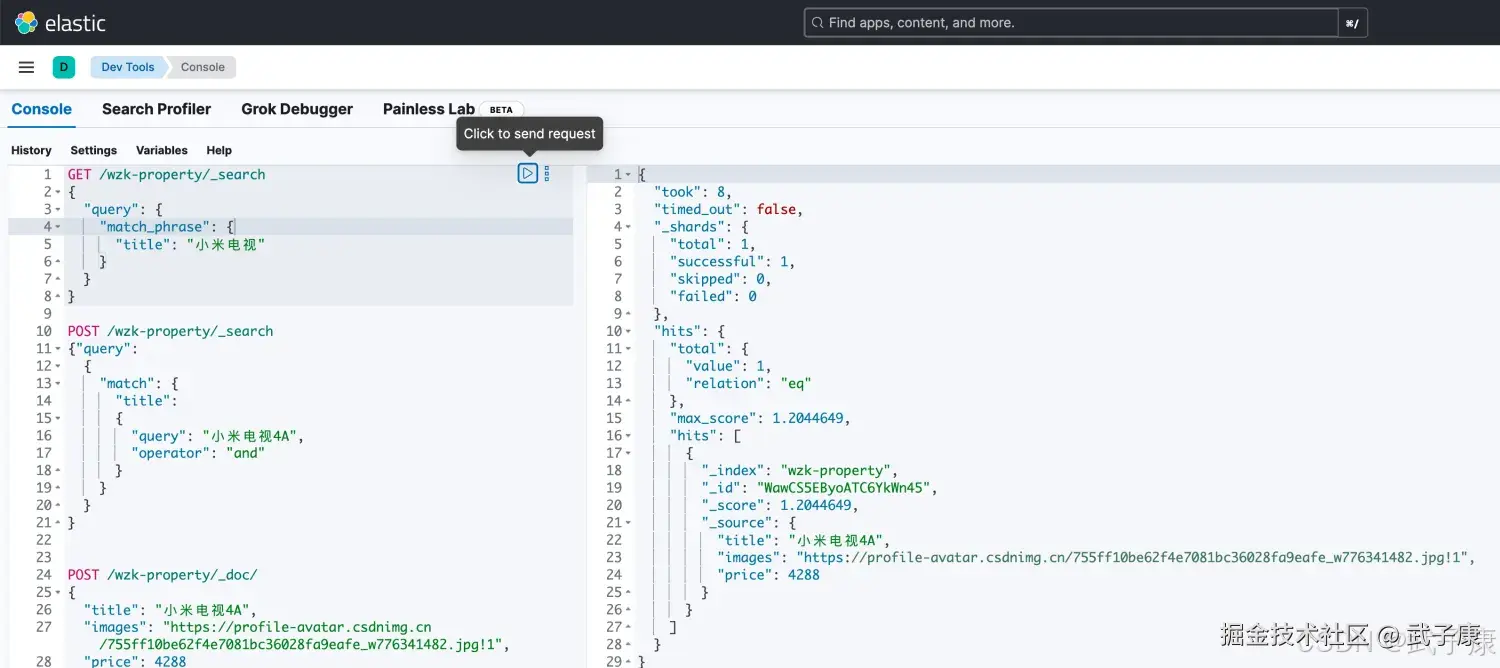
shell
# match_phrase 分伺后:1电视 2小米
# 因为条目中 小米电视的出现不是 1、2,所以没有匹配到
POST /wzk-property/_search
{
"query": {
"match_phrase": {
"title": "电视小米"
}
}
}执行结果如下图所示: 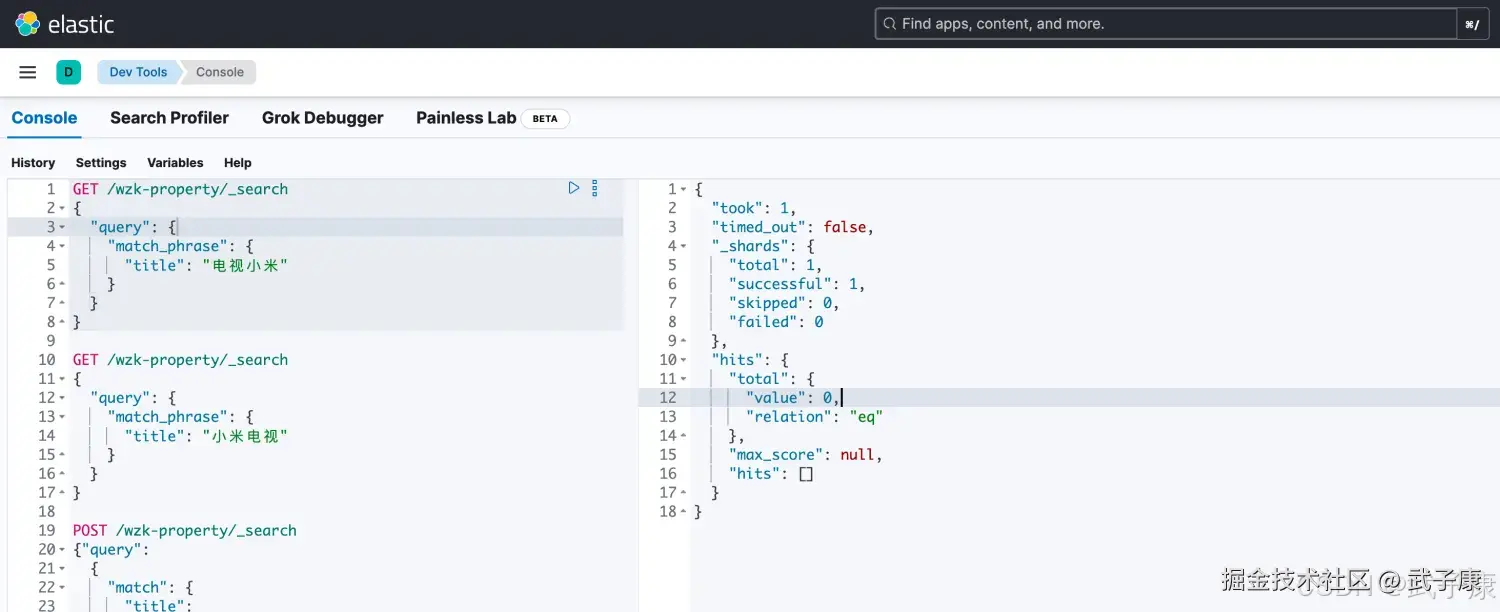
shell
# match_phrase 分词 1是小米 2是4A
# 但是由于 原:小米电视4A,对比中没有严格按照1、2的顺序
# 所以没有结果
POST /wzk-property/_search
{
"query": {
"match_phrase": {
"title": "小米4A"
}
}
}执行结果如下图所示: 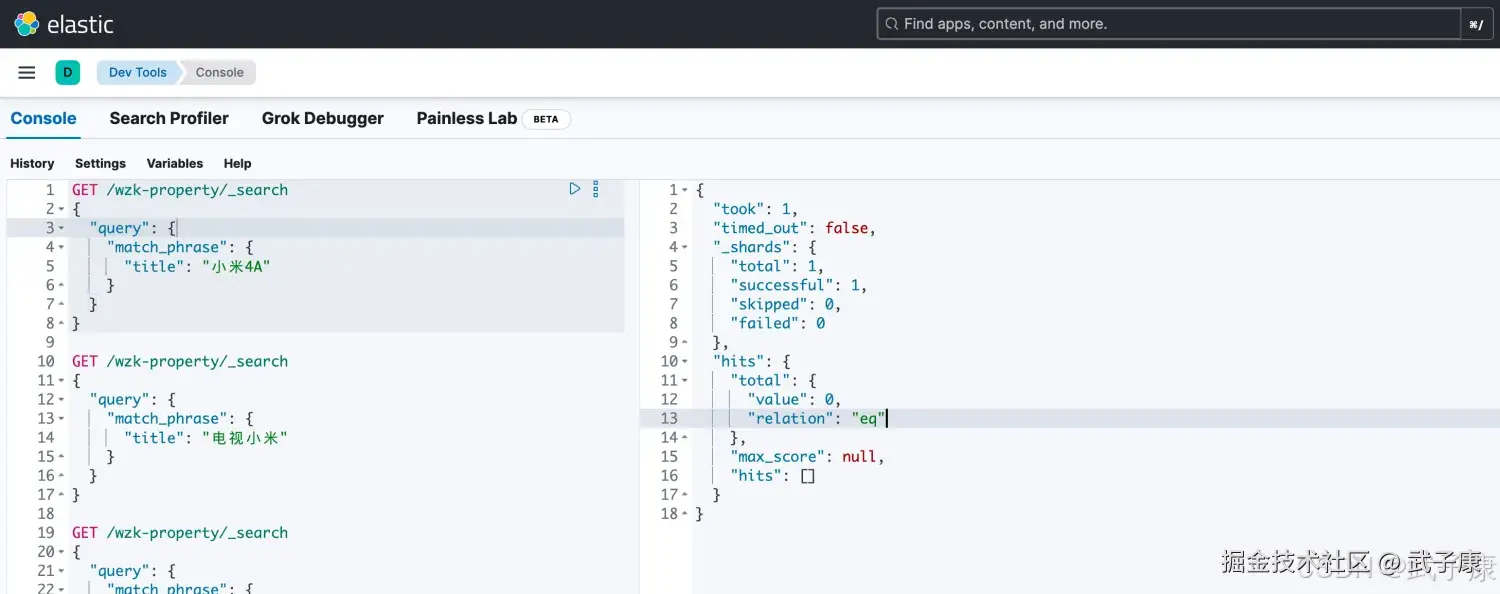 但是对于刚才的结果,可能我们希望使用 小米4A,可以按照 match_phrase 的顺序来查找到 小米电视4A,而不用严格遵守顺序,可以跳过几个词:
