研究背景
现有的通用时间序列预测模型虽然通过大规模预训练实现了跨领域的零样本预测能力,但训练数据的多样性问题尚未得到充分研究。数据集往往存在固有偏差和不平衡分布,仅三个数据集就占总数据量的88.2%,这种偏斜分布会导致原始数据中出现大量重复模式,损害整体数据多样性。现有采样策略(如朴素采样和分层采样)也无法充分纠正大规模时间序列数据中的固有偏差。
本文贡献:论文提出了BLAST(BaLanced Sampling Time series corpus),构造了一个时间序列预训练语料库,通过平衡采样策略增强数据多样性,提升通用时间序列预测模型的性能。
预分析
01 数据集层面的不平衡分布
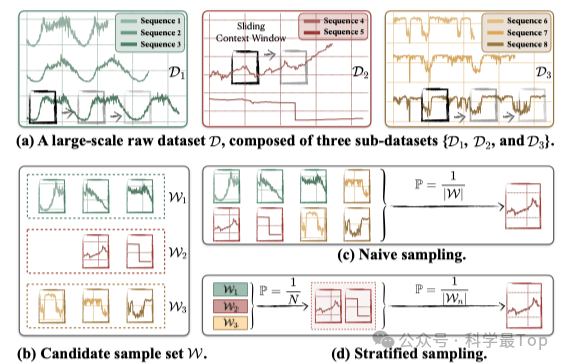
如图1所示,现有数据集存在严重的子数据集不平衡问题。图1(a)展示了来自同一领域(交通领域)的不同数据集(𝒟₁和𝒟₃)却表现出截然不同的模式(pattern),而同一数据集𝒟₂内的不同时间序列也显示出显著差异。这种复杂性表明,仅依靠数据集或领域标签来区分时间序列模式是不够可靠的。
图1(c)和(d)进一步对比了两种常见但不完善的采样策略:朴素采样(Naive Sampling):从所有子数据集中均匀选择样本(图1c)分层采样(Stratified Sampling):先选择子数据集,再从子数据集中选择样本(图1d)。
02 序列长度与样本量的不平衡
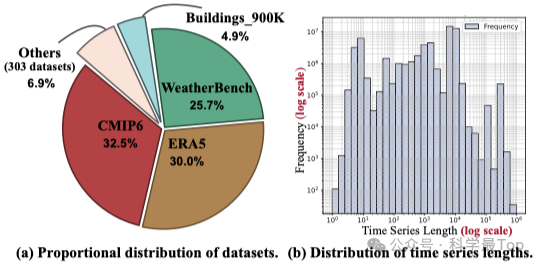
图2通过两个子图更直观地展示了原始数据的不平衡分布,图2(a)显示仅三个数据集就占据了总数据量的88.2%,显示出极端的数据集层面不平衡。图2(b)表明长序列倾向于贡献更多样本,导致序列长度层面的不平衡。这种偏斜分布会导致原始数据中出现大量重复模式,损害整体数据多样性。
03 现有采样方式的不足
|-----------------------------------------------------------------------------------|-----------------------------------------------------------------------------------|
|  |
|  |
|
BLAST方法设计
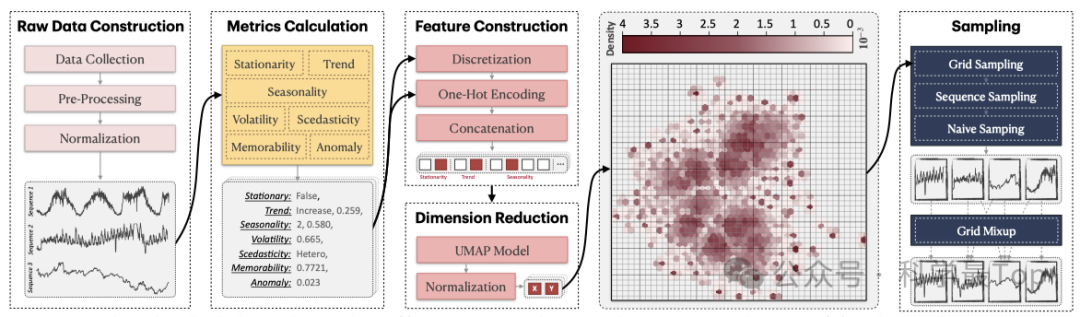
BLAST采用四阶段流程来构建平衡的时间序列预训练语料库,如图3所示。该方法的核心在于将传统基于数据集/领域标签的采样方式转变为基于数据模式特征的智能采样策略。
-
第一阶段通过整合3210亿观测点的公开数据集构建基础语料库,并采用严格的缺失值处理和长度过滤机制。
