1. 大模型微调技术的发展与演进
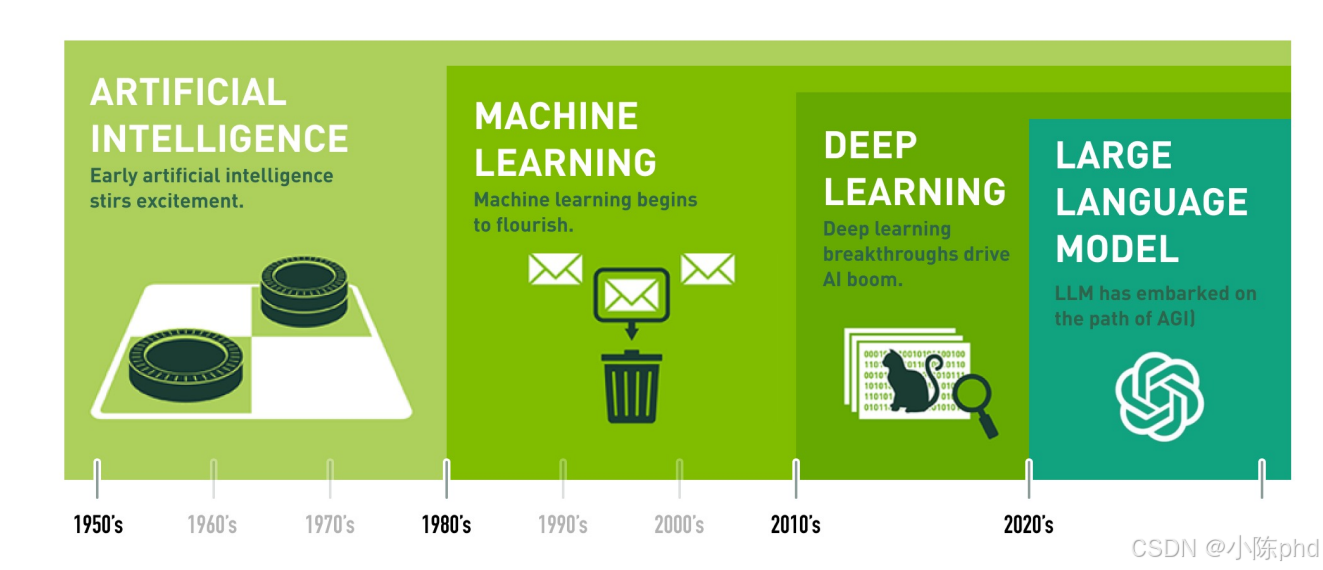
1.1 AI发展的四个核心阶段
- 早期AI(1950s-70s):符号主义+规则驱动,达特茅斯会议定义AI,后陷"寒冬"。
- 机器学习(1980s-2000s):数据驱动+统计学习,算法(SVM)成熟,初现商业化。
- 深度学习(2010s):深度神经网络+GPU算力,AlexNet、AlphaGo推动AI大规模应用。
- 大语言模型(2020s至今) :超大规模参数+多模态,ChatGPT/GPT-4迈向通用智能(AGI)雏形。
1.2 模型是什么
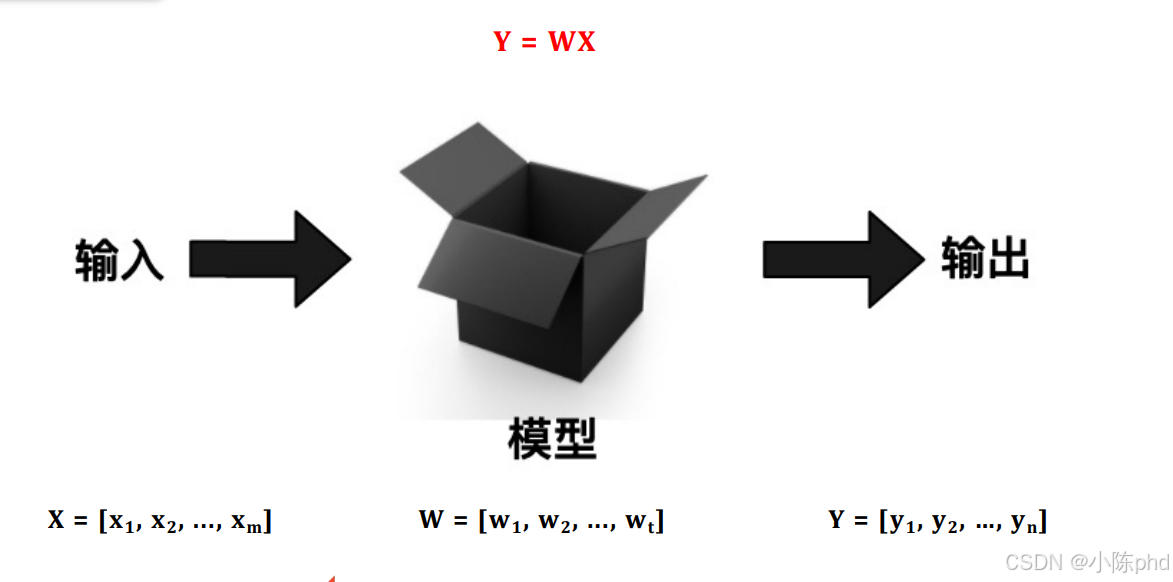
1.3 大模型大在哪里?
大模型(以 LLaMA-65B 为代表)是参数规模超十亿级的 AI 模型,核心特点是 "大参数 + 大数据训练":
它通过海量数据(文本、图像等)学习通用规律,能处理复杂任务(如对话、创作、推理);
对比传统模型(如 ResNet50 仅 2500 万参数),大模型参数量(650 亿)和内存需求(780GB)呈指数级增长,代价是更高算力成本,但能实现更强的泛化能力与智能表现。

