一、什么是索引?
索引是提升查询速度的一种数据结构。
当你想查阅书中某个知识的内容,你会选择一页一页的找呢?还是在书的目录去找呢?
傻瓜都知道时间是宝贵的,当然是选择在书的目录去找,找到后再翻到对应的页。
书中的目录 ,就是充当索引的角色,方便我们快速查找书中的内容。
数据库中除了维护数据以外,还会额外维护索引,所以索引是++以空间换时间++的设计思想。
综上可得:
索引就是++帮助存储引擎快速获取数据的一种数据结构++ ,形象的说++索引就是数据的目录++。
有了索引之后,MySQL 不需要一行一行地全表扫描,而是能像查字典一样,沿着 B+ 树快速定位到数据,++大幅减少 IO 和 CPU 的消耗++ 。
为什么索引能减少 IO 消耗?
补充知识:IO 是什么?
IO,全称磁盘 IO,其中 I 表示 input,就是写数据,O 表示 output,就是读数据。
所以 IO 就是++数据库读取磁盘数据的次数++。
数据库的数据都存储在磁盘上,
- 每次读取数据就是从磁盘读取数据到内存上,
- 每次写入数据就是把内存的数据写到磁盘里。
因为磁盘很慢,内存很快。 一次磁盘 IO 可能是 几毫秒 ,但一次内存访问是 纳秒级。
所以数据库最贵的成本就是磁盘 IO。
因为索引是 B+ 树结构。
- 当某个字段无索引时,查找数据得全表扫描,查找速度为 O(n),非常慢;
- 当某个字段有索引时,查找数据在 B+ 树里二分查找,查找速度为 O(log n),非常快。
例如:我们要查找 user 表中所有 age = 30 的记录。
sql
SELECT * FROM user WHERE age = 30;1)无索引时:全表扫描
如果 age 没索引:
👉 必须从第一行扫描到最后一行
👉 每一行都要读磁盘,这就产生了大量 IO
时间复杂度 = O(n),非常慢。
2)有索引时:B+ 树查找
如果 age 有索引:
👉 直接在 B+ 树里二分查找
👉 一次定位到磁盘页
👉 最多只需要 2~3 次磁盘 IO(树高通常 2~4 层)
时间复杂度 = O(log n) ,极快。
为什么索引能减少 CPU 消耗?
补充知识:CPU 消耗是什么?
CPU 消耗指的是:CPU 用来进行计算、比较、排序、扫描数据的时间。
比如:
- 扫描一行行数据进行比较
- 做排序(ORDER BY)
- 做 MIN(), MAX() 运算
- 扫描 where 条件
这些都属于 CPU 消耗。
因为索引是 B+ 树结构。
- 当某个字段无索引 时,查找数据得全表扫描
- 从第一行开始,一行一行地++比对字段值++,直到找到目标行。
- 每一行都是一次 CPU 运算。 ** **
- 当某个字段有索引 时,查找数据则是通过 B+ 树进行二分查找。
- 只需要每层做一次 key 比较
- 例如三层 B+ 树,只需 3~5 次比较就能找到数据。 ** **
例如:我们要查找 user 表中++同时满足 age = 30 且 status = 1 的记录++。
sql
SELECT * FROM user WHERE age = 30 AND status = 11)无索引时:每一行都必须做条件判断
全表扫描 = 每行都要做以下判断:
- CPU 比较:age == 30?
- CPU 比较:status == 1?👉数据越大,CPU越累。