但是对于刚才的结果,可能我们希望使用 小米4A,可以按照 match_phrase 的顺序来查找到 小米电视4A,而不用严格遵守顺序,可以跳过几个词:
shell
# 通过 slop 可以跳过一个词 来让 match_phrase 匹配到顺序的结果
POST /wzk-property/_search
{
"query": {
"match_phrase": {
"title": {
"query": "小米4A",
"slop": 1
}
}
}
}query_string 查询
该查询与match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。 Query String Query提供了无需指定某字段而对文档全文进行匹配查询的一个高级查询,同时可以指定在哪些字段上进行匹配。
shell
# 广泛查询 所有字段中查找 2699
POST /wzk-property/_search
{
"query": {
"query_string": {
"query": "2699"
}
}
}执行结果如下图所示: 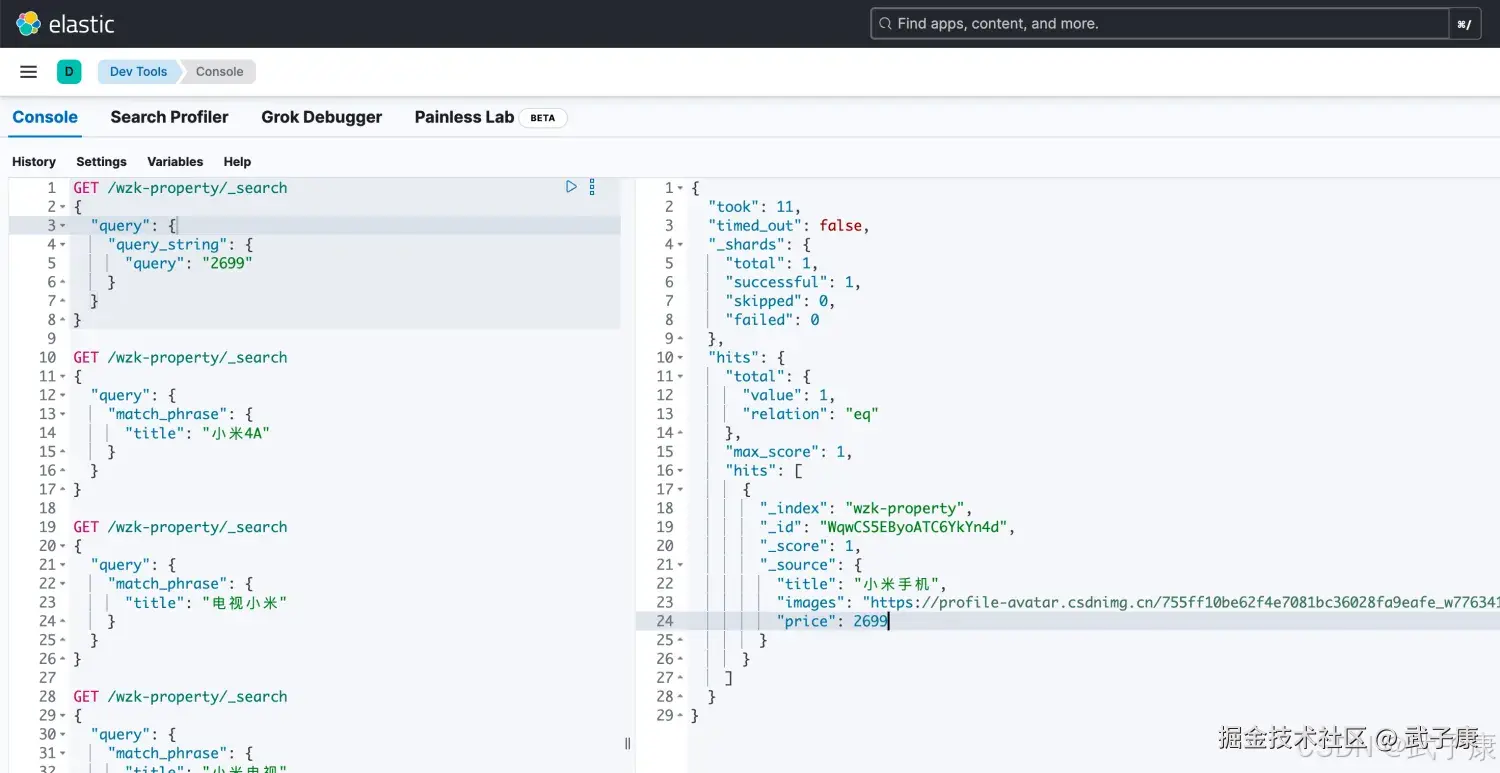
shell
# 广泛查找 但是你希望从这个default_field字段中查找
POST /wzk-property/_search
{
"query": {
"query_string": {
"query": "2699",
"default_field": "title"
}
}
}执行结果如下图所示: 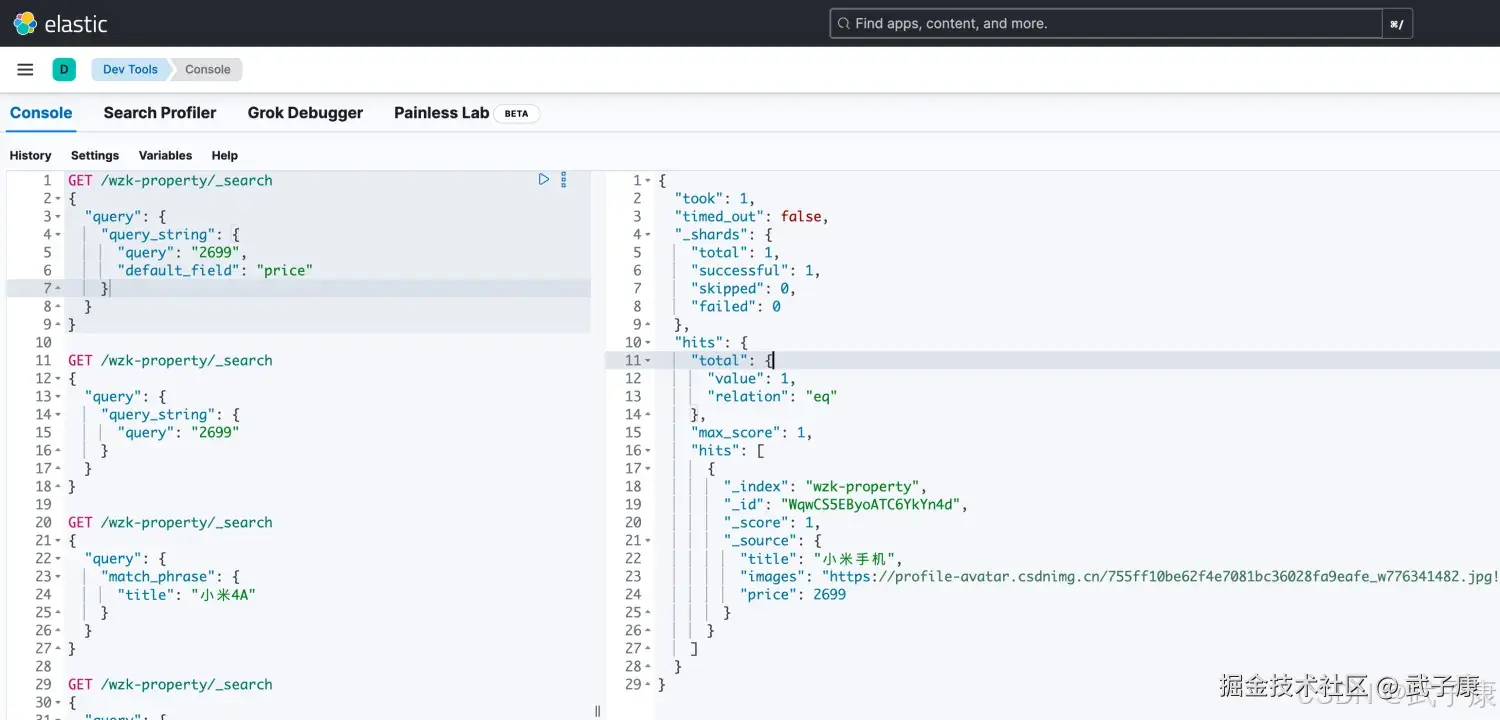
shell
# 逻辑查询 使用 OR 或者 AND
POST /wzk-property/_search
{
"query": {
"query_string": {
"query": "手机 OR 小米",
"default_field": "title"
}
}
