解锁全球旅游数据:动态代理+AI智能推荐实战
引言
你是否也遇到过这些旅行规划的痛点?
计划出国游时,想在Booking、TripAdvisor等国外主流网站查找真实、最新的景点和酒店信息,却经常陷入这样的困境:网页加载缓慢或直接无法访问,多次弹出验证码干扰浏览,甚至IP被管理。更令人沮丧的是,免费代理极其不稳定,数据爬取过程举步维艰。
这些反爬机制让我们不禁思考:如何稳定、大规模地获取这些宝贵的"外部"真实数据,来弥补AI大模型信息可能存在的滞后性或"幻觉"?
本文将介绍一个强大的技术组合------IPIDEA动态代理 + Python + AI,带你亲手打造一个能智能推荐景点的数据采集工具。
方案一:动态代理服务
●亿级纯净代理IP池:拥有全球数以1亿+的住宅IP,IP自动切换,有效被管理
●高匿名性与真实性:使用来自真实用户的住宅IP,使得爬虫行为更像普通用户访问,降低被反爬机制识别的风险
●高并发与稳定性:支持高并发请求,保障大规模数据采集任务的顺利进行
●精准地域数据:可以使用州/省、国家/地区、城市和 ASN 级别的定位,获取真实数据

方案二:网页抓取API
对于希望更简单高效获取数据的开发者,IPIDEA还提供了直接的网页抓取API,只需简单调用即可获取已解析的网页数据,大大简化了开发流程。

实战准备:
1.注册与登录:访问IPIDEA官网,完成账号注册和登录
2.白名单:添加白名单
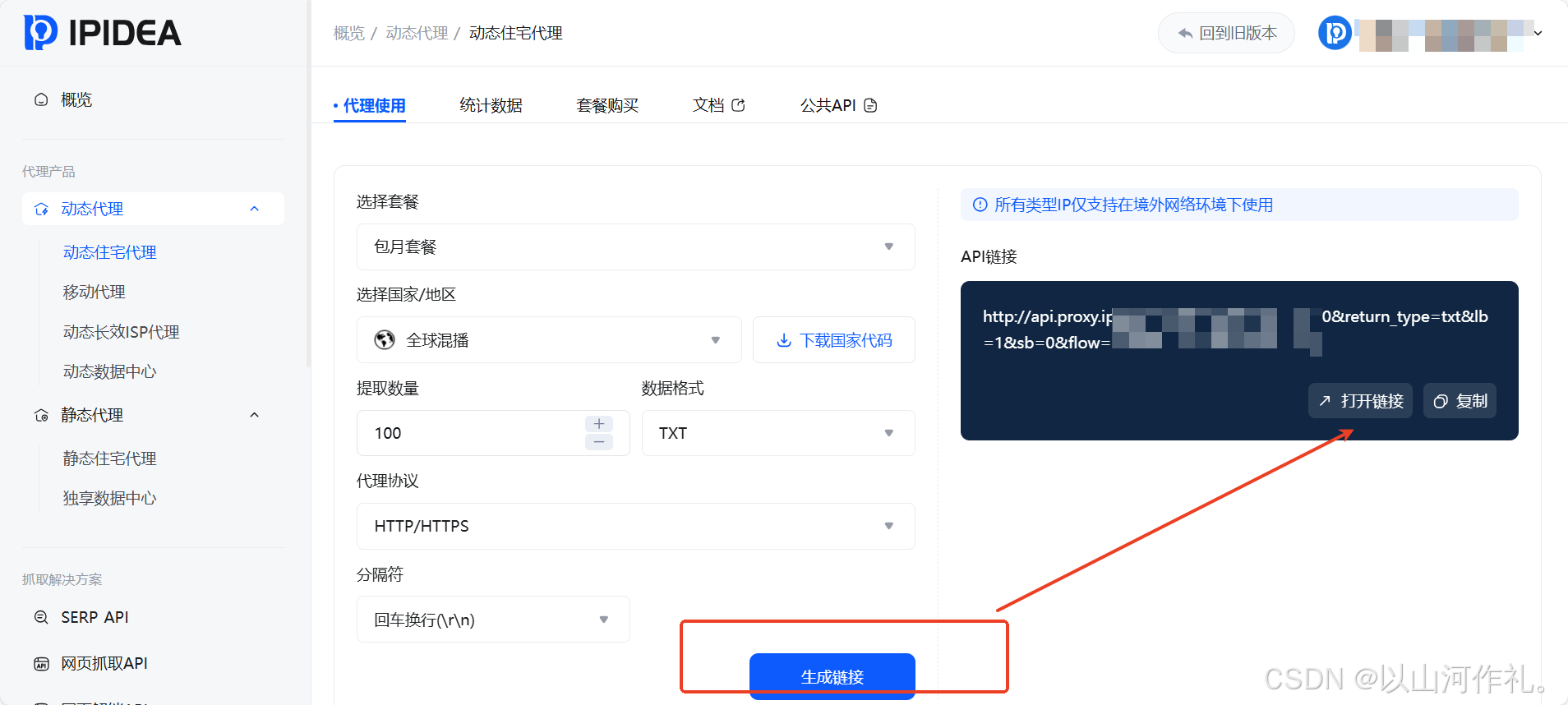
3.选择方案:根据需求选择动态代理或网页抓取API服务
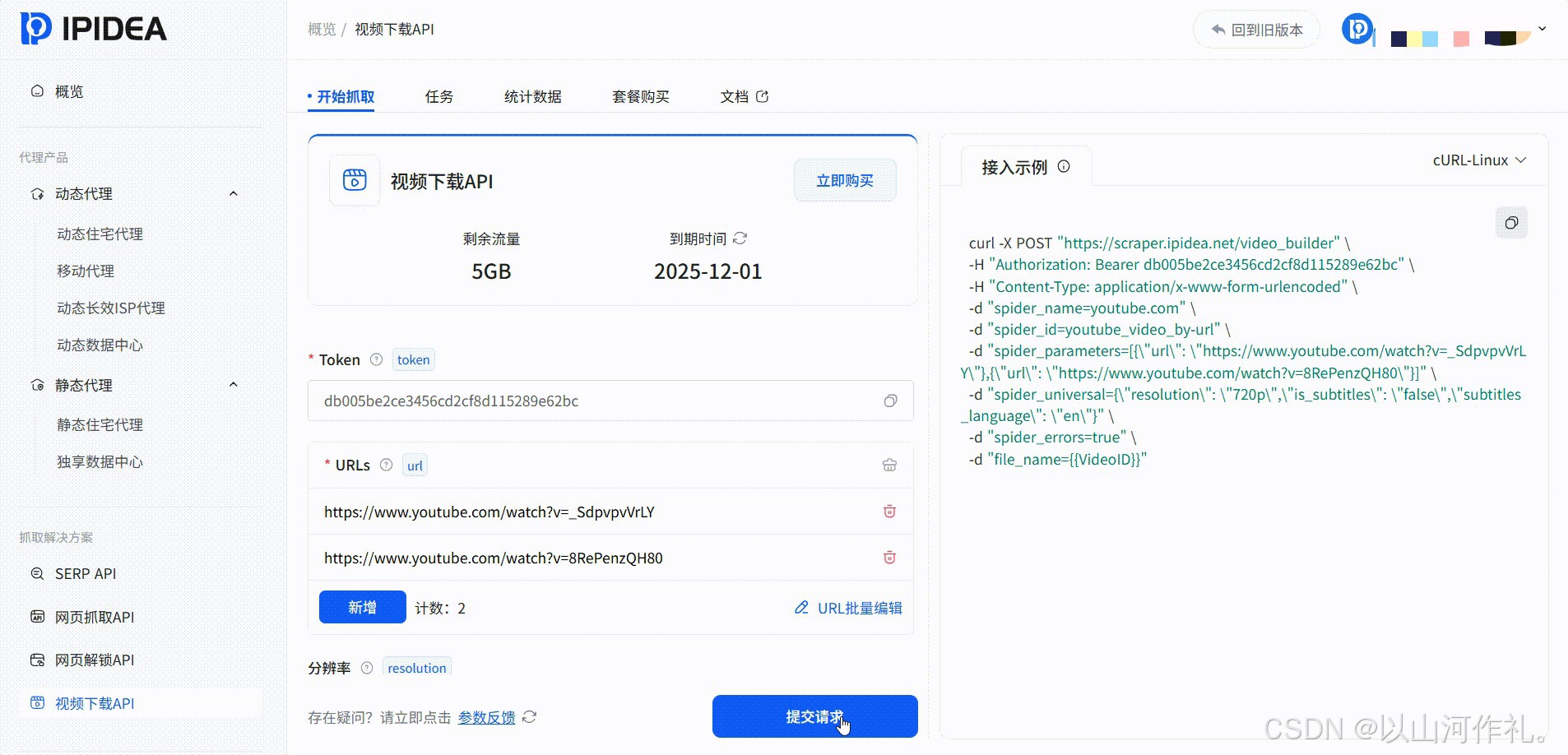
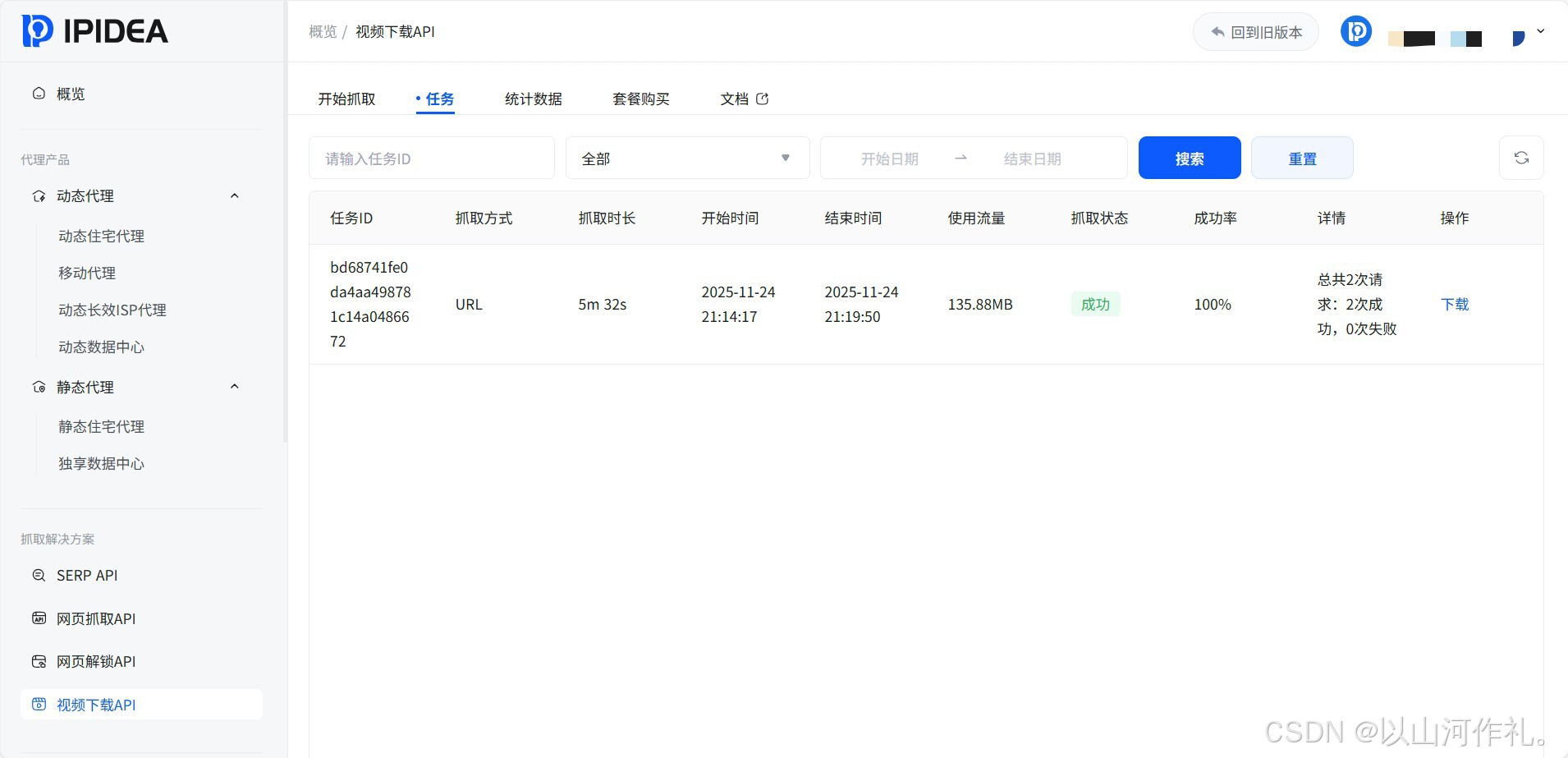
项目实战:构建可视化旅游信息智能推荐工具
我们的目标是创建一个GUI窗口,用户输入目的地后,工具自动爬取Booking.com的景点信息,并由AI进行总结和推荐。
技术栈选择:
●IPIDEA动态代理/网页抓取API:解决IP管理问题
●requests + BeautifulSoup4:处理HTTP请求和HTML解析
●OpenAI API:进行智能分析和内容生成
●Tkinter:构建图形用户界面
核心代码逻辑分步解析:
首先,我们配置IPIDEA代理:
python
def fetch_dynamic_proxies(self, num=10, protocol='http'):
"""从IPIDEA获取动态代理IP"""
api_url = f"http://api.proxy.ipidea.io/getProxyIp?num={num}&return_type=json&lb=1&sb=0&flow=1&protocol={protocol}"