2)有索引时:B+ 树已经帮你排好序 + 过滤好范围
比如 age=30 放在 B+ 树的同一段叶子节点上。
CPU 不需要一行行判断,只需要扫描叶子节点的一小段。
👉 显著减少 CPU 工作量
二、索引的分类
(一)按数据结构分类
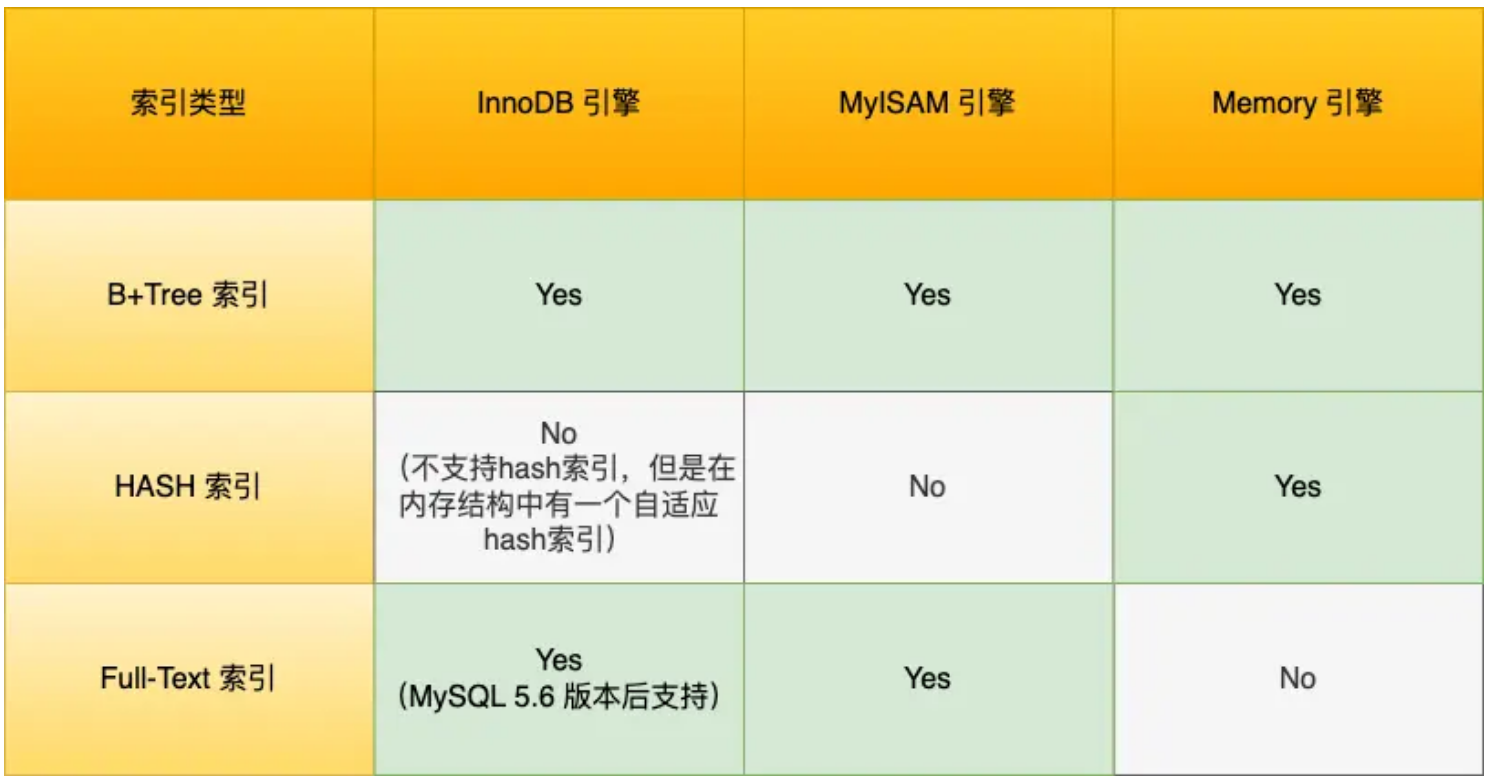
从数据结构的角度来看,MySQL 常见索引有 B+Tree 索引、HASH 索引、Full-Text 索引。
++每一种存储引擎支持的索引类型不一定相同++,下表中总结了 MySQL 常见的存储引擎 InnoDB、MyISAM 和 Memory 分别支持的索引类型。
(二)按物理存储分类
从物理存储的角度来看,索引分为聚簇索引(主键索引)、二级索引(辅助索引)。
聚簇索引
- 聚簇索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
二级索引
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
后面我们会详细介绍这两个索引。
(三)按字段特性分类
从字段特性的角度来看,索引分为主键索引、唯一索引、普通索引和前缀索引。
主键索引
**主键索引(PRIMARY KEY)**就是++建立在主键字段上的索引++,通常在创建表的时候一起创建。
- 每张表必须有一个主键索引(可以是你建的,也可以是 Innodb 自己生成的隐藏主键)。
- 主键索引列的值 不可以为 NULL。
- 主键索引就是聚簇索引 :
数据行按主键顺序存储在 B+Tree 的叶子节点。
**建表时创建 **
在创建表时,创建主键索引的方式如下:
sql
CREATE TABLE table_name (
...
PRIMARY KEY(index_column_1) USING BTREE
);示例:创建 user 表的时候,给 id 创建主键索引。
写法1:
sql
CREATE TABLE user (
id BIGINT NOT NULL,
username VARCHAR(50) NOT NULL,
email VARCHAR(100),
phone VARCHAR(20),
created_at DATETIME,
PRIMARY KEY (id)
) ENGINE=InnoDB;写法2:
sql
CREATE TABLE user (
id BIGINT NOT NULL PRIMARY KEY,
...
);建表后创建
sql
ALTER TABLE table_name
ADD PRIMARY KEY (column_name);示例:给 user 表的 id 字段设置为主键
sql
ALTER TABLE user
ADD PRIMARY KEY (id);唯一索引
唯一索引(UNIQUE)就是建立在 UNIQUE 字段上的索引。
- 一张表可以创建多个唯一索引。
- ++索引列的值不能重复++,但可以为 NULL。
- 唯一索引用来保证数据不会重复。
- 常见的唯一索引有:手机号、身份证号等。
建表时创建
**方式 1:**在建表时,使用 CREATE TABLE 创建唯一索引
sql
CREATE TABLE table_name (
...
UNIQUE KEY(index_column_1, index_column_2, ...)