}执行结果下图所示: 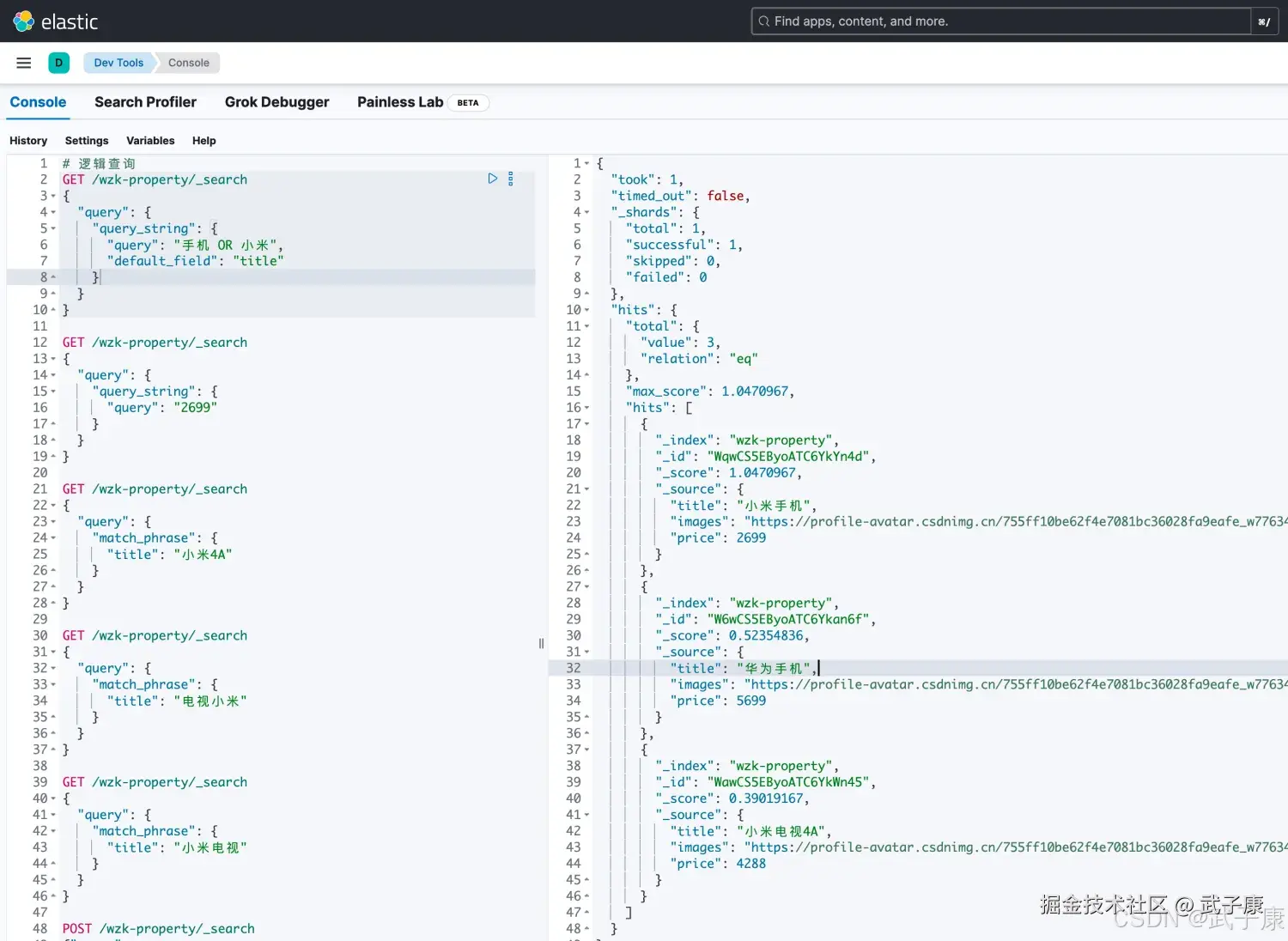
shell
# 逻辑查询 使用 OR 或者 AND
POST /wzk-property/_search
{
"query": {
"query_string": {
"query": "手机 AND 小米",
"default_field": "title"
}
}
}执行结果如下图所示: 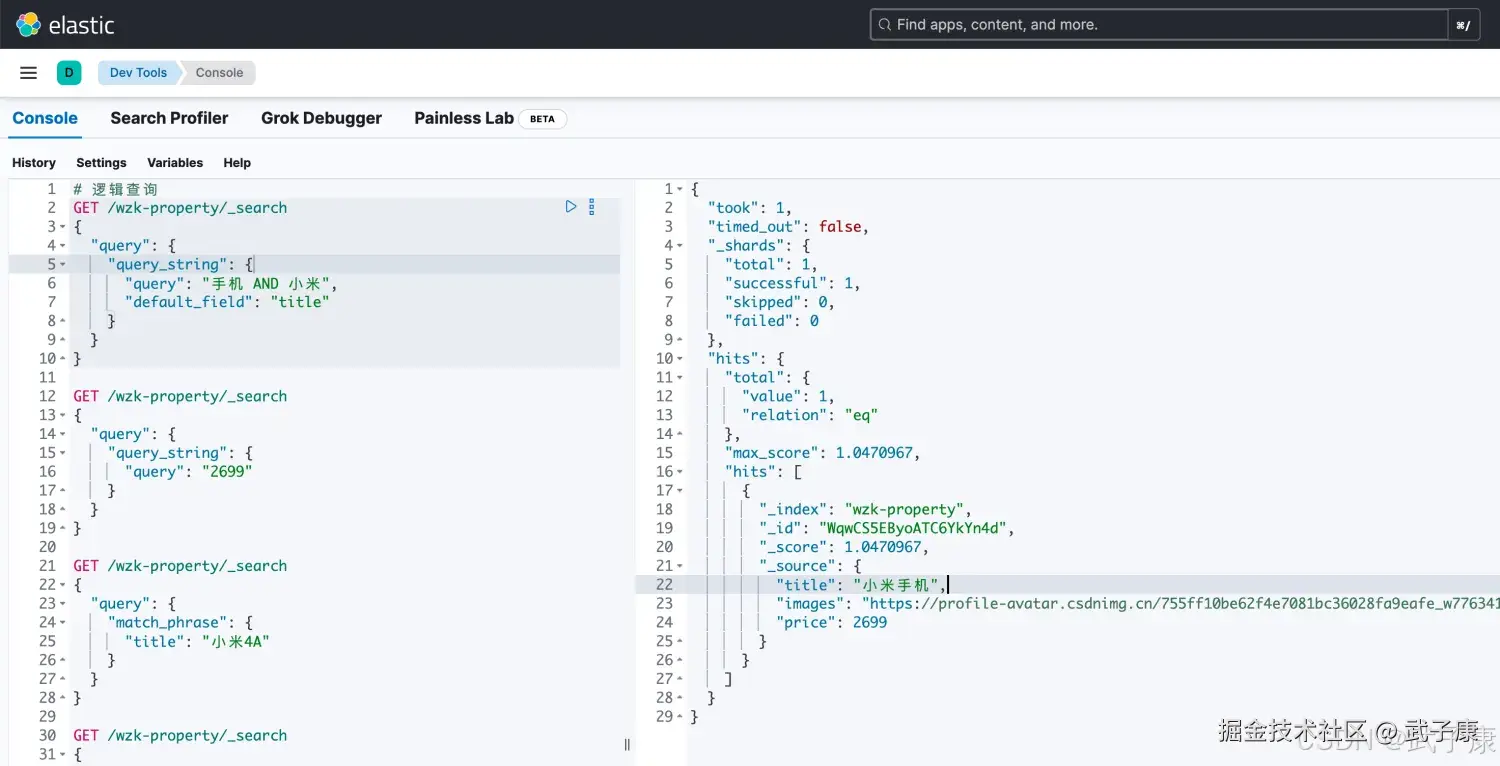
shell
# 模糊查询,表示 小米 这个词可以有1个词变动
# 比如:小明、米小 都是可以查询出来的
POST /wzk-property/_search
{
"query": {
"query_string": {
"query": "小米~1",
"default_field": "title"
}
}
}执行结果如下图所示: 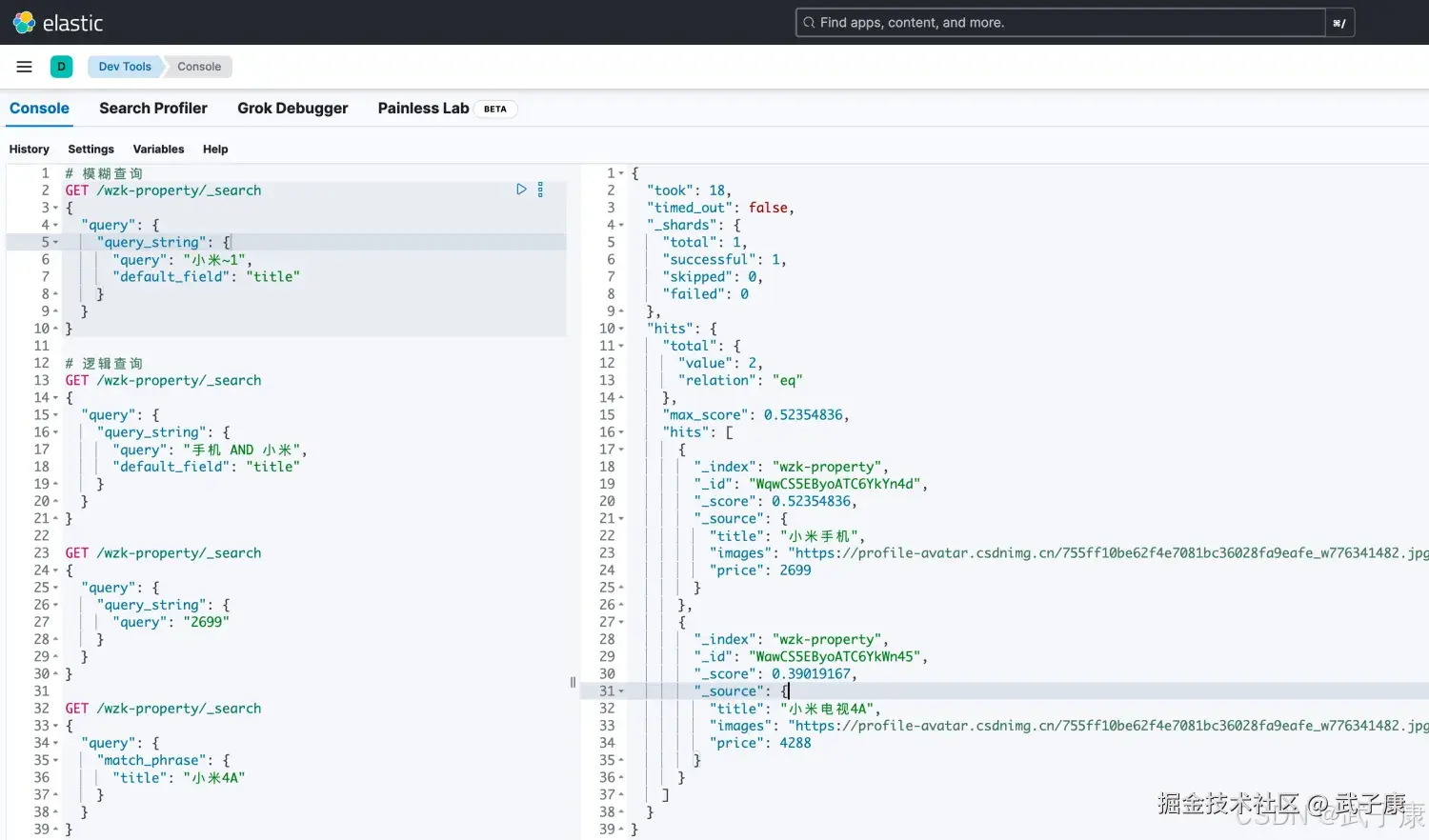
shell
