推荐阅读列表
LLM之Agent(三十三)|AI Agents(二):从零开始构建Agent
LLM之Agent(三十四)|AI Agents(三):AI Agents框架介绍
LLM之Agent(三十五)|AI Agents(四):AI Agent类型
LLM之Agent(三十六)|AI Agents(五):Workflow vs Agent
一、引言
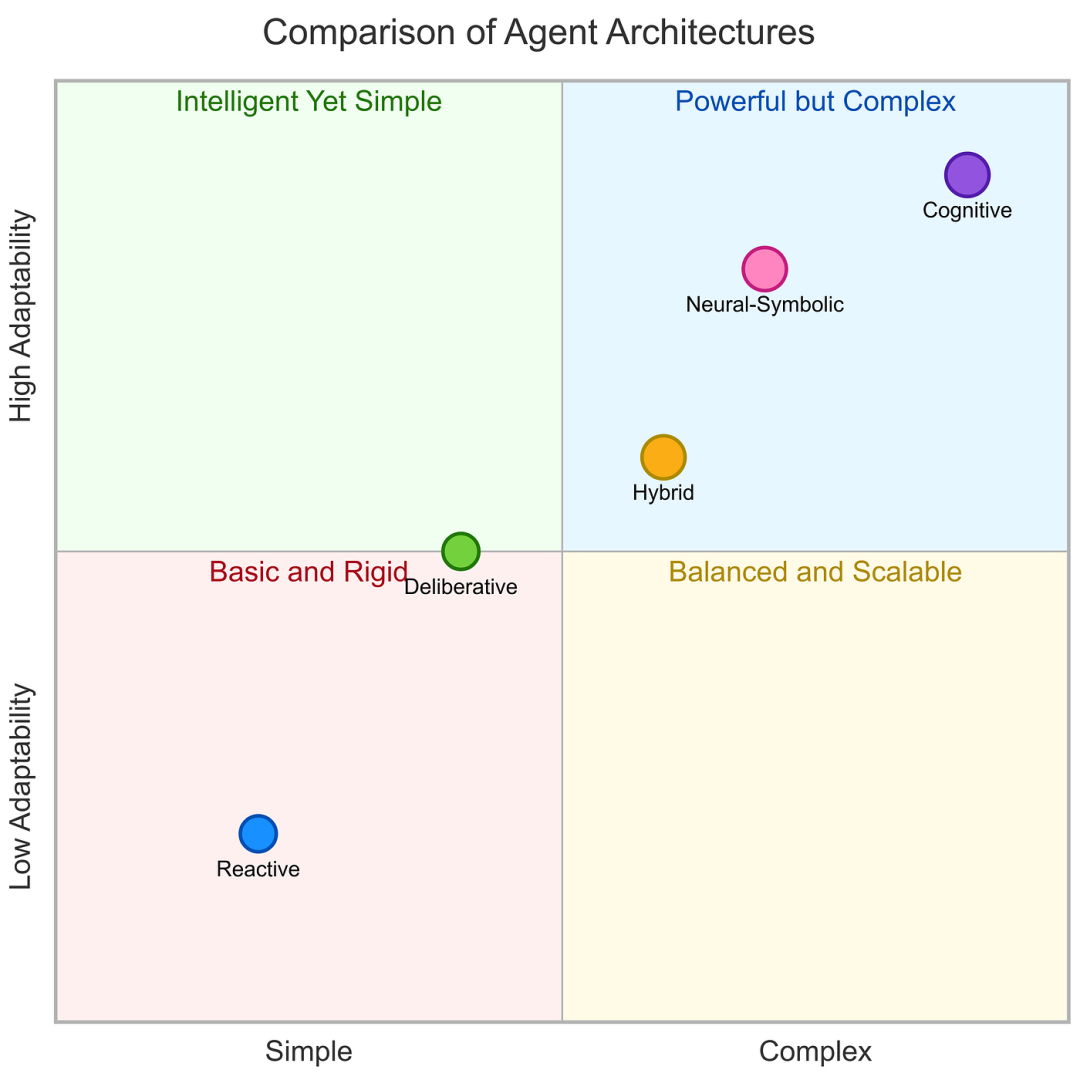
智能体架构是定义AI agent组件如何组织和交互的蓝图,使智能体能够感知环境、进行推理并采取行动。本质上,它就像智能体的数字大脑------集成了"眼睛"(传感器)、"大脑"(决策逻辑)和"双手"(执行器)来处理信息和执行动作。
选择合适的架构对于构建高效的AI agent至关重要。架构决定了agent的响应速度、处理复杂性的能力、学习适应性和资源需求。例如,一个简单的基于反射的代理可能擅长实时反应,但在长期规划方面表现不佳;而一个深思熟虑的代理则可以处理复杂的目标,但计算成本更高。了解这些权衡取舍,有助于工程师将架构与应用领域相匹配,从而实现最佳性能和可靠性。
二、Agent 架构
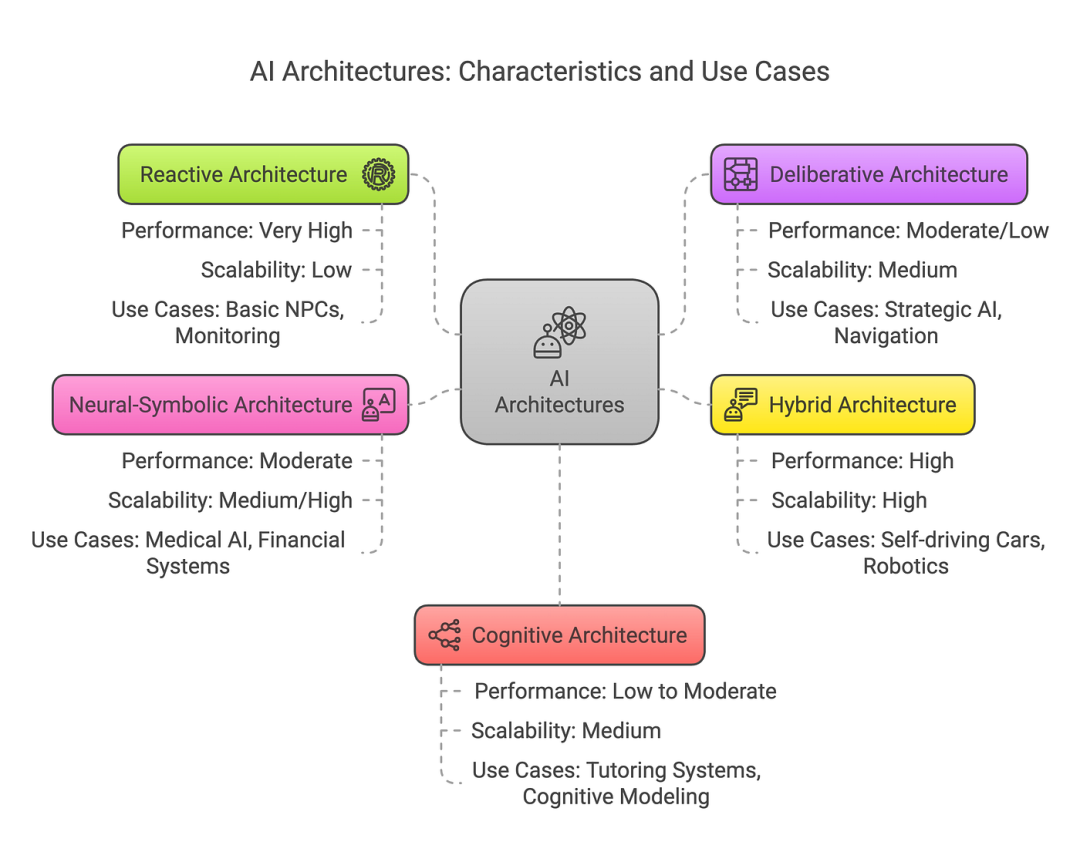
智能体架构大致可分为以下几类:
-
Reactive 反应型
-
Deliberative 审议式
-
Hybrid 混合
-
Neural-Symbolic 神经符号
-
Cognitive 认知的
2.1 Reactive 架构
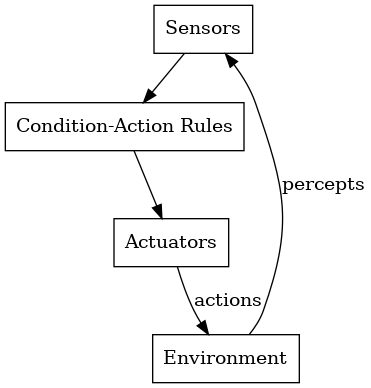
最直接的 AI agent设计模式称为 ReAct 。这种设计模式, 大型语言模型(LLM) 首先分析当前情况并确定下一步行动。然后,该行动在环境中执行,并生成观察结果作为反馈。LLM 处理该观察结果,重新评估下一步行动,选择另一个行动,并重复此循环,直到任务完成。
2.1.1 用例
ReAct架构非常适合需要瞬间决策且响应可预测、定义明确的领域。经典的例子包括机器人和游戏:例如,机器人吸尘器或无人机一旦传感器检测到障碍物就会自动避开;又如,电子游戏中的非玩家角色会对玩家的操作做出预先设定的即时反应(例如,敌方守卫一旦进入玩家视野就会立即攻击)。
在工业环境中,简单的监控agent会在传感器超出范围时触发警报或关闭设备。这些agent在实时控制系统中表现出色,但由于缺乏全局规划能力,它们通常用于相对简单或限制严格的任务, 在这些任务中,所有情况的规则都可以预先定义。
对于简单的任务,可以使用纯代码轻松构建 React 设计模式,而无需使用框架。
首先,我们需要一个大型语言模型作为智能体的大脑:
from dotenv import load_dotenv
from openai import OpenAI
_ = load_dotenv()
client = OpenAI()然后,我们可以将简单的代理构建成一个类,以便返回我们的消息:
class Agent:
def __init__(self, system=""):
self.system = system
self.messages = []
if self.system:
self.messages.append({"role": "system", "content": system})
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
def execute(self):
completion = client.chat.completions.create(
model="gpt-4o",
temperature=0,
messages=self.messages)
return completion.choices[0].message.content我们需要一个系统提示,指示我们的agent使用另外两个工具完成任务:一个用于数学计算,另一个用于找出给定犬种的平均体重。