1.4 为什么需要微调?
- 预训练成本高(780GB 显存)→ 基础大模型无法为每个场景重新训练,微调是 "低成本适配场景" 的方式;
- 提示工程有天花板→ 仅靠提示词无法满足复杂 / 专业任务(如医疗诊断),微调能让模型 "固化" 领域能力;
- 缺少特定领域数据→ 预训练数据是通用的,微调可注入行业数据(如金融、法律),提升领域精度;
- 数据安全和隐私→ 直接用公共大模型会泄露敏感数据,私有化微调能在本地环境适配,保障数据安全;
- 个性化服务需求→ 不同企业 / 用户需要定制化功能(如企业专属客服话术),微调实现 "专属模型"。
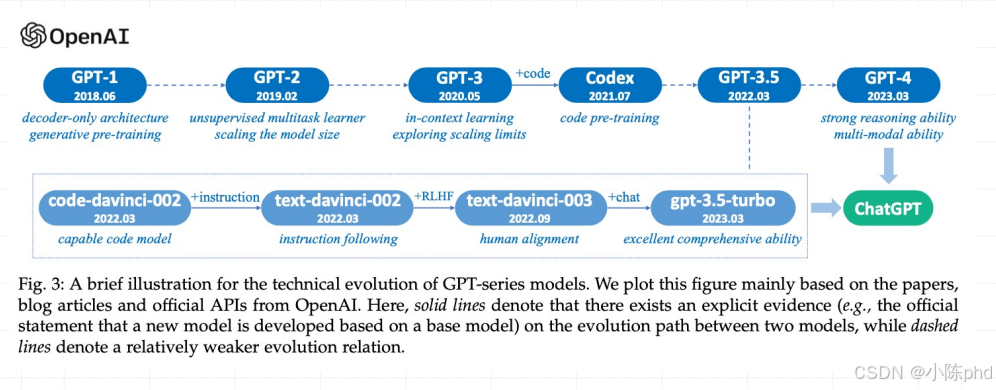
GPT 系列模型迭代:预训练+微调
1.5 大模型微调技术路线
- 全量微调(Full Fine-Tune, FFT),训练成本高,灾难性遗忘
- 高效微调(Parameter-Efficient Fine-Tune, PEFT)
- 有监督微调(Supervised Fine-tune, SFT)
- 基于人类反馈的强化学习(RLHF)
- 基于AI反馈的强化学习(RLAIF)
