目录
引入Sqoop

在Hadoop早期,如果想把MySQL里一张上亿记录的表导入HDFS做大数据分析,开发人员需要手动编写MapReduce程序,通过JDBC读取数据再写入,过程繁琐且性能受限。
Sqoop的诞生,就是为了自动化并高效地完成这种结构化的批量数据迁移,它是Hadoop生态与关系型数据库之间的桥梁。
Sqoop定义
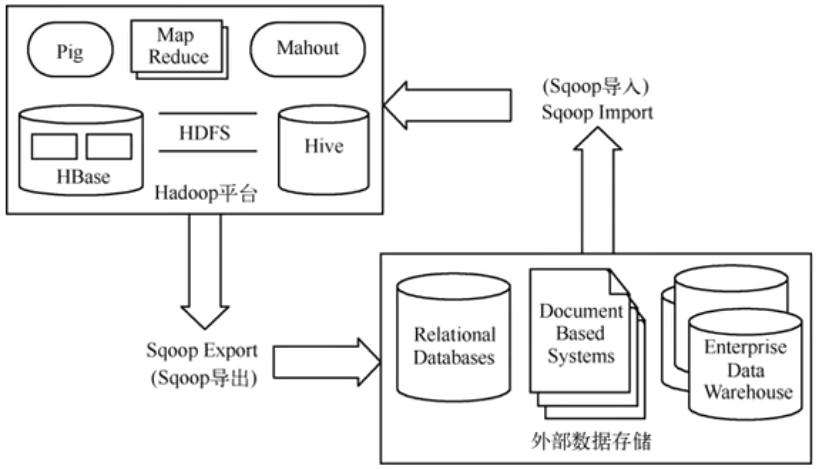
Apache Sqoop是一个用于在Hadoop和结构化数据数据存储之间高效传输批量数据的工具。
它的名字来源是"SQL to Hadoop"。顾名思义,功能就是从数据库导入到Hadoop(用于海量数据离线分析)和从Hadoop导出到数据库(用于业务分析)。
它的优势在于高效的批处理和简化了操作,并且支持主流的关系型数据库,还可自动映射(也可手动配置)。
Sqoop架构设计
追求的是在批量迁移场景下的简单高效。
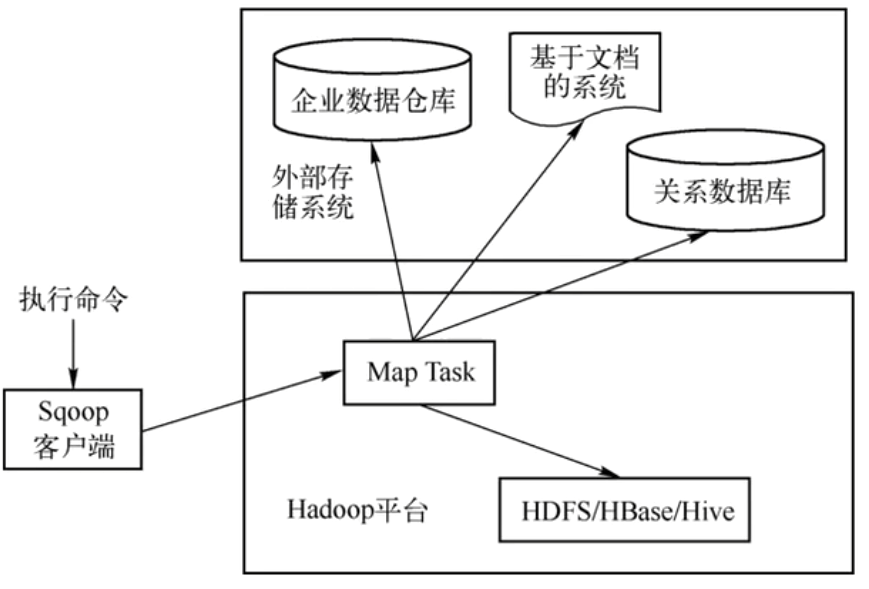
1.Sqoop Client(客户端):执行命令的客户端
2.Connector(连接器):负责与数据源交互的插件,为不同数据源提供定制化读写支持
3.MapReduce Framework(执行引擎):Sqoop将导入/导出任务翻译成MapReduce作业,利用Hadoop集群的分布式能力实现并行传输和容错。
Sqoop工作原理
翻译与并行
1.Import导入(RDBMS--->HDFS)
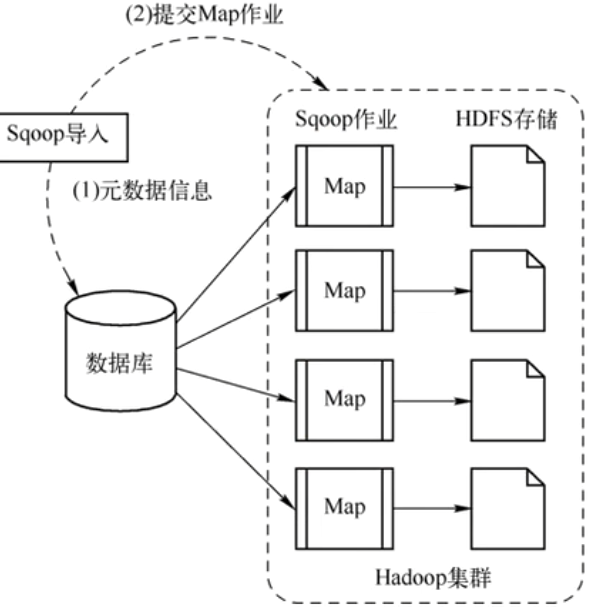
当执行sqoop import命令的时候:
- 元数据获取:Sqoop通过JDBC连接到数据库,获取表的列、数据类型等元数据。
- 任务翻译:Sqoop根据这些信息,生成一个只有Map阶段的MapReduce作业。
- 并行拉取:多个Map任务并行。每个任务负责拉取表的一部分数据工作,并将数据直接写入HDFS
2.导出(HDFS--->RDBMS)
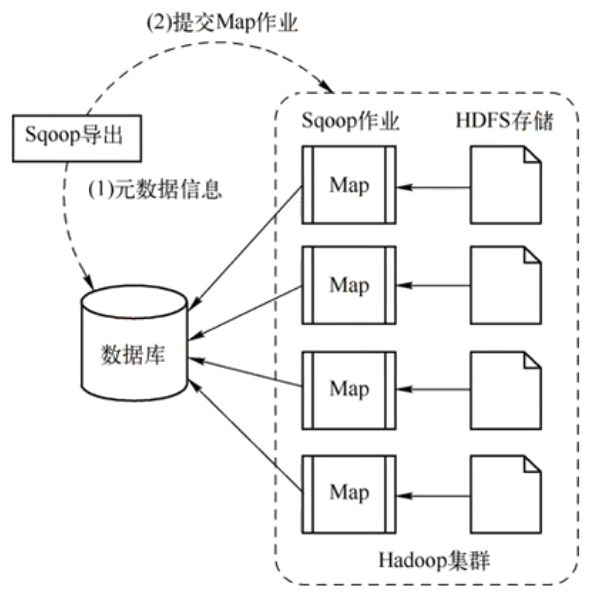
当执行sqoop export命令的时候:
- Sqoop读取HDFS上的数据文件。
- 生成MapReduce作业,每个Map任务读取一部分HDFS数据。
- Map任务通过JDBC将数据块以INSERT语句等形式批量写入目标数据库表。