import openai
import re
import httpx
import os
prompt = """
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you - then return PAUSE.
Observation will be the result of running those actions.
Your available actions are:
calculate:
e.g. calculate: 4 * 7 / 3
Runs a calculation and returns the number - uses Python so be sure to use floating point syntax if necessary
average_dog_weight:
e.g. average_dog_weight: Collie
returns average weight of a dog when given the breed
Example session:
Question: How much does a Bulldog weigh?
Thought: I should look the dogs weight using average_dog_weight
Action: average_dog_weight: Bulldog
PAUSE
You will be called again with this:
Observation: A Bulldog weights 51 lbs
You then output:
Answer: A bulldog weights 51 lbs
""".strip()
def calculate(what):
return eval(what)
def average_dog_weight(name):
if name in "Scottish Terrier":
return("Scottish Terriers average 20 lbs")
elif name in "Border Collie":
return("a Border Collies average weight is 37 lbs")
elif name in "Toy Poodle":
return("a toy poodles average weight is 7 lbs")
else:
return("An average dog weights 50 lbs")
known_actions = {
"calculate": calculate,
"average_dog_weight": average_dog_weight
}prompt = """
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop you output an Answer
Use Thought to describe your thoughts about the question you have been asked.
Use Action to run one of the actions available to you - then return PAUSE.
Observation will be the result of running those actions.现在我们可以通过循环分多个步骤运行agent程序:
abot = Agent(prompt)
def query(question, max_turns=5):
i = 0
bot = Agent(prompt)
next_prompt = question
while i < max_turns:
i += 1
result = bot(next_prompt)
print(result)