try:
response = requests.get(api_url, timeout=30)
response.raise_for_status()
data = response.json()
if data.get('code') == 0:
self.proxy_pool = data.get('data', [])
return self.proxy_pool
else:
print(f"获取代理失败: {data.get('msg')}")
return []
except Exception as e:
print(f"获取动态代理失败: {e}")
return []
def get_random_proxy(self):
"""获取随机代理"""
if not self.proxy_pool:
self.fetch_dynamic_proxies()
if self.proxy_pool:
proxy = random.choice(self.proxy_pool)
if self.username and self.password:
return f"http://{self.username}:{self.password}@{proxy['ip']}:{proxy['port']}"
else:
return f"http://{proxy['ip']}:{proxy['port']}"
return None对于选择网页抓取API的开发者,代码更加简洁:
python
import http.client
from urllib.parse import urlencode
conn = http.client.HTTPSConnection("unlock.ipidea.net")
payload = {
"url": "https://www.google.com",
"type": "html",
"js_render": "true"
}
form_data = urlencode(payload)
headers = {
'Authorization': "Bearer ",
'content-type': "application/x-www-form-urlencoded"
}
conn.request("POST", "/request", form_data, headers)
res = conn.getresponse()
data = res.read()
print(f"Status: {res.status} {res.reason}")
print(data.decode("utf-8"))接下来是数据采集和解析的核心逻辑:
python
def scrape_booking_data(destination):
try:
url = f"https://www.booking.com/search.html?ss={destination}"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
response = requests.get(url, headers=headers, proxies=proxies, timeout=30)
soup = BeautifulSoup(response.content, 'html.parser')
attractions = []
listings = soup.find_all('div', {'data-testid': 'property-card'})
for listing in listings[:10]: # 限制前10个结果
name_elem = listing.find('div', {'data-testid': 'title'})
rating_elem = listing.find('div', {'class': 'b5cd09854e d10a6220b4'})
location_elem = listing.find('span', {'data-testid': 'address'})
if name_elem:
attraction = {
'name': name_elem.text.strip(),
'rating': rating_elem.text.strip() if rating_elem else '无评分',
'location': location_elem.text.strip() if location_elem else '位置未知'
}
attractions.append(attraction)
return attractions
except Exception as e:
print(f"数据采集失败: {str(e)}")
return []然后是AI智能分析模块:
python
def ai_analysis(attractions_data):
if not attractions_data:
return "未能获取到有效数据"
prompt = f"""
请根据以下景点信息,筛选出评分8.0以上且评论正面的景点,
生成一个推荐列表,包含名称、评分和推荐理由:
{attractions_data}
请以清晰易读的格式回复,突出每个景点的特色。
"""
# 这里调用AI API(以OpenAI格式为例)
try:
# client = OpenAI(api_key="your-api-key")
# response = client.chat.completions.create(...)
# return response.choices[0].message.content
# 模拟返回结果
return "1. 中央公园 - 评分: 9.2 - 推荐理由: 纽约最大的城市公园,适合休闲散步\n2. 帝国大厦 - 评分: 8.8 - 推荐理由: 经典地标,观景台视野极佳"
except Exception as e:
return f"AI分析失败: {str(e)}"最后构建GUI界面:
python
class TravelRecommendationApp:
def __init__(self, root):
self.root = root
self.root.title("智能旅游推荐工具")
self.root.geometry("600x400")
self.setup_ui()
def setup_ui(self):
# 创建输入框和按钮
tk.Label(self.root, text="请输入目的地:", font=("Arial", 12)).pack(pady=10)
self.entry = tk.Entry(self.root, width=50, font=("Arial", 10))
self.entry.pack(pady=5)
self.search_btn = tk.Button(self.root, text="开始搜索",
command=self.start_search,
bg="#4CAF50", fg="white", font=("Arial", 10))
self.search_btn.pack(pady=10)
# 结果显示区域
self.result_text = tk.Text(self.root, height=15, width=70, font=("Arial", 10))
self.result_text.pack(pady=10, padx=10, fill=tk.BOTH, expand=True)
def start_search(self):
