一 LSTM和DenseNe t
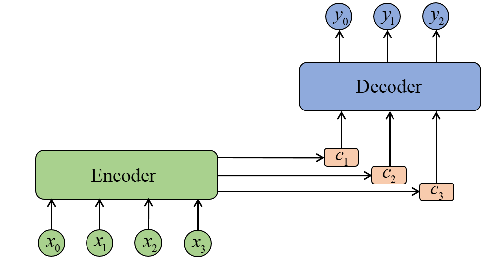
t是深度学习中两种重要但设计哲学完全不同的神经网络架构,核心区别可以总结为:LSTM是用于处理序列数据的循环网络,核心是 时间上的记忆传递,而DenseNet是用于处理空间数据的前馈网络,核心是深度上的特征复用。
二 核心 区别 对比表
|--------|---------------------------------------------|------------------------------------------|
| 对比维度 | LSTM | DensetNet |
| 主要设计目的 | 处理序列数据 文本,语音,时间序列,捕捉时间维度的长期依赖关系 | 处理网格数据,缓解深度网络中的梯度消失,促进特征在层间的复用 |
| 核心思想 | 门控机制:通过遗忘门,输入门,输出门,有选择的传递,更新和输出信息,形成一条记忆传送带 | 密集连接:每一层都接收前面所有层的特征图作为输入,将其输出传递给后面所有层 |
| 数据流向 | 循环/时间展开:信息沿时间步顺序传递,网络权重在时间上共享 | 前馈/空间加深:信息从浅层向深层单向流动,每一层都能直接获取最原始和所有中间特征 |
| 连接方式 | 链式结构:当前时刻的隐藏状态h_t和细胞状态C_t传递给下一时刻 | 全连接拓扑:第l层与之前的所有层0,...l-1都有直接连接,形成密集连接块 |
| 关键特征 | 具有内容状态 细胞状态,擅长建模动态时间行为 | 特征图数量增长,但参数相对高效,具有强大的特征传播能力 |
| 典型应用领域 | 机器翻译,文本生成,语音识别,股票预测 | 图分类,目标检测,医学图像分析 |
1 基于DenseNet网络模型的序列特征提取
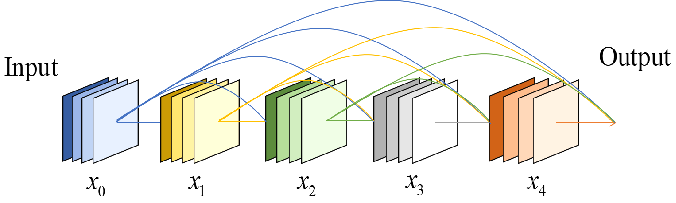
DenseNet是一种有效的图像识别算法,该网络的优点在于减轻了深层网络梯度消失问题,增强了特征图的传播利用率,减少了模型参数量,在ResNet的基础上进一步加强了特征图之间的连接,构造了一种具有密集连接方式的卷积神经网络
DenseNet网络模型的核心组成部分是密集连接模块,这个模块中任意两层之间均直接的连接,即网络中的第一层,第二层,第 L-1层的输出都会作为第L层的输入,同时第L层的特征图也会直接传递给后面所有层作为输入。
2 基于LSTM结构的上下文序列特征提取
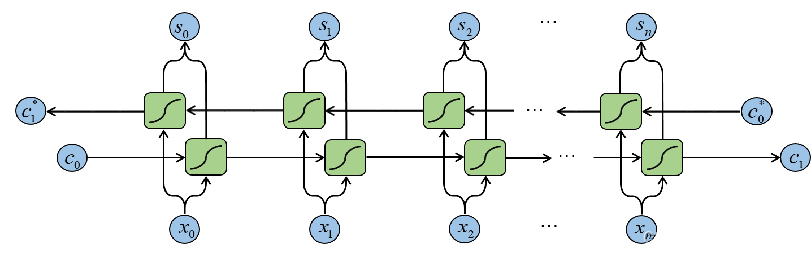
含有丰富的上下文信息,同一文本行中的不同字符可以互相利用上下文信息,这对于字符的识别具有重要的影响,一些模糊的字符在观察其上下文时更容易区分,在卷积网络之后,构建了一个循环网络,用于提取文本序列的上下文序列特征
双向LSTM能在访问之前信息的同时,访问字符之后的信息,故能从正反两个方向提取文本行中的语义信息,有助于文本行识别任务,因此,双向LSTM可以同时处理上文和下文信息来提取上下文序列特征。
字符序列的解码方式
在文本识别网络模型中,LSTM输出的序列中的字符要与标签中字符的位置一一对应,使用softmax函数作为损失函数进行训练,训练网络参数时需要在图像上标注出每个的位置信息,使用手工标注对其样本工作量非常大,所以需要解码使字符位置--对应,下面介绍两种常用的机制。
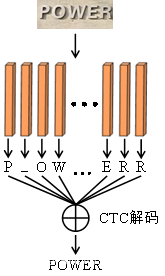
1 基于CTC解码机制
CTC机制常用语文字识别系统,解决序列标准问题中输入标签与输出标签的对其问题,通过映射,无序数据对齐处理,减少了工作量,广泛用于图像文本识别的损失函数计算,多用于网络参数的优化。
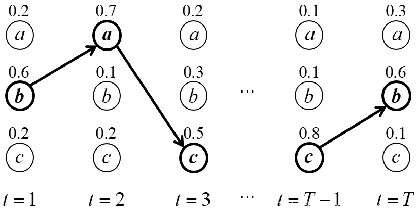
解码是模型在做预测的过程中将LSTM输出的预测序列通过分类器转换为标签序列的过程,解码过程中的分类方式为最优路径编码,输出计算概率最大的一条路径作为最终的预测序列,在每个时间点输出概率最大的字符。
2 Attention模型注意力机制解码方式
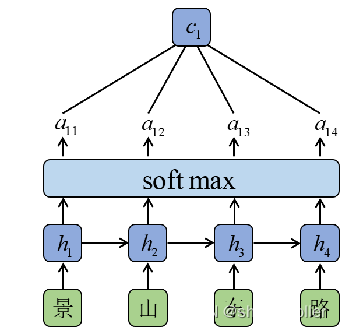
注意力机制被广泛用于序列处理Seq2Seq任务中,注意力模型借鉴了人类视觉的选择性注意力机制,其核心目标是从众多信息中选出对当前任务目标来说重要的信息,忽略其他不重要的信息。
对含有文本的图片而言,文本识别输出的结果的顺序取决于文本行中字符前后位置信息,引入注意力机制可以起到定位的作用,从而突出字符的位置信息,解决序列对齐问题,因此不需要标准文本的位置。
Attention 模型的原理是计算当前输入序列与输出序列的匹配程度,在产生每一个输出时,会充分利用输入序列上下文信息,对同一序列中的不同字符赋予不同的权重。
三 DenseNet的数学表示
第一层输入x0->h1->输出x1
第二层输入x1,x0->h2->输出x2
第三层输入x2,x1,x0->h3->输出x3
第四层输入x3,x2,x1,x0->h4->输出x4