actions = [
action_re.match(a)
for a in result.split('\n')
if action_re.match(a)
]
if actions:
# There is an action to run
action, action_input = actions[0].groups()
if action not in known_actions:
raise Exception("Unknown action: {}: {}".format(action, action_input))
print(" -- running {} {}".format(action, action_input))
observation = known_actions[action](action_input)
print("Observation:", observation)
next_prompt = "Observation: {}".format(observation)
else:
return
question = """I have 2 dogs, a border collie and a scottish terrier. \
What is their combined weight"""
query(question)运行结果如下所示:
Thought: I need to find the average weight of a Border Collie and a Scottish Terrier, then add them together to get the combined weight.
Action: average_dog_weight: Border Collie
PAUSE
-- running average_dog_weight Border Collie
Observation: a Border Collies average weight is 37 lbs
Action: average_dog_weight: Scottish Terrier
PAUSE
-- running average_dog_weight Scottish Terrier
Observation: Scottish Terriers average 20 lbs
Thought: Now that I have the average weights of both dogs, I can calculate their combined weight by adding them together.
Action: calculate: 37 + 20
PAUSE
-- running calculate 37 + 20
Observation: 57
Answer: The combined weight of a Border Collie and a Scottish Terrier is 57 lbst如上所示,该agent使用两种不同的工具成功确定了Border Collies 和Scottish Terriers的平均体重,然后将结果相加。
2.1.2 优势与局限性
-
ReAct架构的主要优势在于速度 。由于无需复杂的推理开销,决策可以在恒定时间内做出,这对于实时机器人或高频交易等毫秒级精度至关重要的领域来说非常理想。
-
ReAct agent的设计和验证也相对简单,因为它们的行为是由规则明确定义的。
-
缺点是,由于它们不会学习或计划,因此它们的适应能力有限 ,它们无法应对不可预见的情况,也无法解决需要按顺序采取行动才能达到目标的问题。
-
它们也往往目光短浅,只注重优化即时响应,而忽略长远后果(如果反应式机器人的规则缺乏策略逻辑,它可能会在一个狭小的循环中无休止地徘徊)。这些局限性促使人们开发出更先进的架构,这些架构融合了内部状态和推理功能。