);示例:在创建 user 表时,给 username 和 email 两个字段创建唯一索引。
sql
CREATE TABLE user (
id BIGINT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100),
UNIQUE KEY uk_username (username), -- 唯一索引
UNIQUE KEY uk_email (email) -- 再建一个
);**方式2:**在建表时,使用 CREATE UNIQUE INDEX 创建唯一索引
sql
CREATE UNIQUE INDEX idex_name
ON table_name(index_column_1, index_column_2, ...);示例:
sql
CREATE UNIQUE INDEX uk_username ON user(username);**建表后创建 **
方式 3:创建表后,使用 ALTER TABLE 添加唯一索引
sql
ALTER TABLE table_name
ADD UNIQUE KEY idex_name (column_name);示例:在创建 user 表后,给 username 字段创建唯一索引 uk_username。
sql
ALTER TABLE user ADD UNIQUE KEY uk_username (username);普通索引
普通索引就是建立在普通字段上的索引,是最基础、最常用的索引。它既不要求字段为主键,也不要求字段为 UNIQUE,只是用来提高查询效率。
**建表时创建 **
在创建表时,创建普通索引的方式如下:
sql
CREATE TABLE table_name (
...
INDEX idx_name (index_column)
);示例:
sql
CREATE TABLE user (
id BIGINT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100),
phone VARCHAR(20),
INDEX idx_phone (phone) -- 普通索引
);**建表后创建 **
建表后,如果要创建普通索引,可以使用下面这条命令:
方式1:
sql
CREATE INDEX idx_name ON table_name(index_column);示例:
sql
CREATE INDEX idx_phone ON user(phone);方式2:
sql
ALTER TABLE table_name ADD INDEX idx_name (idx_column);示例:
sql
ALTER TABLE user ADD INDEX idx_phone (phone);前缀索引
前缀索引(PREFIX INDEX)就是++对字符串类型字段的++ ++前几个字符++ ++建立的索引++,而不是对整个字段建立索引。
使用前缀索引的目的就是为了:提升查询效率的同时,++减少索引占用的存储空间++。
经典用途有:长字符串,如文章标题、URL、邮箱。
注意:前缀索引不能用于 ORDER BY、GROUP BY 完全覆盖查询。
**建表时创建 **
在创建表时,创建普通索引的方式如下:
sql
CREATE TABLE table_name (
...,
column_name column_type,
INDEX idx_name (column_name(length))
);示例:
sql
CREATE TABLE user (
...,
email VARCHAR(100),
INDEX idx_email_prefix (email(10))
);**建表后创建 **
sql
CREATE INDEX idx_name ON tab_name(col_name(length));示例: 假设 email 很长,我们只索引前 10 个字符。
sql
CREATE INDEX idx_email_prefix ON user(email(10));(四)按字段个数分类
从字段个数的角度来看,索引可以分为单列索引、联合索引(复合索引)。
单列索引
单列索引,就是++建立在单列字段上的索引++,比如主键索引。
联合索引
联合索引(COMPOSITE INDEX) ,就是++建立在多个字段上的索引++。
- 会遵守 最左前缀原则:从最左边字段开始,连续使用多少,就能利用多少索引。
- 应用于多条件查询(where a=x and b=y)。
一般在建表后,创建联合索引,命令如下:
sql
CREATE INDEX idx_a_b_c ON table(a, b, c);示例:将用户表中的 name 和 age 字段组合成联合索引(name, age),创建的联合索引如下:
sql
CREATE INDEX idx_name_age ON table(name, age);MySQL 索引总结表
| 索引类型 | 是否唯一 | 说明 |
|---|---|---|
| 主键索引 | 是 | 聚簇索引,数据按主键排序 |
| 唯一索引 | 是 | 允许多个 NULL |
| 普通索引 | 否 | 最常用 |
| 前缀索引 | 否 | 长字符串节省空间 |
| 联合索引 | 取决于是否 UNIQUE | 多字段索引,遵循最左匹配 |
二、相关面试题
1. 什么是索引?
索引就是++帮助存储引擎快速获取数据的一种数据结构++ ,形象的说++索引就是数据库的++ ++目录++。
MySQL 除了维护数据以外,还会额外维护索引的数据结构,这属于++以空间换时间++。
有了索引之后,MySQL 就不需要一行一行地全表扫描,而是能像查字典一样,沿着 B+ 树快速定位到数据,大幅减少 IO 和 CPU 的消耗。
2. MySQL 有哪些索引?
MySQL 主要有++主键索引、普通索引、唯一索引、前缀索引和联合索引++这几种索引。
- Innodb 引擎会要求++每一张表都必须要有一个++ ++主键索引++,比如表里的 id 字段就是主键索引。
- 对于需要++保证数据不重复++ 的字段,如手机号、身份证号等,我们可以建立++唯一索引++。
- 针对++查询比较频繁的字段++ ,我们可以针对这个字段建立最常用的++普通索引++。
- 对于长字符字段,比如文章标题、商品名称等,我们可以++只对这些字段的前缀部分建立索引++ ,这就是++前缀索引++,可以减少索引的存储空间。
- 如果是++多个字段++ 的话,可以考虑建立++联合索引++ ,利用++多字段组合查询++来提高查询效率。