destination = self.entry.get().strip()
if not destination:
return
self.result_text.delete(1.0, tk.END)
self.result_text.insert(tk.END, "正在通过IPIDEA代理连接...\n")
self.root.update()
# 执行数据采集
attractions_data = scrape_booking_data(destination)
self.result_text.insert(tk.END, f"成功获取{len(attractions_data)}个景点信息\n")
self.result_text.insert(tk.END, "正在请求AI进行智能推荐...\n")
self.root.update()
# AI分析推荐
recommendations = ai_analysis(attractions_data)
self.result_text.insert(tk.END, "\n=== AI智能推荐结果 ===\n\n")
self.result_text.insert(tk.END, recommendations)
if __name__ == "__main__":
root = tk.Tk()
app = TravelRecommendationApp(root)
root.mainloop()效果演示:
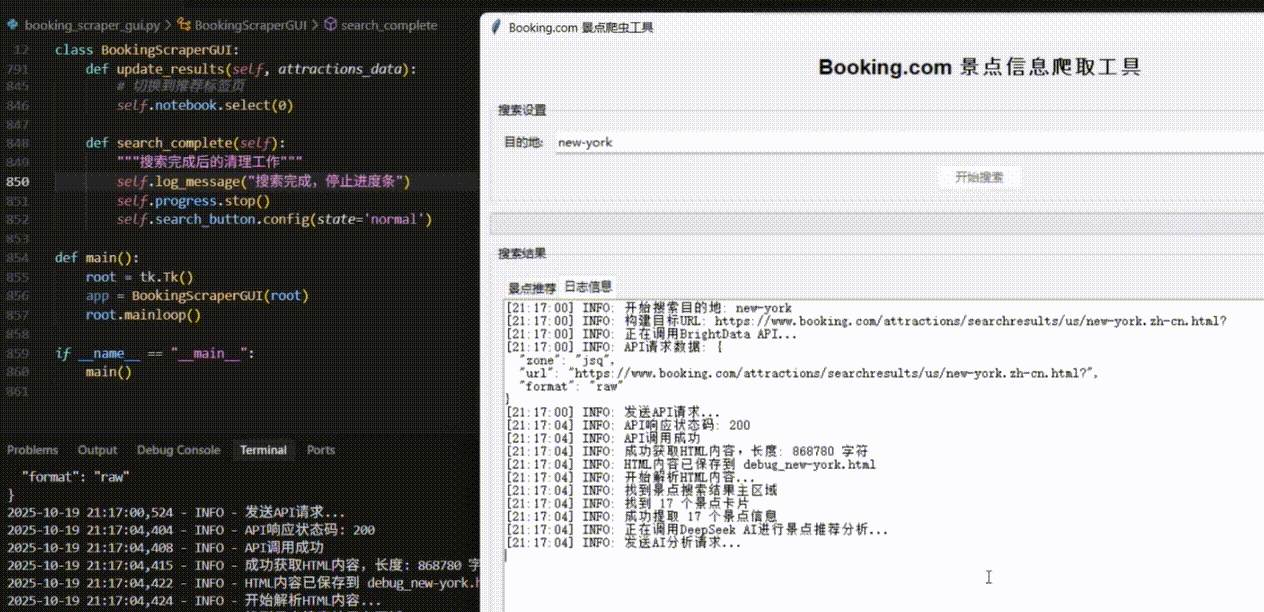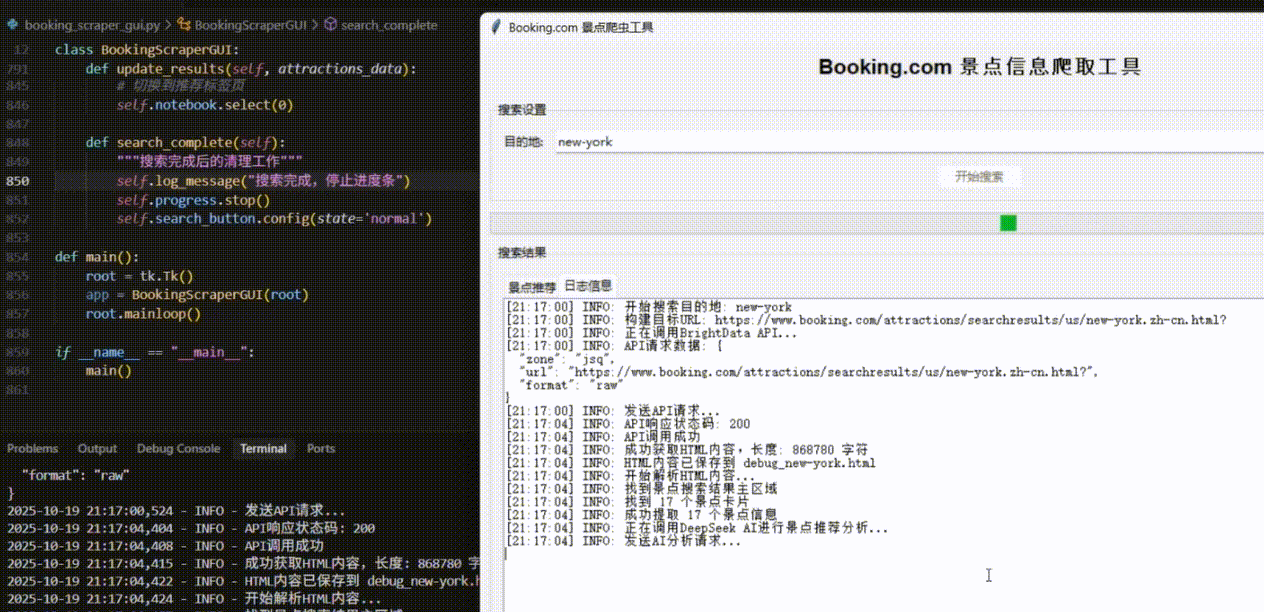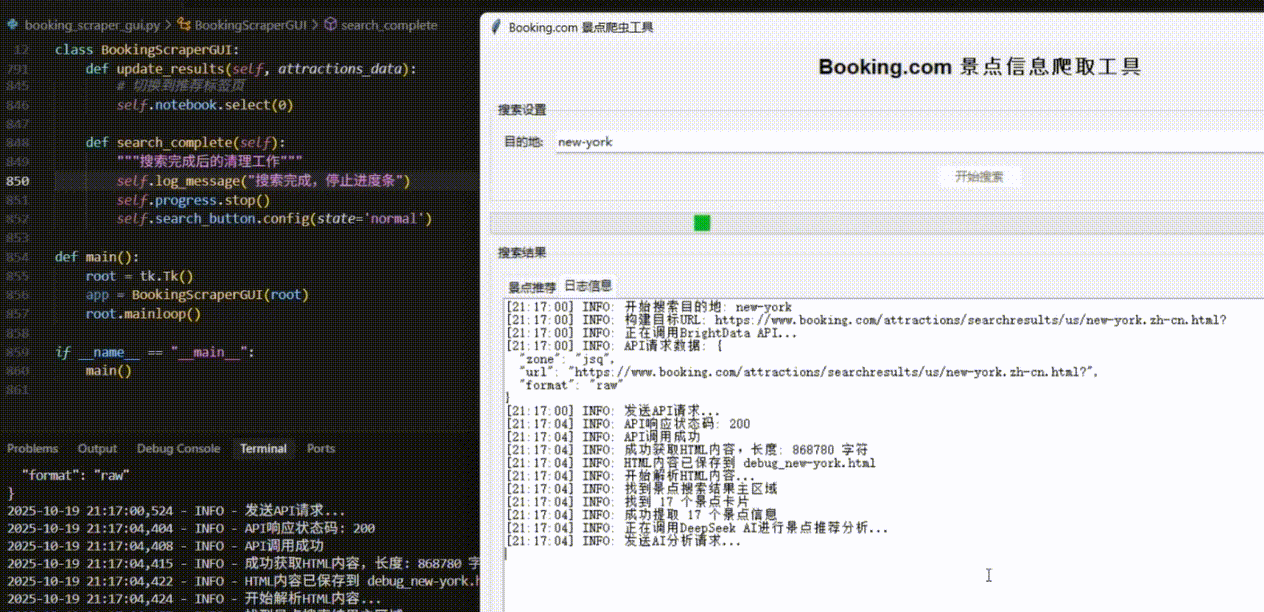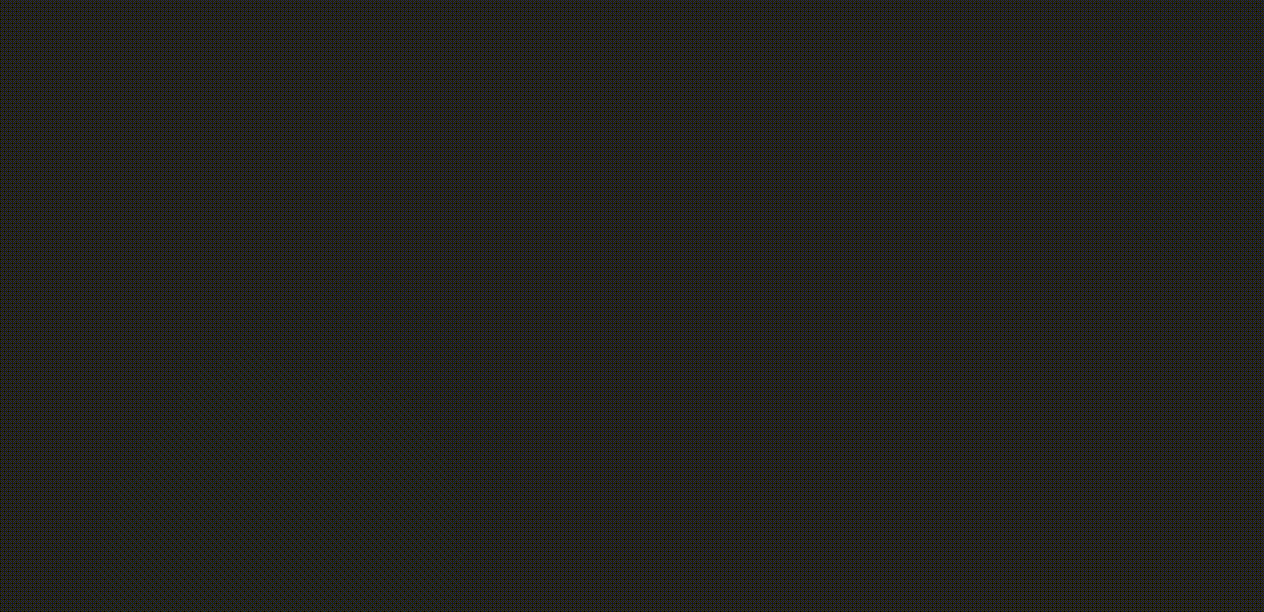
当我们运行这个Python脚本时,会弹出一个简洁的GUI窗口。在输入框中键入"纽约",点击"开始搜索"按钮,后台开始执行一系列操作:
首先显示"正在通过IPIDEA代理连接...",接着是"成功获取页面..."、"数据解析中..."、"正在请求AI进行智能推荐..."等实时日志。