研究表明,不同的设计模式更适合不同的任务。与其从零开始构建这些架构,我们可以利用现有的、经过充分测试的、针对特定问题量身定制的解决方案。例如, LangGraph 的文档中就提供了一系列多智能体架构。
在本文中,我们将探讨这些架构以及如何将它们应用于我们的用例。
2.2 Deliberative 架构
Deliberative智能体是基于模型、目标驱动的智能体。与立即做出反应的ReAct智能体不同,Deliberative智能体会提前思考 ,利用内部模型评估多种可能的行动方案,并选择实现目标的最佳方案。
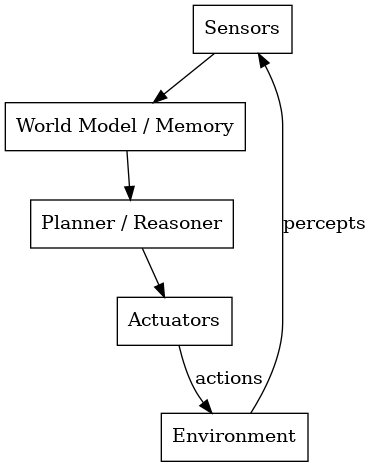
Sense → Model → Plan → Act
感知 → 模型 → 计划 → 行动
-
感知: 接收来自环境的新信息;
-
模型: 更新内部世界模型(例如符号状态、语义地图);
-
规划: 制定可能的计划并模拟/评估其结果;
-
行动: 执行最佳计划。
这种方法就像国际象棋人工智能提前计划好几步棋,而不是每一步都做出反应一样。
示例伪代码: 一个简化的deliberative代理循环(受 BDI 原则启发)可能如下所示:
# Pseudocode for a deliberative agent with goal-oriented planning
initialize_state()
while True:
perceive_environment(state)
options = generate_options(state) # possible plans or actions
best_option = evaluate_options(options) # deliberation: select best plan
commit_to_plan(best_option, state) # update intentions
execute_next_action(best_option)
if goal_achieved(state):
break在这个循环中, generate_options 会根据当前状态和目标生成可能的操作或计划, evaluate_options 会进行推理或规划(例如模拟结果或使用启发式方法来选择最佳计划),然后智能体逐步执行操作,并在每次执行后根据需要重新评估。这体现了深思熟虑的智能体如何考虑未来后果并优化长期目标。例如,在路径规划智能体中, generate_options 可能会生成多条路径,而 evaluate_options 会选择最短且安全的路径。
2.3 混合架构
混合agent架构结合了reactive和deliberative系统,在动态环境中实现速度和智能的平衡。
- Reactive层:对感觉输入做出即时反应(例如,避开障碍物);
- Deliberative层:使用内部模型执行目标驱动的规划(例如,路线规划)。
这些层级协同运作 ,通常并行运作,以平衡快速反应与长期战略。
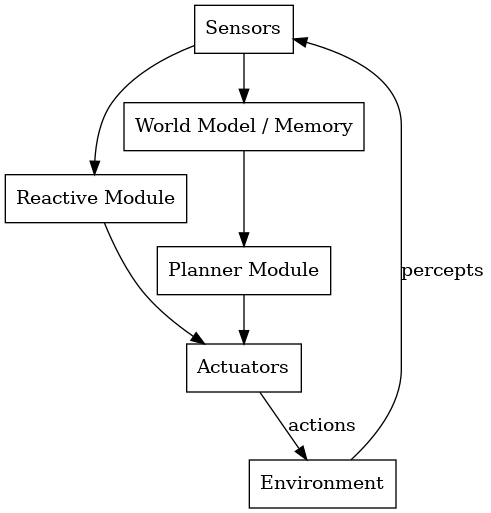
该架构通常采用分层结构:
-
底部: Reactive(本能反应)
-
中间部分(可选): 排序/协调
-
顶部: Deliberative(目标推理和计划)
-
协调机制 (如监督者或优先级规则)决定哪一层的输出优先。
percept = sense_environment()
if is_urgent(percept):
action = reactive_module(percept) # Quick reflex
else:
update(world_model, percept)
action = deliberative_planner(world_model, current_goal)
execute(action)
2.4 Neural-Symbolic 架构
神经符号(或神经符号 )架构将神经网络 (用于从数据中学习)与符号人工智能 (用于基于规则的推理)相结合,使智能体能够感知复杂的环境并对其进行推理 。