# 模糊查询,表示 小米 这个词可以有1个词变动
# 比如:小明、米小 都是可以查询出来的
# 以此类推,如果是 小米~2 那就两个词都可以变动...
POST /wzk-property/_search
{
"query": {
"query_string": {
"query": "米小~1",
"default_field": "title"
}
}
}执行结果如下图所示: 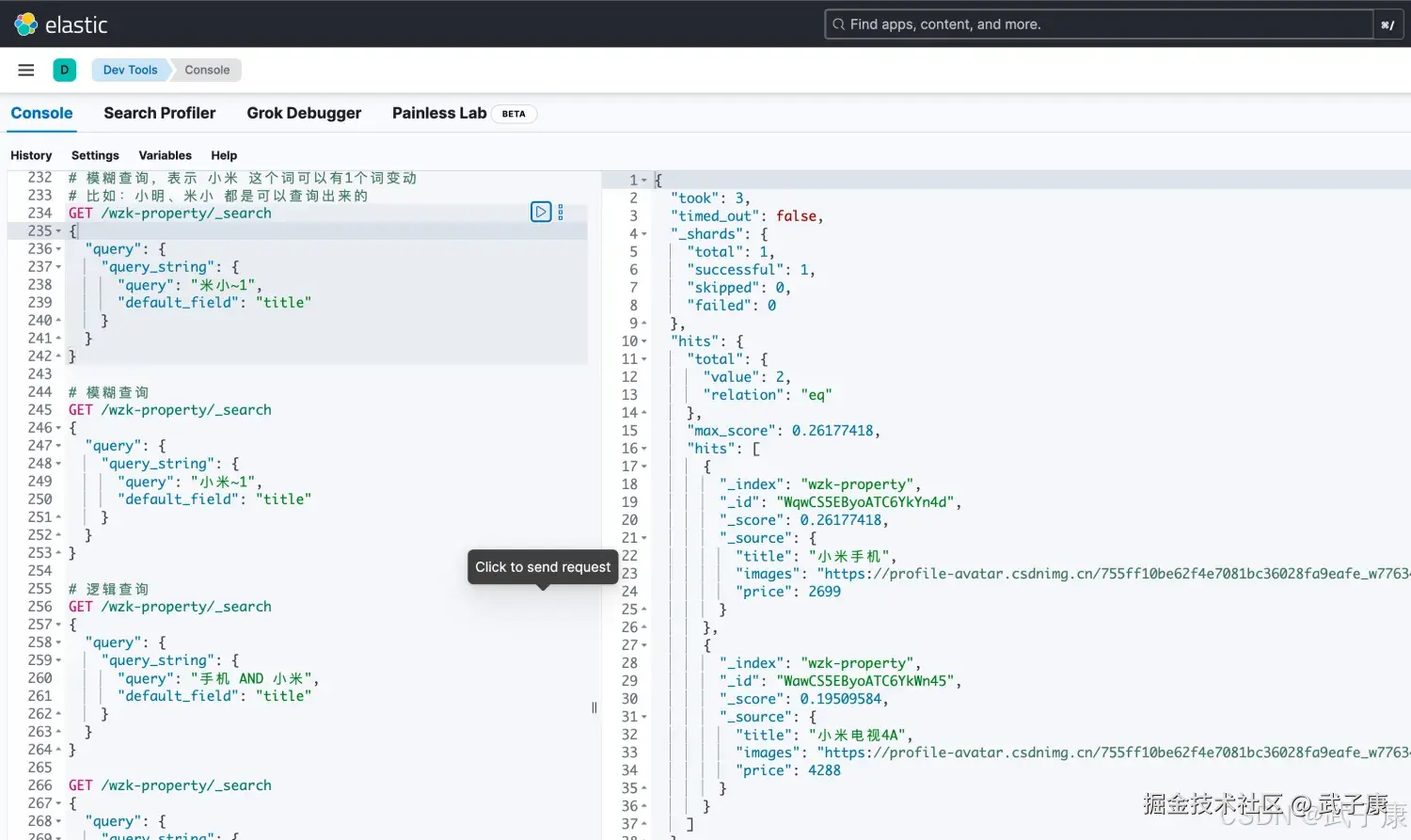
shell
# 多字段支持
POST /lagou-property/_search
{
"query": {
"query_string" : {
"query":"2699",
"fields": [ "title","price"]
}
}
}执行结果如下图所示: 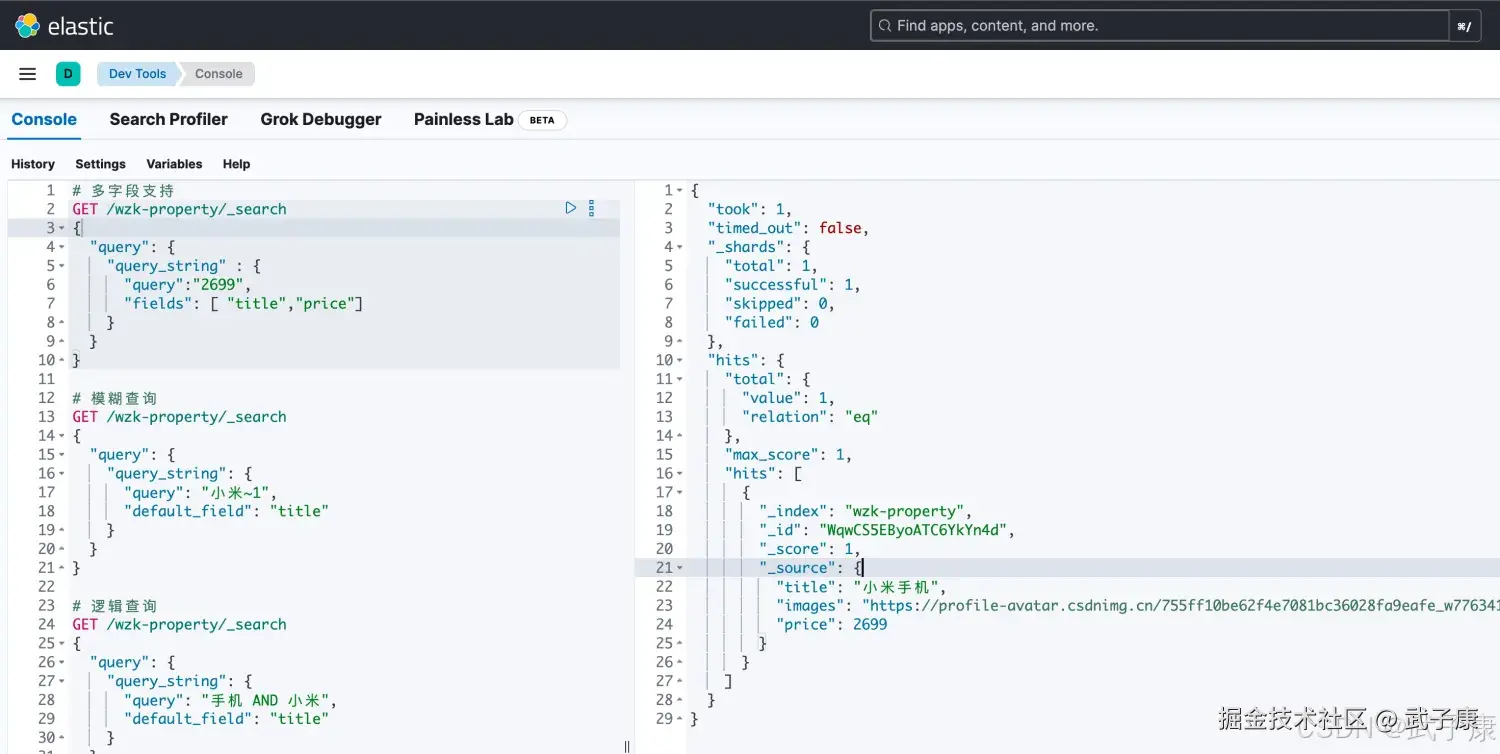
多字段匹配查询(multi match query)
如果你需要在多个字段上进行文本搜索,可用multi_match,multi_match在match的基础上支持对多个字段进行文本查询。