1.6 PEFT主流技术方案
- 围绕 Token 做文章:语言模型(PLM)不变
- Prompt Tuning (提示词向量引导多类型任务)
- Prefix Tuning
- P-Tuning
- 特定场景任务:训练"本质"的低维模型
- LoRA
- QLoRA
- AdaLoRA
- 新思路:少量数据、统一框架
- IA3
- UniPELT
1.6.1 Prompt Tuning
Prompt Tuning 是 "低成本、高性能" 的大模型适配方案,用极小的提示参数就能达到接近全量微调的效果,同时避免参数冗余。
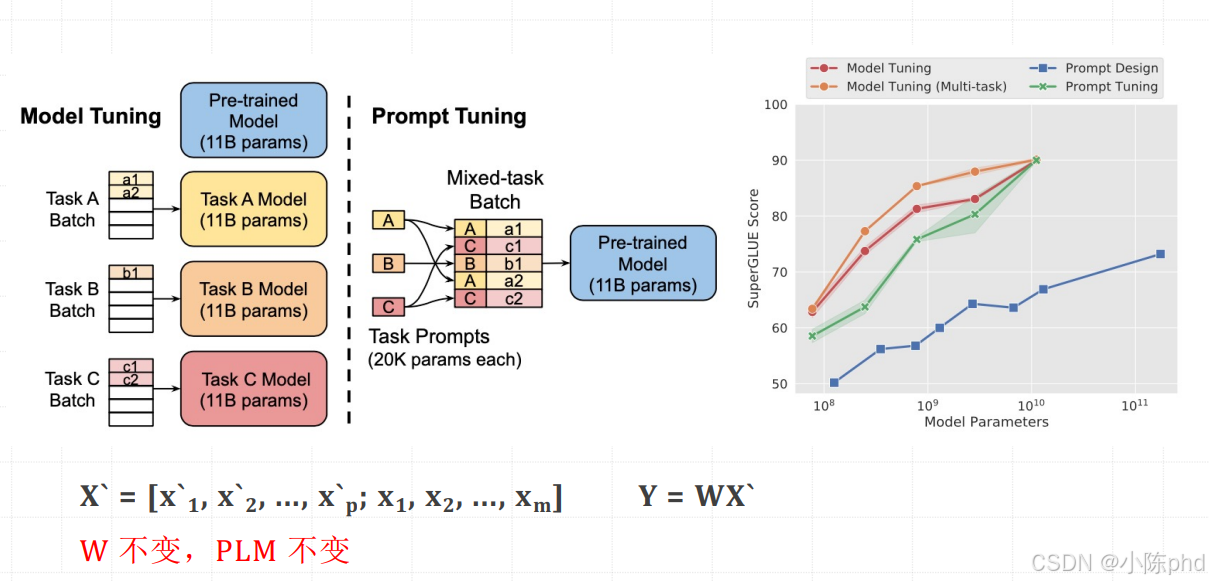
1.6.2 Prompt Tuning
该方法灵感源于提示工程(Prompting),但解决了传统提示是固定离散文本、无法优化的问题。它会在输入序列前插入一组连续的向量作为 "虚拟词" 前缀,这些前缀向量会融入 Transformer 每一层自注意力机制的键(Key)和值(Value)计算中,成为模型生成输出时的重要上下文依据。训练时仅优化这组前缀的参数,原始模型的海量参数保持冻结,相当于给同一个模型搭配不同 "任务专属引导器" 来适配多场景。