- 神经网络: 擅长模式识别 (例如,图像、语音);
- 符号系统: 擅长逻辑、推理和可解释性 ;
- 综合目标: 利用神经感知和符号理解做出智能、可解释的决策。
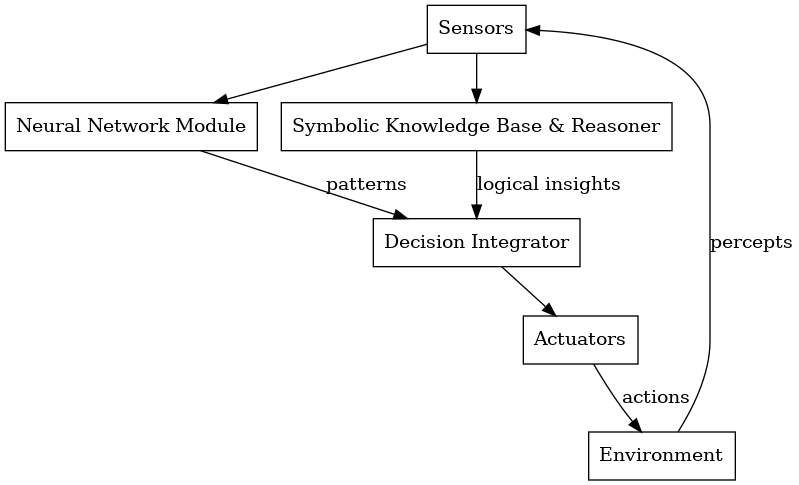
主要有两种整合策略:
- 顺序式: 神经模块处理原始输入(例如,检测物体);符号模块对解释后的输出进行推理;
- 并行: 神经模块和符号模块同时工作, 决策模块将两者的输出融合在一起。
伪代码示例:
percept = get_sensor_data()
nn_insights = neural_module.predict(percept) # Perception (e.g., detect anomaly)
sym_facts = symbolic_module.update(percept) # Translate data to logical facts
sym_conclusions = symbolic_module.infer(sym_facts) # Apply domain knowledge
decision = policy_module.decide(nn_insights, sym_conclusions)
execute(decision)2.5 Cognitive 架构
认知架构是综合框架,旨在通过将感知、记忆、推理和学习整合到一个统一的智能体系统中来模拟一般的人类智能。
目标是构建能够像人类一样学习、规划、解决问题和适应环境的智能体。
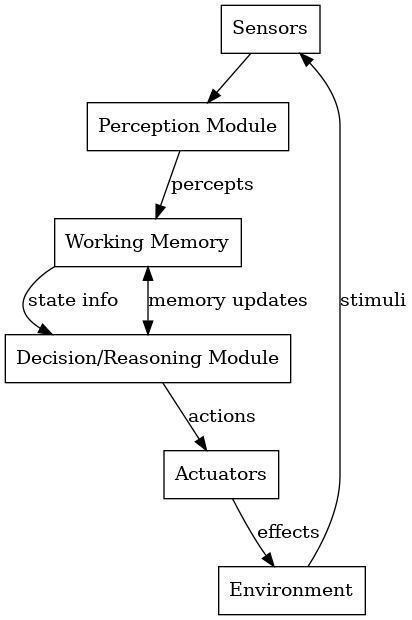
1. SOAR 架构
- 20 世纪 80 年代开发,用于一般智能行为;
- 工作记忆: 保存当前情况;
- 生产记忆: 存储"如果......那么......"规则;
- 采用通用子目标设定法 ------遇到困难时设定子目标。
- 学习: 采用" 组块化 "------将经验转化为新规则。
应用案例:人工智能飞行员、人形机器人、决策代理。
2. ACT-R 架构
- 源于认知心理学;
- 由专门的模块 (例如视觉、运动、记忆)组成;每个模块都使用自己的缓冲区作为临时工作内存;
- 生产规则管理缓冲区之间的数据流;
- 结合符号推理和亚符号机制(如记忆激活)。
共同特征
- 模块化设计 (感知模块、记忆模块、行动模块);
- 多内存系统 :
简化的认知循环:
percept = perceive_environment()
update_working_memory(percept)
action = cognitive_reasoner.decide(working_memory)
execute(action)SOAR 和 ACT-R 等认知架构提供了一种整体智能模型,整合了感知、记忆、决策和学习。它们不仅用于构建智能体,还能帮助我们理解人类思维的运作方式。这些系统非常适合那些需要随着时间推移不断学习 、 处理各种任务并像人类一样进行推理的智能体。
三、LangGraph 中的agent设计模式
智能体架构和智能体设计模式密切相关,但它们在AI agent开发中处于不同的抽象层次。
智能体架构指的是定义智能体构建和运行方式的结构框架或蓝图。它关注核心组件及其组织方式------可以将其视为智能体的"骨架"。架构详细说明了智能体如何感知环境、处理信息、做出决策以及采取行动。
架构通常更侧重于系统的构建方式 ------底层机制以及数据或控制的流动。
智能体设计模式是更高层次的、可重用的策略或模板,用于解决基于智能体的系统中的特定问题。它们不太关注智能体内部的具体细节,而更多地关注如何以一种能够适应不同情境的方式引导行为或交互。你可以把它们想象成实现特定结果的"配方"。
设计模式关注 "是什么" 和 "为什么" ------你希望agent展现出什么样的行为或能力,以及为什么它在给定的场景中是有效的。
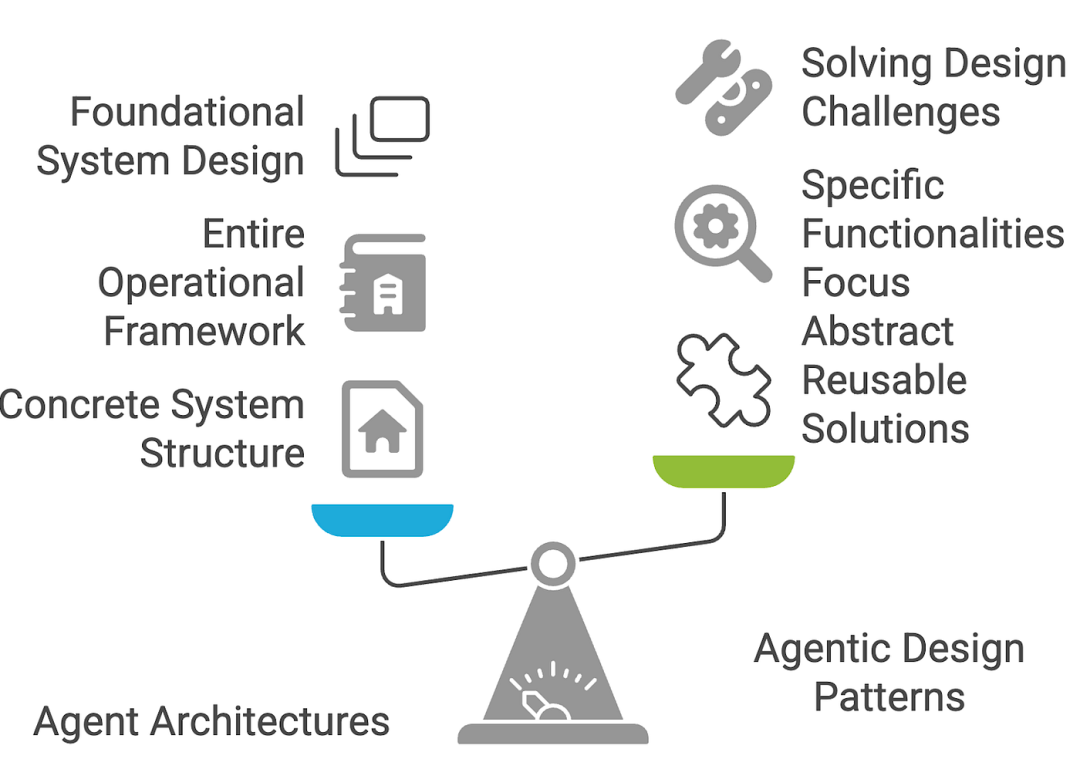
