作为一名开发者,背单词时总觉得市面上的 App 要么广告多,要么功能臃肿。我就想:能不能用最纯粹的前端技术,写一个轻量级、零依赖、且功能强大的背单词应用?
于是,就有了这个 "CET-6 单词斩" 项目。
它不需要后端服务器,不需要复杂的构建流程(Webpack/Vite),仅仅是一个 index.html 文件,双击即用。但它却包含了:
-
🚀 SMART 记忆算法(基于艾宾浩斯遗忘曲线)
-
🎧 听写模式(调用原生 Web Speech API)
-
💾 本地持久化(多用户进度保存)
-
🎨 完美响应式布局(手写 CSS + 仿 Tailwind 风格)
-
📂 智能数据导入(支持解析 GitHub 开源词库)
这篇文章将复盘整个开发过程,重点分享开发中遇到的**"深坑"**以及解决方案。
一、 技术选型:极简主义的胜利
为了保证"单文件"的便携性,我放弃了 npm install 的全家桶模式,采用了最原始但有效的 CDN 引入方式:
-
React 18 + ReactDOM 18 :通过 UMD 引入,利用
Babel Standalone在浏览器端实时编译 JSX。虽然性能不如预编译,但对于这种轻量级工具,灵活性是第一位的。 -
CSS (仿 Tailwind) :为了减少网络请求,我没有引入庞大的 Tailwind CSS 库,而是手动写了一套 CSS Variables (
:root) 和 utility classes,实现了类似 Tailwind 的开发体验,但体积几乎为零。 -
Web Speech API:浏览器的原生 TTS (Text-to-Speech) 引擎,无需下载音频包,离线也能发音。
-
LocalStorage:浏览器的本地存储,充当我们的"NoSQL 数据库"。
二、 核心功能与实现难点
1. 核心架构:MVC 的变体
由于没有 Redux/MobX,我设计了一个简单的单例对象 dataMgr 来管理所有数据流,配合 React 的组件化渲染。
-
dataMgr:负责数据的 CRUD、算法计算、LocalStorage 读写。 -
router:一个简单的状态机,控制currentView来切换"计划"、"背词"、"听写"等页面。 -
ui:负责弹窗、Toast 等全局交互。
2. 难点一:SRS 记忆算法的实现
单纯的"认识/不认识"是不够的。为了达到科学记忆的效果,我参考了 SuperMemo 2 算法的简化版:
JavaScript
process(id, quality) { // quality: 0=不认识, 1=认识
const w = this.db.find(x => x.id === id);
if (!w) return;
// 状态机流转
if (w.status === 0) {
this.config.count++; // 今日新词计数
}
w.status = 1; // 标记为学习中
if (quality === 0) {
// 😭 不认识:惩罚机制
w.interval = 1; // 重置间隔为 1 天
w.isError = true; // 自动加入错题本
w.nextReview = Date.now() + 60000; // 逻辑上 1 分钟后重现
} else {
// 😎 认识:奖励机制(指数增长)
// 间隔翻倍:1天 -> 2天 -> 4天 -> 8天...
w.interval = w.interval === 0 ? 1 : w.interval * 2;
w.nextReview = Date.now() + (w.interval * 86400000);
// 熟练度高了自动移出错题本
if (w.interval > 5) w.isError = false;
}
this.save();
}思考: 这种设计让单词复习不再是线性的,而是根据用户的掌握程度动态调整,大大提高了效率。
3. 难点二:第三方数据的"智能清洗"(遇到的最大坑)
在开发"导入 GitHub 词库"功能时,我遇到了严重的兼容性问题。
问题描述: 我期望的数据格式是 { word: "...", mean: "..." },但用户提供的开源词库格式五花八门,比如:
JavaScript
// 实际遇到的格式
{