- Prompt Tuning:仅在输入序列的 token 层(嵌入层之前)插入可学习的虚拟 token。这些虚拟 token 属于词表中的特殊标识,其影响仅停留在输入端,后续只能依靠模型自身的自然传播来作用于后续计算环节,无法直接干预模型内部层的运行。
- Prefix Tuning:会在 Transformer 每一层的键(Key)和值(Value)矩阵前插入前缀向量。该前缀是与任何词表 token 都不对应的纯向量,能直接干预模型每一层的注意力机制,从深层调控模型的计算过程,影响更直接且深入。
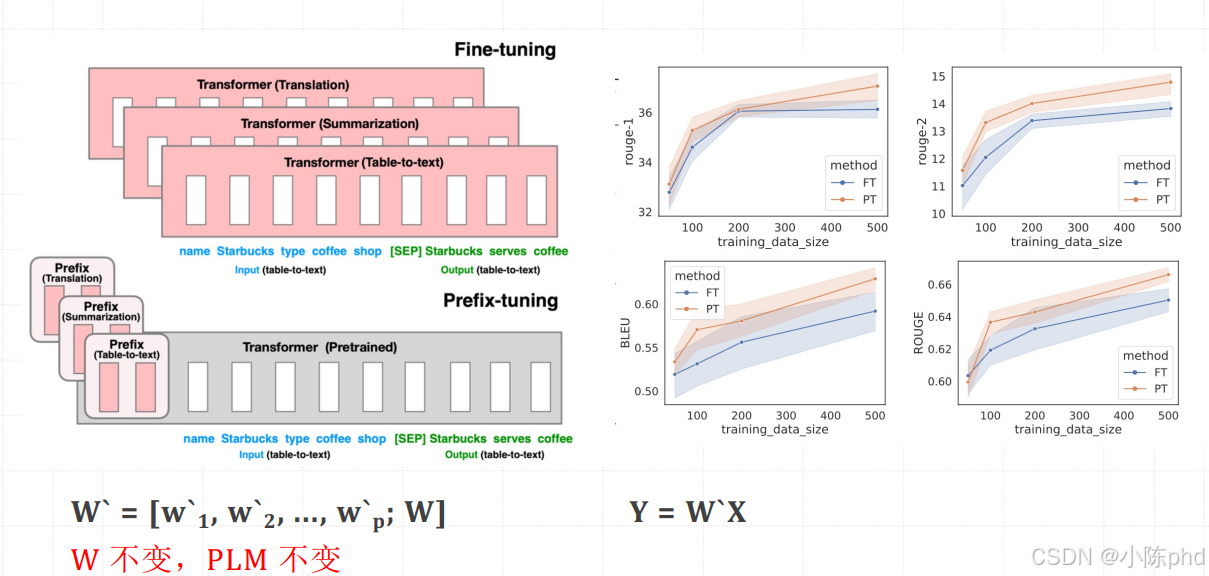
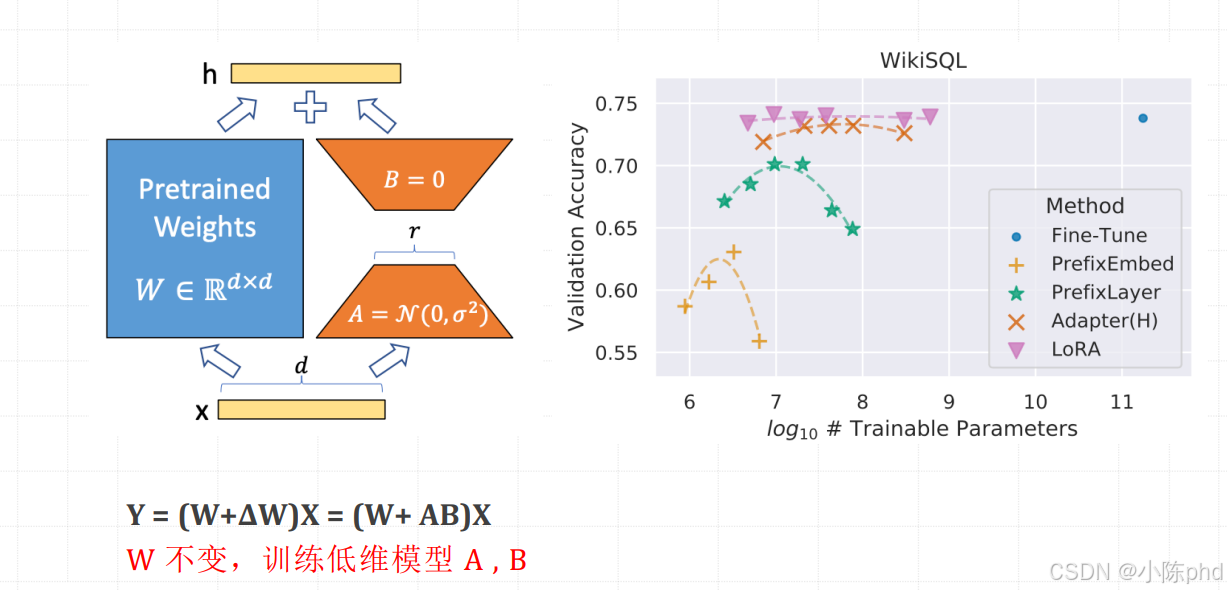
1.6.3 LoRA
LoRA(Low-Rank Adaptation of Large Language Models)是由微软团队 2021 年提出的参数高效微调(PEFT)方法,核心思想是通过 "低秩矩阵分解" 大幅降低微调参数量,同时冻结大模型原始参数,在兼顾微调效果的前提下,极大降低计算和存储成本,现已成为 LLM 微调的主流方案(如 Llama/GLM/GPT 系列均广泛适配)。
