今日总结
- java随笔录------redis作为分布式锁,是如何实现的呢?
- AI随探录------智能输入法案例
- 代码随想录------分割回文串
目录
详细内容
java随笔录
redis作为分布式锁,是如何实现的呢?
-
答:分布式锁使用的场景:集群情况下的定时任务、抢单、幂等性场景(因为集群模式下,synized锁作为本地锁,无法锁住多个节点,因此用分布式锁来解决)
Redis实现分布式锁主要利用Redis的setnx命令。
分布式锁的新机制:当一个线程调用上锁后,另一个线程来获取资源时,会进行循环获取锁,加锁和设置过期时间等操作都是基于LUA脚本完成的(最大的作用是能够调用redis命令来保证多条命令执行的原子性)。 代码如下
java
public void redisLock() throws InterruptedException {
//获取锁
RLock lock = redissonClient.getLock("123");
//尝试获取锁:超过最大时间后,会自动释放
boolean isLock = lock.tryLock(10,TimeUnit.SECONDS);
//判断是否获取成功
if(isLock) {
try{
System.out.println("执行业务");
} finally{
lcok.unlock();
}
}
}Redisson实现的分布式锁支持可重入锁:利用hash结构记录线程id和重入次数,如下
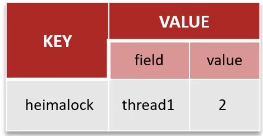
redisson实现的分布式锁实现主从一致性.
RedLock(红锁):不能只在一个redis实例上创建锁,而是在多个redis实例上创建锁(n/2+1),避免在一个redis实例上加锁。实现复杂,性能差。
redisson整体的思想是AP思想:优先保证的是高可用性。
保证数据的强一致性是CP思想,采用zookeeper实现
AI随探录
智能输入法案例
根据用户当前已输入的文本内容,预测下一个可能输入的词语,要求返回概率最高的 5 个候选词供用户选择。
数据集
本任务使用的数据集为https://huggingface.co/datasets/Jax-dan/HundredCV-Chat
模型结构
基于RNN的语言模型结构实现。模型整体分为 嵌入层(Embedding)---循环神经网络层(RNN)---输出层(Linear)
训练方案
采用交叉熵(CrossEntropyLoss)损失函数,结合交叉熵计算。使用Adam优化器
项目代码
在进行项目开始之前,要配置好nlp虚拟环境,搭建依赖。
process.py:数据预处理
python
import jieba
import pandas as pd
from sklearn.model_selection import train_test_split
from tqdm import tqdm
import config
from src.train import train
def build_dataset(sentences,word2_index):
index_sentences = [[word2_index.get(token, 0) for token in jieba.lcut(sentence)] for sentence in
sentences]
dataset = []
for sentence in tqdm(index_sentences,desc='构建数据集'):
for i in range(len(sentence) - config.SEQ_LEN):
input = sentence[i:i + config.SEQ_LEN]
target = sentence[i + config.SEQ_LEN]
dataset.append({'input': input, 'target': target})
return dataset
def process():
print("开始处理数据")
# 读取文件
df = pd.read_json(config.RAW_DATA_DIR / "synthesized_.jsonl", lines=True, orient='records').sample(frac=0.1)
#print(f'开始打印{df}')
# 提取句子
sentences = []
for dialog in df['dialog']:
for sentence in dialog:
sentences.append(sentence.split(':')[1])
print(f'句子总数:{len(sentences)}')
# 划分数据集
train_sentences, test_sentences = train_test_split(sentences, test_size=0.2)
# 构建词表
vocab_set = set()
for sentence in tqdm(train_sentences, desc="构建词表"):
vocab_set.update(jieba.lcut(sentence))
vocab_list = ['<unk>'] + list(vocab_set)
print(f'词表大小:{len(vocab_list)}')
# 保存词表
with open(config.MODELS_DIR / 'vocab.txt', 'w', encoding='utf-8') as f:
f.write('\n'.join(vocab_list))
# 构建训练集
word2_index = {word: index for index, word in enumerate(vocab_list)}
train_dataset = build_dataset(train_sentences,word2_index)
#保存训练集