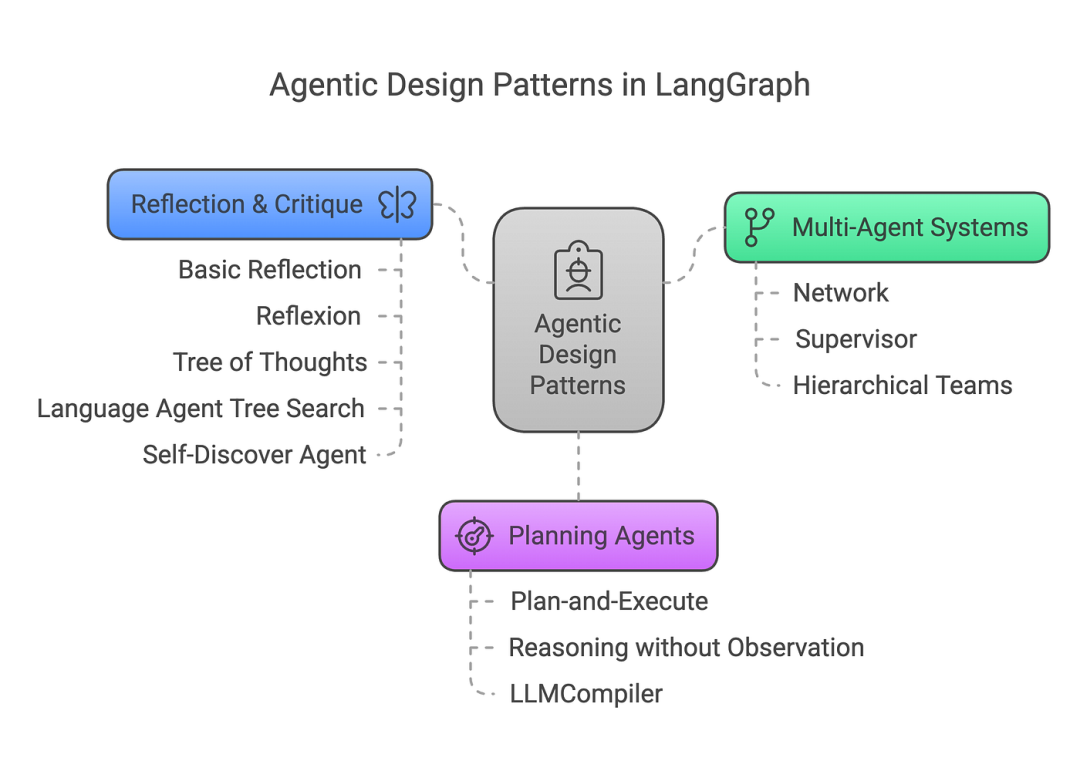
LangGraph 将这些Agent架构归纳为以下三大类:
3.1 Multi-Agent 系统
- Network1: 使两个或多个agent能够协作完成任务;
- Supervisor2: 使用 LLM 来协调任务并将其委派给各个agent;
- Hierarchical Teams3: 协调嵌套的agent团队来解决问题
3.2 Planning Agents
- Plan-and-Execute4: 实施一个基本的计划与执行代理;
- Reasoning without Observation5: 通过将观察结果保存为变量来减少重新规划;
- LLMCompiler6: 从规划器流式传输并立即执行 DAG 任务
3.3 Reflection & Critique
- Basic Reflection: 提示智能体反思并修改其输出;
- Reflexion: 批判性地分析缺失和多余的细节,以指导后续步骤;
- Tree of Thoughts: 使用评分树搜索问题的候选解决方案;
- Language Agent Tree Search: 利用反射和奖励机制驱动蒙特卡洛树搜索算法,搜索多个代理;
- Self-Discover Agent: 分析能够了解自身能力的智能体。
下面我们来深入了解一下Agentic设计模式。
四、Multi-agent 系统
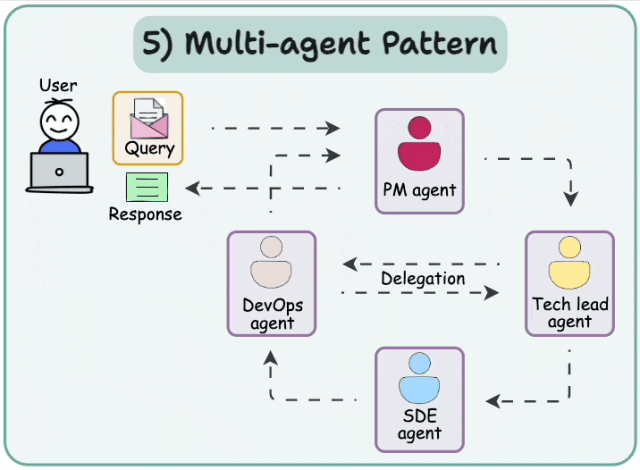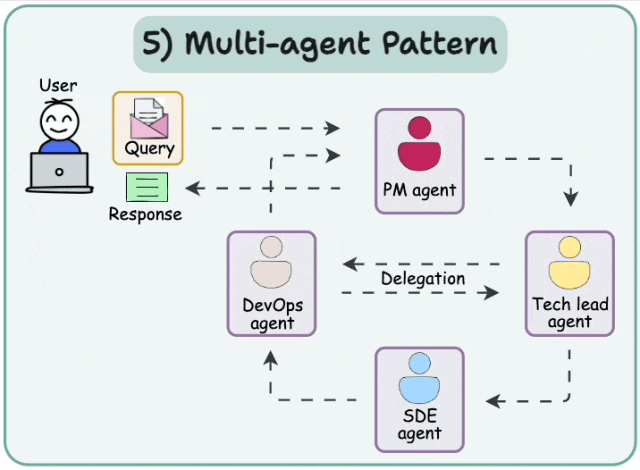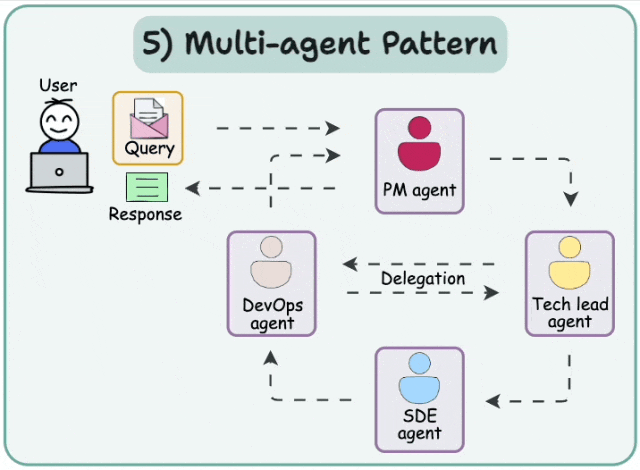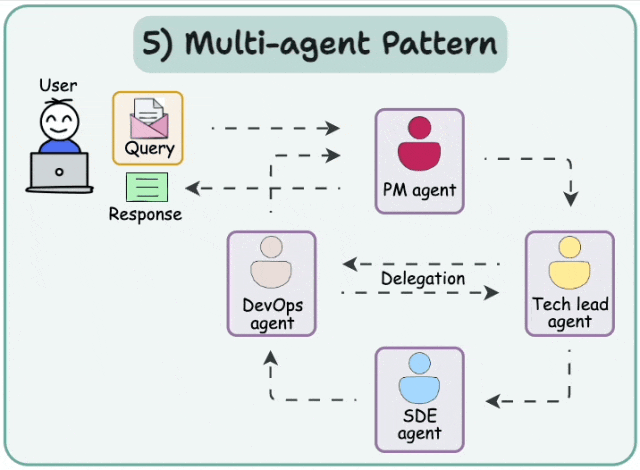
4.1 Multi-agent Network
解决复杂任务的一种方法是采用分而治之的策略。利用路由机制,可以将任务分配给专门负责该任务的代理。
这种架构被称为多智能体网络架构。
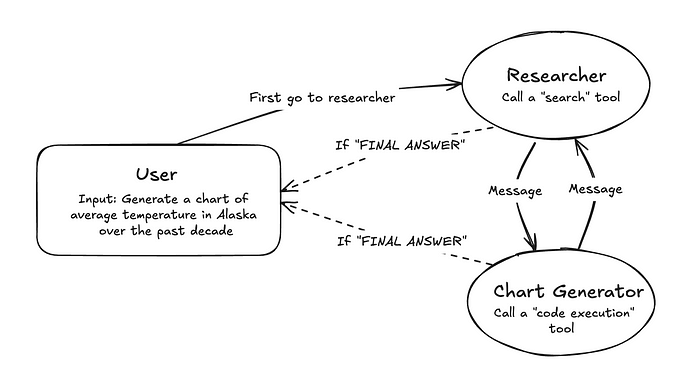
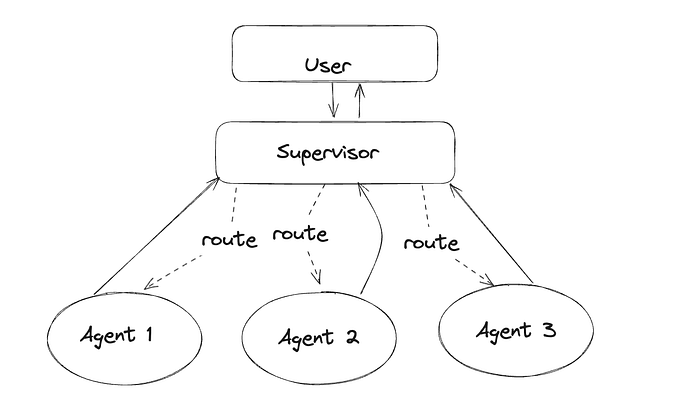
4.2 Multi-agent Supervisor
这种架构与网络架构非常相似,区别在于它使用一个主管Agent来协调不同的Agent,而不是路由器。
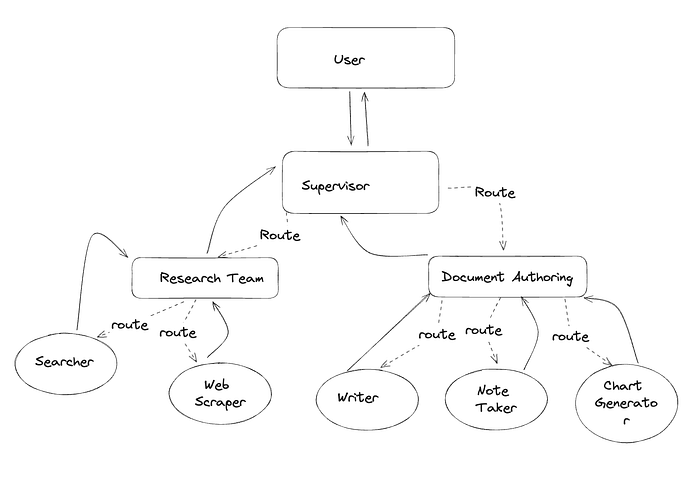
4.3 Hierarchical Agent Teams
层级式团队架构源于这样一个理念:"如果单个智能体不足以完成特定任务该怎么办?" 在这种情况下,不再是由一个主管智能体协调多个智能体,而是由一个主管智能体协调多个由多个智能体组成的团队。
五、Planning Agents
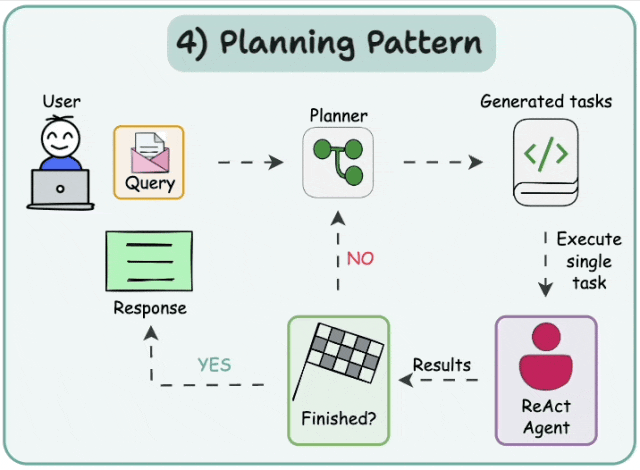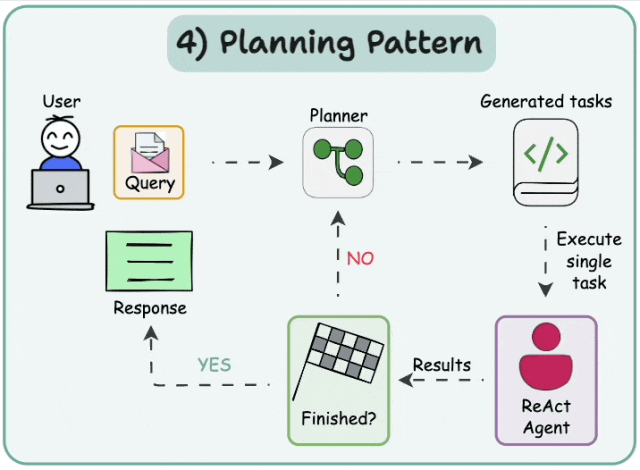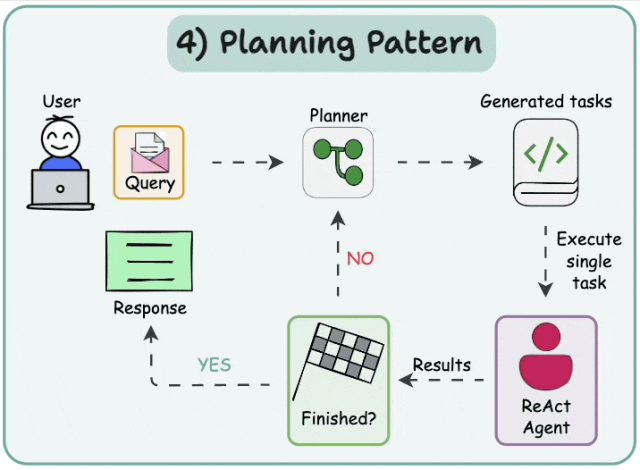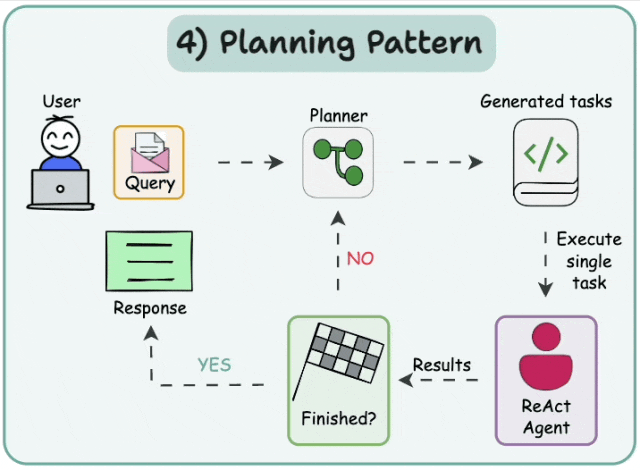
5.1 Plan-and-execute
在这种架构中,首先,智能体根据给定的任务顺序生成子任务。然后,单任务(专业化)智能体解决这些子任务,如果任务完成,则将结果发送回规划智能体。规划智能体根据结果制定不同的计划。如果任务完成,规划智能体会向用户发出响应。
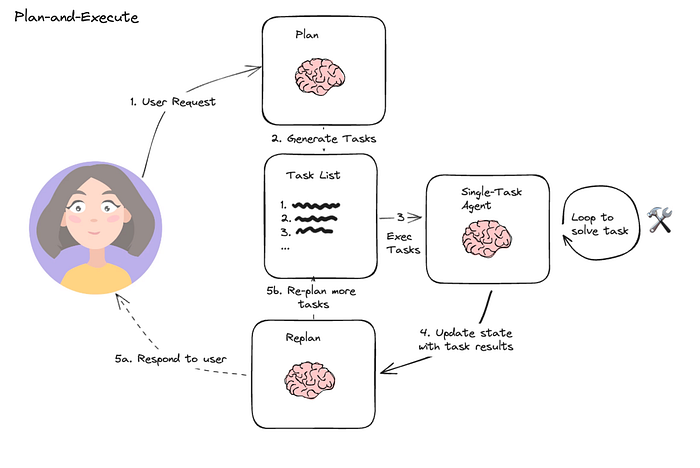
5.2 Reasoning without observation
在 ReWOO 中,Xu 等人提出了一种智能体,该智能体集成了多步骤规划器和变量替换机制,以优化工具的使用。这种方法与plan-and-execute架构非常相似。然而,与传统模型不同的是,ReWOO 架构在每个动作之后并不包含观察步骤。相反,整个计划在生成之初就已制定完成,并且保持不变,不受任何后续观察的影响。