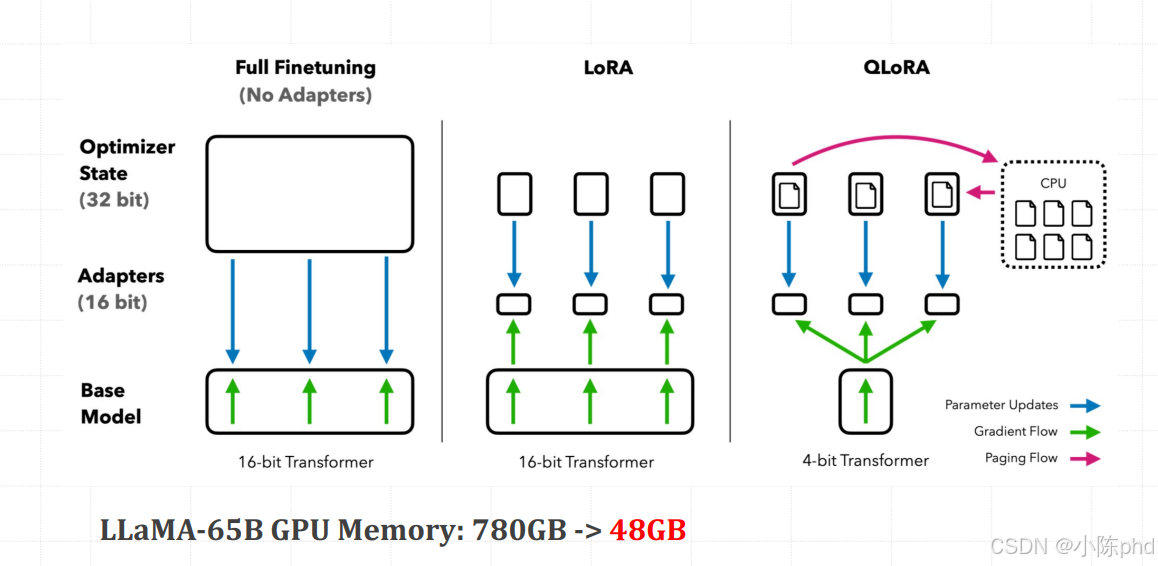
1.6.4 QLoRA
QLoRA(Quantized LoRA)是由华盛顿大学团队 2023 年提出的低精度量化版 LoRA,核心是在 LoRA 基础上引入 4-bit/8-bit 量化技术,进一步降低大模型微调的显存占用,让普通消费级显卡(如 RTX 4090/3090)能高效微调 7B/13B/70B 甚至更大的 LLM,同时几乎不损失微调效果。
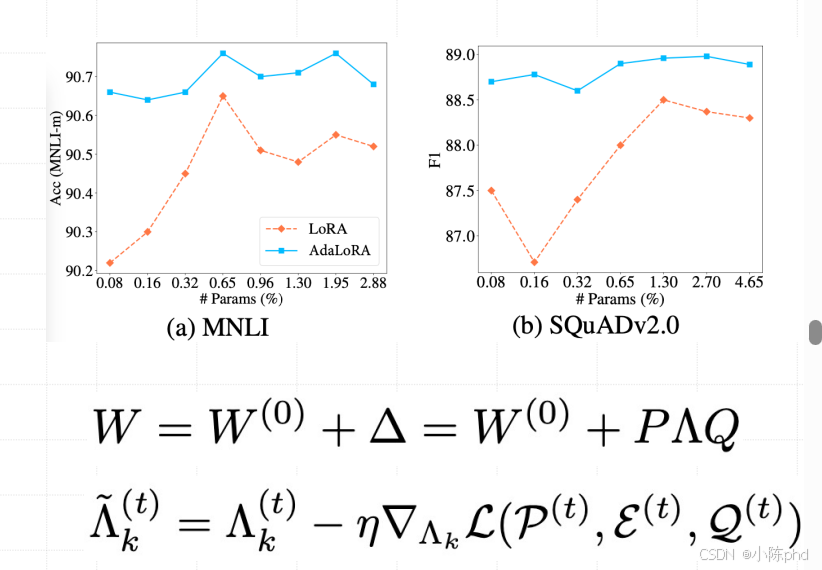
1.6.5 AdaLoRA
AdaLoRA(Adaptive LoRA)是对经典 LoRA 的自适应改进版,由清华大学 & 字节跳动团队 2023 年提出,核心解决了传统 LoRA"固定低秩维度(r)对所有层 / 任务均一化" 的问题 ------ 通过动态调整不同层、不同 token 的 LoRA 秩分配,在保持极低参数量的同时,进一步提升微调效果,尤其适配复杂任务(如长文本生成、多模态、复杂对话)。