pd.DataFrame(train_dataset).to_json(config.PROCESSED_DATA_DIR / 'train.jsonl', lines=True, orient='records')
#构建测试机
test_dataset = build_dataset(test_sentences, word2_index)
#保存测试集
pd.DataFrame(test_dataset).to_json(config.PROCESSED_DATA_DIR / 'test.jsonl', lines=True, orient='records')
print("数据处理完成")
if __name__ == '__main__':
process()dataset.py:数据处理模块
python
import torch
from torch.utils.data import Dataset, DataLoader
import pandas as pd
import config
class InputMethodDataset(Dataset):
"""
输入法数据集类,用于加载 JSONL 文件并生成张量。
"""
def __init__(self, file_path):
"""
初始化数据集。
:param file_path: 数据文件路径(JSONL 格式)。
"""
self.data = pd.read_json(file_path, lines=True,orient='records').to_dict(orient='records')
def __len__(self):
"""
获取数据集样本数量。
:return: 样本数量。
"""
return len(self.data)
def __getitem__(self, index):
"""
获取指定索引的数据样本。
:param index: 数据索引。
:return: (input_tensor, target_tensor)
"""
input_tensor = torch.tensor(self.data[index]['input'], dtype=torch.long)
target_tensor = torch.tensor(self.data[index]['target'], dtype=torch.long)
return input_tensor, target_tensor
def get_dataloader(train=True):
"""
获取数据加载器。
:param train: 是否加载训练集(True 加载训练集,False 加载测试集)。
:return: DataLoader 对象。
"""
file_name = 'train.jsonl' if train else 'test.jsonl'
dataset = InputMethodDataset(config.PROCESSED_DATA_DIR / file_name)
return DataLoader(dataset, batch_size=config.BATCH_SIZE, shuffle=True)
if __name__ == '__main__':
dataloader = get_dataloader()
for input_tensor, target_tensor in dataloader:
print(input_tensor.shape, target_tensor.shape) #input_tensor.shape [batch_size,seq_len] output:[batch_size]
breakmodel.py:训练模型的结构
python
import torch
from torch import nn
from torchinfo import summary
import config
class InputMethodModel(nn.Module):
"""
输入法预测模型,基于 RNN 的序列模型。
"""
def __init__(self, vocab_size):
"""
初始化模型。
:param vocab_size: 词表大小。
"""
super().__init__()
# 嵌入层:将 token 索引映射为向量
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=config.EMBEDDING_DIM) #(词汇表的大小,词向量的维度)
# RNN:处理序列数据,提取上下文特征
self.rnn = nn.RNN(
input_size=config.EMBEDDING_DIM,
hidden_size=config.HIDDEN_SIZE,
batch_first=True
)
# 全连接层:将隐藏状态映射到词表大小的概率分布
self.linear = nn.Linear(in_features=config.HIDDEN_SIZE, out_features=vocab_size)
def forward(self, x):
"""
前向传播。
:param x: 输入张量,形状 (batch_size, seq_len)。
:return: 模型输出,形状 (batch_size, vocab_size)。
"""
# 嵌入层处理输入序列
embed = self.embedding(x) # (batch_size, seq_len, embedding_dim)
# RNN 处理嵌入向量序列
output, _ = self.rnn(embed) # (batch_size, seq_len, hidden_size)
# 取最后一个时间步的输出进行分类
result = self.linear(output[:, -1, :]) # (batch_size, vocab_size)