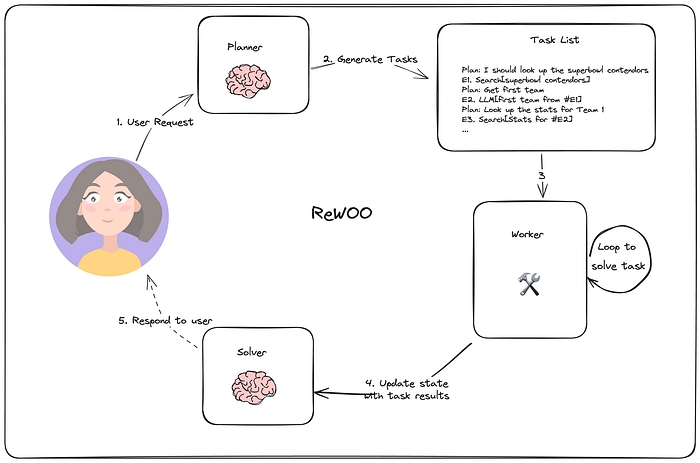
规划智能体构建一个包含子任务的计划来解决该任务,而worker智能体只需完成这些子任务,然后响应用户。
5.3 LLMCompiler
LLMCompiler 是一种agent架构,旨在通过在有向无环图 (DAG) 内执行预先加载的任务来加速agent任务的执行。它还通过减少对 LLM 的调用次数来节省冗余令牌的使用成本。以下是其计算图的概述:
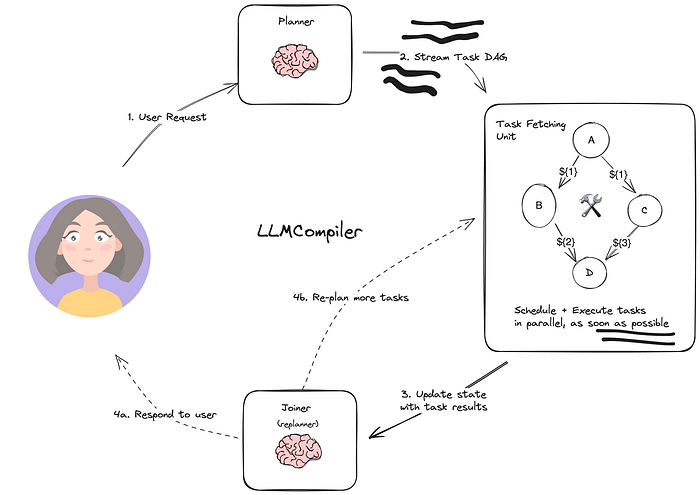
它由 3 个主要部分组成:
- Planner: 流式传输任务的 DAG;
- Task Fetching Unit: 负责调度和执行可执行的任务;
- Joiner: Responds to the user or triggers a second plan
六、Reflection & Critique
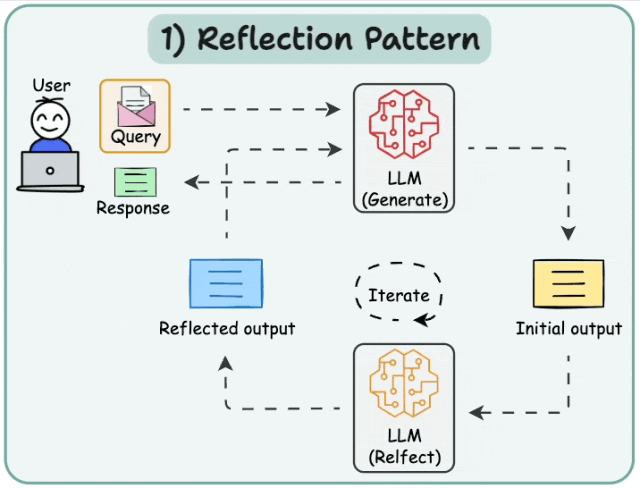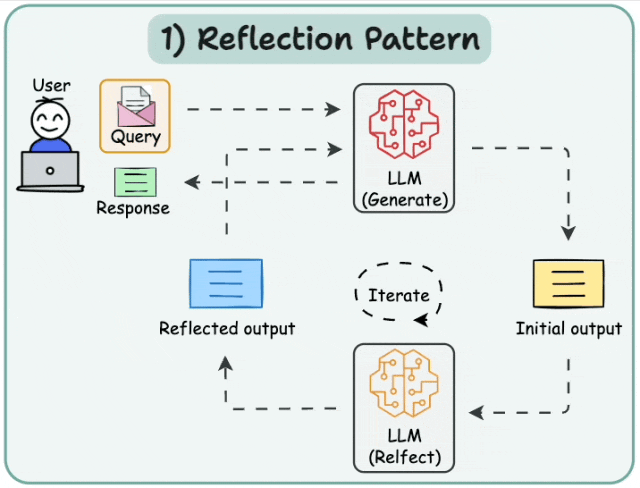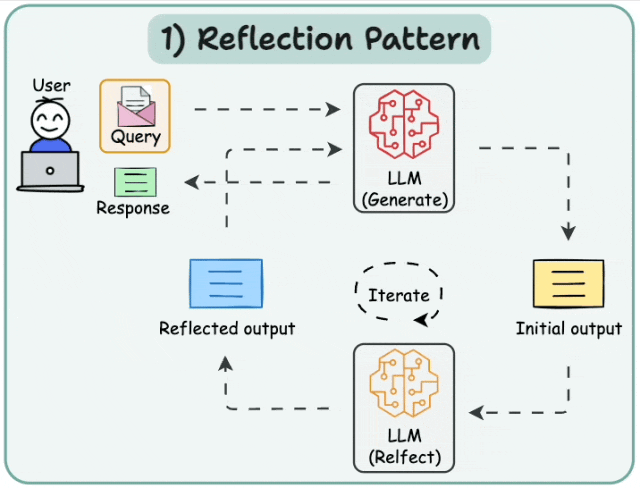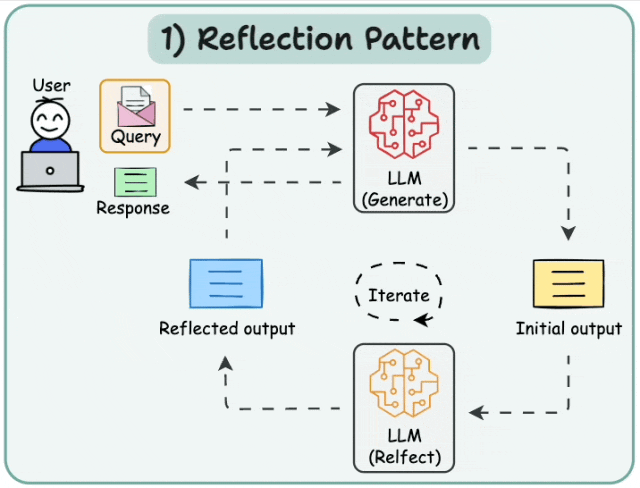
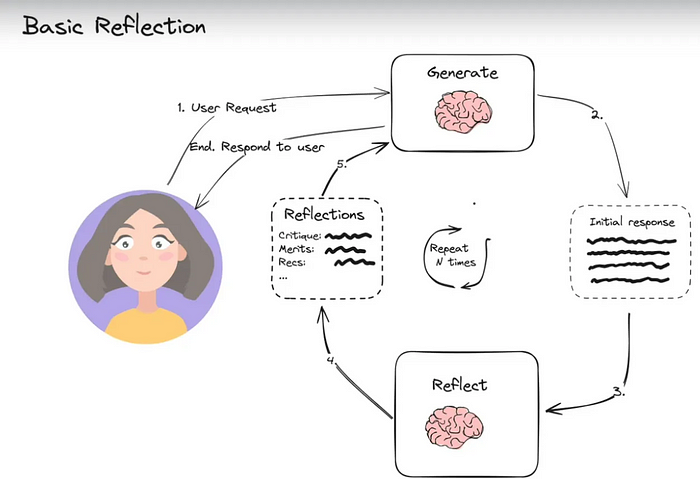
6.1 Basic Reflection
Reflection agents促使LLM反思其过往行为,从而不断学习和改进。该架构包含两个agents:生成器和评论者。最简单的例子是作者和评论者。作者根据用户请求撰写文本,评论者审阅文本,然后将评论反馈给作者。此循环持续进行,直至达到预设的迭代次数。
6.2 Reflexion
Shinn 等人提出的 Reflexion 架构旨在通过语言反馈和自我反思进行学习。该智能体会对其任务响应进行明确的批判性分析,以生成更高质量的最终响应,但代价是执行时间更长。与传统的反思架构不同,Reflexion 智能体还包含工具执行功能。
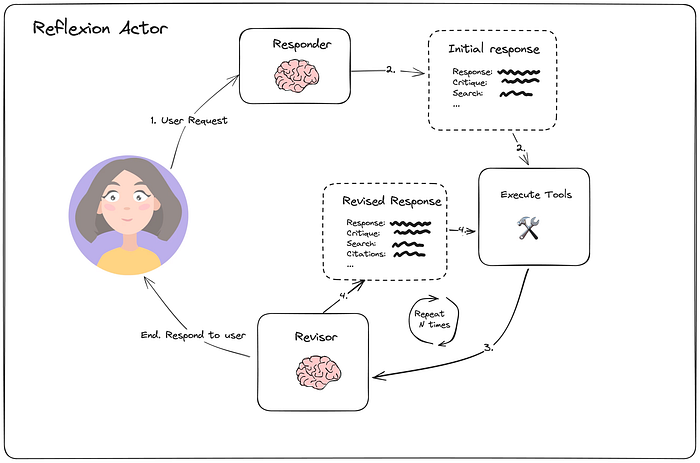
6.3 Tree of Thoughts
由 Yao 等人提出的"思维树"(ToT)是一种通用的 LLM 代理搜索算法,它结合了反思/评估和简单搜索(在本例中是 BFS,不过如果你愿意,也可以应用 DFS 或其他算法)。
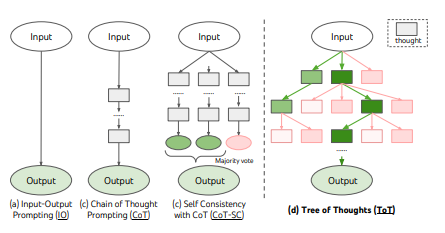
它包含三个主要步骤:
- 展开:生成一个或多个问题的候选解决方案;
- 评分:衡量回答的质量;
- 筛选:保留前 K 个最佳候选者
如果找不到解决方案(或者解决方案质量不足),则返回"展开"。
6.4 Language Agent Tree Search
Zhou 等人提出的Language Agent Tree Search (LATS)是一种通用的 LLM agent搜索算法,它结合了反思/评估和搜索(特别是蒙特卡洛树搜索),与 ReACT、Reflexion 或 Tree of Thoughts 等类似技术相比,能够实现更好的整体任务性能。
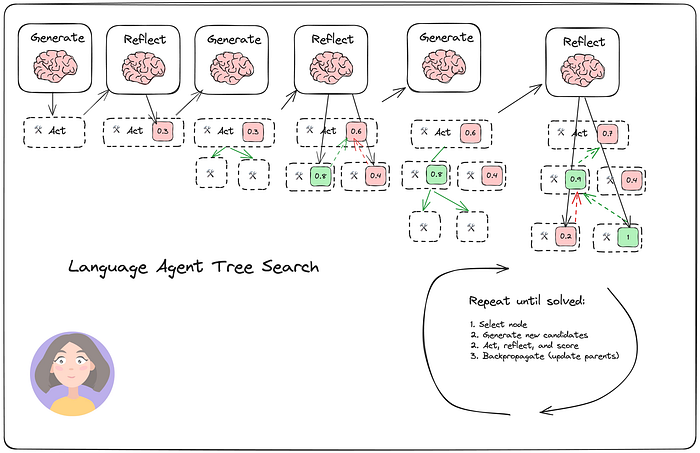
它包含四个主要步骤:
-
Select: 根据步骤(2)的综合奖励选择最佳的下一步行动。要么做出响应(如果找到解决方案或达到最大搜索深度),要么继续搜索;
-
Expand and simulate: 选择 5 个"最佳"潜在行动并并行执行;
-
Reflect + Evaluate: 观察这些行动的结果,并根据反思(以及可能的外部反馈)对决策进行评分;
-
Backpropagate: 根据结果更新根轨迹的分数。
6.5 Self-Discover Agent
Self-discover有助于大型语言模型 (LLM) 找到思考和解决棘手问题的最佳方法。