AdaLoRA 是 LoRA 的 "智能升级版"------ 通过分层自适应秩分配 + 稀疏更新,在保持 LoRA 参数高效、无推理开销的核心优势下,进一步提升复杂任务的微调效果。相比传统 LoRA,它更适配大模型、复杂任务,但实现复杂度略高(需自定义秩分配逻辑);相比 Prefix/Prompt Tuning,它仍保留 "无推理延迟、显存占用低" 的优势,是工业界微调大模型的下一代优选方案。
2. 大模型微调开源框架与工具

3. 国产化大模型技术栈的重要性
4. 大模型微调技术未来的趋势与挑战
- 架构创新的复杂性:设计能够超越Transformer的新架构将面临巨大的技术挑战,特别是在保持或提高效率和效果的同时减少计算资源需求。
- 适应新架构的微调技术:随着基础架构的变化,现有的微调技术可能需要重大调整或重新设计,以适应新的模型架构。
- 模型可解释性:新的架构可能会带来更复杂的模型内部结构,这可能会进一步加剧模型可解释性和透明度的问题。
- 迁移学习的挑战:新架构可能会使得从旧模型到新模型的迁移变得更加困难,特别是在保留已有知识和经验方面。
- 伦理和社会责任:新架构可能会在不同程度上放大或缓解目前模型的偏见和不平等问题,如何确保技术的公正性和负责任使用将持续是一个挑战。