return result
if __name__ == '__main__':
model = InputMethodModel(vocab_size=20000).to('cuda')
# 创建随机 dummy 输入用于展示模型结构
dummy_input = torch.randint(
low=0,
high=20000,
size=(config.BATCH_SIZE, config.SEQ_LEN),
dtype=torch.long,
device='cuda'
)
# 打印模型摘要
summary(model, input_data=dummy_input)config.py:超参数配置
python
from pathlib import Path
# 项目根目录
ROOT_DIR = Path(__file__).parent.parent
# 数据路径
RAW_DATA_DIR = ROOT_DIR / 'data' / 'raw'
PROCESSED_DATA_DIR = ROOT_DIR / 'data' / 'processed'
# 模型和日志路径
MODELS_DIR = ROOT_DIR / 'models'
LOG_DIR = ROOT_DIR / 'logs'
# 训练参数
SEQ_LEN = 5 # 输入序列长度
BATCH_SIZE = 64 # 批大小
EMBEDDING_DIM = 64 # 嵌入层维度
HIDDEN_SIZE = 128 # RNN 隐藏层维度
LEARNING_RATE = 1e-3 # 学习率
EPOCHS = 30 # 训练轮数train.py:模型训练模块
python
import time
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from dataset import get_dataloader
from model import InputMethodModel
from tokenizer import JiebaTokenizer
import config
def train_one_epoch(model, dataloader, loss_function, optimizer, device):
"""
训练一个 epoch。
:param model: 输入法模型。
:param dataloader: 数据加载器。
:param loss_function: 损失函数。
:param optimizer: 优化器。
:param device: 设备。
:return: 平均损失。
"""
total_loss = 0
model.train()
for inputs, targets in tqdm(dataloader, desc='训练'):
# 将数据移到设备
inputs, targets = inputs.to(device), targets.to(device)
#input.shape [batch_size,seq_len]
# target.shape [batch_size]
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)# (batch_size, vocab_size)
# 计算损失
loss = loss_function(outputs, targets)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
return avg_loss
def train():
"""
模型训练主函数。
"""
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('设备:', device)
dataloader = get_dataloader() # 获取数据加载器
# 加载 tokenizer 和模型
with open(config.MODELS_DIR / 'vocab.txt', 'r', encoding='utf-8') as f:
vocab_list = [line.strip() for line in f.readlines()]
#加载模型
model = InputMethodModel(vocab_size=len(vocab_list)).to(device)
#损失函数
loss_function = nn.CrossEntropyLoss()
#优化器
optimizer = torch.optim.Adam(model.parameters(), lr=config.LEARNING_RATE)
# TensorBoard 日志
writer = SummaryWriter(log_dir=config.LOG_DIR / time.strftime('%Y-%m-%d_%H-%M-%S'))
best_loss = float('inf')
for epoch in range(1, config.EPOCHS + 1):
print(f'========== Epoch: {epoch} ==========')
# 训练一个 epoch
avg_loss = train_one_epoch(model, dataloader, loss_function, optimizer, device)
print(f'Loss: {avg_loss:.4f}')
# 记录到 TensorBoard
writer.add_scalar('Loss/train', avg_loss, epoch)
# 保存最优模型
if avg_loss < best_loss:
best_loss = avg_loss
torch.save(model.state_dict(), config.MODELS_DIR / 'model.pt')
print('模型保存成功!')