shell
# multi_match 是 match查询的一种扩展方式,用于在多个字段上进行查询
POST /wzk-property/_search
{
"query": {
"multi_match" : {
"query":"小米4A",
"fields": [ "title","images"]
}
}
}执行结果如下图所示: 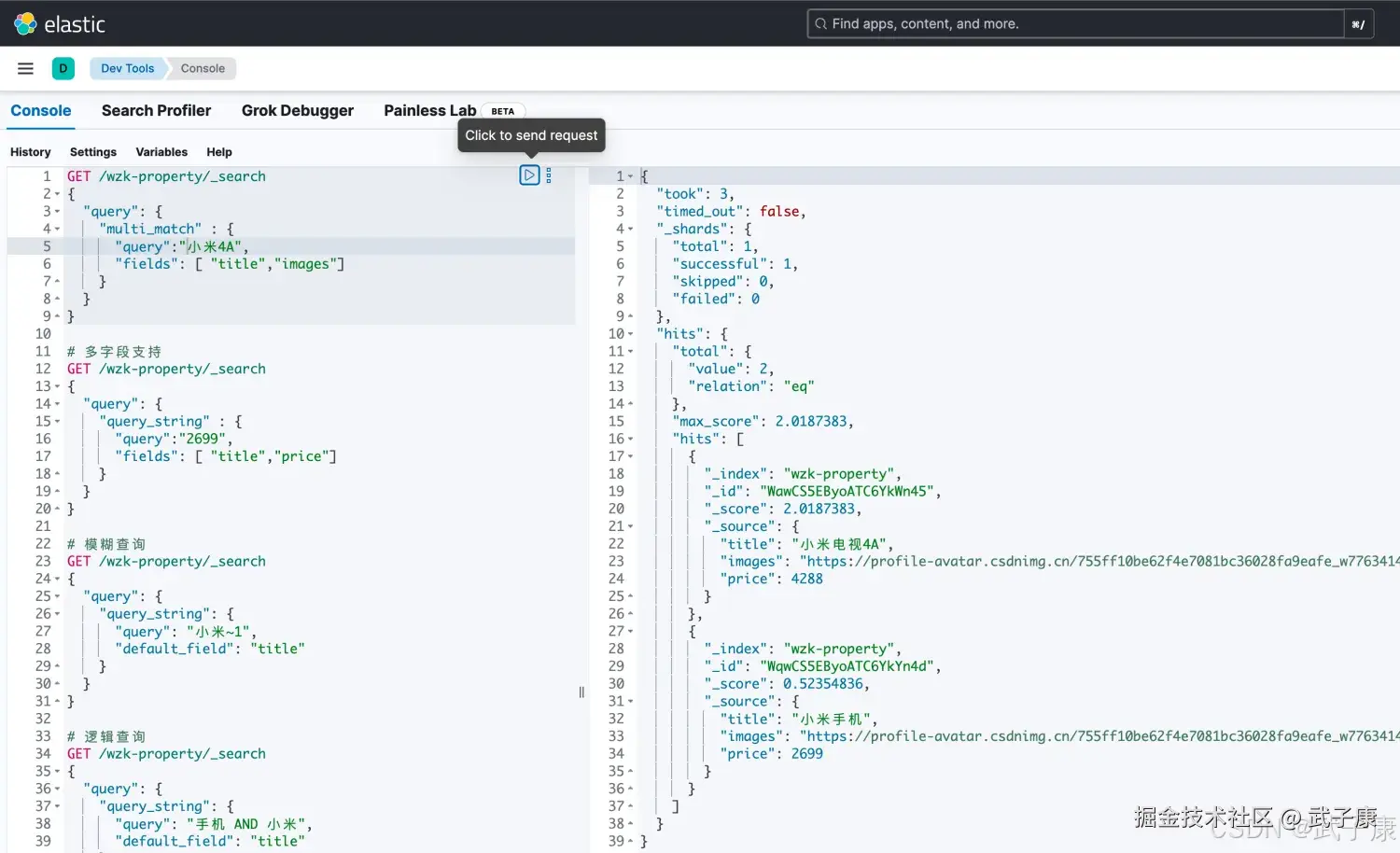
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 用 match 查询"小米电视4A",结果把"小米手机"也查出来 | match 默认 operator=OR,中文分词后任意一个词命中即算匹配 | 在 Kibana 中使用 _analyze 查看 title 分词结果,确认分词粒度 | 在 match 中显式设置 "operator": "and",或改用 keyword/精确匹配字段承载商品名 |