"word": "estimate",
"meanings": [ "v. 估计", "n. 评价" ] // 这是一个数组!且字段名是 meanings
}导致的结果是,页面上大量单词显示为 "暂无释义"。
解决方案: 我在导入层增加了一个 Adapter(适配器)模式 的 transform 函数,进行防御性编程:
JavaScript
transform(list) {
return list.map((item, i) => {
let mean = '暂无释义 (解析失败)';
// 1. 优先匹配数组格式
if (item.meanings && Array.isArray(item.meanings)) {
mean = item.meanings.join(';'); // 核心修复:数组转字符串
}
// 2. 兼容其他常见字段名
else if (item.translation) mean = item.translation;
else if (item.mean) mean = item.mean;
else if (item.definition) mean = item.definition;
return {
id: Date.now() + i,
word: item.word || item, // 甚至兼容纯字符串数组
mean: mean,
// ...其他初始化字段
};
});
}此外,为了解析用户直接粘贴的 const vocabulary = [...] 这种非标准 JSON 字符串,我使用了 new Function('return ' + json)() 这种黑魔法(仅限客户端本地使用),它比 JSON.parse 容错率更高,能直接执行 JS 代码片段获取数组。
4. 难点三:移动端布局的"跳动"问题
在 V8 版本发布前,我发现一个非常影响体验的 UI 问题:
-
现象:从"背单词"页面切换到"听写"页面时,内容区域的宽度会发生微小的抖动。
-
排查 :发现是因为不同页面的容器
padding设置不一致。有的页面是在外层容器加padding: 20px,有的是卡片自带margin。 -
解决:重构 CSS 布局策略。
-
去除容器 Padding :让主容器
main宽度占满。 -
统一卡片宽度 :强制所有
.card组件使用width: calc(100% - 16px)并配合margin: 8px auto。 -
这样无论页面内容如何,卡片永远距离屏幕边缘 8px,视觉体验如丝般顺滑。
-
三、 功能亮点:听写模块
为了强化记忆,我增加了一个听写模块。这里充分利用了浏览器的能力:
-
发音 :
speechSynthesis.speak()。这里有个坑,默认语速太快,我将其调整为rate = 0.9,更适合听写。 -
交互 :输入框绑定
onKeyDown事件监听 Enter 键。 -
反馈:
-
✅ 正确:输入框变绿,自动进入下一题。
-
❌ 错误:输入框变红,显示正确拼写,并自动调用
markError函数将该词加入错题本,实现了"背、听、复习"的闭环。
-
四、 部署与上线
项目写完只有一个 HTML 文件,怎么给朋友用? 我选择了 Netlify Drop。
-
把
index.html放入一个文件夹cet6-app。 -
打开 Netlify Drop 页面。
-
把文件夹拖进去。
-
3秒上线,自动生成 HTTPS 链接。
后续更新只需再次拖拽文件夹,这种体验对于静态应用来说简直完美。
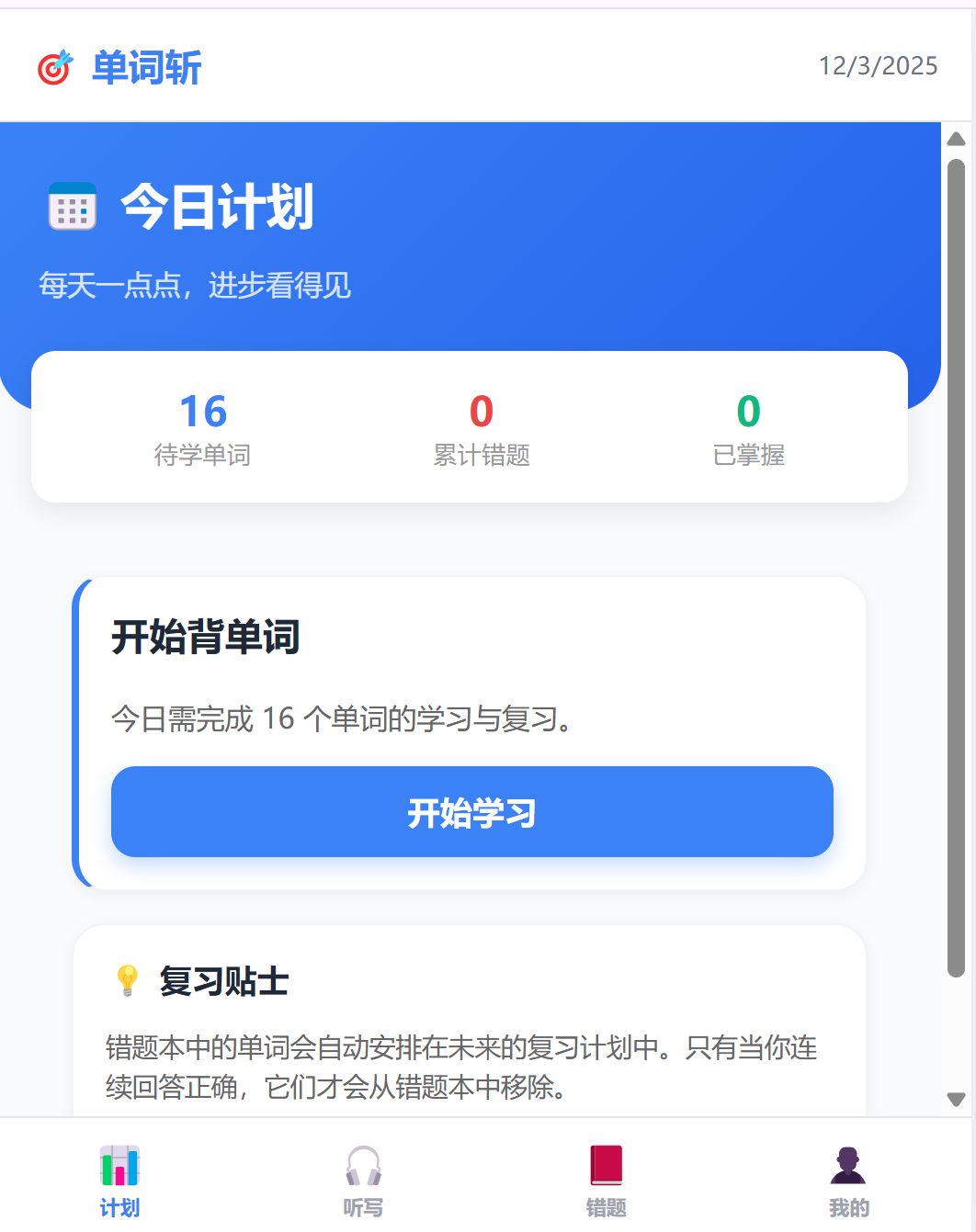
五、 总结
这个项目虽然代码量不大(约 500 行),但麻雀虽小五脏俱全。它涵盖了:
-
数据层:本地存储、数据清洗、结构适配。
-
逻辑层:SRS 算法、状态管理、路由控制。
-
视图层:响应式布局、交互反馈、动画效果。
通过手写这个项目,我深刻体会到了脱离框架(Create-React-App/Next.js)进行原生开发的乐趣。有时候,为了解决一个小需求,我们引入了太多的复杂性。回归基础,往往能带来意想不到的高效和掌控感。
词汇库:https://github.com/Thatgfsj/Typing-Shooter-English/blob/main/vocabulary.js