writer.close()
if __name__ == '__main__':
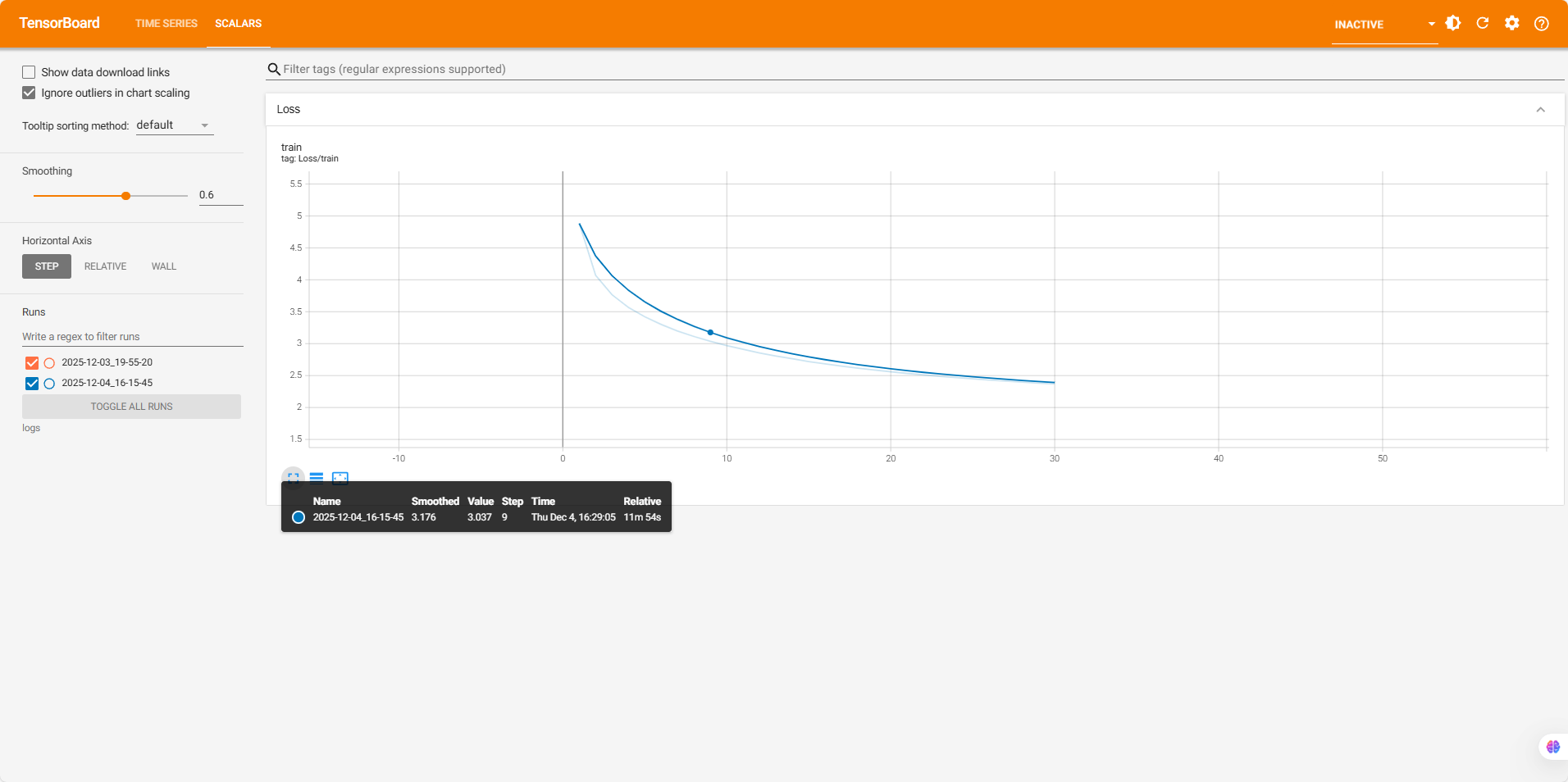
train()tensorboard可视化工具
在train模块中,采用tensorboard可视化工具
pip install tensorboard进行安装。
创建SummaryWriter
python
from torch.utils.tensorboard import SummaryWriter
# 创建写入器,指定日志保存目录
writer = SummaryWriter(log_dir="./logs")
writer.add_scalar(tag, scalar_value, global_step)启动
在终端输入tensorboard --logdir ./logs

predict.py:模型预测
python
import jieba
import torch
import config
from model import InputMethodModel
def predict(text,model,word2index,index2word,device):
#4. 处理输入
tokens = jieba.lcut(text)
indexes = [word2index.get(token,0) for token in tokens]
input_tensor = torch.tensor([indexes], dtype=torch.long)
input_tensor = input_tensor.to(device)
#5.预测逻辑
model.eval()
with torch.no_grad():
output = model(input_tensor)
top5_indexes = torch.topk(output, 5).indices
top5_indexes_list = top5_indexes.tolist()
top5_tokens = [index2word[index] for index in top5_indexes_list[0]]
return top5_tokens
def run_predict():
# 1. 确定设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 2.词表
with open(config.MODELS_DIR / 'vocab.txt', 'r', encoding='utf-8') as f:
vocab_list = [line.strip() for line in f.readlines()]
word2index = {word: index for index, word in enumerate(vocab_list)}
index2word = {index: word for index, word in enumerate(vocab_list)}
