1、准备数据
我已经有了标注好的数据文件,当然也可以用标注工具生成数据,比如下文中的方法:https://blog.csdn.net/xulibo5828/article/details/154707998
- 我的原始数据目录结构:
python
datasets
├── images/
│ ├── class1/
│ │ ├──cls1-00001.jpg
│ │ ├──cls1-00002.jpg
│ │ ├──。。。
│ │ ├──cls1-00nnn.jpg
│ ├── class2/
│ │ ├──cls2-00001.jpg
│ │ ├──cls2-00002.jpg
│ │ ├──。。。
│ │ ├──cls2-00nnn.jpg
│ │ 。。。
│ ├── classn/
│ ├──clsn-00001.jpg
│ ├──clsn-00002.jpg
│ ├──。。。
│ ├──clsn-00nnn.jpg
├── labels/
│ ├── class1/
│ │ ├──cls1-00001.txt
│ │ ├──cls1-00002.txt
│ │ ├──。。。
│ │ ├──cls1-00nnn.txt
│ ├── class2/
│ │ ├──cls2-00001.txt
│ │ ├──cls2-00002.txt
│ │ ├──。。。
│ │ ├──cls2-00nnn.txt
│ │ 。。。
│ ├── classn/
│ ├──clsn-00001.txt
│ ├──clsn-00002.txt
│ ├──。。。
│ ├──clsn-00nnn.txt
├── classes.txt
images和labels目录下分别保存有图片和标签,按照不同的分类存放在class1------classn目录下,classes.txt是所有分类的名称明细。
- 标注文件的格式
YOLO对目标检测的标注文件格式要求如下:
https://blog.csdn.net/xulibo5828/article/details/145657008
python
class x_center y_center width height其中 class 是目标的类别索引(从 0 开始),x_center、y_center 是边界框中心点相对于图像宽度和高度的归一化坐标,width 和 height 是边界框宽度和高度相对于图像宽度和高度的归一化值。
我的原始数据中所有txt文件都是按照这个格式要求标注的。
- 用于YOLO训练的目录结构
预期的YOLO项目下训练文件的目录结构是这样的:
python
datasets
├── images/
│ ├── train/
│ ├── var/
│ ├── test/
├── labels/
│ ├── train/
│ ├── valr/
│ ├── test/
├── dataset.yamlimags目录下保存图片,按照用途的不同又分为train(训练集)、var(验证集)和test(测试集),labels目录下保存与images目录下图片文件的同名txt文件,dataset.yaml是训练配置文件。
运行脚本,将原始数据划分数据集,并自动生成dataset.yaml文件:
python
import os
import shutil
import random
from pathlib import Path
# 配置参数
RAW_DATA_DIR = "dataset/generated_dataset" # 原始数据根目录
TARGET_DATA_DIR = "datasets_yolo" # 转换后数据根目录
TRAIN_RATIO = 0.7 # 训练集比例
VAL_RATIO = 0.2 # 验证集比例
TEST_RATIO = 0.1 # 测试集比例
def create_dirs():
"""创建目标目录结构"""
dirs = [
f"{TARGET_DATA_DIR}/images/train",
f"{TARGET_DATA_DIR}/images/val",
f"{TARGET_DATA_DIR}/images/test",
f"{TARGET_DATA_DIR}/labels/train",
f"{TARGET_DATA_DIR}/labels/val",
f"{TARGET_DATA_DIR}/labels/test"
]
for dir in dirs:
Path(dir).mkdir(parents=True, exist_ok=True)
def load_classes():
"""从classes.txt加载类别信息"""
classes_path = os.path.join(RAW_DATA_DIR, "classes.txt")
with open(classes_path, "r", encoding="utf-8") as f:
classes = [line.strip() for line in f if line.strip()]
return classes
def split_data_per_class(class_name):
"""按类别划分数据"""
# 获取该类别的所有图片文件
img_dir = os.path.join(RAW_DATA_DIR, "images", class_name)
img_files = [f for f in os.listdir(img_dir) if f.endswith(('.jpg', '.jpeg', '.png'))]
random.shuffle(img_files)
# 划分数据
total = len(img_files)
train_split = int(total * TRAIN_RATIO)