| match_phrase 查不到预期文档(如"电视小米""小米4A"均无结果) | match_phrase 要求分词顺序与位置连续,默认不允许跳词 | 用 _analyze 查看短语分词顺序,对比 _source.title 的实际分词顺序 | 使用 "slop": N 放宽位置约束,或改写查询短语与文案保持一致 |
| query_string 报解析错误或查不到数据 | query_string 语法较复杂,逻辑运算符、特殊字符未转义,或 default_field 不含目标内容 | 查看 Kibana 报错信息,逐步简化 query 字符串,只保留单词验证 | 避免直接透传用户输入,必要时对 `+ - && |
| 使用 query_string 模糊查询"小米~1"但结果过多或过少 | 模糊匹配基于编辑距离,且受 analyzer 影响,并非"看起来相似就一定命中" | 对同一单词分别用 _analyze 和 query_string 测试,观察实际命中词条 | 明确业务接受的模糊程度,合理设置 ~1/~2,必要时改为前缀/通配符或拼音索引等更明确方案 |
| multi_match 跨字段查询命中不符合预期 | 多字段中字段类型和分词方式不同,score 被某个字段主导,导致排序或命中偏移 | 查看 mapping 中各字段的 type/analyzer,并用单字段 match 对比效果 | 在 multi_match 中显式配置 fields 权重(如 "title^3"),或统一文本字段的 analyzer,避免 keyword 与 text 混用产生误解 |
| match_all 能查到文档,但任一全文查询都查不到 | 字段被映射为 keyword 或未被索引,全文查询打在错误字段上 | 用 mapping 接口确认字段 type 及 index 属性,检查查询 JSON 中的字段名拼写 | 将字段改为 text 或设置合适的多字段(text + keyword),并校正 DSL 中的字段名,重建索引后再次验证 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解