# 3.模型
model = InputMethodModel(vocab_size=len(vocab_list)).to(device)
model.load_state_dict(torch.load(config.MODELS_DIR / 'model.pt'))
print("欢迎使用输入法模型(输入q或者quit退出)")
input_history = ''
while True:
user_input = input("> ")
if user_input in ['q', 'quit']:
break
if user_input.strip() == '':
print("请输入内容")
continue
input_history += user_input
top5_tokens = predict(input_history,model,word2index,index2word,device)
print(top5_tokens)
if __name__ == '__main__':
run_predict()实现效果
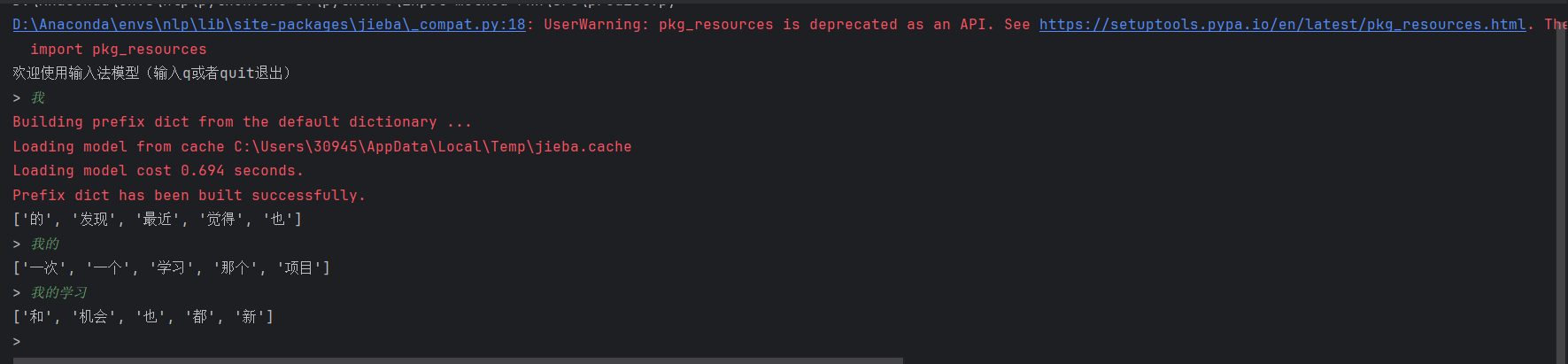
代码随想录
分割回文串
给你一个字符串
s,请你将s分割成一些 子串,使每个子串都是 回文串 。返回s所有可能的分割方案。示例 1:
输入:s = "aab" 输出:[["a","a","b"],["aa","b"]]示例 2:
输入:s = "a" 输出:[["a"]]提示:
1 <= s.length <= 16s仅由小写英文字母组成
java
class Solution {
List<List<String>> result = new ArrayList<>();
List<String> path = new LinkedList<>();
private boolean ishw(String s, int j, int k) {
for(int i = j, n = k; i < n; i++, n--) {
if(s.charAt(i) != s.charAt(n))
return false;
}
return true;
}
private void back(String s, int ids) {
if(ids >= s.length()) {
result.add(new ArrayList(path));
return;
}
for(int i = ids;i < s.length(); i++) {
if(ishw(s,ids,i)) {
String str = s.substring(ids,i + 1);
path.add(str);
}else{
continue;
}
back(s,i + 1);
path.removeLast();
}
}
public List<List<String>> partition(String s) {
back(s,0);
return result;
}
}