val_split = int(total * (TRAIN_RATIO + VAL_RATIO))
train_files = img_files[:train_split]
val_files = img_files[train_split:val_split]
test_files = img_files[val_split:]
return train_files, val_files, test_files
def copy_files(class_name, file_list, subset):
"""复制图片和标签文件到目标目录"""
for img_file in file_list:
# 复制图片
src_img = os.path.join(RAW_DATA_DIR, "images", class_name, img_file)
dst_img = os.path.join(TARGET_DATA_DIR, "images", subset, img_file)
shutil.copy2(src_img, dst_img)
# 复制标签
label_file = os.path.splitext(img_file)[0] + ".txt"
src_label = os.path.join(RAW_DATA_DIR, "labels", class_name, label_file)
dst_label = os.path.join(TARGET_DATA_DIR, "labels", subset, label_file)
if os.path.exists(src_label):
shutil.copy2(src_label, dst_label)
def generate_dataset_yaml(classes):
"""生成dataset.yaml文件"""
yaml_content = f"""# YOLOv11 Dataset Configuration
path: {os.path.abspath(TARGET_DATA_DIR)} # 数据集根目录
train: images/train # 训练集图片路径
val: images/val # 验证集图片路径
test: images/test # 测试集图片路径
# 类别信息
nc: {len(classes)} # 类别数量
names: {classes} # 类别名称列表
"""
yaml_path = os.path.join(TARGET_DATA_DIR, "dataset.yaml")
with open(yaml_path, "w", encoding="utf-8") as f:
f.write(yaml_content)
def main():
# 初始化
random.seed(42) # 设置随机种子确保结果可复现
create_dirs()
classes = load_classes()
# 处理每个类别
for class_name in classes:
print(f"Processing class: {class_name}")
train_files, val_files, test_files = split_data_per_class(class_name)
# 复制文件
copy_files(class_name, train_files, "train")
copy_files(class_name, val_files, "val")
copy_files(class_name, test_files, "test")
# 生成配置文件
generate_dataset_yaml(classes)
print(f"数据转换完成!目标目录:{TARGET_DATA_DIR}")
if __name__ == "__main__":
main()2、训练
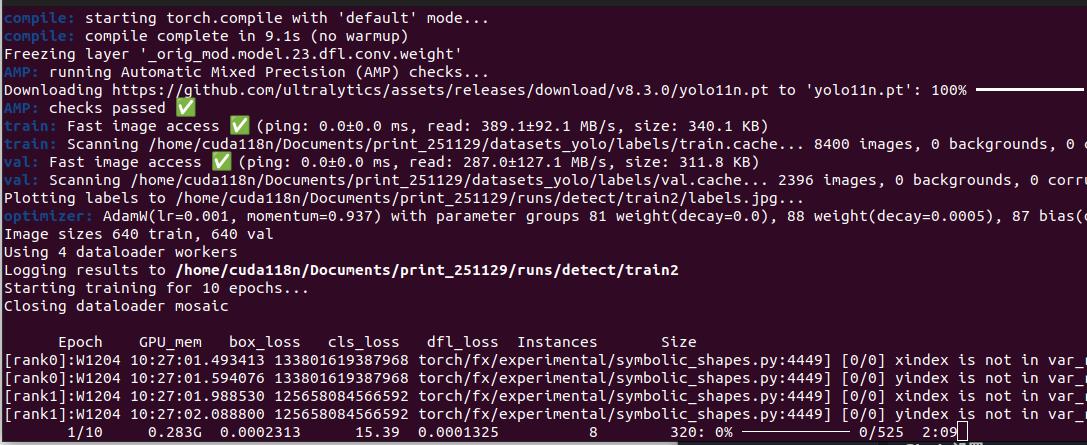
打开conda prompt,cd到datasets_yolo的上级目录下,激活创建好的YOLO虚拟环境,输入已下指令试运行:
python
yolo task=detect \
mode=train \
model=yolo11n.yaml \
data="datasets_yolo/dataset.yaml" \
epochs=10 \
imgsz=640 \
batch=16 \
device=0,1 \
workers=2 \命令解释:
task=detect:任务类型,实例分割 segment,目标检测 detect、分类 classify、姿态估计 pose
mode=train:模式,训练 train、推理 predict、验证 val、导出 export
model=yolo11n.yaml:使用的基础模型是 YOLOv11版本(yolo11n),但是不用它的预训练权重(从头训练),如果使用预训练权重,将该段指令改为:model=yolo11n.pt
model=yolo11n.pt:使用的基础模型是 YOLOv11 的(yolo11n)的预训练分割模型
data=dataset.yaml:指定数据集配置文件,包含训练集 / 验证集路径、类别信息等
epochs=10:训练总轮次为 10 轮(先小批次试运行)
imgsz=640:输入图像的尺寸统一调整为 640x640 像素
batch=16:每批处理 16 张图像
device=0,1:指定使用第 0 号 和第 1 号 GPU 进行训练(若为 cpu 则使用 CPU)
workers=2:使用2个并行进程训练,提高效率
第一次训练,会自动下载模型数据,需要连接科学网。当小批次运行成功后,修改和优化训练参数,进行正式训练。