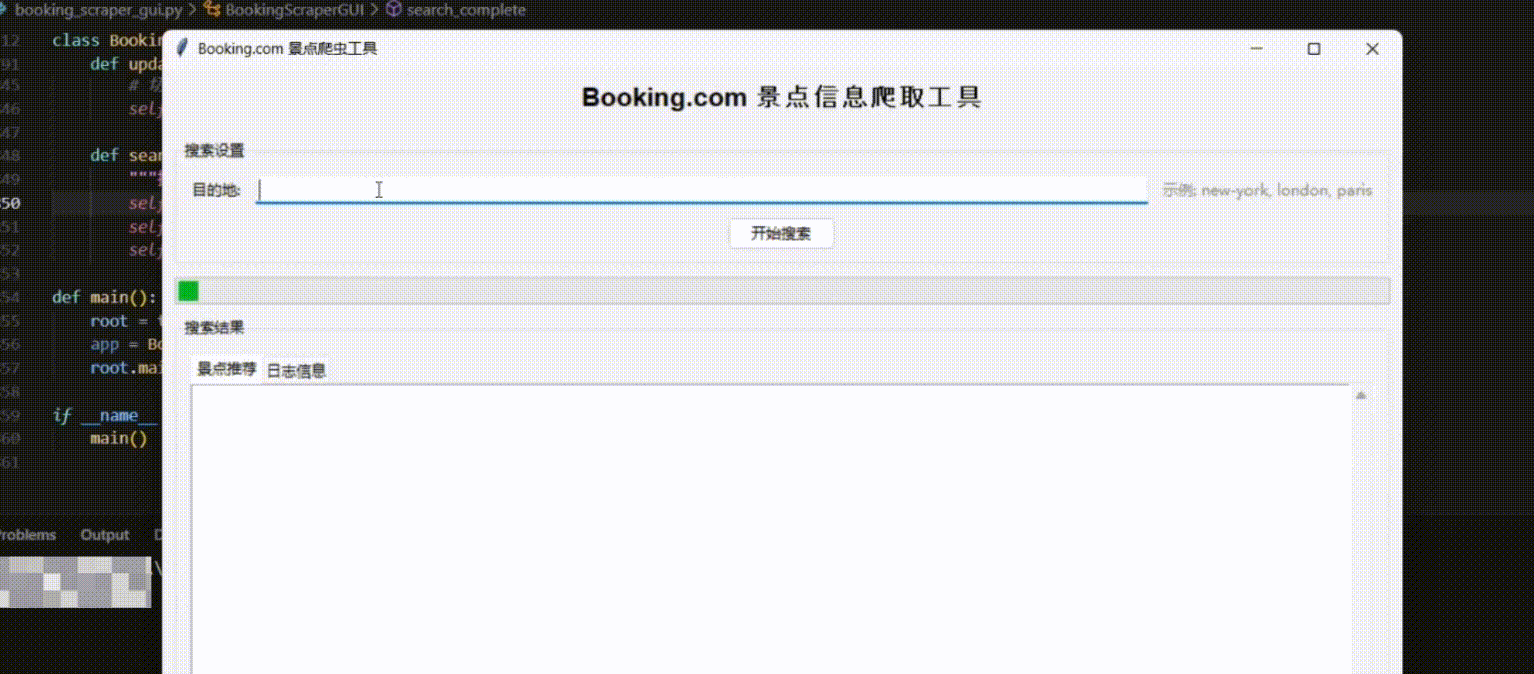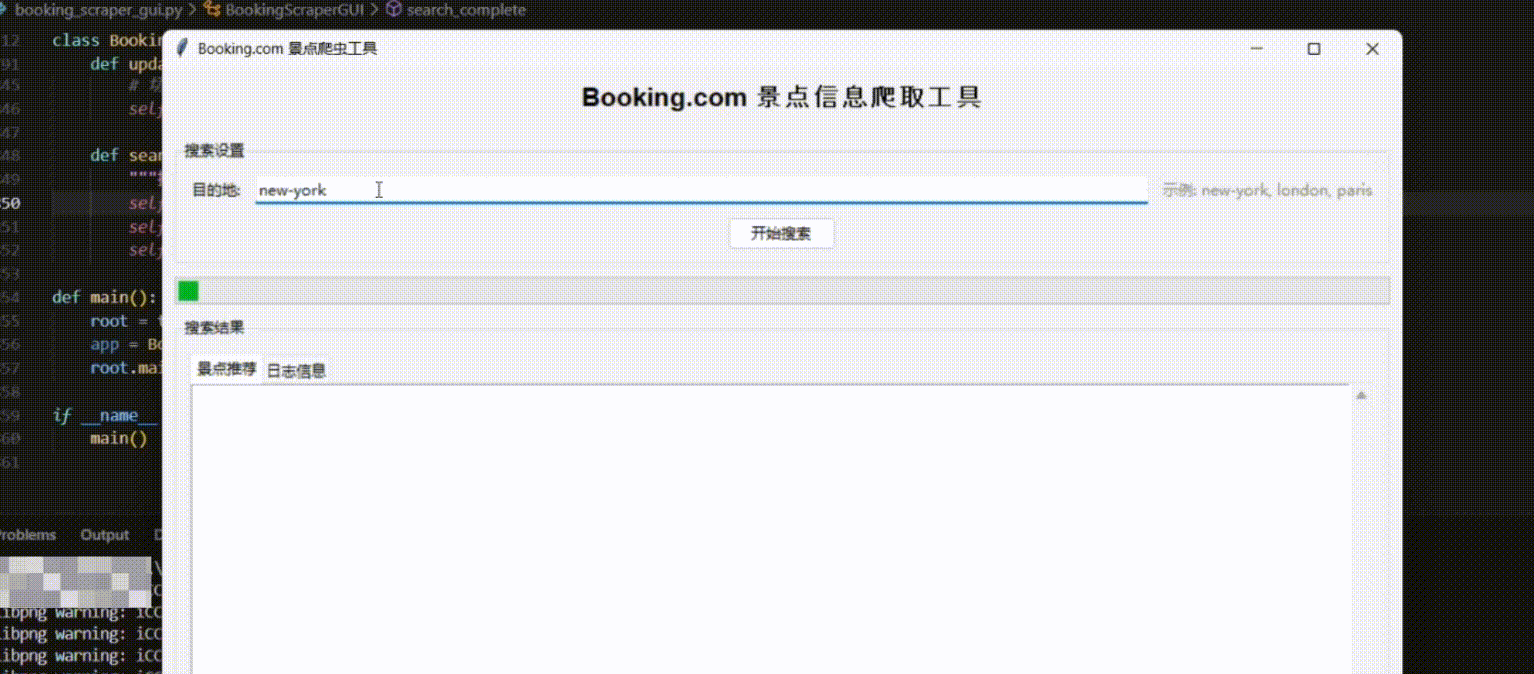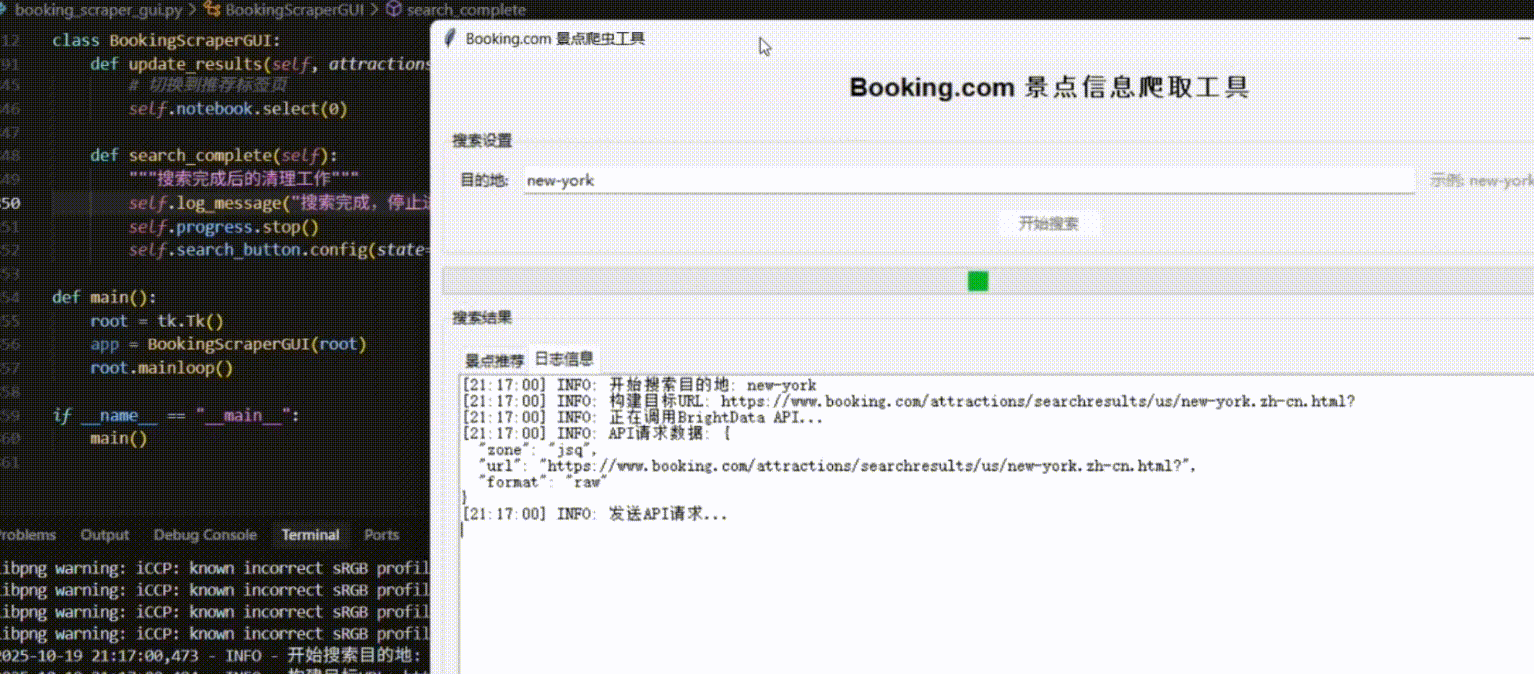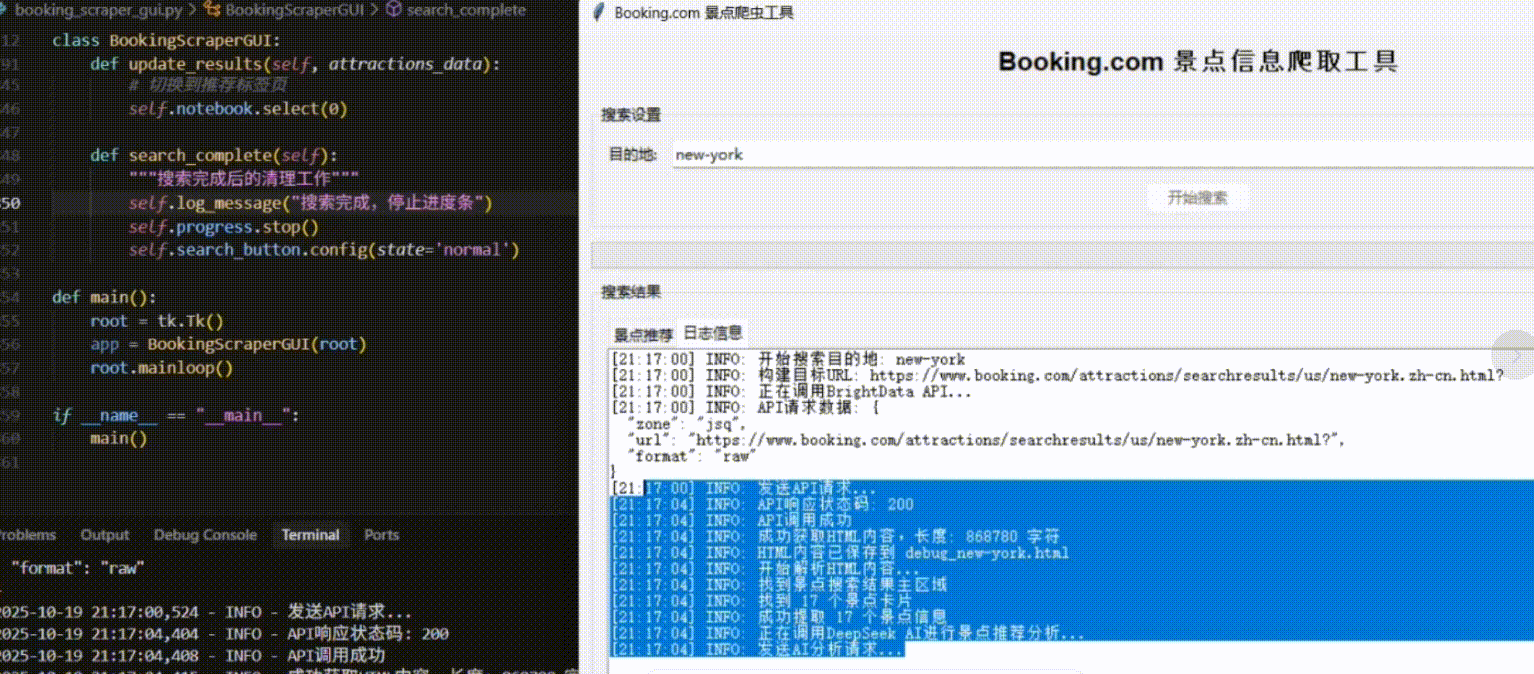
最终,窗口内清晰地展示出AI推荐的纽约景点列表,包括中央公园、帝国大厦等地标,每个都附有评分和详细的推荐理由。
总结与展望
通过本项目的实践,我们全面验证了IPIDEA解决方案在采集复杂国际网站数据时所表现出的良好稳定性与实效性。无论是通过智能动态代理系统有效应对地域与访问管理,还是借助高效可扩展的网页抓取API应对不同站点结构,再结合AI驱动的信息抽取与语义分析技术,我们成功实现了从海量原始数据到高价值、结构化数据的转化,可直接用于业务决策的深度洞察。
这一流程不仅显著提升了数据获取的覆盖面和实时性,也确保了信息处理的准确性与可解释性。展望未来,我们将持续优化数据采集策略与智能解析模型,进一步拓展支持的数据源类型与行业场景,助力企业在跨境市场洞察、竞争情报监测、价格动态监控等领域实现数据驱动的精细化管理与战略布局。欢迎进一步尝试与合作,共同开启您的高效数据洞察之旅。