-
第二阶段创新性地使用7类统计指标(包括平稳性、趋势强度、季节性和波动性等)全面刻画时间序列特征,克服了传统方法仅依赖单一特征的局限性。
-
第三阶段通过特征离散化和UMAP降维技术,将高维统计特征投影到二维空间,直观揭示数据分布的不平衡性。
-
第四阶段提出的网格采样与网格混合技术是方法的核心创新:将特征空间划分为100×100网格,以网格为单元进行均衡采样,同时引入k=3的网格混合策略,通过Dirichlet分布(α=1.5)生成混合系数,有效填补数据分布中的空白区域,确保各种模式都能得到充分表征。
结果分析
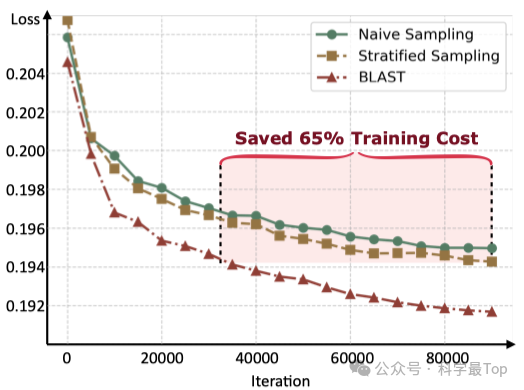
实验结果表明,BLAST方法在训练效率和模型性能方面均取得了显著提升。如下图所示,采用BLAST平衡采样策略的模型展现出更快的收敛速度和更低的验证损失。在训练后期阶段,平衡采样仅需约35%的训练步数即可达到与朴素采样或分层采样相当的损失水平,大幅提升了训练效率。
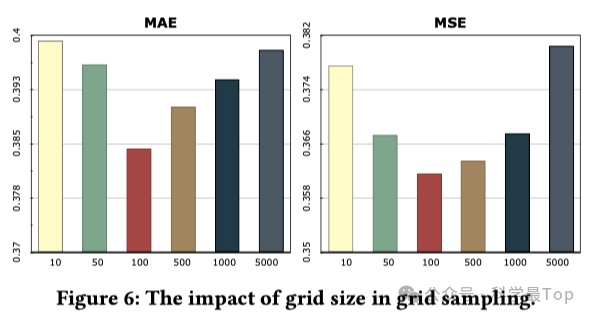
网格采样与混合技术的优化效果。下图展示了网格大小对模型性能的影响,揭示了网格划分的关键平衡点。当网格尺寸设定为100×100时达到最佳效果,既避免了网格过大导致的模式混杂问题(如单一网格情况退化为朴素采样),又防止了网格过小导致的样本稀疏问题。这一发现为时间序列数据采样提供了重要的超参数设置指导。
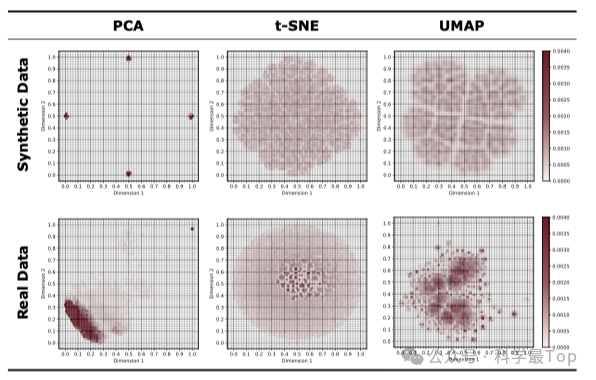
降维方法的比较与选择。下表对比了三种降维技术的表现,证实UMAP在保持全局结构完整性和局部模式区分度方面的优势。UMAP不仅计算效率优于t-SNE,还能更好地保持原始特征空间的拓扑结构,为后续的网格划分提供了更可靠的基础。这一选择确保了模式聚类的准确性,是BLAST方法成功的关键因素之一。
总结与评价
这篇论文提出的BLAST方法确实让人眼前一亮!论文作者敏锐的抓住了时间序列预测领域一个被长期忽视的关键问题------数据多样性不足。通过平衡采样策略,解决了大规模时间序列数据中的模式不平衡问题,还大幅提升了模型的训练效率和预测性能。
其中有一点,BLAST仅用1/16的计算资源(8块A100 vs 128块)和不到1/5的训练token(78.64亿 vs 419.43亿),就超越了原有模型的性能。此外,论文的实验设计也很扎实,特别是将复杂的统计特征转化为直观的二维可视化,比较具有可读性。
推荐阅读~
**大家可以关注我【科学最top】,第一时间follow时序高水平论文解读!!!**获取时序论文合集