- 首先,它通过选择和改变基本推理步骤,为每个问题找到一个独特的解决方案;
- 然后,它利用这个计划逐步解决问题。
这样,LLM 使用不同的推理工具,并根据问题进行调整,从而获得比仅使用一种方法更有效的解决方案。
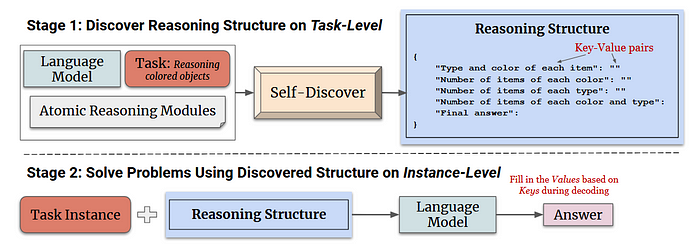
自我发现法与其他规划方法不同之处在于,它能自动为每个任务生成独特的推理策略。它的独特之处在于:
- 推理模块:它使用基本的推理步骤,并按特定顺序将它们组合在一起;
- 无需人工干预:它能够自行制定这些策略,无需人工标记任务;
- 适应任务:它能找到解决每个问题的最佳方法,就像人类制定计划一样;
- 可迁移性:它所创建的推理策略可以被不同类型的语言模型所使用。
简而言之,自我发现的独特之处在于它结合了不同的推理方法,无需具体的任务说明即可制定计划。
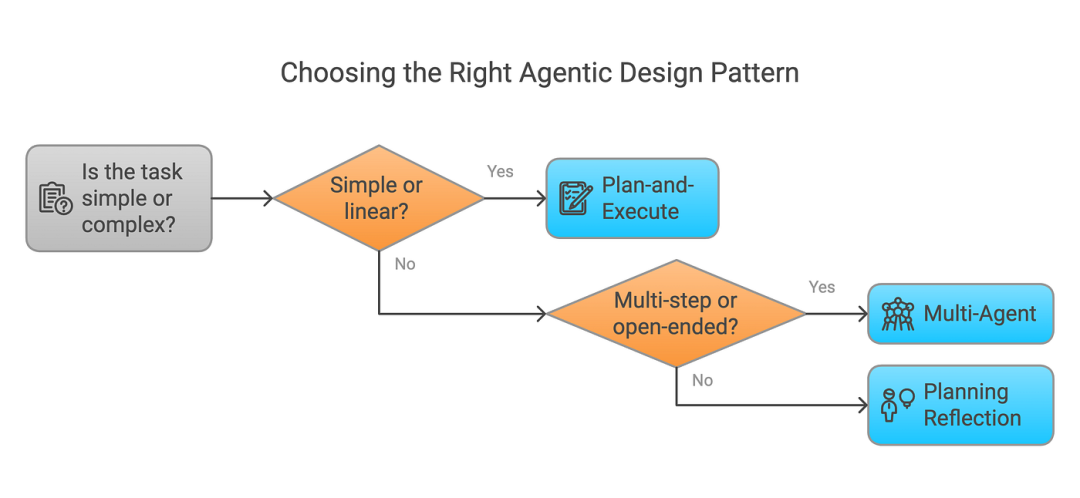
七、结论
在本篇博客中,我们探讨了智能体架构的演变,从传统的ReAct和审慎式模型到更先进的混合式、神经符号式和认知式系统。随后,我们利用 LangGraph 将这些基础概念与现代实现相结合,展示了强大的智能体设计模式,例如规划、协作、反思和批判。随着我们不断构建日益智能和自主的系统,理解和应用这些架构原则将是解锁可扩展、模块化和目标驱动型人工智能解决方案的关键。人工智能的未来不在于孤立的智能,而在于协调一致、善于反思且目标明确的智能体共同协作,解决复杂任务。
参考文献:
1 Network(https://langchain-ai.github.io/langgraph/tutorials/multi_agent/multi-agent-collaboration/)
2 Supervisor(https://langchain-ai.github.io/langgraph/tutorials/multi_agent/agent_supervisor/)
3 Hierarchical Teams(https://langchain-ai.github.io/langgraph/tutorials/multi_agent/hierarchical_agent_teams/)
4 Plan-and-Execute(https://langchain-ai.github.io/langgraph/tutorials/plan-and-execute/plan-and-execute/)
5 Reasoning without Observation(https://langchain-ai.github.io/langgraph/tutorials/rewoo/rewoo/)
6 LLMCompiler(https://langchain-ai.github.io/langgraph/tutorials/llm-compiler/LLMCompiler/)
7 Basic Reflection(https://langchain-ai.github.io/langgraph/tutorials/reflection/reflection/)
8 Reflexion(https://langchain-ai.github.io/langgraph/tutorials/reflexion/reflexion/)
9 Tree of Thoughts(https://langchain-ai.github.io/langgraph/tutorials/tot/tot/)
10 Language Agent Tree Search(https://langchain-ai.github.io/langgraph/tutorials/lats/lats/)
11 Self-Discover Agent(https://langchain-ai.github.io/langgraph/tutorials/self-discover/self-discover/)